跨社交网络用户对齐技术综述
2021-07-14陈白杨陈晓亮
陈白杨,陈晓亮
(西华大学计算机与软件工程学院,四川 成都 610039)
近年来,在线社交网络(online social network,OSN)在世界范围内迅速普及,各种各样的社交网络服务平台纷纷建立,如国内的微博、豆瓣、贴吧,国外的Facebook、Twitter、Instagram。这些平台为用户提供了丰富多彩的个性化服务,如:Twitter、微博主要提供社交服务和微博客服务;Facebook、Instagram 主要提供社交服务和照片分享服务;豆瓣、贴吧主要提供影视、书籍、兴趣活动等分享服务。用户为满足不同的需求,往往不会局限于单个社交网络,而会在多个网络平台上注册账号。这些用户可以充当连接不同网络的桥梁,从而将多个社交网络进行连接、融合。
用户对齐(user alignment,UA),旨在将不同社交网络上的同一自然人联系起来。开发一个高质量的用户对齐模型有助于构建一个全面的用户特征表示。大量社交网络应用,如跨网络朋友推荐[1]、信息扩散[2−3]、链路预测[4]和网络动力学分析[5]等都表明了研究用户对齐问题的必要性和益处。
跨社交网络用户对齐的研究工作大致兴起于2009 年,目前仍处于高速发展时期,各类方法络绎不绝。大数据条件下的跨网络用户对齐的算法研究和系统构建成为了当下研究的热点。本文对近年来跨社交网络用户对齐的研究进行了综述:首先对研究的问题进行了形式化定义;然后从数据预处理、候选集生成、训练数据获取、特征抽取、对齐算法5 方面概述了各种可用方法和研究进展,重点从基于规则和基于统计2 个角度对主流的用户对齐方法进行了详细阐述,并简要介绍了一些可用的数据集和算法评估方法;最后对目前面临的问题和挑战进行了探讨,对未来的研究方向做出了展望。
1 问题描述
跨社交网络平台的用户对齐最初被定义为在不同社区之间链接具有相同身份的用户[6]。用户对齐也称为用户识别[7](user identification)、锚定链接预测[8](anchor link prediction)、个人资料链接[9](profile linkage)、用 户 身 份 链 接[10](user identity linkage,UIL)等,其目的是在不同社交网络平台上对属于同一自然人的用户进行链接。一般而言,具有唯一性的用户属性,如电子邮件地址、手机号码和身份号码等,可以直接用于确定在线社交网络用户的真实身份。然而,由于隐私保护和安全问题,这些信息常难以获取。研究者往往通过用户在社交网络平台上公开的信息,如用户名、兴趣爱好、职业、发表的帖子、好友关系等进行跨社交网络平台的用户对齐。下面对本文研究的问题进行定义。
定义1社交网络。一个社交网络是一个三元组G=(U,R,A),其中U=表示该网络中全体用户的集合,R=表示网络中用户之间关系(如朋友、粉丝、关注等)的集合,A=表示全体用户属性的集合。
定义2用户属性。用户属性是用户性质或特征的集合,包括用户的基本信息(如用户名、工作单位等)和用户生成的内容(如用户发布的微博、帖子等)。用户属性用一个由键值对组成的集合来表示,每个属性键值对代表用户某一方面的属性,如<姓名:迈克尔>,其中“姓名”是属性的类型(或键),“迈克尔”是该属性的值。在社交网络中,用户通常具有许多不同类型的属性,例如姓名、年龄、隶属关系等。用户ui的 属性表示为aui=,其中代 表 用 户ui第j个属性键值对。
定义3用户对齐。给定2 个任意的社交网络GX=(UX,RX,AX)和GY=(UY,RY,AY),以及一些预先匹配的用户对,用户对齐(UA)的目标是找到其他隐藏的匹配用户对M=,其 中ui和uj属于同一自然人。
2 用户对齐技术概述
现有的用户对齐技术大多可以归纳为一个统一的框架,如图1 所示。该框架由5 个部分组成:1)数据预处理;2)候选集生成;3)标注数据获取;4)特征提取;5)用户对齐算法。
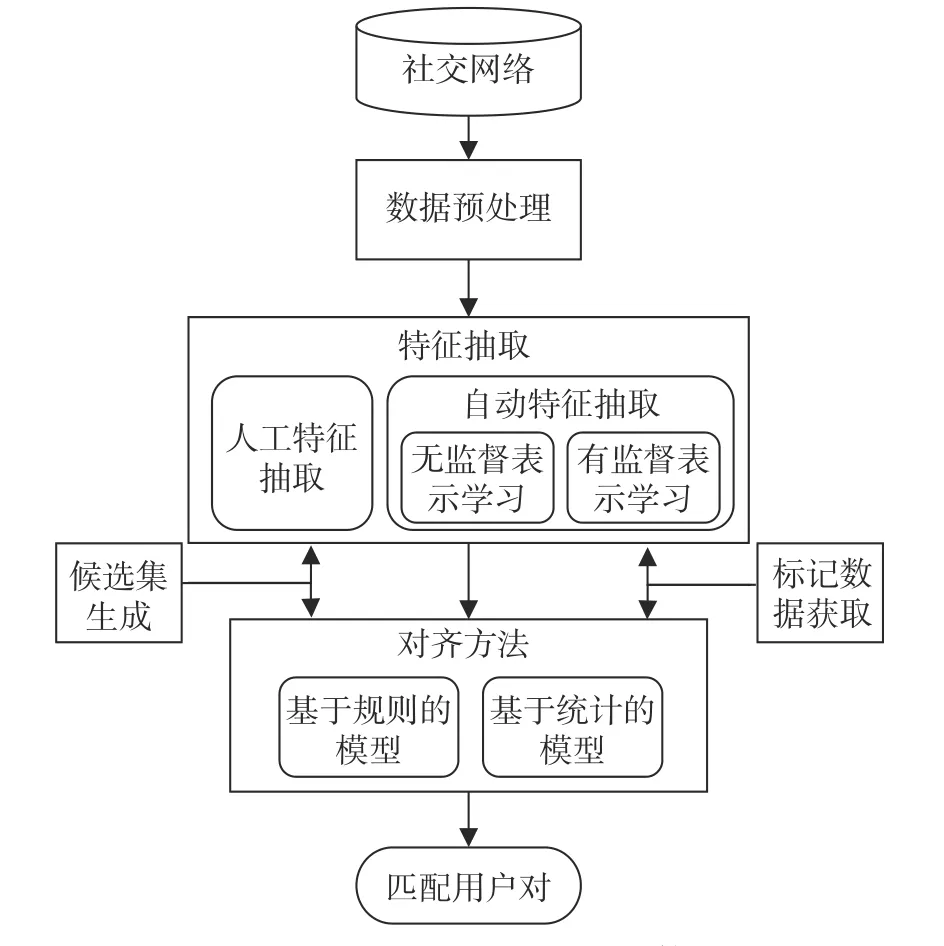
图1 跨社交网络用户对齐总体框架
对于待匹配的任意2 个或多个社交网络平台,首先应对用户数据进行预处理,挑选出待匹配的候选用户,并根据算法需要获取必要的标记数据;然后进入到特征抽取和对齐算法模块,先从用户数据中提取到有用的特征作为对齐算法的输入,再通过算法优化、求解来预测候选用户对是否匹配。
2.1 数据预处理
对于跨社交网络平台用户对齐问题,给定待匹配用户的属性集合中某些属性可能很关键、很有用,另一些属性则可能没什么用。对当前任务有用的属性称为“相关特征”,没什么用的属性称为“无关特征”。数据预处理首先要做的就是从给定特征集合中选出和当前任务有关的特征子集;然后,通过归一化、标准化、正则化等方式改进不完整、不一致、无法直接使用的数据。然而,在线社交网络的数据庞大、零乱且高度非结构化[11],不同网络平台之间的用户数据可能存在极大差异,这为数据的预处理带来了巨大挑战。值得庆幸的是,随着数据清洗与整合技术的发展,数据预处理领域的大量研究成果可供借鉴,具体内容可以参见文献[12−14],本文不再赘述。
