基于领域特有情感词注意力模型的跨领域属性情感分析
2021-07-23赵光耀吕成国付国宏刘宗林梁春丰
赵光耀,吕成国,付国宏,刘宗林,梁春丰,刘 涛
(1. 黑龙江大学 计算机科学与技术学院,黑龙江 哈尔滨 150080;2. 苏州大学 人工智能研究院,江苏 苏州 215006)
0 引言
随着互联网技术的发展以及京东、携程和淘宝等电子商务平台的普及,涌现了大量关于产品和服务的用户评论数据。通过这些评论数据的用户情感倾向分析,不但能够帮助用户选择商品,而且有助于商家即时获取用户的反馈信息。因此,情感分析,特别是细粒度的属性情感分析近年来得到广泛的关注[1-4],其目的是识别句子中目标属性的情感极性(如正面、负面和中性)。以“各方面还是不错的,唯独[屏幕]拖影严重,看的眼睛刺痛”为例,“屏幕”是目标属性,“拖影严重”是对“屏幕”带有负面情感倾向的细节描述,所以可以判断出该属性的情感极性为负面。
主流的数据驱动的属性情感分析方法依赖于充足的训练语料[3-4]。但由于语料标注的成本高,很难在每个领域都能够得到大规模、高质量的训练语料。针对训练语料不足的问题,一些研究尝试将与目标领域相似的源领域样本直接迁移到目标领域中[5-6]。此外,使用大量的目标领域无标注数据能增强模型对目标领域数据的学习能力[7],而且获取大量的无标注数据也相对较为容易。因此,本文采用半监督迁移学习,充分利用已有的源领域有标记数据、少量目标领域有标记数据和大量目标领域无标记数据,探索跨领域属性情感分析问题。
基于迁移学习的建模方法主要有特征选择[8-9]和数据分布自适应[10-11]等。特征选择方法对源领域和目标领域的共有信息建模,并将模型直接应用于目标领域。数据分布自适应方法则使用一个映射函数,将两个领域的向量表示映射到新的空间,并使映射后的概率分布在新的空间。这两种方法虽能有效学习两个领域的共有信息,但都忽略了目标领域的特有信息。针对特有信息,Peng等人[12]提出利用CMD正则化[13]同时提取领域共有表示和特有表示的方法,并在情感分析任务上取得了很好的效果。
