基于深度信念网络的铁谱图像智能识别方法与试验验证*
2021-07-23樊红卫胡德顺高烁琪张旭辉曹现刚
樊红卫 胡德顺 高烁琪 张旭辉 曹现刚
(1.西安科技大学机械工程学院 陕西西安 710054; 2.陕西省矿山机电装备智能监测重点实验室 陕西西安 710054)
机械设备中的传动齿轮在长期运行过程中,受到润滑油、负载变化等因素的影响,经常会出现磨损现象。磨损原因主要有主、从动轮表面粗糙度和硬度不匹配[1];润滑油黏度过低[2];负载加重和循环次数增加[3]。据统计,齿轮传动失效引起的机械故障在总故障中占比约80%,其中磨损约占40%。一旦发生磨损故障,不仅会加剧系统的振动噪声,还会降低传动精度和效率,甚至引发断齿等严重的机械事故[4]。
机械磨损检测技术已有很长的发展历史,主要有放射性检测、磨粒分析、振动检测、光学检测、电学检测、磁学检测、声学检测、压痕方法等[5],这些技术在各自领域取得了良好效果。如,张雪英等[6]通过振动信号的小波阈值降噪与遗传算法优化的支持向量机实现了齿轮磨损识别;SHI等[7]提出了一种改进的磨粒电感检测法,弥补了普通电感法检测非铁磁性金属颗粒能力不足的问题。
磨粒分析中的铁谱分析应用广泛,是机械磨损检测的重要手段。PENG等[8]提出了一种高斯背景混合模型和斑点检测算法,对润滑油中磨损颗粒进行检测,提取了磨粒形状和尺寸特征,实现了磨粒在线监测。WU等[9]提出了一种恢复方法来减少在线铁谱图像中散焦模糊问题,用卷积神经网络构造退化模型,实验验证了所提出的恢复策略能有效提取磨粒特征,具有更高计算效率。WANG等[10]提出了一种用于识别典型磨损碎片的集成化方法,利用反向传播神经网络作为第一级分类,利用卷积神经网络作为第二级分类,实验证明了其识别率明显提高。SUN[11]总结了柴油机中常见磨粒特征,将故障机制与磨粒特征结合,建立了磨损评价体系,利用铁谱分析对柴油机进行监测,取得了良好效果。