2.2 候选集生成
一般对2 个或多个用户进行匹配的时候,需要将一个社交网络平台中所有用户与其他待匹配的社交网络平台中所有用户进行比较,这将导致算法复杂度随着网络规模呈指数增长。在大数据条件下,其计算量是难以接受的,而实际上可能的匹配用户数量不会超过规模较小社交网络的用户数量。为了解决这个问题,需要设计高效的算法在保证准确率的前提下尽可能减少待匹配用户的数量,使复杂的匹配计算只在最有可能的用户中进行。单个待匹配用户一般称为“候选用户”,成对的待匹配用户则称为“候选用户对”。所有候选用户及候选用户对统称为“候选集”,候选集的生成一般可以采取3 种策略。
1)从所有待匹配用户中选择具有辨识度的用户特征来进行判断。例如:Zafarani 等[6]首先通过寻找一组用户名的关键词来生成候选集,然后通过添加/删除一系列前/后缀来进行扩展;MEgo2Vec直接将具有较高用户名相似性的用户对作为候选集[15]。
2)从已经发现的匹配用户出发,沿着其相邻用户进行扩展。例如:Bennacer 等[16]将已匹配用户的直接邻居作为候选集;Zhang 等[17]将已匹配用户的d跳邻居作为候选用户集,d从1 开始逐步增大。
3)将以上2 种策略相结合。例如COSNET 首先将具有较高用户名相似度的用户对作为初始候选集,然后沿着初始用户的邻居进行扩展[18]。
2.3 标记数据获取
在用户对齐任务中,预先匹配的用户对又称为标记数据。大部分基于统计学习的用户对齐方法需要充足的标记数据来进行模型的训练。标记数据无论是对匹配的准确度还是算法的收敛速度都会产生重要影响。然而,大规模获取这种标记数据的成本较高。目前主要有2 种获取标记数据的手段。
1)一些社交网络平台允许用户公开自己在其他网络平台上的账号。这些账号即可作为获取预先匹配用户对的线索。这种数据获取方式速度快、准确度高,因此,大部分研究[15,19−20]采用这种方法。
2)部分用户属性具有很强的辨识度,通过人工设置一组规则可以自动进行数据标注。例如Narayanan 等[21]通过搜索具有相同度数和邻居数的k团(k-clique)来获取初始对齐用户;Liu 等[22]通过分析用户名的稀有性和通用性来自动标注训练数据;CoLink 预定义了一组基于用户名稀有性、属性一致性和用户关系的规则来生成标记数据[23]。这类方法适用性广,可以大规模获取标记数据,但准确度相对较低。
2.4 特征抽取
由于用户对齐问题讨论的是2 个或多个网络之间用户的关联,其特征抽取可以分为2 种方式。
1)针对候选用户对的特征抽取,即先从待匹配网络中挑选成对的候选用户,再对候选用户对提取特征。这种类型主要采取人工特征抽取技术(即特征工程)。传统的人工特征提取是用户对齐任务中特征抽取的重要方法,大量研究[20,24−25]采取这类方法。
2)针对单个用户的特征抽取,即先分别从待匹配网络中挑选候选用户,再对单一候选用户提取特征。这种类型主要采取基于表示学习(representation learning,RL)的方法。表示学习旨在将原始数据转换成为能够被计算机有效利用的表示形式,从而在构建分类器或其他预测模型时更容易提取有用的信息[26]。表示学习的重要特性在于允许计算机学习使用特征的同时,也学习如何提取特征。
社交网络中的用户数据[27]主要包括用户的基本信息(如用户名、职业、地理位置),用户生成内容(如用户发布的帖子、博客、出版物)以及用户之间的关系(如朋友、关注、被关注)等。这些数据按照表现形式不同又可以分为文本数据、图像数据、音频/视频数据、地理位置数据、网络拓扑结构数据等。学者们利用用户文本属性和用户网络关系来进行用户对齐研究。下面主要介绍基于文本和网络拓扑结构的特征抽取方法。
2.4.1 文本特征抽取
对于成对的文本类型用户属性(如用户名)主要采用字符串相似性算法来进行特征提取,如Jaccard 相似度[28]、Jaro和Jaro-Winkler距离[29]、Levenshtein 距离[30]等。此外,一些研究[7,31−32]先将文本字符串向量化,再通过向量之间的距离度量,如余弦相似度、欧氏距离等来提取特征。
1)Jaccard 相似度。将待匹配的2 个字符串看作2 个由单一字符构成的集合,再计算2 个集合的交集与并集的比值,即
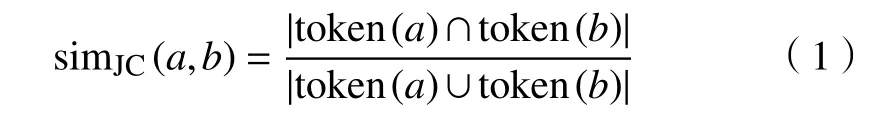
其中a,b为 待匹配的2 个字符串。token(·)函数将字符串转换为由单个字符组成的集合。Jaccard 相似度算法的优点在于对文本顺序无关,但对错误比较敏感,人工录入错误或字符缺失等情况会对结果产生较大影响。
2)Levenshtein 距离。即将一个字符串转换另一个所需要的插入、删除和替换操作的最小次数。Levenshtein 距离又称为“编辑距离”,用ai/bj表示字符串a/b的第i/j个 字符,当ai≠bj时,指示函数Iai≠bj的值 为1,否 则为0。函数 Leva,b(i,j)表示a的前i个字符构成的子串与b的前j个字符构成的子串之间的Levenshtein 距离,则a和b之间的Levenshtein 距离 Leva,b(|a|,|b|)可以通过式(2)递归计算得出。