然而,以上方法没有深入分析提取到的共有信息或特有信息,并加以区分。假设共有信息或特有信息是与领域高度相关的专有名词或与领域无关的介词等,即使这些词可以被划分为共有信息或特有信息,它们也不包含任何感情色彩。尤其在跨领域属性情感分析任务中,属性词与领域高度相关,并且是领域的特有信息,但是属性词不包含感情色彩。相反,描述目标属性的情感词能够明显地反映出目标属性的情感极性。在图1中,分别列举了酒店领域和手机领域的两条样例,情感词“不错”和“臭”反映了“餐厅”和“卫生间”的情感极性分别为正面和负面。情感词“很好”和“失灵”反映了“质量”和“屏幕”的情感极性分别为正面和负面。

图1 情感词反映目标属性的情感极性
进一步研究发现,情感词不仅蕴含重要的情感信息,有助于判断目标属性的情感极性,而且可以进一步划分为共有情感词和特有情感词。在图2中,分别列举了共有情感词和特有情感词,其中共有情感词有“很好”“不错”等;手机领域的特有情感词有“清晰”“卡顿”等;酒店领域的特有情感词有“老旧”“吵闹”等。因此,本文尝试以情感词为核心作为共有信息和特有信息探索跨领域属性情感分析任务。

图2 共有情感词和特有情感词
为此,本文使用注意力机制提取源领域和目标领域的情感词特征,并利用CMD正则化方法将情感词特征划分为共有情感词特征和特有情感词特征,同时根据情感词特征和目标属性之间的关系分别建立共有特征分类器和特有特征分类器,最后使用协同训练(co-training)[14]方法融合两种特征。
本文的主要贡献如下:
(1) 改进了共有特征和特有特征融合的领域迁移方法,提出一种跨领域属性情感分析方法。
(2) 针对特有信息和情感词,提出一种领域特有情感词注意力模型。
(3) 构建了一个跨领域的中文属性情感分析数据集,并利用该数据集实验验证了基于领域特有情感词注意力模型的跨领域属性情感分析方法的有效性。
1 相关工作
1.1 迁移学习
近年来,迁移学习在自然语言处理任务中取得了很大进展,尤其是跨领域情感分析任务[15-16]。特征选择是迁移学习的主流方法之一。Blitzer等人[8]提出一种结构对应学习方法(structural correspondence learning, SCL),以发现两个领域的共有信息。但该方法忽略了领域特有信息。为此,Bousmalis等人[17]提出利用领域特有信息的方法(domain separation networks, DSN)。