异地多活之架构与存储研究
2021-07-22胡宏娟
胡宏娟
中国电信股份有限公司江苏分公司
1 异地多活与CAP理论
(1)异地多活,是指在多个不同物理地域之间同时提供业务流量和商业服务,各个地域之间不是主备关系,各个地域有自己独立的基础设施以及数据中心,业务流量可以不均等地分配在某几个地域之间。与异地冷备相比,其不仅具有更高的成本优势,而且更具有可扩展性。异地多活实际上就是让各个地域同时承担部分业务流量,缓解单一地区的业务压力。与冷备相比,异地多活提供了更快速的业务恢复能力,业务流量可以随时在不同地域相互切换,达到了提供商业可持续性的同时进行流量动态分配的目的。
(2)CAP理论。异地多活涉及分布式系统和数据库,就涉及著名的一致性、可用性、分区容错性(Consistency-Availability-Partition tolerance,CAP)理论。一般CA是无法兼得的,P是无法放弃的,所以所有分布式系统的设计要么是保AP、要么保是CP,如图1所示。
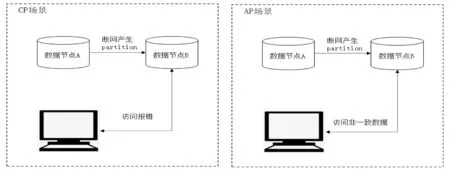
图1 CAP理论说明
2 业界方案研究
多数互联网公司都经历了从单机房、同城双活、异地灾备,再到异地多活、单元化的过渡。本文着重从架构和存储两个方面来讲述。
2.1 单机房
目前的应用一般都部署在公有云平台上,硬件方面(包括网络、电力、散热)都是冗余的,服务方面则是通过集群模式来减少机器、机架故障造成的影响,对于SLA要求不高的应用,基本能满足要求。
单机房部署在整体组网架构中存在单点隐患,一旦机房出现故障,服务只能暂停并等待恢复,灾害性事故导致服务长时间中断所引发的资产损失以及社会效益损失,都是企业无法承担的。所以,BAT等大型互联网公司都会考虑服务的冗余,如“同城双活”或“同城灾备”。
2.2 同城双活和同城灾备
同城双活和同城灾备的差别在于两个机房是否都跑流量。(1)部署方面:当单机房因断网、断电等故障而停止服务,同城机房可及时弥补;而同城机房的物理距离足够近,机房之间通过光纤专线连接,跨机房调度的时延(<3 ms)一般可以忽略不计,在部署方面和单机房相比并未提高复杂性。(2)分层方面:第一,接入层。CDN、4层代理、7层代理、网关,可以选择路由的方式,如随机、轮询、权重、一致性哈希等,也可以选择有目的性的路由策略,如主机房优先、同机房优先、自定义路由规则等。第二,服务层。设计为无状态的,应用之间用SOA框架连通,如Dubbo、Spring Cloud、Istio等,内部可以横向扩展,具备auto scaling能力。第三,存储层(以一般数据库为例,高端存储设备不作描述)。一般互联网公司使用MySQL,数据拓扑架构为Master-Slave,采用主从复制(async或semi-sync),在数据中心切换之前,仅在主数据中心进行写操作,同步到非主数据中心的数据库,便于主库故障时可以手工或自动切换(failover),减少恢复时间。这种架构问题主要是伪双活,当主数据中心故障时,数据的一致性无法得到保障,解决方式是使用分布式数据库,利用Paxos、Raft分布式一致性协议保证强一致。