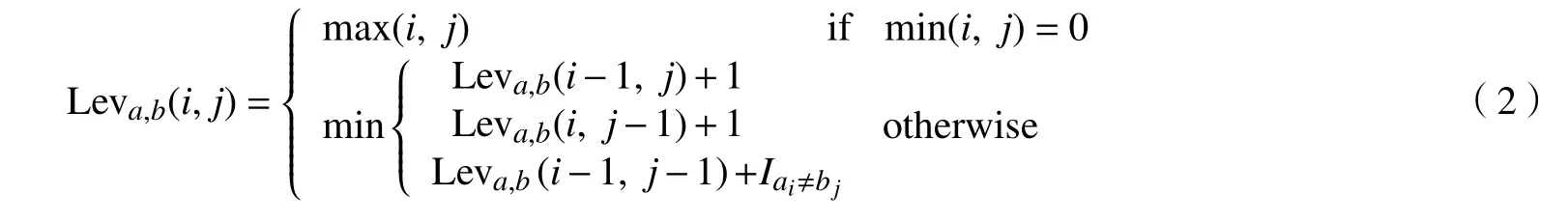
Levenshtein 距离可以降低相似性匹配的错误敏感性,但是它为每一个字符的每一次编辑操作都赋予相同的权重(次数),没有考虑不同字符或子串的重要程度;然而实际上不同位置的子串编辑操作对相似性匹配的重要性可能不同,比如一些前后缀和缩写词的处理。
3)Jaro 和Jaro-Winkler 距离。Jaro 距离的主要思想是通过比较2 个字符串的公共部分来计算相似程度,所谓“公共”这里特指2 个字符相等并且它们在字符串中的位置距离之差Δ不大于较小字符串长度的一半,即 ∆≤0.5×min(|a|,|b|),设t为公共部分发生位置交换的次数,δ为公共字符的集合,则Jaro 距离可以定义为
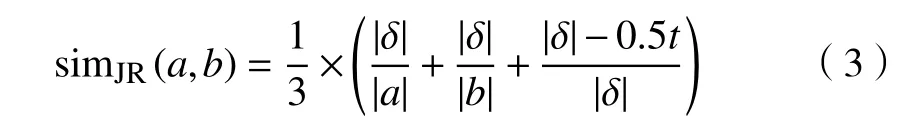
Jaro 距离可以容忍少量的拼写错误,但对于2 个主体部分相同但前缀或者后缀不同的字符串的度量效果并不好。Jaro-Winkler 距离对此进行了改进。对于字符串a和b以及共同前缀τ,Jaro-Winkler 距离表示为
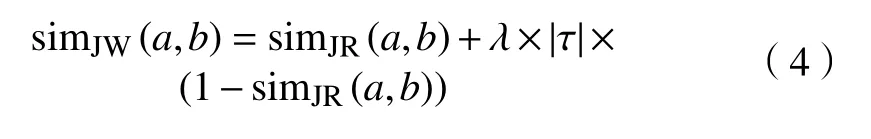
其中,λ 为前缀τ 对整体相似度影响的一个系数。
4)基于向量距离的方法。先将文本字符串向量化,再通过计算2 个向量之间的距离来评估字符串相似程度。将文本字符串表示为向量的常用方法有词袋模型(bag-of-words,BOW)、词频–逆文档频 率(term frequency-inverse document frequency,TF-IDF)等。
词袋模型忽略文本的语序、语法或句法关系,将其仅仅看作是一个词的集合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。对字符串a,其词袋向量化表示定义为
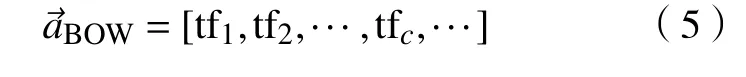
其中 tfc表 示字符表 V 中第c个字符在a中 出现的次数。
TF-IDF 在词袋模型的基础上进行了改进。其核心思想在于:一个词的重要程度跟它在单个文档中的计数成正比,而跟它在语料库中出现的次数成反比。对字符串a,其TF-IDF 向量化表示为
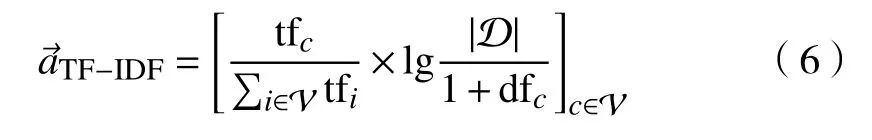
式中:D表示语料库中文档的总数(即用户总数);dfc表 示语料库中包含词汇表 V中第c个单词的文档的数量。
在将字符串a和b分 别进行向量化表示后,其余弦相似度可表示为
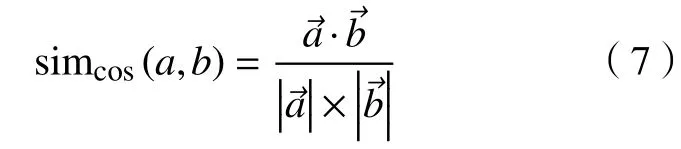
其欧式距离表示为
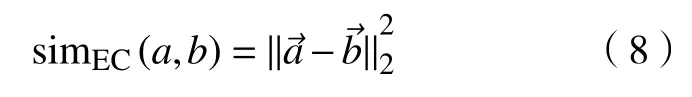
基于向量距离的文本特征抽取方法具有适用性广的优点,能够有效提取长文本的语义特征,但仍然忽略了词的顺序以及语法、句法关系。此外,少量研究也在成对用户文本特征提取中采用了表示学习方法,如MEgo2Vec 先将候选用户对的文本属性用卷积神经网络(convolution neural network,CNN)从字符和词2 个视角分别进行嵌入,再进行拼接,通过训练使得匹配用户之间的文本属性向量距离最小[15]。
对于单一用户的文本类型属性,大部分研究采用基于表示学习的方法来提取特征。基于表示学习的特征抽取方法往往能够从大规模训练数据中获得对下游任务有用的特征表示,性能通常较高,但也需要构建较复杂的优化模型,运算量较大。自然语言处理技术中有大量相关研究,本文不再叙述。
2.4.2 网络结构特征抽取
对于候选用户对之间的网络结构特征一般用一些结构相似性函数进行度量,如共同邻居计数[33]、Jaccard 系数[28]、Adamic/Adar 系数[34]等。
1)共同邻居计数(common neighbors)。即2 个用户在不同网络中的属于同一自然人的相邻用户个数。用户ui和uj的相邻用户分别用N B(ui)和 NB表示,其共同邻居计数s imNB表示为
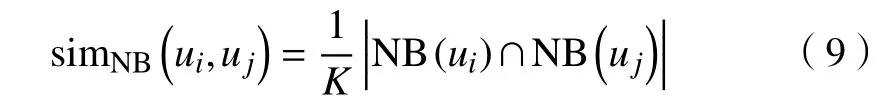
其中,K为一个足够大的常数,使得所有用户对的共同邻居计数值都在0 到1 之间。
2)Jaccard 系数。即2 个用户的共同邻居计数与他们所有邻居计数的比值,定义为
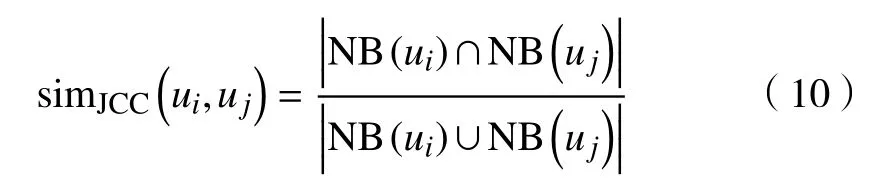
Jaccard 系数和共同邻居计数都比较简单直观,但Jaccard 系数考虑了节点本身的度数,从而能够区分不同节点的重要程度。此外,两者都为每个匹配的邻居赋予相同的权重,但实际中某些邻居可能具有不同的影响力或作用。为此,Adamic/Adar系数进行了改善。
3)Adamic/Adar 系数。其核心思想是存在关联关系越多的用户作为邻居在计算中所分配权重越低,其定义为
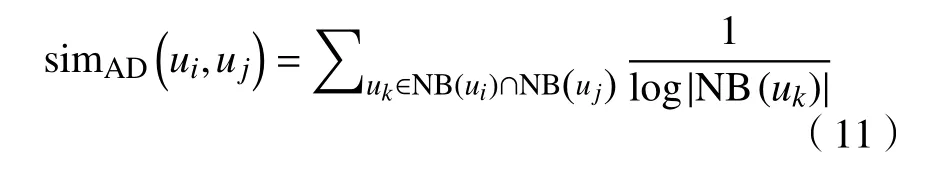
