面向用户地理位置的电信大数据分群方法研究与实现
2021-07-19蔡一欣刘颖慧
蔡一欣 刘颖慧 李 堃 廖 军
中国联通研究院 北京 100176
引言
近年来,随着我国数据通信和移动互联网的高速发展,不论是传统行业还是新兴产品行业,数据逐渐发展成为了互联网技术的重要核心。在当前的大数据时代,要率先与互联网开展融合并取得成果,首先要抓住大数据中所隐含的规则,才会有可能抢占先机。相比于以往的传统数据,大数据在技术上具备的特点包括数据规模大、数据类型繁多、数据价值和信息密度相对偏低、数据处理速度快、对时效性要求高[1]。
目前,针对大数据膨胀所提出的各种有效解决行业发展问题的创新方法,是各企业持续发展的有力支撑。移动互联网和互联网所提供的各种个性化服务,要求不断改善和提升使用者的体验。一般对于用户大数据的处理,可以分为事后风险和追溯,在用户大量的数据中挖掘信息,为企业提供决策,从而提升用户体验。例如,以阿里巴巴电商公司为主要代表的互联网电商搭建了一个大数据处理系统,用于实时统计和分析消费者的行为,细分客户随时更新自己的商品推荐列表[2]。以美国T-Mobile为主要代表的运营商已经开展了大数据分析的技术研究工作,通过集成数据进行综合分析,确定消费者流失的原因,根据分析结果优化网络布局,为广大消费者和企业提供了更好的服务和体验。用户的数据分析通常是量级的处理,利用用户的天然特征和行为特征,纵向对批量用户进行分析,从而提高数据处理的速度,通常分析用户属性的方法就是用户分群。运营商目前主要的用户分群场景及规则,大多是通过用户的消费习惯和浏览视频、信息等行为偏好提取出群体类别,对群体进行定点营销。针对用户的消费特征,将用户分为高中低端用户,结合消费类别,又细分为流量型、话费型用户,在此基础上对不同消费倾向的群体匹配对应的营销策略[3]。例如,韩国通信公司 SK telecom新成立名为SK Planet的公司,通过移动互联网和大数据分析等技术对于所有用户的韩国网络网页浏览器的使用和用户体验记录进行数据分析。