张珊珊等[12]将铁谱与激光粒度分析技术综合应用于磨粒识别,既能判断磨损类型,又能判断磨损程度。CAO等[13]提出了一种数据重构与特征提取方法,对监测数据进行重构后表征了数据变化趋势,提取了磨损状态特征并进行了磨损预测,实验结果表明改进的模型能提供更早的异常警报,预测性能良好。LI等[14]针对基于传统梯度算法的前馈神经网络易陷入局部极小值问题,提出了基于极限学习机的铁谱磨粒图像识别方法,获得了较好分类效果。闫建阳等[15]提出了一种磨粒图像多特征融合识别方法,提取了铁谱图像磨粒纹理、颜色和几何特征,归一化后运用SVM与D-S证据理论实现了铁谱图像识别,准确度高。WANG等[16]提出了基于卷积神经网络的铁谱图像识别方法,对铁谱图像进行端到端分类,可用ms级的速度处理图像,实现在线监测。安超等人[17]提出了基于Mask R-CNN的铁谱磨粒智能识别方法,克服了传统方法在复杂图像背景下对相似磨粒识别难题。
上述研究对磨粒铁谱图像的智能识别提供了不同思路,但尚未见将深度信念网络用于磨损状态识别。本文作者提出一种基于深度信念网络的铁谱图像智能识别方法,利用铁谱技术制备磨粒图像集来训练网络模型,研究模型中各参数变化对其性能的影响以确定最佳模型,从而实现机械磨损故障类型智能识别。
1 铁谱图像智能识别算法的基本原理
1.1 受限玻尔兹曼机
1986年,HINTON和SEJNOWSKI[18]提出了一种基于能量的随机神经网络即玻尔兹曼机,该模型是一种无监督训练模型,具有强大的特征提取能力,能够提取输入数据中深层次、复杂的高级特征。但是,模型可见层与隐含层内神经元全连接,训练时间较长。因此,SMOLENSKY[19]改进提出了一种限制的玻尔兹曼机,即受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)。RBM同样具有可见层和隐含层,每层包含若干个神经元,不同于玻尔兹曼机的是RBM层内无连接,结构如图1所示。