Adamic/Adar 系数提升了算法的准确率,但相应地增加了运算复杂度。此外,一些研究将待匹配的2 个(或多个)网络通过预先匹配用户整合为一个统一网络,然后在这个统一网络上进行网络表示学习,进而获得候选用户对的有效特征表示,例如MGGE 先将2 个网络进行合并,然后利用社交网络在结构上的高阶邻近性和面向对齐任务的特性来构造网络表示学习模型[35]。
对于单个用户的网络结构特征,研究者大多采取诸如DeepWalk[36]、LINE[37]、TADW[38]、Node2vec[39]、Struc2vec[40]、GAT[41]等的网络表示学习的方法进行特征学习。此外,一些异构网络表示学习方法,如TransE[42]及其扩展等也可以直接运用于社交网络结构的特征提取。表1 示出本文阐述的各种特征抽取方法。
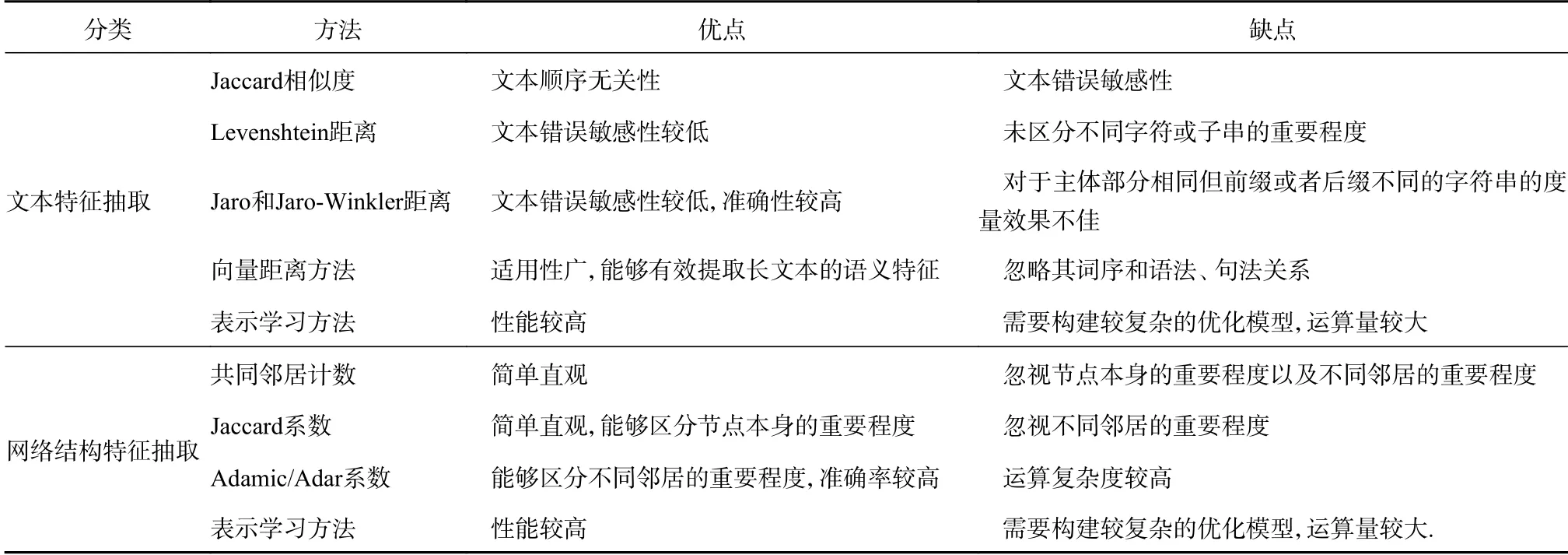
表1 特征抽取方法对比
2.5 用户对齐方法概述
一般来说,用户对齐方法总体上可以划分为2 大类:基于规则的方法和基于统计学习的方法。基于规则的方法首先从社交网络平台用户数据中人工挑选一组适合的用户属性,再针对每个属性设计评分规则,最后通过匹配算法来实现跨社交网络的用户对齐,这部分内容将在3.1 节进行详细阐述。基于统计学习的方法,也称为基于统计机器学习的方法[43],通过特征工程或表示学习来抽取用户特征,并训练预测模型来进行用户对齐,这类方法是当前跨社交网络用户对齐研究的主流方法,将在3.2 节进行详细介绍。
此外,由于用户对齐问题与传统的网络对齐[44](network alignment)和知识库实体对齐[45](knowledge base entity alignment)在问题设置、研究方法、评估方法等方面比较相似,因此,网络对齐和实体对齐的一些方法也可以适用于用户对齐问题,这部分内容将在第3 章相关部分进行概述。
3 用户对齐方法
3.1 基于规则的用户对齐方法
基于规则的方法是用户对齐问题的重要方法,早期的大量研究建立在这种方法之上。一个典型的基于规则的用户对齐方法有4 个步骤。
步骤1,通过数据预处理从社交网络中挑选出对当前任务有用的属性,如用户名、出生日期、工作单位、朋友关系等。
步骤2,对每个属性设计相应的评分规则,并计算候选集中待匹配用户对的各项评分。
步骤3,将候选用户对的各项评分进行加权求和,得到该候选用户对的匹配度。
步骤4,通过一个特定匹配算法进行用户对齐。
给定一个候选用户对 (ui,uj)及其对应的属性集合 K,通过特征抽取方法,用sk(ui,uj)表示该候选用户对的第k个特征的评分,则该用户对的匹配度Sij可以表示为
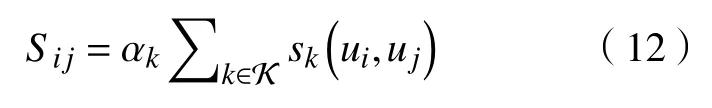
其中 αk∈[0,1]表 示第k个特征的权重系数。下面介绍一些常见的用户匹配算法。
3.1.1 匹配度最大化用户对齐算法
在获得候选用户对的匹配度以后,一种最直观的用户对齐方法是将候选集中具有与目标用户最大匹配度的候选用户作为对齐用户。早期研究大多利用用户公开的属性信息来进行用户对齐。例如:Zafarani 等[6]直接利用待匹配用户的用户名进行字符串模式匹配;Iofciu 等[46]结合用户名的字符串相似性和标签(Tag)模式相似性来搜索对齐用户。用户属性信息通常比较容易获得,但不同的社交网络之间的用户属性可能差异极大,仅仅依靠用户属性可能难以取得比较好的对齐效果。用户之间的关系反映了用户在网络中的拓扑结构特征,为跨网络的用户识别提供了重要线索。因此,一些研究者通过用户在网络中的拓扑结构来识别匹配用户。例如:CPCC 设计了3 个基于网络结构的相似性指标,并通过综合比较候选用户对的结构相似度来发现匹配用户[24];冯朔等[47]借鉴图论中最大公共子图的思想来定义用户之间匹配度,匹配度越高代表2 个用户有越高的概率是同一自然人。社交网络中用户之间关系可能非常嘈杂,而大规模社交网络的完整结构信息通常难以获取,单纯依靠网络结构特征的用户对齐方法也有其局限性;因此,研究者往往把用户的属性特征和网络结构特征相结合,以提高预测准确率。例如:Labitzke 等[48]提出通过比较用户朋友的用户名来发现匹配用户;DCIM 基于用户发布的文章和好友关系定义了动态核心兴趣度的概念,然后采用余弦相似度来计算目标用户对之间匹配度[49]。
为了进一步提高预测准确性,一些算法在最大匹配度规则上设置了约束。约束主要包括2 种类型。
1)只有当最大匹配度达到某个阈值的候选者才被识别为匹配用户对。例如:Vosecky 等[7]提出了一个字符串相似度算法,将用户之间的多个文本属性(包括用户名、E-mail、生日等)的相似度进行加权求和,再通过一个阈值来过滤相似度较低的候选用户对;Perito 等[32]讨论了用户名的独特性,通过用户名相似性来识别匹配用户,并用一个阈值来调节算法的查准率和查全率。