电信行业数据主要是个人的基本信息、用户的电信消费记录以及活动轨迹,具有数据量大、信息密度低的特点。仅根据静态的信息,通常无法对用户进行精准画像,运营商需要围绕最迫切的业务开展行动,从市场活动中增加收入。通常与用户活动关联度最高的是活动轨迹,通过对用户活动轨迹进行分析,定时定点发放广告,引导用户自己做决策,把握控制权,是目前运营商在用户分析领域另辟蹊径的途径之一。
大数据的实时性、无限性、突发性等特征决定了传统的数据计算理念不再被广泛地应用,取而代之的是针对特定数据类型、特定场景下的大数据处理算法。电信大数据的处理在实时推荐、用户营销等场景中的地位日渐凸显,可以帮助运营商提升营销效率和优化流程。对于用户地理位置的数据分析,在技术上和应用场景上都面临着前所未有的挑战。
1 大数据分群方法
对于电信大数据中用户地理位置分析,目前的研究大多基于用户位置数据,开展用户工作地识别[4]、同住宅区筛选[5]、流动人口数量统计[6]等方面的应用,最常用的研究方法是轨迹聚类。针对地理位置的聚类算法是在大数据挖掘过程中获取信息的重要途径和方法之一,经典的轨迹聚类方法大多采用基于距离和密度的方法判断轨迹的相似性。聚类分析需要使用的大量数据没有任何类别标记,算法需在原始数据的处理中探索得出一定规律,最后计算出符合这些规律的结果。近年来随着机器学习和人工智能的发展,聚类算法出现了基于人工神经网络、支持向量机以及基于核聚类的方法。需要特别指出的是,这些改进的聚类的准则函数一般由人为设定的终止条件实现,而这些终止条件并没有统一的标准。由此可见聚类算法具有一定的主观性,需要根据实际情况对聚类所揭示的数据结构进行进一步归纳总结。因此,本文主要以聚类算法为主,研究其在聚类结果隶属程度方面的改进过程[7]。