该方法通过分离共有信息和特有信息,增强提取共有信息的能力。但DSN提取特有信息是为了辅助模型更好地提取共有信息,特有信息并没有得到充分利用。为了充分利用特有信息,Peng等人[12]提出同时提取共有表示和特有表示并分别训练一个分类器的方法。然而上述方法并没有进一步分析并区分所提取到的共有信息或特有信息。基于此,本文针对跨领域属性情感分析任务的特点,利用注意力机制作为编码器,并以情感词为核心建模,同时提取共有情感词特征和特有情感词特征。
数据分布自适应是另一种典型的主流迁移学习方法。Pan等人[10]提出迁移成分分析方法(transfer component analysis, TCA)。TCA方法假设存在一个映射分布φ,使映射后的源领域概率分布和目标领域概率分布近似,即P(φ(xs))≈P(φ(xt))。因此,两个领域的距离是衡量领域之间相似程度的重要指标。机器学习中常用的距离公式有最大均值差异(maximun mean discrepancy, MMD)[18-19]和多核最大均值差异(multi-MMD)[20-21]等。在此基础上,Zellinger等人[13]提出中心矩差异(central moment discrepancy, CMD),将MMD推广至多阶。以上方法直接使用句子级编码来计算两个领域间的距离,而本文针对跨领域属性情感分析的特点,以情感词为核心的向量表示为基础计算两个领域的概率分布距离。
基于分歧的方法[22]是一种主流的半监督学习方法。其中,Blum等人[14]提出将每个属性集看作一个视角(views)的协同训练方法。随后,Chen等人[23]提出在协同训练的每一轮迭代中,将一个特征空间看作一个视角,并将其作为单一优化问题进行训练。本文针对跨领域属性情感分析任务,将共有情感词信息与特有情感词信息看作两个不同的视角,并利用协同训练方法融合两个视角的特征。
1.2 属性情感分析与注意力机制