2)一对一匹配约束。基于最大匹配度的方法简单、直观,但没有考虑匹配结果的唯一性,输出的结果可能存在一对多(即一个网络中的某用户和另外一个网络中的多个用户相匹配)、多对多的情况;因此,研究者提出了一对一匹配约束。例如:Narayanan 等[21]要求候选用户对在2 个网络中彼此都具有最大匹配度(又称为“双向最大匹配度”),且匹配度达到一个阈值方可进行对齐;Buccafurri等[50]考虑了用户名的文本相似度和基于共同邻居计数的网络结构相似度,通过一个阈值过滤相似度较低的候选用户对,再设置另一个阈值识别对齐用户;User-Matching 计算了候选用户对的基于网络结构特征的匹配度,然后通过一个带阈值的双向最大匹配度算法来搜索匹配用户对[51];POIS 先通过地理位置轨迹特征来计算候选用户对匹配度,然后在二部图上进行一对一用户匹配[52]。
3.1.2 基于传播的用户对齐方法
基于传播的用户对齐方法可以利用网络拓扑结构以及已经获取到的匹配用户信息来迭代地发现新的匹配用户。设 N(ui)和分别表示用户ui及uj的相邻用户的集合,传播算法通过一个基于邻居特征的匹配函数来计算新的候选用户对的匹配度,并进行多次迭代,直到没有发现新的匹配用户对为止。依据候选集的生成方式,传播方法可采取2 种传播规则。
1)穷举法,即从剩余的未匹配用户对中选择候选用户对。例如:Narayanan 等[21]通过搜索具有相同度数和邻居数的k团(k-clique)来获取初始对齐用户,然后重复从所有未匹配用户中随机选取候选用户对进行匹配;User-Matching 首先通过基于共同邻居计数的规则来识别匹配用户,然后用一个预设条件来挑选新的候选用户对,逐步发现更多的对齐用户[51]。
2)相邻搜索,即从现有匹配用户对的邻居中选择候选用户对。例如:Buccafurri 等[50]和Shen 等[53]综合利用了用户属性相似度和网络结构相似度来识别对齐用户,然后沿着相邻用户进行传播;Bennacer等[16]则通过基于用户名、姓名、Email 等属性相似度的规则来迭代搜索匹配用户对;FRUI 仅依靠朋友关系特征来计算用户匹配度,然后沿着匹配用户的邻居关系进行传播[54];CLA 基于用户链接信息定义了朋友匹配度,并结合用户名、URL、E-mail 等属性相似度来迭代发现对齐用户[25]。
此外,知识库实体对齐方法中也有基于传播的算法可供借鉴,例如SiGMa 利用实体属性和邻居结构特征计算候选实体对的相似度评分,并一对一进行实体对齐,然后沿着相邻实体迭代搜索新的匹配实体对[55]。表2 汇总了本文阐述的基于规则的用户对齐方法。
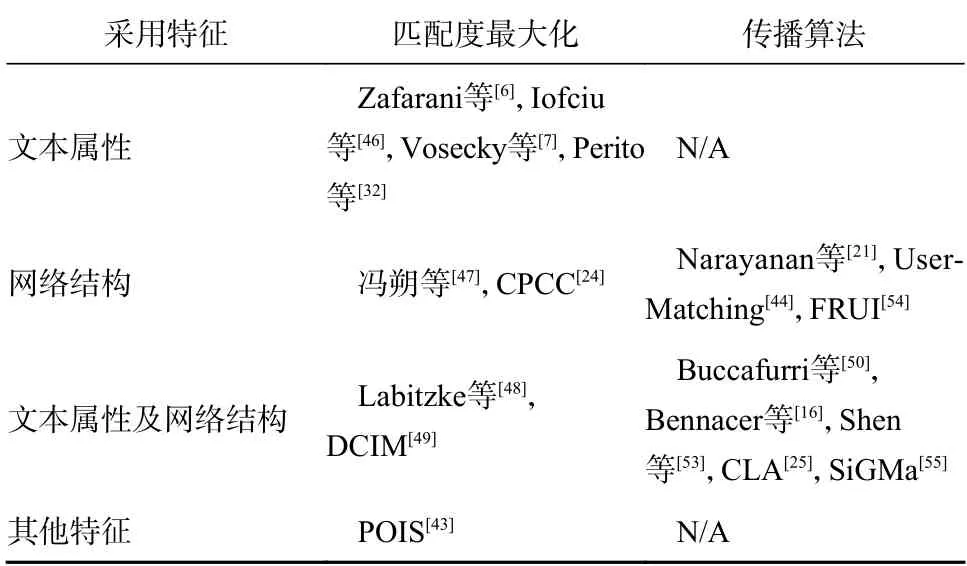
表2 基于规则的用户对齐方法
3.2 基于统计学习的用户对齐方法
随着机器学习和深度学习技术的快速发展,大量基于统计学习的方法也被应用到用户对齐领域,并取得了丰硕的研究成果。基于统计学习的用户对齐方法主要有2 种工作模式:一是通过特征工程人工提取用户特征,然后在标记数据的基础上训练分类模型;二是通过表示学习的方法学得适应于用户对齐任务的最佳用户表示,然后再进行跨网络用户匹配。依据使用标注数据数量的不同,基于统计学习的用户对齐方法又可以分为基于监督学习(supervised learning)、基于半监督学习(semi-supervised learning)和基于无监督学习(unsupervised learning)的用户对齐方法。
3.2.1 基于监督学习的用户对齐方法
基于监督学习的用户对齐方法需要将预先匹配的用户对作为标记数据,然后使用训练好的模型对待匹配的候选用户对进行预测。一个典型的监督学习模型[56]有以下3 个步骤。
步骤1,选择合适模型,使用训练数据对模型进行训练,并进行参数调节。
步骤2,对以上训练出来的模型进行测试和评估,并进一步调节参数或改进模型。
步骤3,将测试好的模型应用于实际数据进行预测。
基于监督学习的方法一般将用户对齐任务设置为分类问题,其训练数据包括2 类实例:一是真实的匹配用户对,称为“正例(positive instances)”;二是非匹配用户对,称为“负例(negative instances)”。集合表示所有候选用户对,M=属于同一自然人⊂Q表 示正例集合,N=Q−M表示负例集合。候选用户对集合 Q又 可以划分为训练集 Q′和测试集 Q′′。基于监督学习的用户对齐模型目标在于在训练集 Q′上学得一个映射函数 F :UX×UY→{0,1}。早期的基于监督学习的用户对齐方法通常在人工提取特征的基础上训练分类器模型。给定一个候选用户对(ui,uj)及 其对应的属性集合 K,通过特征抽取,用sk(ui,uj)表 示该候选用户对的第k个特征的评分,则可以用一个 |K|维 向量fij来表示该用户对,即
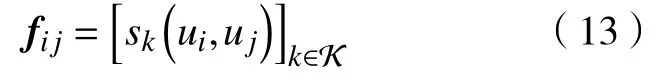
