基于多尺度注意力特征的识别算法研究
2021-07-13张学军王文帅张丙克
张学军,周 云,杜 丹,郑 威,王文帅,张丙克
(1.中国电子科技集团公司第五十四研究所,河北 石家庄 050081;2.陆军装备部驻石家庄地区第一军代室,河北 石家庄 050081;3.中国人民解放军73602部队,江苏 南京 211100)
0 引言
不同于手工特征提取方法,使用深度卷积神经网络能够自动提取图像的表观特征[1]。然而不同的算法提取到的特征表征能力不同,最终的特征表征能力越强,越能反映视频中所发生的动作,模型算法识别准确率越高,因而构建一个表征能力强的特征成为计算机视觉领域中算法关键研究点。
1 尺度特征
在计算机视觉的目标检测任务中,模型需要对图像中不同大小的物体进行检测定位,通过观察可知单发多框检测(SSD)方法能够很好地解决这一问题[2]。SSD算法属于目标检测方法中的“一步式”方法,不同于“两步式”方法,“一步式”方法不需要提取计算候选区域,其特征提取与目标位置回归整合到卷积神经网络中,因而在速度上有很大的优势。SSD使用多尺度特征直接进行目标的位置回归和分类。在卷积过程中得到的特征图尺寸不一,大尺寸的特征图还包含丰富的底层表观信息,可用于检测一些细小的物体[3]。小尺寸的特征图经过多层的卷积操作,包含更为抽象的语义信息特征,可用于检测更为宏观的物体。SSD的模型框架如图1所示。
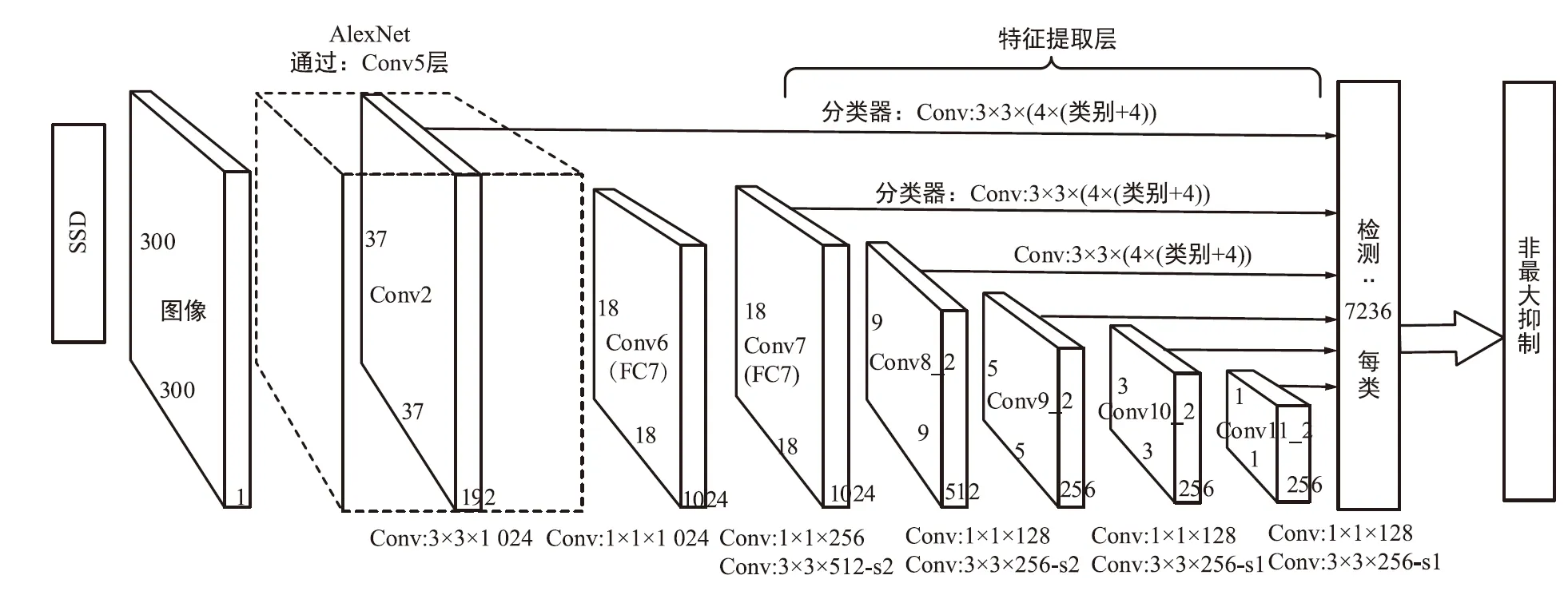
图1 SSD模型框架Fig.1 SSD model framework
SSD模型使用VGG16-SSD模型训练自己的数据集做识别,在VGG16基础上取消其最后两层全连接层,增加了额外的卷积层以获取更多不同尺寸的特征图。图中,Conv8、Conv9、Conv10、Conv11均为额外增加的卷积层[4]。
SSD算法的优势在于检测速度快,但也存在一定缺陷,模型网络对于小目标的检测效果不如对大目标的检测效果好,考虑添加更为精细的特征提取,引入注意力机制对网络中的特征进行增强[5]。
2 注意力机制