2.3 异地多活和异地灾备
(1)同城双活+异地灾备架构:同城双活能解决架构上的单点问题,但依然无法摆脱地域性的灾难,如地震、洪水等自然灾害,跨地域部署镜像灾备机房和服务便成为进阶考虑。但大量的跨地域调度,时延往往比较可观,如果在网络设计和带宽方面高可用设计或资源冗余不足,网络抖动往往容易影响业务的稳定性,所以,一般异地备份机房只做灾备,采用非对等独立部署(更小规模、各层独立部署)不承载业务流量,存储基于数据库同步机制进行复制。这种同城双活+异地灾备的架构,一般称为“两地三中心”架构,即2个地域、3个IDC,如图2所示。这种架构适用于中小型应用,由于容灾机房不跑流量,对于数据一致性要求很高的场景有一定风险。同时,扩容和集群伸缩性、计算、存储、网络等资源受限于单地域的容量。

图2 两地三中心架构示意
(2)异地多活架构:地域之间不是主备关系,不同物理地域之间同时提供业务服务,不涉及故障切换failover的工作(流量会有策略调度)。failover的灾备策略往往不是自动化的,而且一般比较复杂,需要测试演练,所以维护成本、切换风险很高。异地多活架构如图3所示。异地多活下,各个地域机房独立运行,流量可以按策略调度到各个地域和可用区,与异地灾备相比,其优势在于:(1)成本更低,因为两个机房都跑流量。(2)复杂度更高,因为需要涉及流量的调度策略。(3)若不同机房的流量产生切换,则会带来更复杂的数据同步问题。(4)伸缩性好,服务和数据可以相对平衡负载在各个区域,不受单地域资源限制。需要说明的是,并不是所有应用都需要做异地多活,一般对主链路业务、SLA要求较高、扩容频繁的业务优先做,否则方案会比较复杂,工作量也比较大。
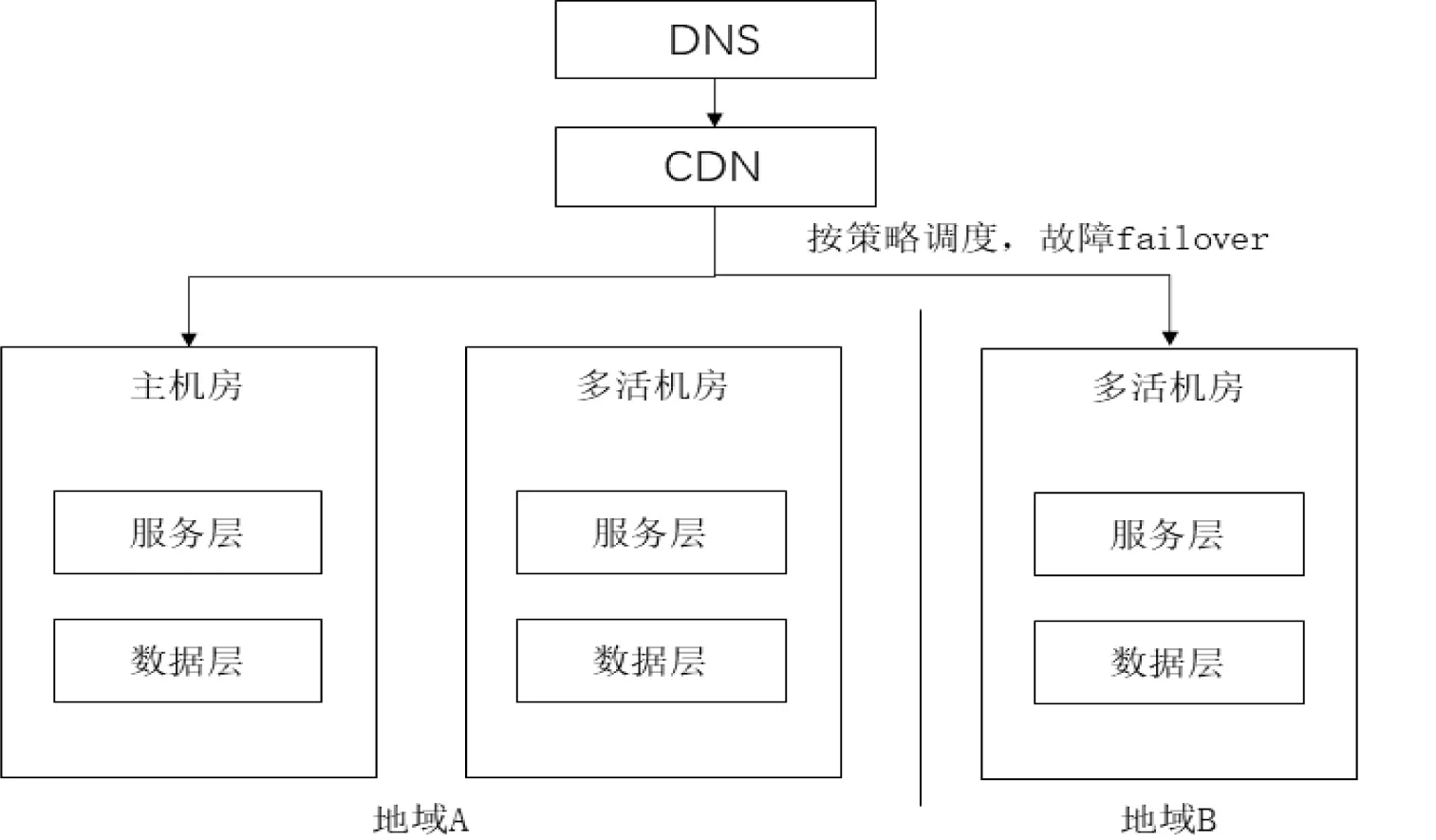
图3 异地多活架构示意
2.4 单元化
实现了异地多活,也并不代表到达了终点。异地多活主要的问题在于跨地域延时,业界目前的解决方案主要集中在网络层面(如搭建BGP网络、CDN加速等)。在架构层面,阿里2016年提出了 “单元化”概念,让特定user的请求和数据收敛、封闭在同一个IDC,单元高内聚,尽量减少跨区域访问,即“单元封闭”。一些流量较小的长尾应用,仍然只在中心部署,配套容灾方案。
单元化的策略是按照某个业务维度拆分用户,例如,线上商城和支付App一般是按照会员ID(userid)取模划分单元的,物流一般是按照user所处的地域划分。每个IDC根据URL设定路由策略调度流量,并封闭服务和存储,只承载本单元的请求。单元化架构如图4所示。

图4 单元化架构示意
2.5 数据库的高可用
对于传统数据库,需要额外配套HA策略来切换Master和Slave。MySQL在本区域或者跨区域的高可用,可以通过主从复制(replication)加多副本(replica)实现,一个实例做Master,其他实例做Standby,主故障即可切换,其他可以做本区域或者跨区域的复制,仅只读,扩展读能力。数据库集群高示意如图5所示。

图5 数据库集群高可用示意