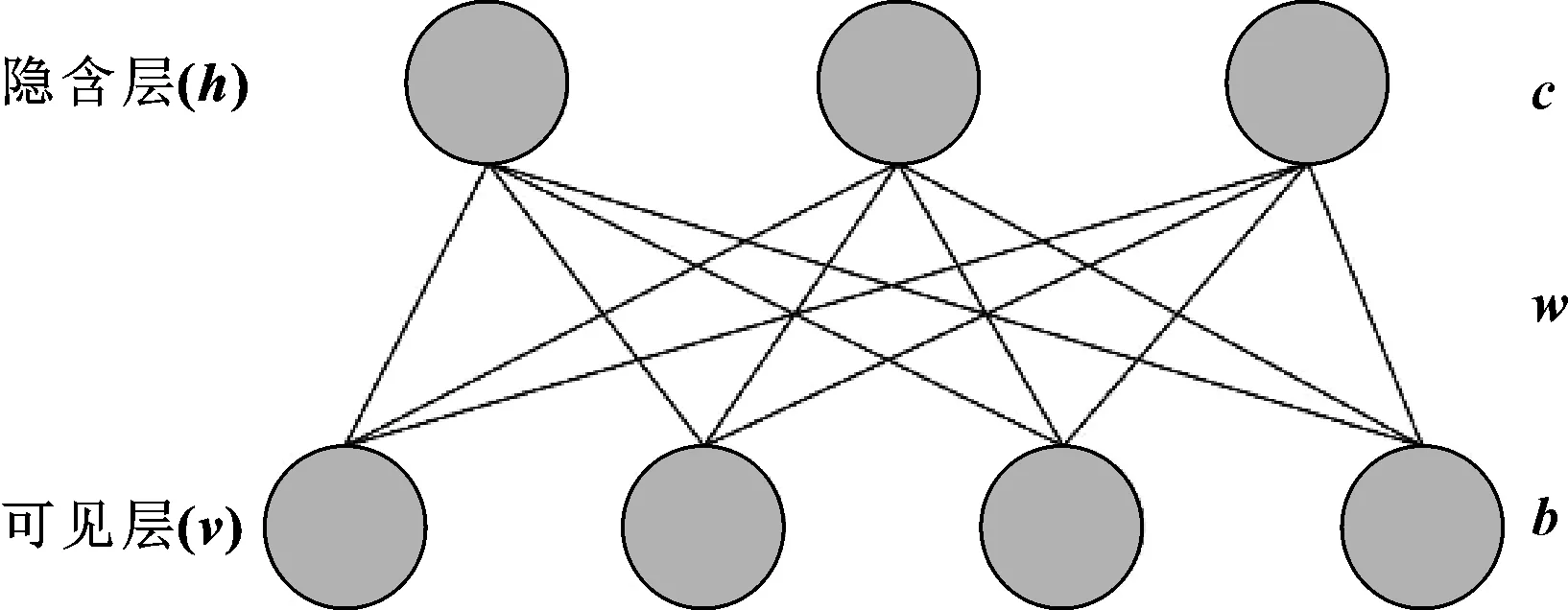
图1 受限玻尔兹曼机模型
当RBM模型中权重w、可见层偏置b和隐含层偏置c给定,且可见层v和隐含层h的状态给定时,模型的能量为
(1)
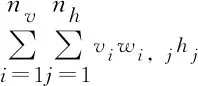
基于模型能量函数,可得RBM模型的概率分布:
(2)
进一步可得到隐含层和可见层神经元被激活的概率为
(3)
(4)
式中:Sigmoid(x)是激活函数,表达式为
(5)
RBM模型的训练目标是不断学习模型中各参数,使RBM所表示的边缘概率分布P(v)尽可能接近训练数据所表示的分布,即最大化似然函数:
(6)
式中:θ为训练目标参数,包含w、b、c;v(i)为第i个样本数据;m为训练样本数量。
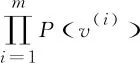
(7)
对式(7)进行偏导数计算得到:
(8)
(9)
(10)
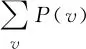
CD算法利用训练样本初始化可见层状态,利用式(3)计算隐含层神经元激活概率,从而确定隐含层神经元状态,然后利用式(4)计算可见层神经元激活概率,从而确定可见层神经元状态,完成CD-1算法,将该过程循环k次即实现可见层神经元的k次重构,即完成CD-k算法。
1.2 深度信念网络
深度信念网络(Deep Belief Network,DBN)是HINTON等于2006年提出的基于RBM的学习模型[21]。DBN的实质是将若干个RBM串联起来构成一个DBN,其中,上一个RBM的隐含层即为下一个RBM的可见层,上一个RBM的输出即为下一个RBM的输入,结构如图2所示。
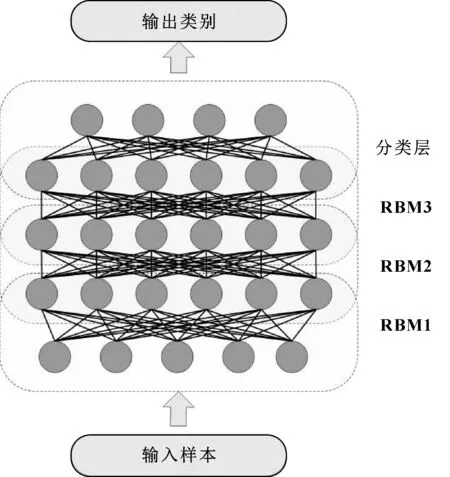
图2 DBN模型结构