人类的视觉机制在观察事物时总是会优先把注意力聚焦于其感兴趣的部分,视频行为识别任务中,输入的视频数据除了包含人类对象,还包含了其他许多无关信息。引入注意力机制的目的是让神经网络模型也像人类一样更加关注图像中的显著部分[6]。注意力机制按形式分可分为两类:硬注意力机制和软注意力机制[7],如图2和图3所示。注意力机制本质是为图像中的像素点赋予一个权重掩膜,值得注意的像素点位置注意力权重高,无关的像素点位置注意力权重低。硬注意力机制只为像素点赋予0或1两个注意力权重值,被赋予0的像素点可以被视为舍弃,只留下被赋予1权重的像素点。软注意力机制的注意力权重范围在0~1之间,这位于[0,1]区间的连续分布注意力掩膜反应了不同区域受到模型关注的高低程度。在计算机视觉领域中一般都使用软注意力机制为图像赋予注意力权重,软注意力在学习过程中是可微的,在学习过程中可通过网络计算梯度反向传播进行权重的更新[8]。
此外不同注意力机制关注的域不同,可分为:关注图像空间中不同位置的方法、关注同一空间位置不同通道的方法、同时关注空间域和通道域的方法和关注时域的方法。不同的方法对应不同的应用场景[9]。

图2 硬注意力机制Fig.2 Hard attention mechanism

图3 软注意力机制Fig.3 Soft attention mechanism
3 多尺度注意力特征网络
3.1 用于目标检测领域
考虑到SSD算法在检测小目标时容易出现误检测,需要构建多尺度注意力特征网络来验证注意力特征对特征表征能力的增强效果,如图4所示。对于上文提到的SSD算法,本文对其结构做了一些改变,在SSD算法的后5个检测分支上添加注意力模块,从而构建了5个全新的检测分支。最后用于检测的分支为5个新分支和SSD原有的最后一个分支,最终的模型网络命名为多尺度注意力特征检测(MA-SSD)。使用Fi(i= 1,2,…,6)代表原始SSD的第i个检测分支所构建的特征,多尺度注意力特征网络中对后5个检测分支特征{F2,F3,…,F6}进行上采样操作,使其每个特征的大小与各自前一个检测分支特征的尺寸保持一致,可以使用反卷积操作来实现特征的上采样。经过上采样步骤后再将特征输入注意力模块,使得网络更加容易关注到图像中存在目标的区域,最后得到的注意力特征再与上一检测分支的特征相融合,作为新的检测分支特征进行检测[10]。第i个新检测分支得到的特征MA_Fi表示如下:
MA_Fi=Fi⊗F′i+1,i=1,2,…,5。
(1)
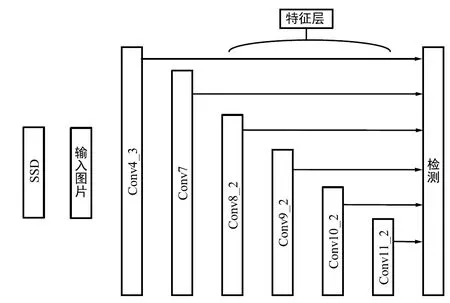
图4 多尺度注意力特征SSDFig.4 Multi-scale Attention Characteristics SSD