在此基础上,一些常见的分类器,如支持向量机[57](support vector machine,SVM)、决 策 树[58](decision tree)、朴素贝叶斯[59](naïve bayes)等可以用来构建有监督的用户对齐模型。例如:Motoyama 等[31]提取了候选用户对的文本属性特征(包括生日、地址、教育背景等),然后通过提升技术[60](Boosting)将多个弱分类器进行整合;Malhotra 等[61]和Zhang 等[9]则全面考察了包括图像特征(如头像、脸部照片等)在内的多种用户特征来构建分类器模型,并进行有监督的用户对齐;Bartunov 等[62]、Peled 等[63]以及Li 等[20]结合用户文本属性和网络结构特征来构建分类模型;MOBIUS 从用户行为模式中提取特征,并在决策树、朴素贝叶斯、随机森林、支持向量机、逻辑斯蒂回归等多个分类器上取得了近似的用户对齐效果[64];朱俊星[65]对中文用户名的特性进了研究,然后在用户名相似度评分的基础上训练多个分类器。
与此同时,一些研究者在分类器模型基础上结合了基于规则的匹配算法,例如:MNA 通过扩展的共同邻居计数、Jaccard 系数、Adamic/Adar 系数提取了用户文本属性特征、用户关系特征和用户时空分布特征,然后在训练分类器模型的基础上提出了一个一对一的稳定匹配算法[8];Zhang 等[17]利用了用户昵称、地址、朋友关系等特征来构建分类器模型搜索对齐用户,并沿着匹配用户的邻居进行迭代传播。
近年来,基于有监督表示学习的用户对齐方法越来越受到研究者的重视。这类方法有2 种工作模式。
1)将待匹配的2 个网络通过表示学习映射到同一低维向量空间中,使得真实匹配用户对在向量空间中的距离最小。例如PALE 利用网络结构信息,通过一个映射函数将源网络投影到目标网络,从而使匹配用户之间的距离最小化[66]。与之类似,ULink 通过学习一个投影矩阵将来自多个社交网络的用户映射到同一个潜在用户空间中[10]。ABNE 利用社交网络中用户的关注和粉丝关系并结合图注意力机制[41](graph attention network,GAT)来进行网络表示学习[67]。KGEUA 采用TransE[42]模型将2 个网络嵌入到同一个向量空间,再结合共同朋友计数来识别匹配用户[68]。DPlink 获取了用户活动的时空位置信息,构造了基于深度神经网络的位置编码器、轨迹编码器以及分类器模型来实现用户对齐[69]。MGGE 利用社交网络在结构上的高阶邻近性和面向对齐任务的特性来进行表示学习,最后通过比较向量相似度来识别匹配用户[35]。
2)通过表示学习自动抽取候选用户对的特征,然后通过构建分类器进行用户对齐。例如IAUE[70]在进行网络粗粒化的基础上采用node2vec[39]模型进行图表示学习,训练分类器来搜索对齐用户,最后通过稳定婚姻匹配算法[71]筛选出一对一的匹配用户;MEgo2Vec[15]采用卷积神经网络将待匹配用户对的自我中心网络进行嵌入,然后通过一个二元分类器输出预测结果;SAUIL[72]挖掘了社交网络中用户的网络浏览行为,并通过一个孪生神经网络[73](siamese neural network)模型和分类器来识别对齐用户。
3.2.2 基于无监督学习的用户对齐方法
在缺乏标记数据的情况下,研究者通过无监督的机器学习来解决用户对齐问题。目前,基于无监督机器学习的用户对齐方法主要有2 种模式。
1)首先在具有较强辨识度的属性特征上设置一组规则来自动获取标记数据,然后进行有监督的用户对齐。例如:Liu 等[22]首先通过评估用户名的稀有性来自动标记匹配用户对,然后利用一系列相似性评估算法来提取候选用户特征,最后采用二元分类器模型来识别对齐用户;CoLink[19]定义了一组规则用于自动生成标记数据,然后在协同训练框架下,构建一个基于用户属性的序列到序列[74](sequence to sequence)神经网络模型和一个基于共同邻居计数的相似度模型,使它们迭代相互增强。
2)首先通过无监督的表示学习抽取候选用户特征,然后利用对齐算法识别匹配用户。例如UMA[75]和FRUI-P[76]仅利用网络结构特征进行对齐模型构建。UMA 讨论了多个待匹配网络之间对齐用户的传递性,并考虑了一对一匹配约束。FRUI-P 通过随机游走和CBOW[77]模型进行网络表示学习,使得对齐用户之间在潜在向量空间中的距离最小。UUIL[78]则采用了一个全新的研究路径,它将社交网络中的全体用户看作一个离散概率分布,构建了一个瓦瑟斯坦对抗生成网络[79](wasserstein GAN)模型和一个正交矩阵变换模型,通过最小化2 个网络对应的分布来学习2 个网络之间的映射,使得同一自然人之间的距离最近。
此外,网络对齐方法中也有基于无监督表示学习的模型可供参考。例如REGAL 首先提取了节点网络邻近性和属性文本相似性特征,然后通过矩阵分解来进行网络表示学习,最后按照相似度排名来进行网络对齐[80]。
3.2.3 基于半监督学习的用户对齐方法