DBN模型的训练分为2个阶段:第一阶段是预训练,先用训练样本训练第一个RBM,并用训练好的第一个RBM参数初始化DBN第一层参数,然后将第一个RBM的输出结果作为第二个RBM的训练样本来训练第二个RBM,训练完后用第二个RBM参数初始化DBN的第二层参数,以此类推,直到最后一层;第二阶段是微调,初始化DBN所有层参数后,利用带标签的训练集有监督地训练DBN,微调DBN各层参数。DBN模型的训练过程如下:
第一步:初始化DBN模型结构;
第二步:根据设定的DBN模型结构划分其中RBM模型;
第三步:利用CD-k算法对每个RBM模型进行参数训练;
第四步:利用训练完毕的RBM参数初始化DBN模型中每层参数;
第五步:利用带标签的数据集有监督地训练DBN整体模型。
2 磨粒铁谱图像智能识别算法的实现
文中通过铁谱分析技术,结合DBN模型,实现对机械设备润滑油中磨粒铁谱图像的智能识别。从铁谱图像制备到最终故障识别的流程如图3[21]所示。
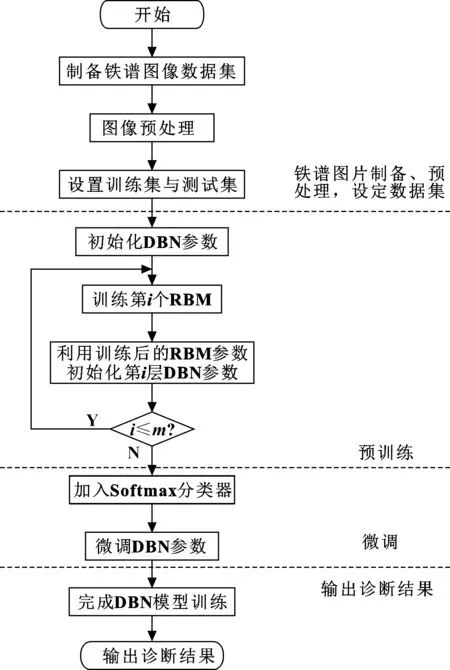
图3 铁谱图像智能识别流程
基于DBN的铁谱图像智能识别主要有以下步骤:
(1)利用铁谱仪制备铁谱图像数据集,并对图像进行预处理,然后设置训练集与测试集;
(2)搭建DBN模型框架,根据输入数据维度和输出故障类别数确定网络输入层和输出层的神经元个数,初始化其中各参数,包括学习率、激活函数、优化器等,利用铁谱图像数据集对模型中关键参数进行研究,确定DBN模型的最佳参数设置;
(3)利用铁谱图像逐层训练每一层RBM模型,用训练完的RBM模型参数初始化同层DBN神经元的权重与偏置,将上一层RBM输出作为下一层RBM输入,逐层无监督训练每一层RBM模型;
(4)预训练完毕后,利用带标签的铁谱图像数据集有监督地微调整个DBN模型,优化各神经元的权重和偏置;
(5)微调结束后,DBN模型即可用于铁谱图像的智能识别,实现磨损故障诊断。
由以上铁谱图像识别过程可知,DBN将无监督预训练和有监督微调有机结合,实现了铁谱图像数据深层特征的自动提取和故障类别自动识别,较传统故障识别方法极大地提高了故障诊断的准确率和效率。