作为一种典型的细粒度情感分析,属性情感分析的关键是明确目标实体和上下文中重要情感信息的关系。早期的方法依赖于人工设计和提取与目标实体相关的重要情感信息[24]。但这些方法高度依赖人工设计特征的质量。随着深度学习的发展,目前的研究主要利用神经网络模型自动学习上下文中与目标实体相关的重要情感信息句子表示[25-27,29-32]。Tang等人[27]利用两个双向长短时记忆神经网络(bi-directional long short-term memory, BiLSTM)[28]分别对上下文进行编码,自动获取上下文中和目标实体相关的重要情感信息。Zhang等人[29]提出使用门控机制选择上下文中和目标实体相关的重要情感信息。
近来,由于注意力机制能够有效捕获句子中的重要信息,细粒度情感分析相关研究开始使用注意力机制建模[30-31]。Tang等人[30]通过叠加多层注意力网络对句子进行编码。Ma等人[31]直接利用目标实体的词向量表示和注意力机制捕获上下文的重要信息。Liu等人[32]利用注意力机制,根据每一个词对目标实体情感极性的贡献度建模。受这些研究启发,本文在跨领域属性情感分析任务中使用注意力机制提取情感词信息,得到以情感词为核心的向量表示,但在计算两个领域的距离时忽略情感词和目标属性的关系,只在分类器中对目标属性和情感词信息的关系建模。
2 方法
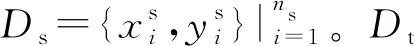
如图3所示,本文方法主要由输入端、基于注意力机制的共有情感词特征与特有情感词特征提取器、分类器以及协同训练等部分构成。
2.1 输入端
输入端为源领域有标记数据Ds和目标领域数据Dt。在计算两个领域的距离时使用有标记样本和无标记样本,而在分类时仅使用有标记样本。本文以字为单位,使用预训练外部词向量将输入句子序列{w1,…,wn}转换为低维稠密的向量表示{x1,…,xn}。
2.2 特征提取器
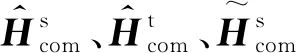

图3 本文方法的整体框架
2.2.1 注意力机制
在跨领域属性情感分析任务中,情感词信息可以直接地表达属性的情感极性,而且使用注意力机制可有效地提取句子的情感词信息。因此,本文使用注意力机制作为情感词特征编码器,从而得到以情感词为核心的向量表示H。