常见的聚类算法包括K-均值(K-Means)、模糊C-均值聚类(FCM)、层次聚类(Agglomerative clustering)等,具有灵活、快速、应用范围广等特点,前期需要对数据进行预处理和特征选取。K-Means是一种具有排他性的目标聚类方法,即一个目标的数据仅归纳为一个特定的类别[8],分群数随机产生,K值确定较为困难,且对于初始聚类中心非常敏感,容易陷入局部最优解。层次聚类算法的初始对象是所有目标,将两个距离最近的目标合并,不断重复直到达到预设簇的数目为止[9],具有相似度容易定义、可以发现类的层次关系的优点,但是时间复杂度大,聚类过程不可逆。FCM模糊了目标聚类的边界,结果可分为多类,在应用中更能描述实际的情况,然而抗噪性较差、容易出现局部收敛的聚类结果[10]。实际情况下,用户的活动点是复合的,当用户活动范围较小时,一个活跃点可能涉及多个类型的地点,用户所属类别不应是单一的,因此采用FCM算法,能够更加贴合现实情况。
针对现有的运营商在用户大数据处理中面临的问题与不足,本文在地理位置变化的实时推荐场景下,提出了一种基于改进FCM的大数据分群算法,可以根据用户实时位置、历史位置及个人轨迹的地理信息判断不同用户在地理空间尺度的相似性,对用户进行分群。此外,本文还针对该算法进行实际的大数据测试,分析不同聚类算法对分群结果的影响,验证改进FCM算法的有效性。最后针对该大数据分群算法对业务需求的适配性进行展望,帮助在用户做出决定之前推出符合用户兴趣的合作业务,便于针对不同群体进行定向营销。
2 面向用户地理位置信息的大数据分群方法
大数据的应用广泛且涉及场景繁多,对于电信运营商来说,大数据在中国的电信移动网络产品和服务行业市场上具有重要作用,特别是在精准市场营销和实现客户关系有效管理等方面。本文基于大数据的特征,设计了一种面向用户地理位置信息的大数据分群方法,包括数据预处理、改进FCM分群算法并确定分群评价指标。
2.1 数据预处理
针对用户地理位置的特点,对数据集内容进行预处理,降低数据集内容的不平衡性,以此提升算法在非平衡性数据集上分群的准确度和可靠性。
1)获取用户位置及历史轨迹