3 齿轮箱磨粒铁谱图像智能识别试验
3.1 铁谱图像制备
为了制备铁谱图像,搭建了齿轮传动系统,如图4[22-23]所示,对该系统中齿轮传动部件运行一段时间后的油液进行收集,用于制备铁谱图像。

图4 齿轮传动系统
该齿轮传动系统由变频电机驱动,磁粉制动器模拟负载,包含二级行星轮系和二级直齿轮减速器,利用600XP150齿轮油进行润滑。润滑油收集完毕后,利用YTF-8分析式铁谱仪对油液进行谱图制备[22-23],铁谱仪平台如图5[22-23]所示,是一种典型的分析式铁谱仪,由制谱系统和显微成像系统两部分组成,所得铁谱图像存于上位机中。

图5 铁谱分析平台
根据机械设备磨损的磨粒特征,可将磨粒分为正常磨粒、切削磨粒、严重滑动磨粒、滚动磨粒等,相应的铁谱图像及其特征总结如表1所示。

表1 磨粒铁谱图像与特征
由于铁谱图像制备过程复杂耗时,谱图质量较难控制,故谱图数量通常有限,不足以用来训练深度学习模型,因此需要对图像数据进行扩充。通过数据增强方法可以快速扩充样本,包括平移、旋转、对比度增强、翻转等方法。文中通过混合使用以上4种方法对原始铁谱图像数据集进行扩充,原始小样本以指数速率扩充成大样本,在样本数量上满足了深度信念网络模型训练要求。此外,对采集到的铁谱图像进行了背景色处理,极大提高了前景和背景的辨识度。
3.2 铁谱图像智能识别研究
采用Python语言,基于TensorFlow框架搭建了DBN模型,其输入层神经元个数为3 600,第一层隐含层神经元个数为2 000,第二层隐含层神经元个数为1 000,第三层隐含层神经元个数为100,输出层神经元个数为4,损失函数采用交叉熵,优化器选择Adam,然后利用铁谱图像数据集(包含训练集40 000张,测试集8 000张,训练集每个类别10 000张,测试集每个类别2 000张)对模型重要参数进行研究,包括激活函数、Dropout值、学习率和批训练数,从而完成对齿轮工作状态(包含正常状态、切削磨损、严重滑动磨损、滚动磨损)的智能诊断。