在此结构中,高层特征通过对特征上采样以及注意力模块为低层特征提供了一个注意力掩膜,增强了低层特征的表征能力。同时先进行下采样再进行上采样的操作也可以视为一个编码解码结构,在这种结构中使用注意力模块能够有效地使网络学习到图像数据中更为显著的区域,提高检测/分类精度[11]。

(2)
式中,λij代表该点的先验特征值。同理对于关注位置的软注意力机制,本文更关注特征中某个确定通道中一个位置上的像素点与该通道中其他像素点之间的softmax概率值,可以用式(3)表示其计算方式:
(3)
这两种不同关注域的软注意力机制的表现形式如图5所示,蓝色部分为该方式中更侧重关注的域。
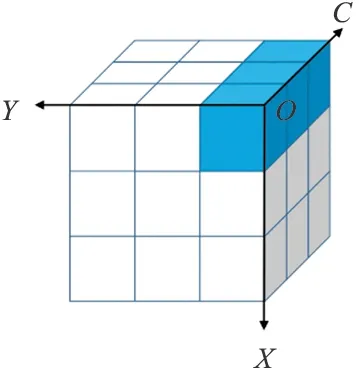
(a) C-Softmax
对于注意力机制的效果,通过验证发现F-softmax的效果更好,可见图像中物体的空间位置影响要比通道间权重影响大,后续会有实验结果证明这一点。
对于MA-SSD在目标检测领域中的应用,进行了验证分析。验证实验的数据集使用的是目标检测领域常用的数据集PascalVOC,实验的硬件环境为:单块Nvidia Titan X GPU(12 GByte内存),运行环境为pytorch 0.3版本深度学习框架。具体训练方式如下:
冻结第一阶段训练的模型参数不参与反向传播更新,将第一阶段训练的模型看作一个预训练模型用于本阶段,然后训练网络学习多尺度注意力分支的参数。在第一阶段中,使用随机梯度下降算法学习网络参数,批次大小设置为32,动量设置为0.9,重量衰减设置为0.000 5。将学习率初始化为0.001,并在经过80K和100K迭代后降低到原1/10,迭代总数为120K。在第二阶段,将基础网络和在第一阶段训练的额外层视为注意力检测分支的预训练模型,通过冻结SSD模型的基础网络额外层来训练注意力分支和预测层,设置学习率初始化为0.001,并在30K和80K迭代后降低到原1/10,整个训练在120K迭代次数时停止。
将MA-SSD与目标检测领域中一些有竞争力的方法进行了比较,实验结果如表1所示,实验结果的评价指标是mAP。MA-SSD在VOC2007数据集上取得了不错的检测效果:mAP 78.4%。相比于“两步式”的方法如Fast R-CNN/ Faster R-CNN,MA-SSD有着明显的优势。相比于没有使用到多尺度注意力特征的原始SSD算法,MA-SSD把检测精度提高了1%,特别对于检测细小的物体(如鸟类,瓶子),MA-SSD有着明显的优势,可见使用注意力机制加强低层特征能够增强SSD网络对于小目标的检测性能[12]。