如图4所示,注意力机制编码器的输入端为{h1,…,ht0,…,htm,…,hn}。其中{ht0,…,htm}代表句子中目标属性词的向量表示,ht代表属性词均值的向量表示。本文以字为单位,通过计算每个字的权重α得到句子的向量表示H。为了排除属性词本身的领域高度相关性,本文在使用注意力机制的同时,属性词不参与H的计算。
(1)
其中α为每个字的权重,公式如式(2)所示。
(2)
β的计算公式如式(3)所示。
βi=UTtanh(W·hi+b)
(3)
根据目标属性在句子中的位置可以将句子划分为前文、属性词和后文三部分。考虑到情感词可能分布在前文或后文中,本文分别对前文和后文同样使用注意力机制进行编码,以增强注意力机制的效果,如式(4)所示。
(4)

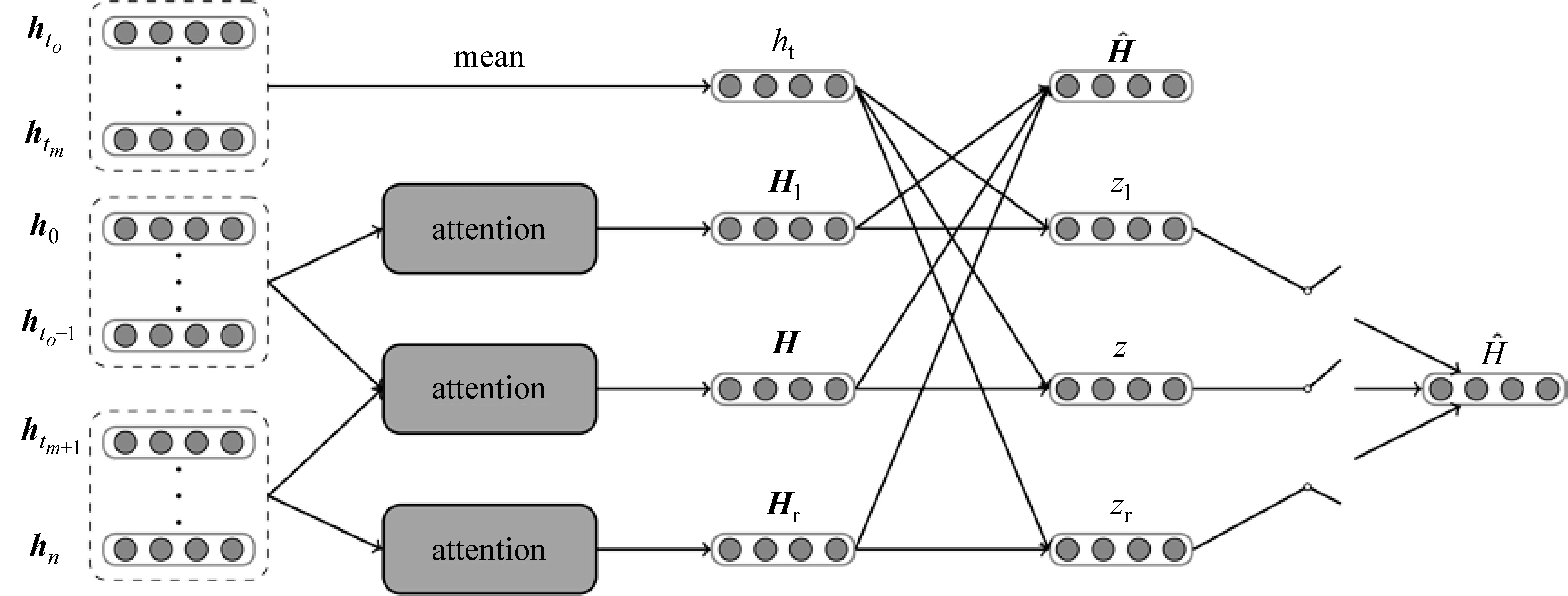
图4 注意力机制
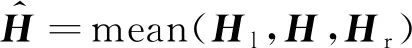
(5)
2.2.2 CMD正则化
CMD正则化公式的定义如下: 假设存在X=(X1,…,Xn)和Y=(Y1,…,Yn)两组独立同分布的边缘随机向量,且分别来自稠密区间[a,b]N上的两个概率分布p和q,则CMD距离为:
(6)
其中,E(X)是X的期望,ck(X)是k阶中心矩向量,即:
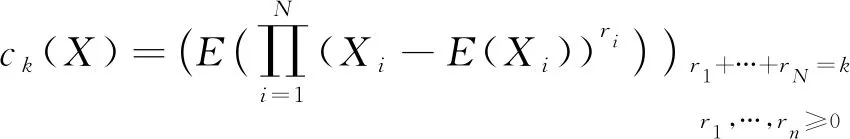
(7)
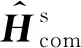
(8)
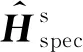
(9)
在实际模型中,为了在最小化Lsim的同时最大化Ldiff,本文在Ldiff前加入梯度翻转层(gradient reversal layer, GRL)。
2.3 分类器
与大多数分类任务不同,属性情感分析中目标属性与上下文情感词之间的关系非常重要。本文在共有特征分类器和特有特征分类器中,根据描述目标属性的情感词判断目标属性的情感极性,但句子中往往存在多个情感词。因此,本文采用门控机制对目标属性和多个情感词的关系建模,其具体过程如下:
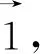
2.4 协同训练
