基于非迭代训练层次循环神经网络的快速文本分类算法
2021-07-16方自远
方 自 远
(河南农业职业学院 河南 郑州 451450)
Non-iterative training Adversarial training
0 引 言
在人们生活和社会生产的诸多领域中,出现了大量自媒体类型的应用[1],如时尚领域的小红书、体育领域的虎扑、视频领域的哔哩哔哩,以及咨询服务领域的知乎等[2]。在这些应用中,大量的普通用户和意见领袖通过个人账号按照规定的格式上传文本内容、图像内容和视频内容[3],在用户上传内容的过程中往往需要指定该内容所属的类别,从而便于应用的管理和维护[4]。但在用户指定类别的过程中常常出现错误,而这些错误直接影响后续自动推荐服务的性能。为了解决该问题,许多应用集成了自媒体上传内容的类别检查程序,纠正错误的类别标注[5]。
文本内容是许多自媒体应用的重要组成部分,提供了关键的信息,因此区分文本内容的类别是其中的重点研究方向。在传统的文本分类方法中,基于中心的文本分类方法是一种高效率的方法[6],也是目前满足在线分类条件的主要方法,此类方法利用一些统计方法建模训练语料库和训练样本集的分布,然后利用距离度量方法将文本分类。此类方法包括许多不同技术的结合,包括随机森林[7]、k-近邻[8]和k-means[9]等分类器,以及模糊集分布[10]、字典分布[11]和粗糙集[12]等相似性度量方法。此类传统方法在时间效率上具有巨大的优势,但是在分类准确率方面存在明显劣势,尤其在处理高维文本数据集时,其分类准确率和时间效率均出现明显的下降。
深度学习技术具有强大的非线性学习能力,在许多工程领域内取得了成功[13]。许多专家应用深度学习技术对文本进行分类,包括:深度神经网络[14]、卷积神经网络[15]和循环神经网络等模型。循环神经网络在文本分类问题上表现出较好的效果,但传统的循环神经网络对于文本特征的拟合能力依然不足。近期许多研究将分层注意方法[16]引入循环神经网络,分层注意方法将文本分割为段落,再利用神经网络并行地处理每个段落,该方法明显提高了文本分类的性能。但许多研究表明,分层注意方法导致神经网络的参数出现大量的冗余,导致明显的过拟合问题[17]。
为了利用分层注意方法的优点,同时解决训练过程的冗余参数和时间效率问题,提出基于非迭代训练层次循环神经网络的快速文本分类算法。本文的工作主要有两点:① 提出一种对抗训练算法,为词汇和语句表示增加扰动,从而缓解过拟合问题。② 给出一种非迭代循环神经网络的训练算法,提高模型的训练速度。
1 基于循环神经网络的文本分类模型
1.1 门限循环单元网络
门限循环单元网络(Gated Recurrent Unit,GRU)是长短期记忆网络(Long Short-Term Memory,LSTM)的简化版本,其性能与LSTM十分接近。GRU仅有两个Gate且没有LSTM的cell参数,其训练难度小于LSTM。GRU将不同长度的句子编码成固定长度的向量表示,通过重置门和更新门控制状态信息的更新。重置门的计算式为:
rt=σ(Wrxt+Uryt-1+br)
(1)
式中:rt为重置门;br为学习的偏置;σ为Sigmoid函数;xt为时间t的输入向量;Wr∈Rn×m和Ur∈Rn×n是学习的权重矩阵;yt-1为上一个状态;m和n分别为词嵌入维度和隐层单元数量。更新门的计算式为:
zt=σ(Wzxt+Uzyt-1+bz)
(2)
(3)
式中:⊙为矩阵元素的乘法运算;Wy∈Rn×m和Uy∈Rn×n为学习的权重矩阵。最终,GRU新状态yt的计算式为:
yt=(1-zt)⊙yt-1+zt⊙yt
(4)
如果重置门rt设为0,那么上一个状态对候选状态无效果。
1.2 层次注意网络
层次注意网络将文本y分割为K个句子,记为{syk|k=1,2,…,K},句子k表示为字词的向量{wkt|t=1,2,…,T},T为字词的数量。图1所示是层次网络处理文本的一个简单例子,将文本内容划分为若干条句子,每个句子分为字和标点符号。