对于用户的位置数据,提取用户近1个月的位置日志,以日与星期为单位,对数据进行预处理。以位置数据中有效地点为圆心,半径200m的区域为策略区,有效到访地点为用户设备进入策略区并停留5min及以上的位置。从位置日志中提取用户有效到访地点,构建位置向量P={p1,p2,…,pn},每个向量包含三个维度,纬度(Latitude)、经度(Longitude)和时间戳(Time)。根据时间戳连接位置点,构建用户活动历史数据。
从用户活动数据中提取活跃点,活跃点为停留1h以上或者每周到访3次以上的区域。通常活跃点都具有一定特殊含义,例如工作地点、学校、家、健身房、超市等用户经常停留的地方。以一个用户的活动轨迹为例,每个矩阵表示用户在不同时间的位置变化。一个用户A一天到访Y个地点,可建立一个3×y的矩阵AY,表示用户到访地点的纬度、经度和时间,如公式(1)所示,其中PY=[LatY,LonY,TY],代表用户到访第y个地点的经度、纬度及时间。
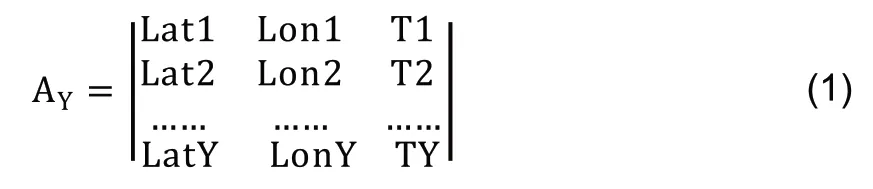
2)构建活跃点与时间戳矩阵
标记活跃点H后,可以建立活跃点矩阵HM。用户A本月共有m个活跃点,可建立一个2×m的活跃点矩阵HM,表示用户活跃点的纬度、经度,如公式(2)所示。
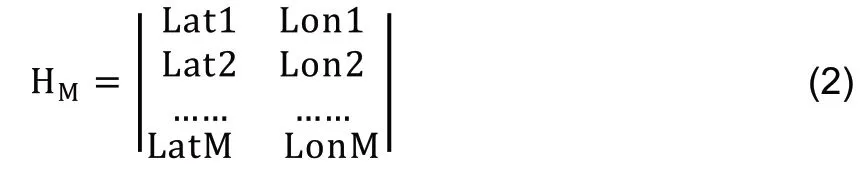
用户A与用户B的活动轨迹如图1所示,实心点表示策略区,空心圆表示活跃点。
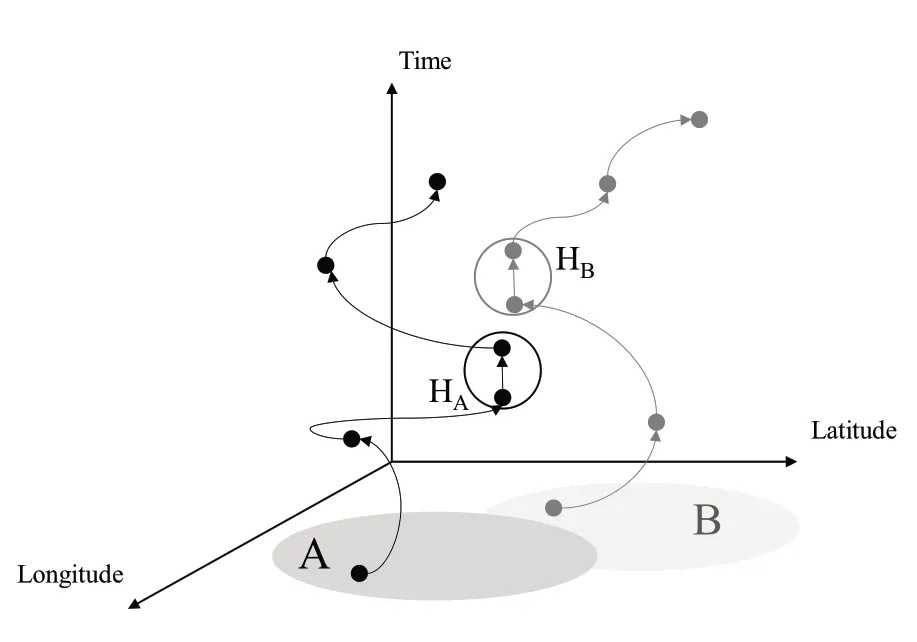
图1 基于活跃点的用户历史轨迹
提取同一时间戳下所有用户的活跃点,构建时间戳矩阵TS。在某个预设时间戳信息TK,提取TK时刻的所有用户设备的活跃点的经度和纬度。设定在时间戳为TK时,所有用户包括S个活跃点,则根据S个活跃点的经度和纬度构建时间戳矩阵TS,其中,S为大于或等于1的整数。例如,可采用公式(3)表示TK时刻的时间戳矩阵TS。
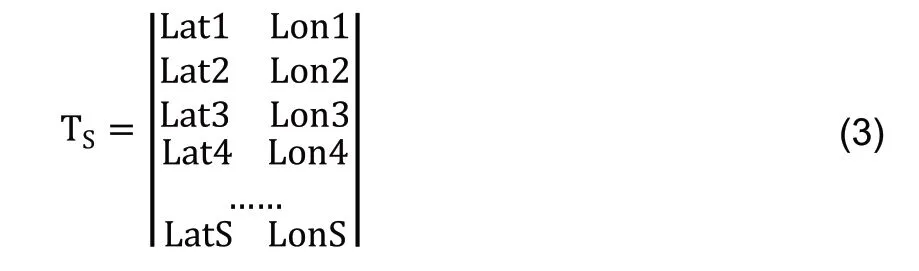