表1 目标检测算法实验结果对比
使用不同的注意力机制最终的检测效果也不相同。在VOC2007上进行了对比实验,表2给出了对比上文提到的两种不同注意力形式的检测效果,不使用注意力模块时,检测分支相当于一个编解码结构,这仍然增强了特征分支中的特征表示,因而相对于SSD方法效果也有一定提升。使用F-Softmax的效果要比使用C-Softmax的效果更好,本文认为关注空间位置中的显著区域更能够加强整体网络的识别能力。

表2 使用不同注意力形式对比
3.2 用于视频行为识别领域
考虑在视频行为识别领域使用注意力机制增强不同尺度的特征以提升识别的精度。在视频动作识别任务中,与专门处理长期序列数据的方法(例如递归神经网络和长期短期记忆网络)相比,注意力机制更有效,更方便提取稀疏样本的相对重要特征,捕获特征之间的关系。对于待进行分类的视频数据,一般是将其处理成图像帧序列再送入神经网络模型。对于包含一定持续时间行为视频,如果仅从中选择一个小的连续帧并将其输入到卷积神经网络以进行特征提取,所获得的信息仅是某个特定区域的领域信息[13]。例如双流卷积神经网络算法就是如此,选取的光流片段只是一个短时序范围的片段,不一定能代表整个视频片段。但如果选择大范围的连续帧序列进行特征提取,由于随着帧数量增加动作不会发生明显变化,特征提取的结果将包含大量的冗余信息,将导致额外的计算成本。
本研究希望获得一个包含从动作发生到结束的特征表示,同时,希望此特征表示不会混杂太多的冗余信息。因此对于一个输入视频,将其平均划分为N个片段V=[V0,V1,…,VN-1],使用N个视频短片获取N个图像以构建有序帧序列F=[F0,F1,…,FN-1],Fn是从相应的视频段Vn中提取的视频帧。然后将帧序列输入到基础的卷积神经网络提取特征,通过一系列卷积操作即可获得代表整个视频的特征序列T=[T0,T1,…,TN-1]。考虑更稳定的特征提取过程,选择使用类似于SSD的基础网络作为特征提取网络,但与SSD中使用的VGG16不同,选择ResNet50作为基础卷积神经网络。此外,添加额外层来替换原始网络平均池化层和全连接层。多尺度注意力特征网络结构如图6所示。