图1 层次网络处理文本内容的简单例子
通过Word2vec(也称为word embeddings)将字词的One-Hot编码转化为低维度的连续值(稠密向量),意思相近的词被映射到向量空间内靠近的位置。映射后的向量表示为xkt=Wewkt,We∈Rdx|V|为字词的嵌入矩阵,其中:dx为向量维度;V为词汇表中词的编号。We的每一行对应第i个字词的嵌入。图2所示是层次注意GRU的网络结构,网络包含门循环单元、字词编码器和注意单元。

图2 层次注意GRU的网络结构
xkt=Wewkt
(5)
(6)
(7)
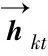
每个字词对句子表示的重要性不同,因此,通过引入注意方法区分每个字词的贡献。注意方法通过积累之前的输出向量,分析字词表示或者句子表示的完整语义信息。本文网络采用该方法提取字词和句子中的重要信息,注意方法的输出是字词或者句子的高阶表示。根据文献[18]的验证结果,注意层的字词表示准确率高于平均池化层和最大池化层。字词对句子语义重要性的计算式总结为:
ukt=tanh(Wwhkt+bw)
(8)
(9)
(10)
式中:ukt为hkt的隐层表示,随机初始化uw,在网络的训练过程中学习uw。
首先将词汇标注信息输入单层感知机,感知机以sine()为激活函数,感知机输出的隐层表示记为ukt。然后Softmax函数处理ukt,计算正则权重αkt。最后通过累加字词的隐层表示计算出句子的表示向量。
给定一个文本y,将文本表示为句子表示向量的集合,再次运用双向GRU处理句子表示向量,分析句子的上下文信息。文本表示的计算式为:
(11)
(12)
再次引入注意力机制计算句子对文本的重要性,获得文本y的向量表示,其计算式为:
uk=tanh(Wshk+bs)
(13)
(14)
(15)
式中:随机初始化us,在训练过程中学习us;v表示包含语义信息的词汇。通过Softmax层将输入的数值转化为条件概率,Softmax函数的计算式为:
p=softmax(Wcv+bc)
(16)
2 神经网络的非迭代对抗训练算法
2.1 对抗训练算法
为了解决层次注意网络的过拟合问题,提出了对抗训练方法,通过对抗训练为网络引入扰动。图3所示是对抗训练层次门循环神经网络的结构,其中虚线部分是嵌入的对抗处理模块。

图3 对抗训练的层次门循环神经网络
(17)

设x表示输入,θ表示分类器y的参数。在对抗训练分类器的过程中,损失函数L的计算式为:
L=-logp(y|x+rAT;θ)
(18)