用户A与用户B的活动轨迹如图2所示,实心点表示策略区,空心圆表示同一时间戳下的用户历史位置。
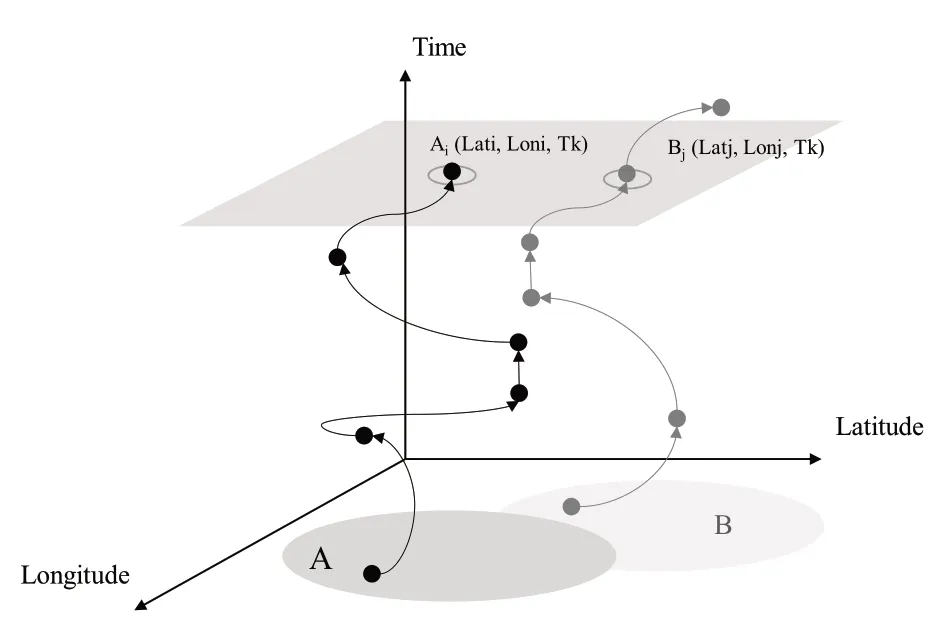
图2 基于时间戳的用户历史轨迹
2.2 FCM算法改进
本文对FCM进行了两个方面的改进。其一,在运行环境方面,将FCM与Hadoop、MapReduce等计算框架有机结合,实现分布式FCM方法,提高算法的处理效率。其二,在空间隶属度方面进行改进,具体方法如下:在FCM聚类算法中一个样本可以不同程度地属于多个类簇,更能描述实际情况中的现象[10]。FCM的传统算法流程如下:首先输入0数据集,每一个样本都有p个特征,输出为一个c行n列的矩阵U,n为数据集中所有样本个数,c为聚类的数目,矩阵U代表分群的结果,表示该样本对该类别的隶属程度[11]。算法流程如表1所示。

表1 FCM聚类算法流程
用户的地理位置数据在处理时,对于策略区与活跃点的判定存在一定模糊的范围,本文基于上述FCM算法,结合隶属度平滑更新方法,对算法进行改进。
将公式(2)中的经度、纬度和时间信息利用线性变换进行标准化处理,使经度、纬度和时间信息都处于区间[0,1]内,得到标准化矩阵。将标准化矩阵中的n个用户的活跃点信息提取出来作为样本数据的集合,例如,样本数据集合中的第i个样本数据记为i为大于或等于1且小于n的整数,n为大于或等于1的整数。
输出c行n列的矩阵U,表示相似性判断结果,每一列表示的是该用户的活跃点矩阵对该分群结果的隶属程度。
3 实验验证
本文对改进的FCM在基于用户地理位置数据的分群场景下进行了测试与对比。测试了模糊加权指数m对于分群结果的影响,以及改进FCM与未改进FCM、K-Means聚类、层次聚类在相同条件下的分群表现。
3.1 实验数据
实验采用数据来自LBS服务平台,在2017年2月至2017年10月期间,该平台用户通过登录共享自身位置信息,平台使用公共API技术收集用户移动端常用位置信息[13]。该数据集包含上万个用户,共计400余万条签到信息。筛取相关字段模拟通信用户的地理位置信息构成实验数据集,数据集包括15 000个用户的有效数据,数据示例如表2所示。