假设有5 000对MySQL主备实例,又有一套用来切换MySQL主备实例的HA工具,要做到任意一台主库宕机,HA都能够在极短的时间内切换主备,需要实现以下功能:(1)部署监控代理。为了监控各个主库的状态,需要在各台机器上部署Agent以采集实例健康状态。Agent以一定时间不断向HA汇报实例的健康状态(Heartbeat)。(2)Heartbeat与仲裁节点。这些实例的健康信息如果存放于一个节点上,也存在单点风险。因此,需要把风险分散到多个节点上,被称为仲裁节点。(3)数据一致性。
到此,HA已经是一个分布式系统,与ZK息息相关,因此,对于分布式集群的管理,最终还是要通过Paxos数据一致性协议。基于这种思路,业界涌现了很多分布式数据库的解决方案。
2.6 数据一致性
对于传统关系型数据库,无论是Oracle还是MySQL,最通用的做法是通过存储共享或者日志同步来保证。
(1)Oracle的存储共享。比较著名的是Oracle的真正应用集群(Real Application Cluster,RAC),基于share everything架构,比如,3个节点的RAC系统在CPU、内存上是做了扩展,但是为了保证数据强一致性,存储做了共享。这种架构最大的弊端是各个节点争用热点块而引起的“GC”(Global Cache)等待事件。引起“GC”事件的原因是同一时间只能有一个节点在更新同一个块。Oracle RAC在Fusion Cache层做了内存锁,用以协调各个节点对同一个Block的Update操作。Block有资源Master概念,只有得到Master的授权,才能对块进行更改。因此,在架构设计上,Oracle引入了动态资源管理(Dynamic Resource Management,DRM)。另外,为了解决集群的脑裂(Brain Split),Oracle引入了基于共享存储的Voting Disk,来对Brain Split进行仲裁。这种架构显而易见的弊端是对硬件依赖非常严重,任何存储介质的异常都必须进行容灾切换,并且无法跨机房部署,做不到IDC间的容灾。而基于Paxos一致性协议的分布式数据库系统很容易做到,只需将其中一个副本存放于其他IDC中即可。
(2)日志同步。对于性能的损耗较大。无论是Oracle的Data Guard还是MySQL的Binlog同步,对于Master主库的TPS有明显的损耗。每次事务commit,必须要等到从库ACK并成功应用后,主库再返回给用户事务提交信息。业界有非常多的优化方案,如日志缓冲区锁优化、异步化、减少不必要的context switch等,但网络开销上即使采用万兆网、调优网卡软中断模式,也很难得到改善。
以MySQL为例,如果采用异步复制(Replication),由于其异步特性,若数据未完成同步即切换,会导致数据丢失,PRO>0。此时,被提升为新主库的数据自然与之前的不一致,如果在同步时停止服务,可用性就会受到影响,业务是无法接受的。