(19)
式中:g=▽xlogp(y|x;θ);ε为扰动系数,ε在后向传播中学习获得。

(20)
式中:g=▽xlogp(y|X;θ)。
句子的对抗扰动rs_AT计算式为:
(21)
式中:g=▽xlogp(y|S;θ)。
对抗训练对字词所造成的损失计算式为:
(22)
对抗训练对句子所造成的损失计算式为:
(23)
式中:N为字词和句子的数量。
2.2 非迭代训练算法
梯度下降法是RNN常用的迭代训练算法,但该训练方法计算成本很高,且部分参数需要人工调节。本文设计了一种非迭代训练算法,通过线性函数逼近激活函数,学习RNN连接的权重。
(1) LSTM网络泛化模型。本文的GRU网络是LSTM网络的简化版本,LSTM网络解决了RNN的梯度消失问题,本文的非迭代训练方法也同样适用于其他的LSTM网络,因此本文以LSTM模型为例介绍非迭代训练的方法。LSTM的网络模型的相关介绍可参考文献[19]。
(2) LSTM非迭代训练算法。本文通过线性函数逼近激活函数,以实现对于循环连接权重的学习。针对本文GRU模型所采用的sine激活函数,采用Taylor序列扩展逼近sine激活函数,其计算式为:
(24)
使用一阶多项式获得输出权重,其计算式为:
(25)
式中:M为句子的最大词汇数量;Q为文章的最大句子数量。
LSTM的非迭代训练步骤为:
Step1随机初始化wi、bi。
Step2使用线性函数逼近激活函数,计算H。
Step3对H进行正则化处理,避免产生奇异矩阵。
Step4使用广义的Moore-Penrose伪逆计算θ=[β,α]T。
2.3 训练的计算复杂度
非迭代训练主要包含三个步骤:(1) 为网络的输入权重和偏差分配随机值。(2) 计算输出矩阵H。(3) 使用Moore-Penrose伪逆计算参数向量θ和输出权重β。假设网络共有F个输入节点、M个隐层节点和1个输出节点,共有N个输入向量。
步骤(1):分配随机值的时间复杂度和空间复杂度均为常量,关于值的数量呈线性关系,等于输入层的权重和偏差之和。步骤(2):输出矩阵H是一个N×M的矩阵,包含F维的输入向量,计算H矩阵共需要NM(F+c)次运算,c为常量的浮点数运算。步骤(3):计算H的伪逆:如果M≤N,需要O(NM)的计算复杂度,否则为O(NM+N2M)。因为训练数据的数量远大于隐层节点的数量,所以计算θ共需要O(NM)次运算。测试过程需要计算β矩阵,每个数据需要O(M(F+c)+M)次运算。最终训练模型的总体时间复杂度为:O(NM(F+c)+NM),总体空间复杂度为O(FM+2M+NM)。
3 实 验
3.1 实验环境和参数设置
硬件环境为Intel Xeon 64位12核处理器,主频2.0 GHz,内存24 GB。编程环境为MATLAB R2016b。使用Adam优化器迭代训练本文的RNN网络,该训练模型简称为HRNN,迭代训练的学习率范围为10-6~10-2,权重衰减惩罚因子范围为0.90~0.99,采用网格搜索从范围10~200中选择最优的epoch数量,批大小设为32。此外,使用本文的非迭代训练方法训练本文的RNN网络,该模型简称为SRNN,SRNN和HRNN权重和偏差的随机初始化均服从均值为0、标准偏差为0.01的高斯分布。GRU的隐层节点数量设为25,失活率(Dropout)设为0.1。经过预处理实验,将对抗训练的ε值设为0.3,此时为最小化过拟合的网络。每组参数的实验独立运行30次,将30次结果的平均值作为最终的性能值。
3.2 英文文本分类实验
(1) 实验的英文文本数据集。使用6个公开的英文文本数据集进行仿真实验,表1所示是6个英文数据集的介绍。Reuter是标记的新闻数据集,从该数据集选择8个出现频率高的新闻类别,分别为:earning、acquisition、crude、trade、money、interest、grain和ship。Amazon是亚马逊数据集的商品介绍文本集,选择4个出现频率高的商品类型,分别为:books、DVD、electronics和kitchen。Snippet是一个短新闻数据集,共有8个类别,分别为:business、computers、culture arts、education science、engineering、health、politics society和sports。SST-1和SST-2均为电影档案数据集,共有5个类别,分别为:very positive、positive、neutral、negative和very negative。TREC是一个开放领域的问答档案数据集,共有6个类别,分别为:abbreviation、entity、person、description、location和numeric information。

表1 英文文本数据集的基本信息
对6个数据集进行统一的预处理:将大写字母转化为小写字母,删除其中非utf-8字符串解码器的特殊字符,最终共保留72种字符。将所有文本扩展为统一长度,该长度为每个数据集最长文本的长度。
(2) 比较算法介绍。选择5个英文文本分类算法作为比较算法:① ConGDR[19]:由Mujtaba等提出的一种基于概念图的文本表示方法,根据概念图之间的相似性将文本分类。② DKVR[20]:由Hsieh等提出的分布式向量文本表示方法,通过向量间的相似性评估文本之间的距离。③ LST_SVM[21]:由Kumar等提出的最小二乘孪生支持向量机的文本分类算法,利用简单词袋模型表示字词,利用孪生支持向量机学习文本之间的高维非线性关系。④ LSTM_DSR[22]:由Huang等提出的基于LSTM的深度句子表示方法,通过循环训练提高每层神经网络的信息量,积累的表示提高了句子的表示效果。⑤ CNN_CNC[23]:由Lauren等提出的基于卷积神经网络的短文本分类算法。该网络第1层是自然语言处理层,嵌入层的输入为文本矩阵,文本矩阵的长度设为文本长度的最大值。
(3) 分类准确率。图4所示是6个英文文本数据集的平均分类准确率结果。总体而言,基于神经网络的分类算法LSTM_DSR、CNN_CNC、HRNN和SRNN优于传统算法ConGDR、DKVR,并且也好于机器学习算法LST_SVM。将HRNN与LSTM_DSR进行比较,LSTM_DSR是一种正常反向传播训练的LSTM方法,HRNN是本文设计的对抗训练算法,HRNN的分类准确率均优于LSTM_DSR,由此可得出结论,本文算法有效地缓解了过拟合问题,提高了文本分类的性能。