在视频行为识别任务中所添加的注意力模块与添加在图像上的注意力模块有所不同。在不涉及时序信息的任务中,网络的注意力只需放在图像的空间域上。但在视频任务中,网络需要关注时间维度上像素点的显著变化。在模型中使用一种自注意力机机制,使得输入视频帧序列的每一个像素点能够保持与这个帧序列中其他所有位置(包括空间位置和时间位置)像素点之间的关系。
图像经过卷积后,某一层的特征图的某一个点可能包含原始图像中很大范围的信息,因为这一点的特征值相当于对原图部分信息的聚合,但其范围也是有限的。如果考虑不仅仅是局部特征点之间关联,而将这一点的特征值与特征图中所有范围内点的特征值之间的关系进行计算,即可计算出该点相对于所有点的一个权重。在构建的自注意模块中,T是由某个卷积层获得的特征图序列,自注意力模块接收T作为输入来执行非局部的自注意力操作:SA(Xi,Xj),其中Xi为输入特征的某个点的像素值,Xj为其余所有可能位置点的像素值。基本的自注意力操作可以解释为:
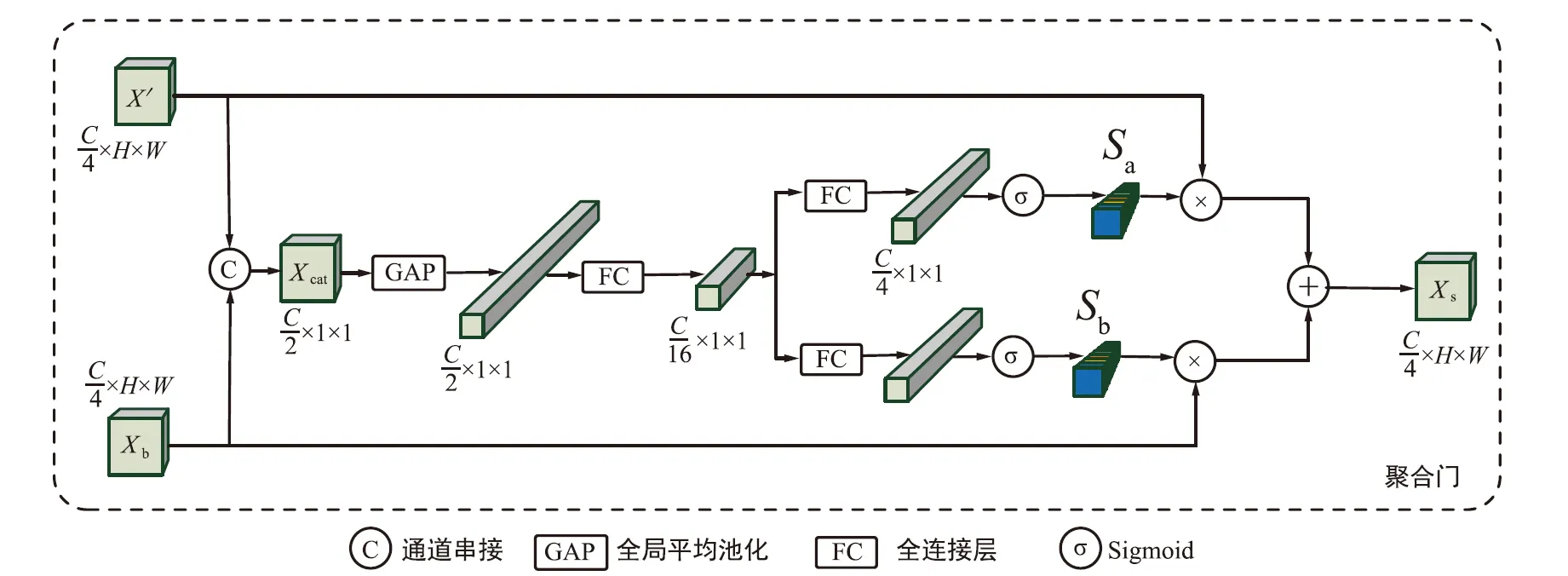
图6 多尺度注意力特征网络结构图Fig.6 Structure diagram of multi-scale attention feature network
(4)
式中,Yi表示通过计算后的Xi所对应的自主注意力特征值,可从式(4)中看出,某一个位置的点与其他所有点都进行了计算,这样更能反应该点相对于空间域以及时域上与其他特征点的关系。可以将其特征序表示为式(5),其中Tatt为时间特征序列。
(5)
在时间特征模块中,仅使用2D卷积核来捕获帧之间的时间表示。对于大小为N×C×H×W的特征序列T,首先将通道数减少为原始通道的1/16,然后对其中后N-1帧的特征Tn+1进行2D卷积运算,然后从前一帧的特征Tn中减去。该模块通过计算两个帧之间的像素偏移量来捕获两个帧之间的运动提示:
T′n=Conv(Tn+1)-Tn。
(6)
通过计算N个帧之间的运动信息,网络可以获得N-1个时间特征序列。为了与原始输入大小一致,在特征序列的末尾添加了一个全零的特征,以表示最后一个时间点的运动信息。 最后再恢复通道数以确保与输入的一致性。 将自注意力模块获得的特征与时间特征模块获得的特征融合在一起后,形成原始输入特征进行跳过层连接以获得关注的时空特征表示并输入至后续网络:
T=T+T′+Tatt。