为改善Replication带来的数据不一致问题,MySQL提供了半同步复制(semi-sync),即主库需要接受从库的ACK(代表同步到Binlog),才成功返回客户端。对于幻读,在MySQL 5.7版本之后,又可以通过设置AFTER_SYNC或AFTER_COMMIT模式来解决,需要注意,开启semi-sync会影响写性能。MySQL半同步复制AFTER_SYNC和AFTER_COMMIT两种模式如图6所示。

图6 MySQL半同步复制两种模式示意
开启semi-sync,也不一定PRO=0,非高负载select的场景下,MySQL通常开启InnoDB引擎,采用2PC进行提交,在事务Prepare阶段写完Redo log,事务不是commit状态,需要走到Server层面,Binlog写成功才进行解锁,清理Undo log的commit工作,再返回客户端。
MySQL支持用户自定义在commit时,解决如何将log buffer中的日志刷到log files中的问题,主要方法是通过设置变量innodb_flush_log_at_trx_commit的值来控制Redo Log的刷盘策略,如图7所示。其中,“0”:commit时,写入log buffer中,每秒写入os buffer并同步fsync刷盘,若进程crash,丢失1 s数据。“1”:默认模式,commit时,写入os buffer并同步fsync刷盘,安全,但需要等待磁盘IO,性能差。“2”:commit时,仅写入os buffer,每秒fsync()将os buffer中日志写入到log file disk中,比“0”安全,比“2”快,若宕机,丢失1 s数据。

图7 Redo Log的刷盘策略示意
通过调整参数innodb_flush_method的值来控制Redo Log的打开、刷写模式。这个参数有4个值:(1) fdatasync:默认,调用fsync()去刷数据文件与redo log的buffer。(2)o_dsync:InnoDB会使用o_sync方式打开和刷写redo log,使用fsync()刷写数据文件。当write日志时,数据都write到磁盘,并且元数据也需要更新,才返回成功。(3)o_direct:InnoDB会使用o_direct打开数据文件,使用fsync()刷写数据文件跟redo log,write操作是从MySQL InnoDB buffer里直接向磁盘上写。(4)all_o_direct:与o_direct差别在于redo log也直接向磁盘上写。这4个策略的选择最终影响的是CPU、处理性能和响应时间,如图8所示。

图8 innodb_flush_method参数策略示意
Sync_Binlog控制Server层面Binlog的刷盘策略。在事务prepare阶段,当MySQL进程Crash或者系统宕机、Binlog是否传输到从库、相应的文件有没有落盘,都会造成客户端、主库、从库的数据不一致。MySQL的主从加上刷盘,是不能保证数据强一致的。如果采用semi-sync+强制刷盘的策略,可以做到不丢数据,但是MySQL实例之间的数据一致性无法保证。比如,redo log或者Binlog任意一方丢失,那么客户端会感知失败,主库恢复时会rollback,如果Binlog同步到了从库就生效了,从而出现主从不一致。