(a) Reuter、Amazon和Snippet数据集的结果

(b) SST-1、SST-2和TREC数据集的结果图4 英文文本分类的平均准确率
(4) 训练效率实验。迭代训练算法和非迭代训练算法的时间效率的对比结果如表2所示。结果显示,隐层节点越多,训练时间越长。隐层节点为25时,分类准确率最高,而此时HRNN的训练时间较高,本文非迭代训练算法SRNN的训练时间仅为HRNN的10%~20%之间,而SRNN的分类准确率略低于HRNN,但依然高于ConGDR、DKVR、LST_SVM、LSTM_DSR和CNN_CNC算法。

表2 英文文本的训练时间

续表2
3.3 中文文本分类实验
(1) 实验的中文文本数据集。使用中国科学院汉语词法分析系统(Institute of Computing Technology Chinese Lexical Analysis System,ICTCLAS)处理数据集,删除常用的停用词。采用复旦大学的文本分类语料库,选择经济、政治、宇航、医疗、军事、艺术和历史7个大类的文档集,删除其中与正文无关的信息。

表3 中文文本数据集的基本信息
(2) 比较算法介绍。选择两个中文文本分类算法作为比较算法:① CC[24]:根据领域本体图结构模型创建中文文本分类的本体学习框架,并建立中文术语-术语关系映射。基于概念聚类本体图半监督地学习中文文本的类别。② DBN[25]:一种深度置信网络的中文文本分类模型,分别以文本的TF-IDF和LSI特征作为输入,利用深度置信网络强大的特征学习能力获取深层次特征。
(3) 分类性能实验。一般采用宏F1(MF1)指标评价中文文本的分类性能。MF1的计算式为:
(26)
式中:Pi为类i的查准率;Ri为类i的查全率;m为分类数量。
图5所示是7个中文文本数据集的平均分类性能结果。总体而言,基于神经网络的分类算法DBN、HRNN和SRNN优于传统算法CC。HRNN和SRNN的分类准确率均优于DBN,由此可得出结论,本文的对抗训练算法和分层注意方法有效地提高了中文文本的分类性能。

图5 中文文本分类的平均MF1结果
(4) 训练效率实验。迭代训练算法和非迭代训练算法的时间效率比较结果如表4所示。结果显示,隐层节点越多,训练时间越长。隐层节点为25时,此时的分类准确率最高,而此时HRNN的训练时间较高,本文非迭代训练算法SRNN的训练时间大约为HRNN的1.5%,而SRNN的分类准确率略低于HRNN,但依然高于DBN算法和CC算法。
4 结 语
将分层注意力机制与循环神经网络结合,能够提高对文本分类的准确率,但存在过拟合问题和训练时间过长的问题。本文设计对抗训练方法最小化分层注意循环神经网络的过拟合问题,并提出非迭代训练算法加快循环神经网络的训练速度。最终对中文文本数据集和英文文本数据集均完成了仿真实验,结果表明本文的对抗训练算法有效地缓解了分层注意循环神经网络的过拟合问题,而非迭代训练算法有效地加快了训练速度,非迭代训练算法的训练时间大约为传统方法的1.5%。
因为实验条件的限制,本文算法目前仅在小规模文本数据集上完成了验证实验,未来将研究利用高性能机器对大规模文本数据集进行实验,评估本文算法的可扩展能力。