3.2.1 激活函数与Dropout值
设DBN模型中激活函数分别为Sigmoid和Relu,研究其在不同Dropout值下的表现。图6示出了激活函数为Sigmoid,而Dropout值分别为0.2、0.4、0.6时训练结果。
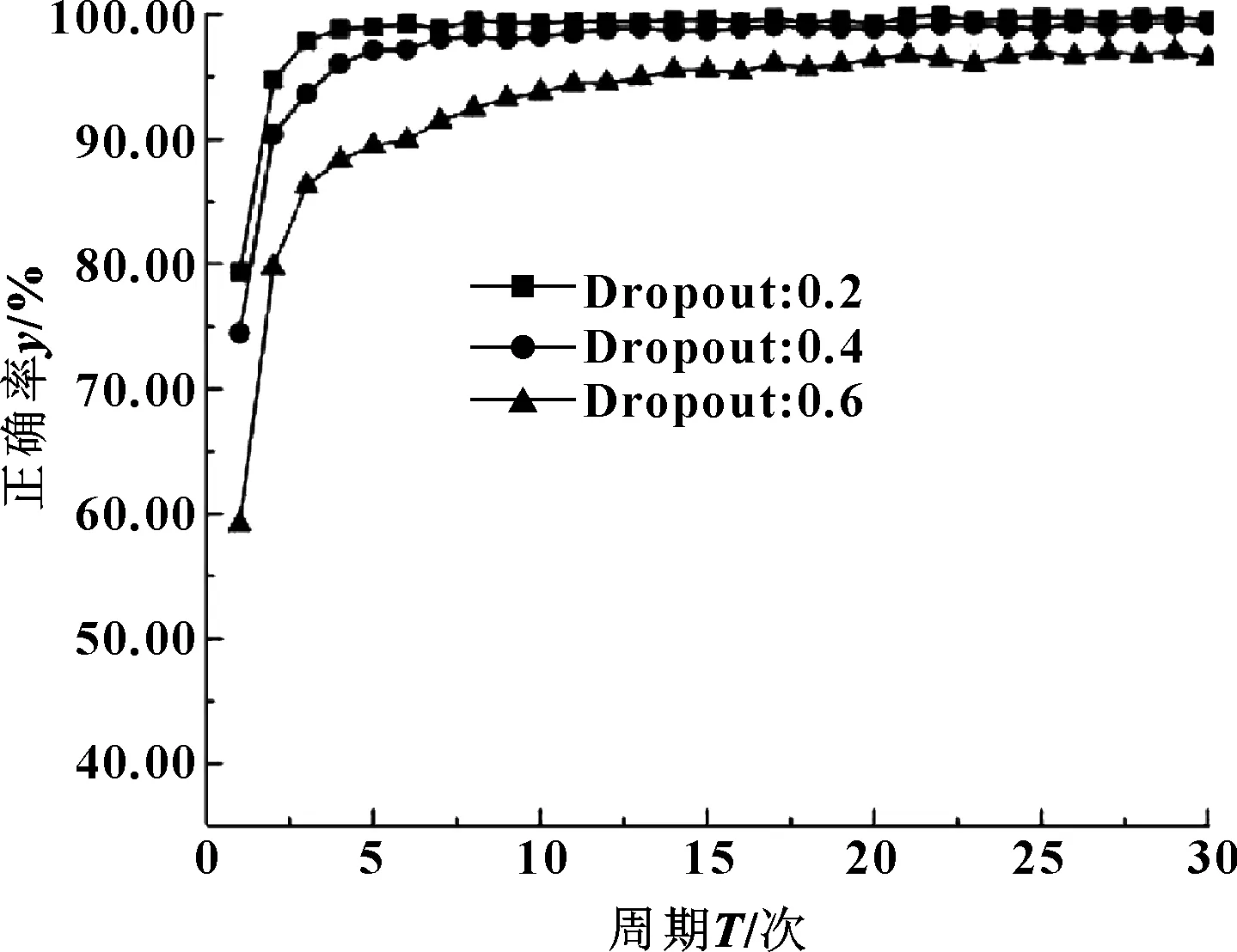
图6 Sigmoid下不同Dropout值对比曲线
图7示出了激活函数为Relu,而Dropout值分别为0.2、0.4、0.6时训练结果。
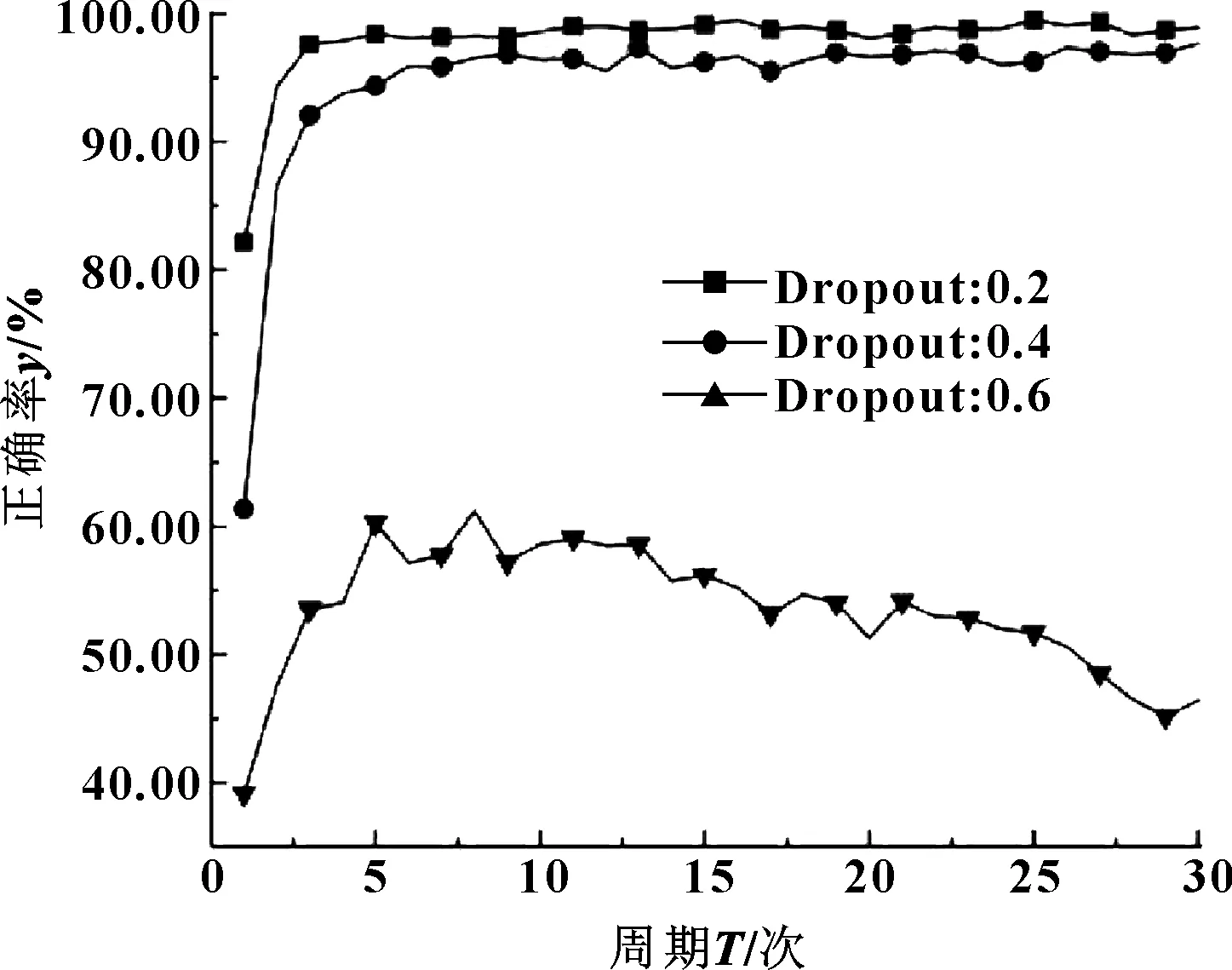
图7 Relu下不同Dropout值对比曲线
表2和表3给出了以上2种情况下模型训练的各项参数设置及量化结果。

表2 Sigmoid下不同Dropout值的结果对比

表3 Relu下不同Dropout值的结果对比
观察图6和图7,结合表2和表3中数据,发现同一激活函数下Dropout值越大,DBN识别正确率越低,其中激活函数为Sigmoid,Dropout值为0.2和0.4时,正确率逼近100%,可能发生了过拟合,Dropout值为0.6时正确率和耗时较理想;激活函数为Relu,Dropout值为0.6时识别正确率过低,为0.2时耗时较大,为0.4时正确率和耗时较理想。将两者横向比较发现,激活函数为Sigmoid、Dropout值为0.6和激活函数为Relu、Dropout值为0.4的识别正确率和耗时均接近。由于Relu函数可避免梯度消失且简单快捷,故文中激活函数选取Relu,Dropout值取0.4。
3.2.2 预训练学习率
设DBN预训练学习率分别为0.001、0.01、0.1、1.0,研究其对模型性能的影响,图8所示为训练结果。
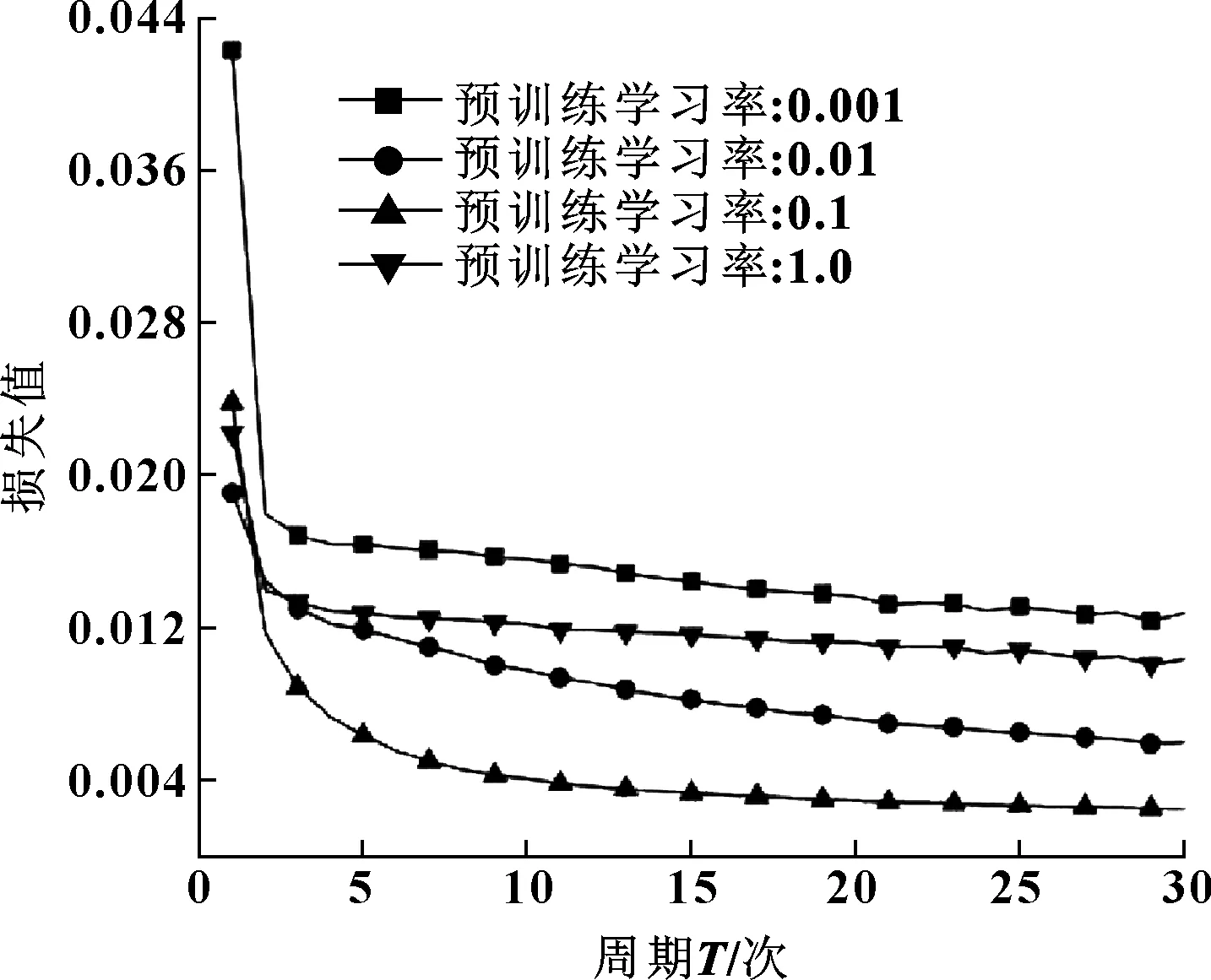
图8 不同预训练学习率对比曲线