(7)
在两块Nvidia Titan X GPU(12 GByte内存)上训练MAST,采用pytorch 1.0实现。 GPU能执行大规模的并行操作,可以加速网络计算,所有输入图像的尺寸为224×224。使用随机梯度下降算法来学习网络参数,批量大小设置为64,动量设置为0.9。将学习率初始化为0.001,并在40和80个epoch后降低到原1/10,epoch总数为100。在实验中,统一采样的帧数N设置为8。基础网络Resnet50模型已在ImageNet数据集上进行了预训练,在Conv_4x之后替换了池化层和全连接层,有关具体的网络参数如表3所示。
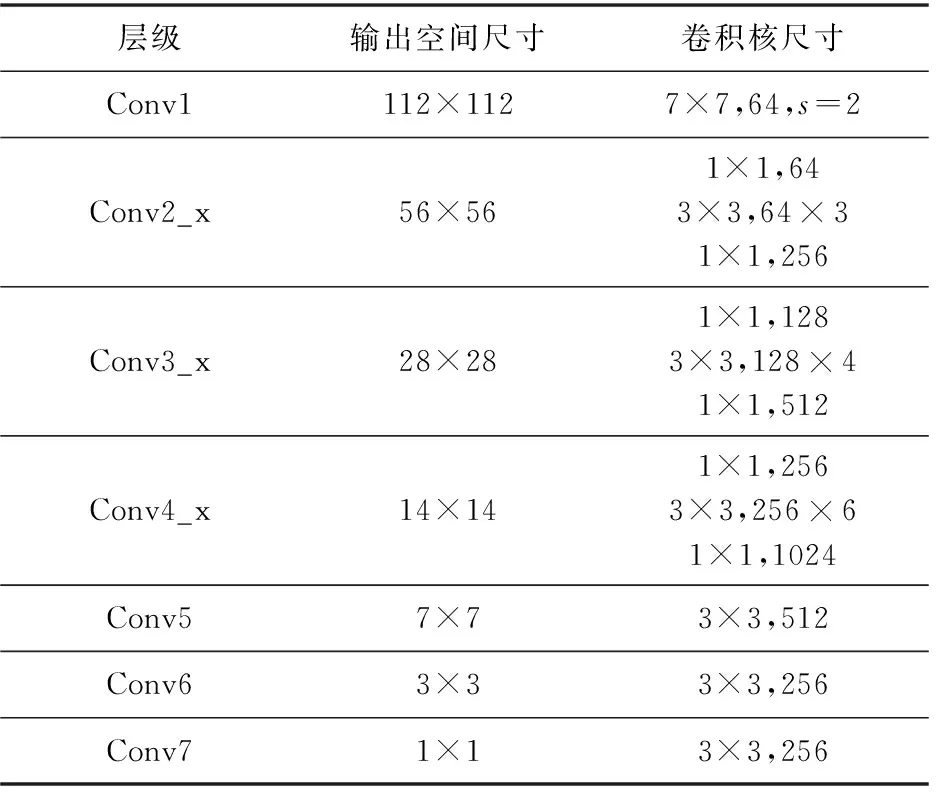
表3 多尺度注意力特征网络结构
将MAST与视频行为识别领域一些具有代表性的算法进行了实验对比,在UCF101和HMDB51两个数据集上进行实验。实验结果如表4所示,可以看出传统的手工提取特征方法与基于深度学习的识别方法相比已没有优势。相比于C3D使用三维卷积核进行特征提取,本文的方法使用自注意力模块加强了特征表示,在UCF101上识别精度提升了8.4%,也进一步说明了不需要三位卷积核也能够实现时序特征的构建。双流卷积神经网络(Two-stream)使用了光流作为其时间特征,识别精度已经取得了不错的效果,但MAST的识别精度在其基础上提升了2.7%,证明了多尺度注意力方法在光流面前也具有一定优势。而双流算法的衍生算法TSN也采用均匀间隔采样的方式进行特征提取,MAST相较于此构建了注意力特征,能够识别行为在时间维度上的显著发生点,因而MAST的识别效果要领先于TSN。相较于同样只使用了原始图像视频帧作为输入的方法STC,MAST的效果没有明显优势。STC考虑了不同通道间的特征,并且使用了深层次的网络模型(ResNet101),这些机制都能够使特征的表征能力更为强大,这是未来工作中可以考虑的研究点。

表4 实验结果对比
4 结论
主要介绍了多尺度特征思想以及注意力机制加强卷积特征的方法。在目标检测领域上,通过实验验证了注意力机制的有效性,加入多尺度注意力特征的网络模型对目标检测的结果有了进一步提升。在视频行为识别领域,本文提出的方法主要由基础网络、注意力模块和时间特征构建模块组成。输入网络的视频数据经过等间隔采样,采样后得到的帧数量为8,实验结果证明了本文所提方法的有效性。