本文采用协同训练的方法,将两个分类器得到的概率值加权求和,作为最终的概率结果。两个分类器同时对目标领域无标记数据进行预测,分别选取置信度最高的多个样本作为伪标记(pseudo-labeled)样本添加到目标领域有标记数据中,从而起到数据增强的作用。
协同训练起初是针对多视角(multi-view)数据设计的,就像从不同的角度看待一个问题,不同视角之间是互补的。本文同样可以分为共有特征视角与特有特征视角。基于共有特征视角的目标函数为:
L=αLcom+γLsim+λLdiff
(12)
其中,Lcom是共有特征分类器Ccom的交叉熵损失函数。同样,基于特有特征视角的目标函数为:
L=βLspec+γLsim+λLdiff
(13)
其中,Lspec是特有特征分类器Cspec的交叉熵损失函数。
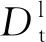
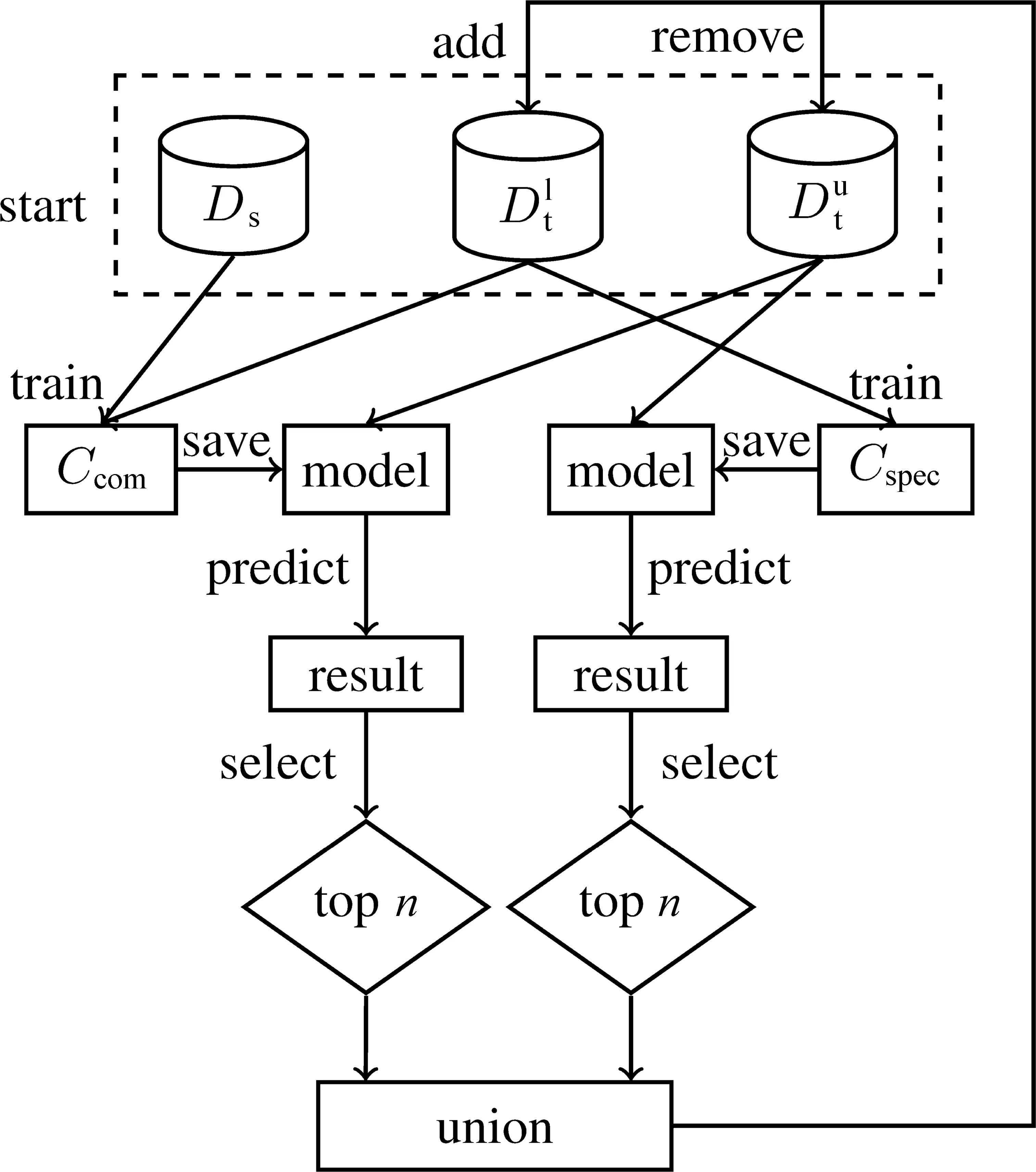
图5 协同训练流程图
3 实验
3.1 数据
为了验证上述跨领域属性情感分析方法的有效性,本文选取酒店和手机两个领域构建了属性级的用户评论数据集。该数据分别从京东网和携程网爬取,并经过清洗、筛选、人工标注和交叉校对等流程。为了简化标注任务,本文只标注目标属性词及其正面、负面和中性情感极性。
如表1所示,该数据集共有28 330条酒店领域的有标记数据,7 233条手机领域的有标记数据。此外,有13 354条无标记的目标领域数据。根据半监督学习的需求,本文对目标领域有标记数据进行了划分,其中训练、开发和测试的比例约为1∶2∶4,并且每份数据集中正面、负面和中性数据的比例保持基本一致。
3.2 评价指标与参数设置
考虑到表1的实验数据中情感极性分别为正面、负面和中性样例的比例存在不平衡性,除了准确率,本文还使用宏平均F值、宏查全率和宏查准率等指标来评估分类模型性能。
此外,本文使用腾讯AILab的中文词向量作为预训练外部词向量。相关参数设置如表2所示。
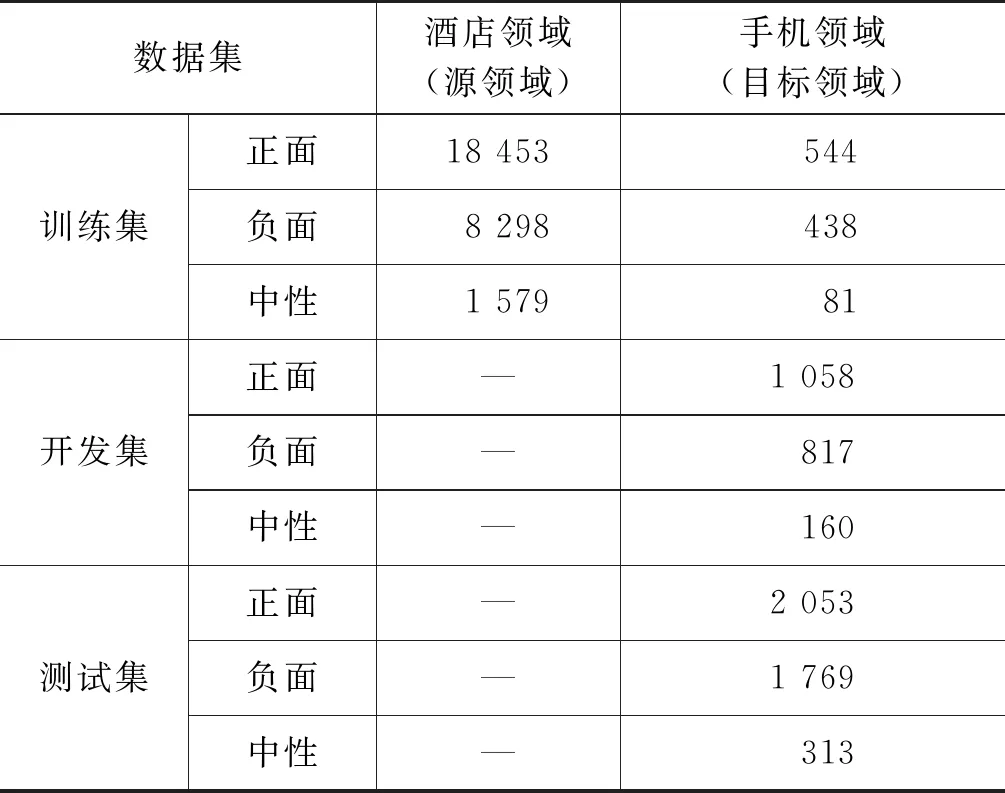
表1 数据统计结果
表2 参数设置
3.3 对比方法与实验结果
(1) 本文使用注意力机制作为情感词特征编码器,利用以情感词为核心的向量表示计算两个领域的概率分布距离,并进一步融入情感词和目标属性之间的关系构建分类器。为了验证本文方法(DSSW-ATT)的有效性,本文与以下实验进行了对比:
BiLSTM: 使用BiLSTM作为编码器,基于监督学习,训练数据为有标记的源领域数据Ds,该方法是监督学习的基线方法。
ATT-BiLSTM: 与BiLSTM作为对比,在BiLSTM的基础上,使用注意力机制作为编码器,训练数据与BiLSTM一致。
ATT-BiLSTM-COCMD: 在BiLSTM-COCMD基础上,使用Liu等人[32]提出的注意力机制作为编码器,根据与目标属性相关的情感词信息计算两个领域的距离并构建分类器。
实验结果如表3所示。从中可以看出,ATT-BiLSTM的准确率、宏平均F值和宏查全率均优于BiLSTM方法。同样,相比于BiLSTM-COCMD方法,ATT-BiLSTM-COCMD方法在准确率和宏平均F值上分别提升了0.33%和0.2%。这表明以情感词信息为核心的建模方式能够提升跨领域属性情感分析的性能。DSSW-ATT方法在准确率和宏平均F值上比ATT-BiLSTM-COCMD方法分别提升了0.66%和1.11%,进一步验证了本文提出的领域特有情感词注意力模型的有效性。
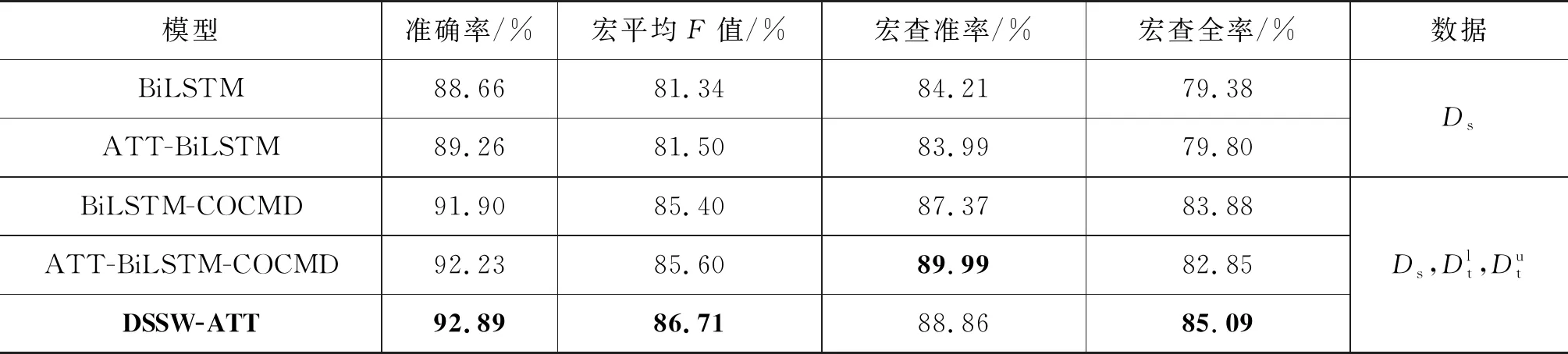
表3 本文模型对比结果
此外,相比ATT-BiLSTM-COCMD,DSSW-ATT在宏查全率上提升2.24%,但在宏查准率上却下降了1.13%。针对这一现象,本文进一步研究这两个模型在各情感类别上的宏查全率、宏查准率和宏平均F值。如表4所示,相比ATT-BiLSTM-COCMD,DSSW-ATT在正面情感上的宏查全率下降,宏查准率提升;相反,在负面和中性情感上的宏查全率提升,宏查准率降低。而且DSSW-ATT在所有情感类别上的宏平均F值均显著优于ATT-BiLSTM-COCMD方法,这表明本文方法能够更好地平衡宏查全率和宏查准率的关系。针对语料不平衡问题,虽然中性情感的训练语料较少,但DSSW-ATT方法在中性情感上的宏平均F值比ATT-BiLSTM-COCMD方法提升了2.16%,尤其在宏查全率上提升了6.4%,表明本文方法对语料较少的类别仍有较强的学习能力,从而在一定程度上解决语料不平衡问题。