图8给出了不同预训练学习率下损失函数的变化趋势,表4给出了训练时各项参数设置及量化结果。
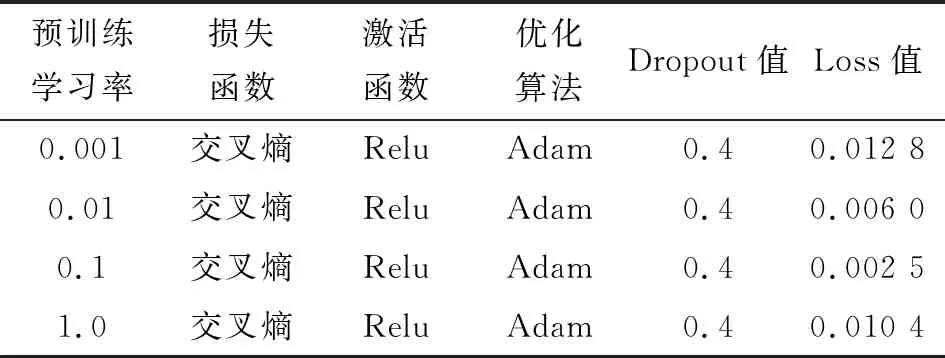
表4 不同预训练学习率的结果对比
结合图8和表4,发现4种不同预训练学习率中,0.1是较合适的值,它在前5个训练周期内即可达到0.001、0.01、1.0训练30个周期时的效果,甚至更好,且它训练完30个周期的Loss值比另外3个均低,故文中预训练学习率设为0.1。
3.2.3 微调学习率
设DBN微调学习率分别为0.000 01、0.000 1、0.001、0.01,研究其对模型性能的影响,图9所示为训练结果。
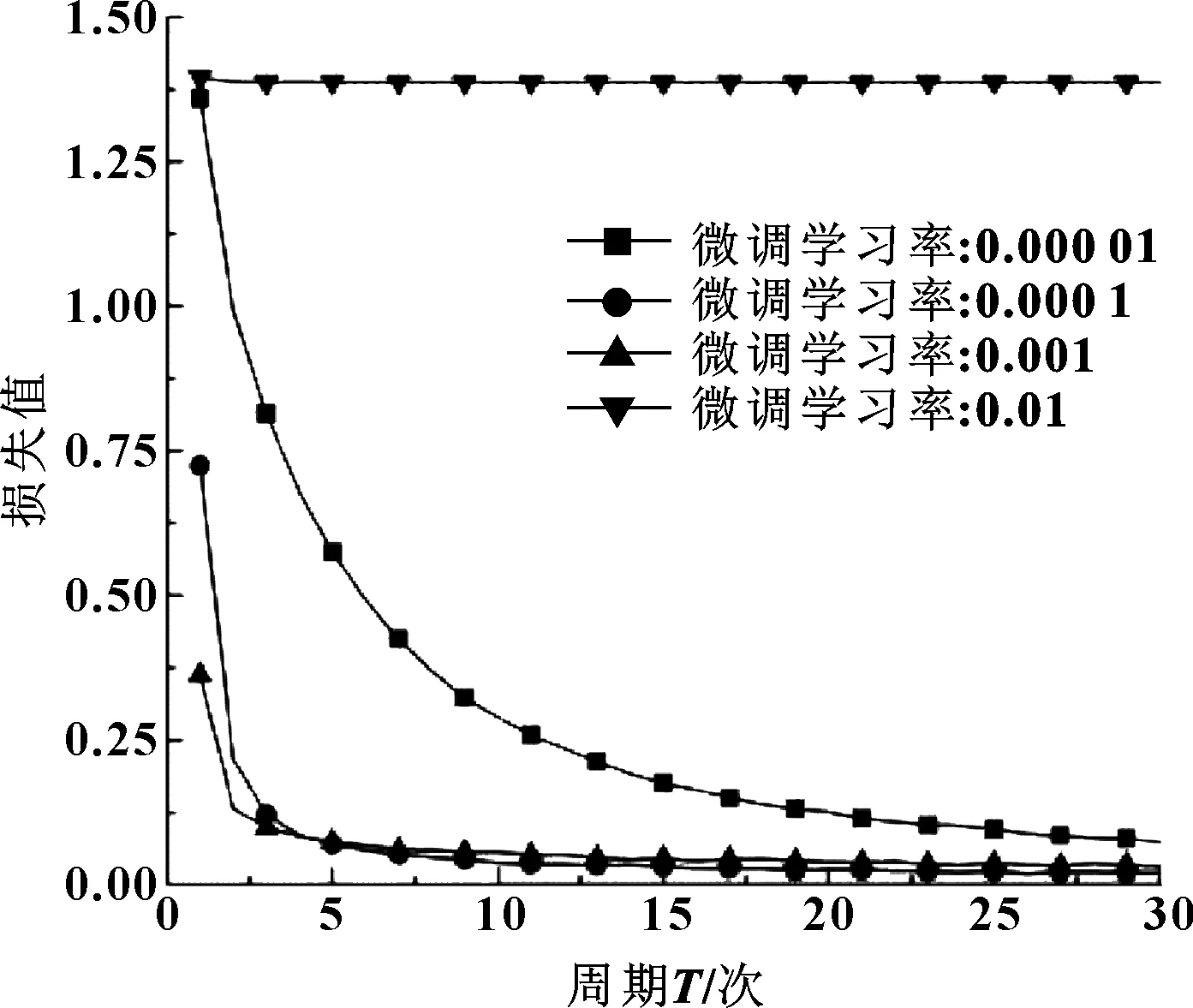
图9 不同微调学习率对比曲线
图9给出了不同微调学习率下损失函数的变化趋势,表5给出了训练时各项参数设置及量化结果。
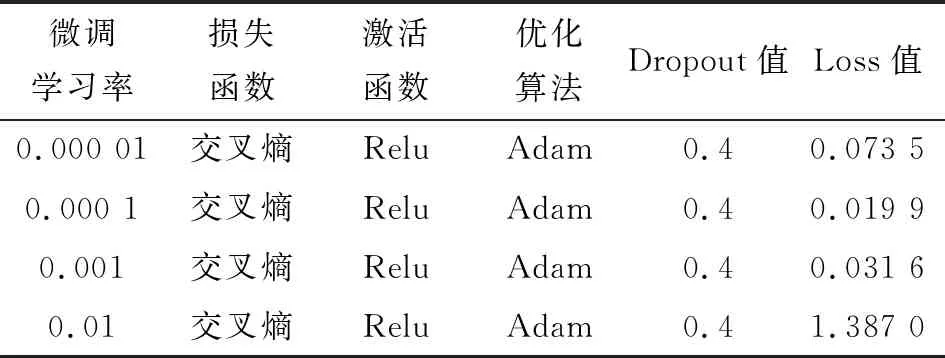
表5 不同微调学习率的结果对比
结合图9和表5发现,当微调学习率为0.01时效果最差,Loss值基本不变;当微调学习率为0.000 01时,虽Loss值逐渐减小,但下降速率很慢;当微调学习率为0.001或0.000 1时,Loss值迅速下降,达到稳定状态耗时小,基本在前5个周期内可稳定。因微调学习率为0.000 1时Loss值最小,故文中微调学习率取为0.000 1。
3.2.4 批训练数
设DBN批训练数分别为8、16、32、64,研究其对模型性能的影响,图10所示是训练结果。
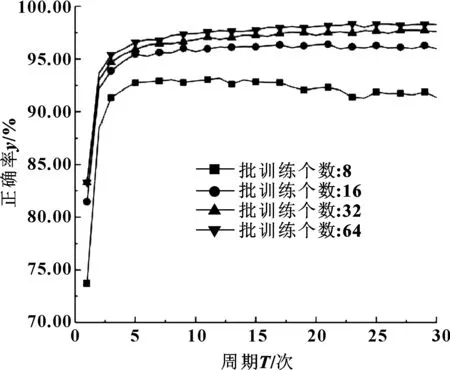
图10 批训练数对比曲线
图10给出了不同批训练数下识别正确率的变化趋势,表6给出了训练时各项参数设置及量化结果。
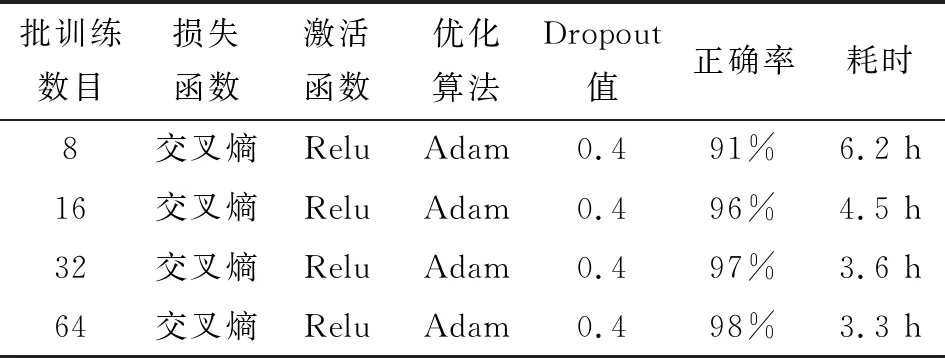
表6 不同批训练数的结果对比