为了满足可用性要求,减少数据不一致,可以优化策略:主库宕机恢复后,先禁写,避免新数据写入主库导致不一库,等把gap diff apply到从库上,如果没有冲突,再恢复;否则,采用手工对帐订正数据。
可用性不强求覆盖100%的用户,原则上满足大部分用户才是关键。面对跨地域的高时延和网络抖动,远距离同步Binlog有很多局限性。所以,存储层面的数据同步在业界会采用DRC中间件解决,比较常用的是Otter和DRC(Data Replication Center)。对比Otter,DRC更关注业务的划分,可以实现单元内封闭,而Otter只是在纯数据库层打通的技术。这类中间件的原理:从数据库同步Binlog,异步的将数据进行解析、过滤、标准格式化(DRC Message)、复制远程传输,中间件本身可以做持久化,便于实现一次订阅,多点分发。可以在事务一致性的前提下提供秒级的DB同步,但其注重AP,牺牲了异地一致性。
在单元化异地多活的架构里,DRC可以承担单元和中心之间的数据复制功能,如可以采用写中心、读单元的模式,中间数据广播到各单元,单元通过中心做数据同步;也可以各单元部分写,相互同步。请求可以做单元封闭,单元内的数据可以是全量的,支持区域故障时的机房切换。
2.7 分布式数据库
比较熟悉的分布式数据库有开源的TiDB、阿里云的RDS等,基于Paxos协议或者Paxos简化变种Raft,来实现分布式系统的数据最终一致性。Paxos有两种实现思路:(1)将Paxos与实际的数据节点独立出来,如zk架构,比较简单,但是增加了Leader和Follower的通信,带来了更大的时延。(2)直接将Paxos实现到各数据节点的组件中,好处是时延低,但技术难度高,比如,蚂蚁的OceanBase、Google的Spanner等。
分布式数据库对数据的每次修改都看作一次增量log,再在存储上套一层Raft协议。例如,3个节点的集群,Raft的Leader负责写,Leader的事务日志同步到follower,超过多数派(majority quorum)落盘后,再commit。虽然延迟明显高,但小幅延时却可以保证数据一致性,而吞吐可以靠集群和拆分解决。以阿里云的RDS为例,通过Raft状态机控制事务,会带来明显的延时问题,一般部署在同地域,依赖DRC(DTS)做异地复制。
3 结束语
从当前业界数据中心级的多活架构来看,私有云的部署一般以同城双活或异地多活为主,更大规模的公司会尝试采用单元化的方案来封闭数据和流量,减少异地流量的调度导致的网络抖动,而造成业务的不稳定。但随着公有云和混合云方案的发展,如今的技术架构又呈现了不同的发展趋势,以同城双机房的私有云配合多云的混合云方案,将成为另一种数据中心级容灾的新趋势。很多传统企业或者较小的企业可以根据业务特性来选择系统架构方案,由于异地多活的技术门槛高、投入成本大、运维要求高,并不适用于所有企业。就笔者所负责的系统而言,一般采用同城双活,即可基本满足业务要求。