无监督方法不依赖于标记数据,与有监督方法相比,其性能相对较低。一些基于半监督学习的方法被用来解决用户对齐问题。半监督学习方法能够充分利用少量标记数据和大量未标记数据来获取数据潜在分布,从而有效提高用户对齐模型效果。IONE[81]和DeepLink[82]仅依靠网络结构特征来进行模型构建。IONE 将用户的关注/粉丝关系表示为输入/输出背景向量,在一个统一的优化框架下同时解决了网络嵌入问题和用户对齐问题;DeepLink 在网络表示学习的基础上构建了一个基于半监督强化学习的用户对齐模型,并结合了对偶学习(dual learning)机制,充分利用未标记数据来提升模型效果。MAH[83]、COSNET[18]、MSUIL[19]和dNAME[84]都结合了用户文本属性和网络结构特征来识别匹配用户。MAH 提出一种基于超图的表示学习模型,并提取用户名特征来改善模型效果;COSNET 综合考虑了用户属性匹配、网络邻居结构匹配和多个网络的全局一致性,采用一个半监督的能量模型来迭代地发现对齐用户;MSUIL 首先采用TADW[38]模型做无监督属性网络嵌入(attributed network embedding),然后在UUIL 的基础上结合多个网络之间的交互依赖性将每对社交网络映射到一个向量空间;dNAME 关注模型的可解释性,利用图卷积神经网络(graph convolution network,GCN)来进行网络表示学习,并通过对抗式学习范式来进一步区分对齐用户及其邻居。HYDRA[85]深入挖掘包括了图像特征在内的用户行为轨迹特征和结构一致性特征,提出了一个半监督的多目标优化框架来进行跨社交网络用户对齐。表3 汇总了本文阐述的用户对齐算法。

表3 基于统计学习的用户对齐方法
4 评估方法
4.1 数据集
社交网络平台的用户数据通常由网络服务提供商进行维护和存储。研究者可以通过应用程序接口(API)、网络爬虫等方式进行读取。单个网络用户数据的获取比较容易。然而,跨社交网络平台用户对齐的研究需要获取不同网络之间相同用户的资料(进行数据标注),加之社交网络规模庞大、平台隐私保护等问题,因此,大规模获取跨社交网络用户数据仍然是比较困难的。与此同时,不同研究方法往往采用了不同的用户特征,因此,能够提供全部用户特征的数据集的获取难度很大。学术界目前还没有广泛认可的用户对齐基准数据集。Shu 等[27]归纳了用户对齐数据集的合成方法,并介绍了早期研究中采用的一些数据集。下面补充介绍一些近年来公布的可用数据集。
1)CLF/IONE[86]。CLF[87]提供了一对包括了用户帖子和地理位置特征的社交网络数据集(Foursquare-Twitter),其中Foursquare 由5 392 个用户及其之间的关系构成,Twitter 包含了5 223 个用户及其之间的关系。IONE[81]仅包含了该数据集的网络结构特征。
2)MEgo2Vec[88]。它提供了3 个学术合作网络和2 个社交网络数据集。其中,学术合作网络由Aminer(学术搜索和挖掘服务)、LinkedIn(求职类社交网络)以及VideoLectures(学术在线视频资料库)组成,包含了用户名、工作单位、教育背景和研究方向/技能等用户属性信息和用户关系信息。社交网络数据由Twitter 和MySpace 组成,包含了用户名、帐户名称和地理位置等用户属性信息。
3)DPlink[89]。它提供了一组包括了用户位置轨迹特征的移动网络数据集,由2 844 个手机用户和1 761 个微博用户在一周内的位置信息组成(已做匿名化处理)。其中手机用户包含325 215 个位置记录,微博用户包含49 651 个位置记录。
4)MAUIL[90]。它提供了一组包含用户名、地理位置和用户帖子信息的社交网络数据集(微博–豆瓣)和一组包含用户名、工作单位和论文名称的学术合作网络数据集[91](DBLP17-DBLP19)。其中,社交网络数据集包含9 714 个微博用户以及9 526 个豆瓣用户;学术合作网络从DBLP 数据库(计算机科学期刊和论文集)2017 年和2019 年的2 个时间点的快照中分别提取了9 086 个作者和9 325 个作者。
4.2 评价指标
评价指标用于度量算法的准确性和全面性。按照问题设置的不同,用户对齐任务的评价指标可以分为面向分类问题和面向排名问题的评价指标。对于分类问题,一个实例包括正例(positive instance)和负例(negative instance)2 种情况,因此算法运行结果会出现4 种情况:1)真正类(true positive,TP),一个正例被预测为正类;2)假正类(false positive,FP),一个负例被预测为正类;3)真负类(true negative,TN),一个负例被预测为负类;4)假负类(false negative,FN),一个正例被预测为负类。
分类问题常用的评价指标有准确率(Accuracy)、精度(Precision)、召回率(Recall)、F1值。
1)准确率,指被算法正确分类的实例数与总实例数的比例,即
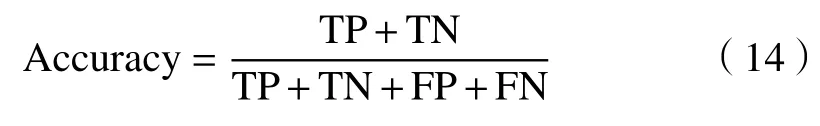
2)精度,也称为查准率,指被算法划分为正类的实例中,真正类的占比,即
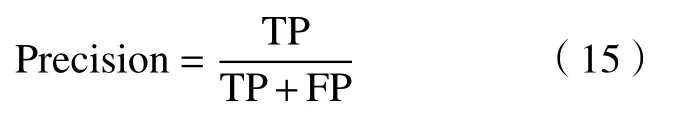
3)召回率,也称为查全率,指所有正例中,被算法划分为真正类的占比,即

4)F1值,也称为F-measure 或f1-score,是综合考虑精度和召回率的一个评价指标,定义为精度和召回率的调和均值,即
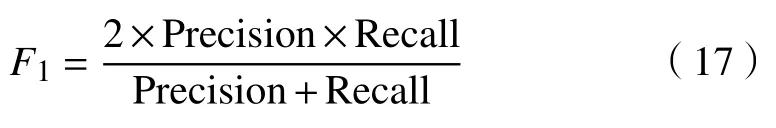