通过图10和表6发现,随着批训练数增大,识别率逐渐提高,且训练时间递减。在合理范围内增大批训练数具有以下优点:(1)计算机内存利用率提高,大矩阵乘法并行化效率提高;(2)每运行一个周期所需迭代次数减少,对相同数量数据集处理速度更快;(3)在一定范围内批训练数越大,其确定的下降方向越准,引起训练震荡越小。对比发现,批训练数为64时训练时间最短且各指标最好,故文中批训练数定为64。
综上,文中DBN模型的最优参数如表7所示。

表7 DBN模型最优参数
表8给出了采用精确率、召回率、F1-score和训练时间作为DBN模型评价指标的具体结果。

表8 DBN模型最终结果
如表8所示,精确率、召回率和F1-score被作为评判DBN模型的指标。其中,精确率表示分类为正的样本中有多少是真正的正样本,召回率表示正样本中有多少被分类正确,而F1-score是精确率和召回率的调和平均数。由表8可知,最佳的DBN模型训练所需时间为3.3 h,精确率、召回率和F1-score值均达到99%以上且极度相近,证明了文中提出的面向铁谱图像智能识别的DBN模型达到了最佳状态。
4 结论
(1)提出了一种基于DBN的设备磨粒铁谱图像智能识别方法。利用DBN特征提取能力提取了铁谱图像特征,利用Softmax分类器实现了故障准确分类,克服了BP神经网络等传统方法的局限性,提高了铁谱图像识别与磨损故障诊断的正确率和效率。
(2)利用铁谱图像数据集对DBN模型中激活函数、Dropout值、学习率和批训练数等关键参数进行了量化研究。当激活函数取定时,Dropout值越小正确率越高,但应防止过拟合;预训练和微调的学习率为0.1和0.000 1时效果最佳;随着批训练数增大,训练时间逐渐下降,模型识别正确率逐渐提升。
(3)经对采集的铁谱图像进行背景色处理、数据增强等操作后,构造了铁谱图像数据集,利用该数据集训练DBN模型并完成测试,结果表明DBN识别率高达99%以上,证明该方法具有潜在工程应用价值。