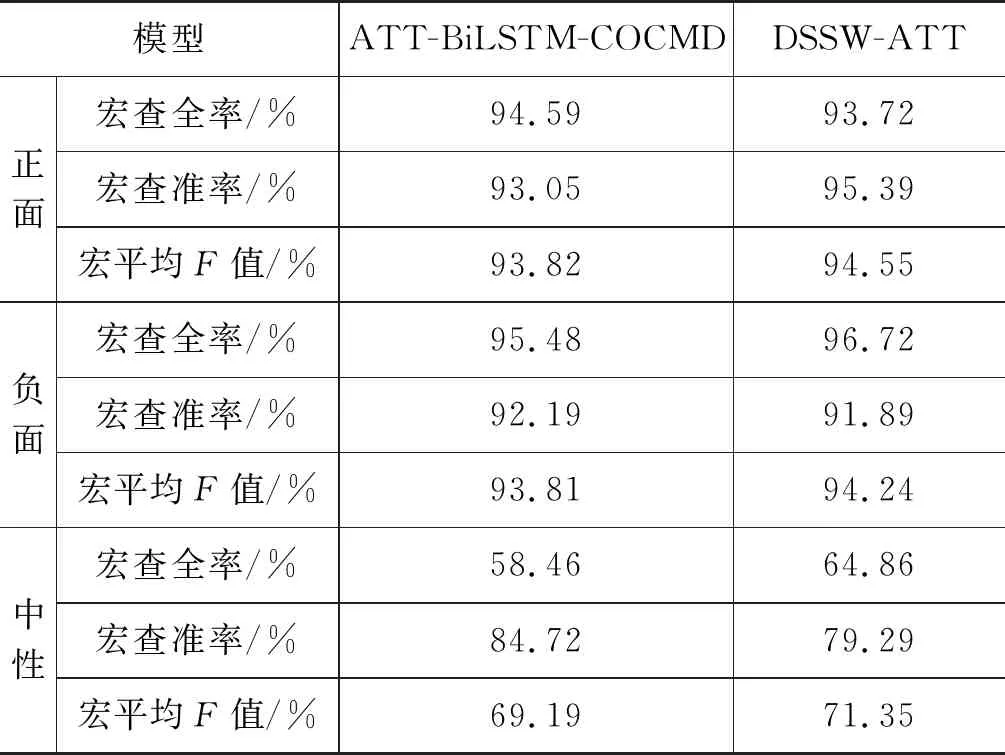
表4 各情感类别上的评价结果
(2) 将本文与其他相关的主流方法进行了对比,结果如表5所示。为了应用于跨领域属性情感分析任务,本文在这些方法的基础上使用注意力机制作为改进。
相比于使用目标领域有标记数据的ST方法,CMD、DANN和DSN方法在准确率和宏平均F值上表现较差,这表明了目标领域有标记数据的重要性。DSN方法尝试利用特有信息作为辅助,使模型更好地提取共有信息。虽然该方法使用了特有信息,但实验结果表明性能提升有限。基于协同训练的CODA方法使用了目标领域有标记数据,通过语料增强的方法扩充了大量的目标领域有标记数据,并取得了较好的效果。本文在利用特有信息的同时,使用协同训练的方法,实验结果表明DSSW-ATT方法在准确率、宏平均F值等评价指标上比DSN和CODA均有较大幅度的提升。

表5 与主流建模方法的对比结果
3.4 情感词特征的分析
为了更直观地分析注意力机制是否能够提取情感词信息,本文分别选取了正面和负面的样例并绘制灰度图以展示句子中每个字的权重分布。在灰度图中,颜色越深表示权重越大。如图6所示,“返回键”是目标属性,相应的情感词“太差”带有负面感情色彩。因此,该属性的情感极性为负面。同样,在图7中,描述目标属性“外表”的情感词“漂亮”带有正面感情色彩,该目标属性的情感极性为正面。基于灰度图的样例分析进一步表明基于注意力情感词提取方法的有效性。

图6 负面情感的灰度图

图7 正面情感的灰度图
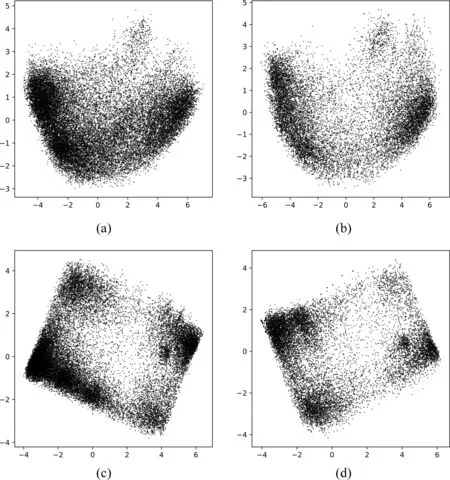
图8 PCA分布图
4 结论
针对跨领域属性情感分析任务,本文提出一种领域特有情感词注意力模型。该模型在提取共有信息和特有信息的基础上,使用注意力机制作为编码器,以情感词信息为核心进行编码,并进一步将情感词划分为共有情感词与特有情感词,最后结合共有情感词信息与特有情感词信息。在本文构建的数据集上的实验结果表明,该方法在跨领域属性情感分析任务上取得了最好的效果。不同的迁移学习方法实际上是从不同的视角解决跨领域问题,未来研究将尝试融合多个迁移学习方法进行跨领域属性情感分析研究。