对于排名问题,算法的输出为一个候选答案的排序,并将排名的第一位候选答案作为预测结果输出。常用的面向排名模型的评分指标有Hits@k、Precision@k、MRR 等。这些指标的评分越高,表明算法性能越好。
1)Hits@k,即真实样例在预测结果中排前k(k≥1)名的平均分数,其计算公式为
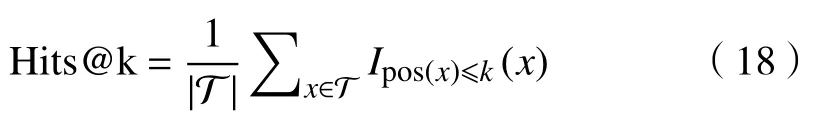
式中:T 表示候选样例集合;pos(·)表示真实样例在所有候选样例评分列表中的位置;Ipos(x)≤k(·)为一个指示函数,当p os(x)≤k时返回1,否则返回0。
2)Precision@k,即真实样例在预测结果中排前k(k≥1)名的加权平均分数。与Hits@k 的不同之处在于,Precision@k 对排名靠前的样例赋予了更高的权重,其计算公式为
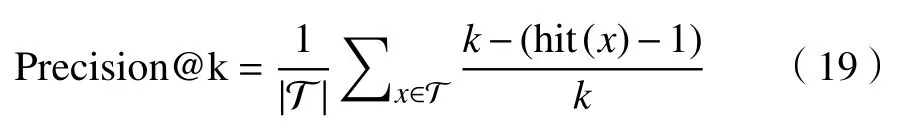
其中,h it(·)表示真实样例在前k个(top-k)候选样例评分列表中的位置,当真实样例不在top-k列表中时,返回k+1。
3)MRR,是一个信息检索领域常用的评价指标,预测结果中第1 个匹配则分数为1,第2 个匹配则分数为1/2,以此类推,第n个匹配则分数为1/n。最后取所有结果的平均值,计算公式为
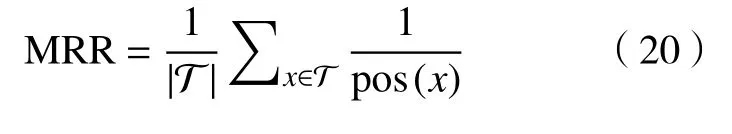
5 挑战与未来的研究方向
跨平台社交网络的用户对齐技术结合了数据挖掘、机器学习和自然语言处理技术的一些方法和技术,是一个综合性的研究方向。近年来,用户对齐问题受到越来越多研究者的关注,并在数据预处理、特征抽取、对齐模型等方向取得了大量研究成果,但仍然存在一些亟待解决的问题和挑战。
5.1 面临的挑战
5.1.1 数据获取的挑战
当前社交网络用户对齐研究的一个主要问题就是缺少可供研究者测试和评价算法的统一数据集。许多算法仍使用自己构建的数据集进行测试。为了获取算法评价所需的数据,研究人员面临以下挑战。
1)用户隐私。大部分社交网络平台都会注重对用户隐私进行保护,比较敏感的用户信息,如电话号码、Email 地址等往往不对外公开[20]。研究者需要在不侵犯用户个人隐私的情况下访问和使用用户数据进行数据集的构建。
2)访问受限。一些在线社交网站提供API 来访问它们的网络数据,但是它们通常只面向网站应用开发人员,并设置了访问许可限制、访问速率限制等(如微博),这使得大规模用户数据的获取难以实现。
5.1.2 数据质量的挑战
当今的在线社交网络数据庞大、嘈杂、不完整且高度非结构化[11],为跨社交网络用户对齐研究带来巨大挑战,主要表现在以下几方面。
1)用户属性的不一致。社交网络平台一般允许用户选择性地公开展示个人资料且对用户填写资料的真实性不加关注[35],而用户自身出于安全考虑也可能不愿意公布真实的个人信息,这就造成了不同平台之间用户信息的不一致。此外,文本格式、数量单位、缩写形式、语种、录入错误等也会给匹配过程带来巨大困难。
2)网络结构的不一致。不同社交网络往往提供了具有差异化的在线服务,单个网络只反映了用户真实世界社交圈的一个子集。例如,一个用户在豆瓣上关注了某位作者,但他们在微博上则不一定是朋友。这就使得一些依靠网络结构特征的用户对齐方法难以取得良好的效果。
5.2 未来的研究方向
5.2.1 多语言社交网络用户对齐
随着社交网络在全球的迅速普及和发展,各种语言的社交网络平台纷纷建立,不同语言社交网络平台之间的信息传播越发频繁。跨语言社交网络平台的用户对齐能促进信息传播、网络融合及网络安全等领域问题的研究。目前跨语言的社交网络用户对齐研究还很少,一些跨语言知识库实体对齐的研究[92−95]则可供借鉴。
5.2.2 多源社交网络用户对齐
当前用户对齐的研究大多集中在2 个网络平台之间的对齐,当涉及2 个以上社交网络的用户对齐时,需要考虑多个网络之间的相互依赖关系[19]以及对齐用户在多个网络之间的传递性[75],这就为多源场景的用户对齐研究带来了新的挑战和机遇。
5.2.3 用户对齐与隐私保护
近年来,隐私保护受到越来越多的关注,欧盟通用数据保护条例(GDPR[96])的出台更是从法律层面对用户数据的使用做出了严格规定。在不采用个人身份识别信息,特别是敏感身份信息,如完整的姓名、身份证号码、手机号码、电子邮箱地址等前提下选取适合的用户特征来构建用户对齐模型是未来研究的一个重要方向[72]。
6 总结
本文对近年来跨社交网络用户对齐技术的主要成果进行了综述,在对用户对齐相关概念、技术和方法深入研究的基础上,归纳了一个用户对齐问题研究的框架,同时从数据预处理、候选集生成、标记数据获取、特征抽取和对齐方法5 方面进行了概括,并重点对主流的用户对齐方法进行了详细阐述,最后探讨了当前用户对齐研究工作面临的挑战和未来的研究方向。跨社交网络用户对齐的研究工作目前仍处于高速发展阶段,虽然取得了一定的成果,但仍有大量的问题亟待解决。随着社交网络平台的不断发展以及网络数据规模的不断增大,未来将会有更多的研究方法和成果涌现出来,推动社交媒体研究不断向前发展。