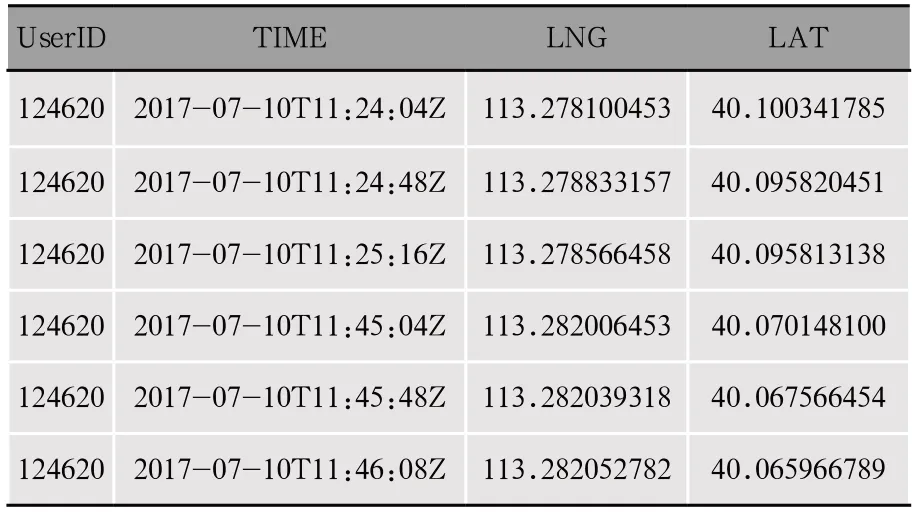
表2 数据字段示例
3.2 实验设计
为了模拟改进的聚类算法实现大数据分群的过程并证明方法的有效性,在局域网环境下基于虚拟机搭建Hadoop虚拟集群,如图3所示。
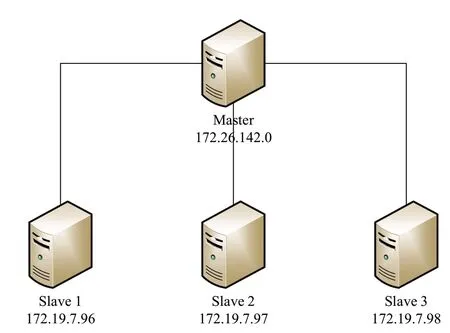
图3 集群架构图
测试集群由4台机器构成,包括1台主控节点和3台从节点,系统硬件配置均相同,如表3所示。
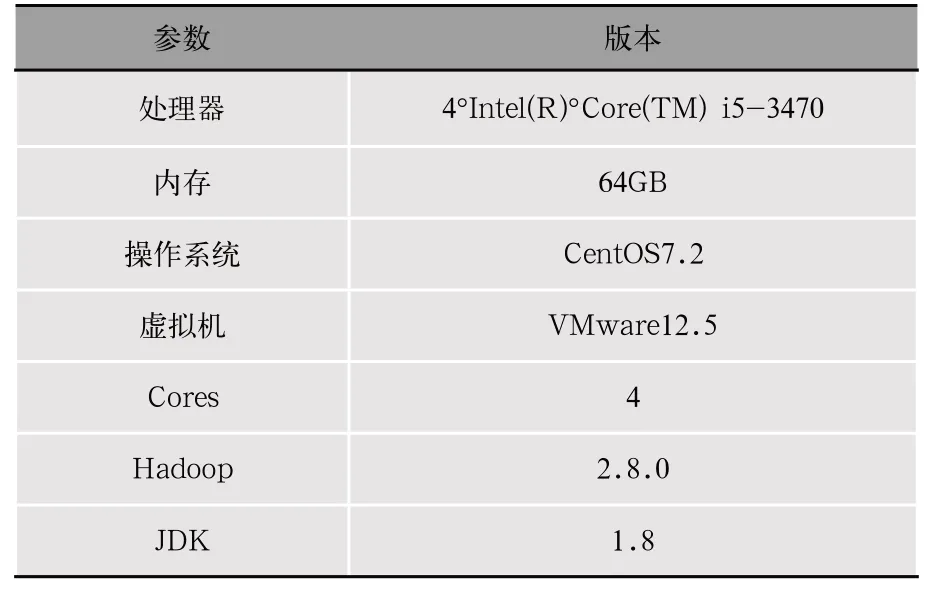
表3 集群配置
实验比较了改进的FCM算法、K-Means聚类算法、层次聚类算法在数据集中的聚类效果,以及不同的模糊加权指数m对于分群效果的影响。
为验证改进FCM分群算法的有效性,本文通过RI指标和NMI信息两个评价指标对算法进行评价,如公式(4)、(5)所示。

其中,a代表有不同标签且分群结果属于不同分群类别的样本数量,b代表有相同标签且分群结果属于同分群类别的样本数量,n表示样本总量,RI表示分群正确的比率。
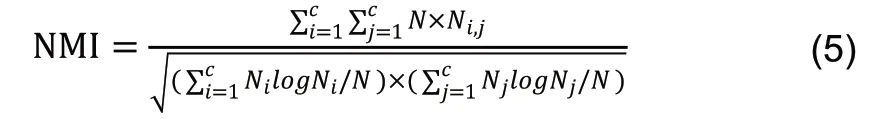
3.3 实验结果及结论
利用实验数据集进行实验,比较改进FCM算法与K-Means聚类、层次聚类算法在m值不同的情况下的对用户基于地理位置的活跃点进行分群的效果,性能表现如表4所示。结果表明改进FCM算法的分群效果显著好于K-Means算法、层次聚类算法。对比各个算法在不同模糊加权指数m下的表现,结果表明m对于分群结果具有一定影响,当m=2时改进FCM算法和其他算法均可以得到较好的分群效果。
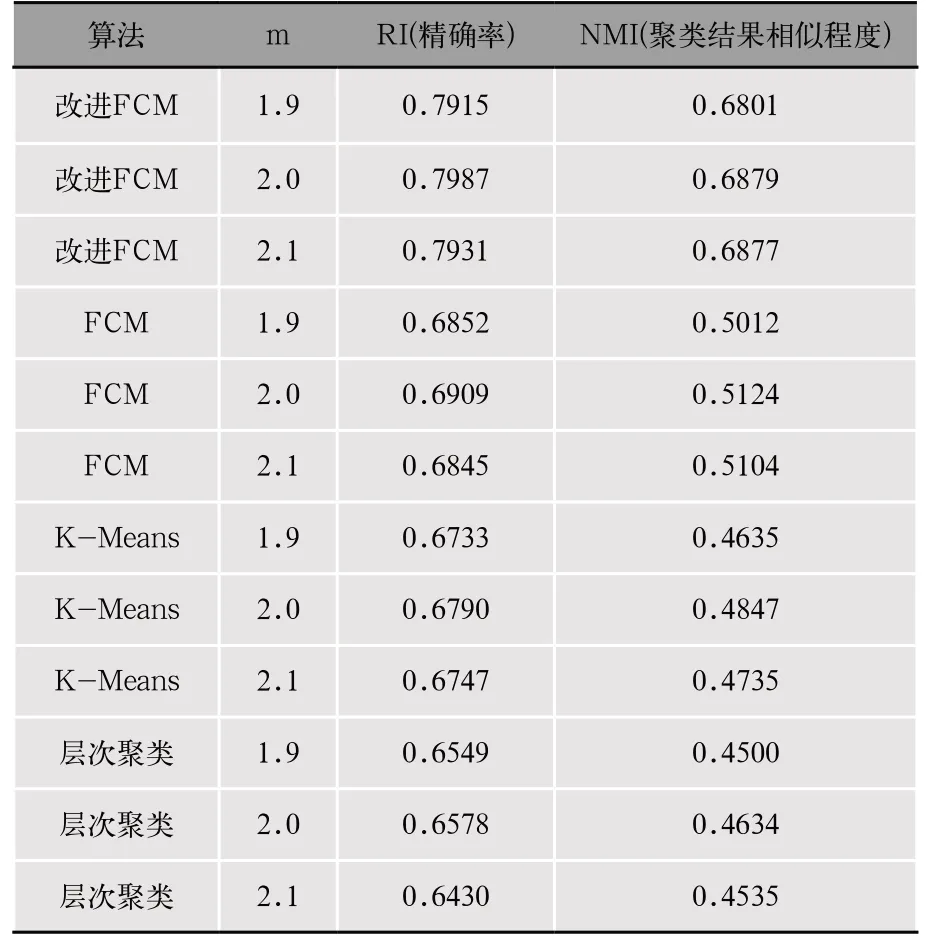
表4 不同分群方法的性能表现
对比m=2时,改进FCM与其他算法在精确率与聚类结果相似度上的表现。传统FCM算法与K-Means算法、层次聚类算法的精确率与聚类结果相近程度差别不大,反而K-Means算法在精确率上具有最好的表现。改进的FCM算法在精确率与聚类结果的相近程度上均有了明显的提高。相较于K-Means算法,改进的FCM算法精确率提高了17.62%,相较于传统FCM算法,改进FCM算法聚类结果的相近程度明显提高了34.25%。
综上所述,经过改进的FCM算法能一定程度上改善处于边界上的活跃点矩阵的分群效果,从而能够更加客观地反映样本属于该类别的隶属度,在面向用户地理位置信息的场景下能够较好地进行大数据分群。
4 总结和展望
本文设计并实现了一个面向用户地理位置数据分析场景的大数据分群方法,利用用户历史位置数据构建个人活动轨迹,绘制用户活动轨迹图,建立用户高频活动点日志。根据轨迹图和高频活动点,建立活跃点矩阵,改进FCM算法判断不同用户在地理空间尺度的相似性,对用户进行分群。在Hadoop计算框架下测试改进FCM、K-Means、层次聚类三种方法在同一数据集中的表现,得到RI、NMI作为测试指标,以图表的形式分析改进的FCM分群方法的性能。实验结果表明,改进的FCM算法的分群效果显著好于未改进的FCM算法、K-Means聚类、层次聚类算法;模糊加权指数m对于聚类算法均存在一定影响,当m=2时三种算法均能够达到较好的分群效果。
电信大数据种类繁多、数据量庞大,从海量数据中挖掘价值并帮助企业决策成为重要难题。未来将从以下几个方面进一步开展研究,为运营商在用户数据挖掘方面提供机会。一是将改进FCM算法应用于不同场景下用户大数据分群。二是测试除模糊加权指数m外,隶属度函数中加权指数s、t对于分群结果的影响。三是与流式大数据处理方法相结合,扩展数据源到用户实时地理位置数据,从而进行更加快速、精准地定位客户需求,为客户运营提供决策参考。四是拓宽应用场景,将用户活跃点的分群与用户消费水平、采用的电信产品等信息结合,构成社会关系网络,细分用户标签,提高客户营销的精准度。
