改进的YOLOv4-tiny行人检测算法研究
2021-07-13周华平孙克雷
周华平,王 京,孙克雷
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引言
作为目标检测重要研究领域之一,行人检测在视频监控、自动驾驶及无人机等方面的应用十分广泛[1]。使用深度卷积来构建目标检测网络,给行人检测领域带来了深远影响[2]。RCNN及其改进系列模型[3]在候选建议框的基础上对框进行分类和回归,对提高精确度帮助很大,但检测速度降低。SSD[4]和YOLO系列[5]等一阶段算法,同时完成目标分类和定位任务,极大地提升了检测速度。YOLO系列的简化版本对硬件要求低、速度快,在小型设备平台上使用更广泛[6]。李文涛等人[7]通过选择更小的预选框,并混合使用SE (Squeeze and Excitation)模块与卷积块注意模块 (Convolutional Block Attention Module,CBAM)对行人和农机障碍物进行检测。单美静等人[8]基于TinyYOLO轻量级网络的交通标志检测,使用部分残差连接增强网络的学习能力。但各种深度学习检测模型权重体积较大,不能很好支撑实时行人检测。因此,该文对YOLOv4-tiny网络结构进行改进,引入新的注意力机制——残差机制(Enhanced Spatial Attention_CSP,ESA_CSP)以及多尺度特征融合模块(Ring-fenced Bodies,RFBs),在维持较快的检测速度和较小的权重体积为前提,提高检测精度,更适合小型设备的实时行人检测。
1 理论基础
1.1 YOLOv4-tiny算法
区别于YOLOv4的深层复杂网络结构,YOLOv4-tiny的网络结构在其基础上要精简许多,计算量小,能够在移动端或设备端运行。YOLOv4-tiny的网络模型如图1所示,其中骨干网络采用的是CSPDarknet53-tiny的网络结构,主要包括普通卷积过程、残差结构堆叠过程和下采样过程。普通卷积过程采用CBL结构,由卷积层(Convolutional)、批量标准化层(BN)以及激活函数层(LeakyRelu)构成,下采样过程通过最大池化(Maxpool)操作完成。残差结构堆叠过程采用了CSP(Cross Stage Partial Connections)结构。CSP结构将输入特征在残差块堆叠通道旁再增加一条残差边通道,然后将两个通道进行Concat操作后输出结果。

图1 YOLOv4-tiny网络结构Fig.1 YOLOv4-tiny network structure
主干网络会将13×13的特征层进行上操作后与26×26的特征层进行融合,提高特征提取能力,最后会分别生成通道数为na×(nc+5)的两个输出通道,na代表锚框数量;nc为类别数。26×26的通道预测小目标,13×13的通道预测大目标。
1.2 注意力机制
1.2.1 CBAM
CBAM[9]是把通道注意力和空间注意力串联相结合组成的注意力模块。首先将输入特征分为两部分,部分1生成通道注意力块(Channel Attention Moudle,CAM),再与部分2在通道上进行相乘得到融合通道注意力的特征图;然后将该特征图继续分为两部分,部分1生成的空间注意力块(Spatial Attention Moudle,SAM),再与部分2在空间上相乘输出融合通道和空间注意力的最终特征图,CBAM注意力模块如图2所示。
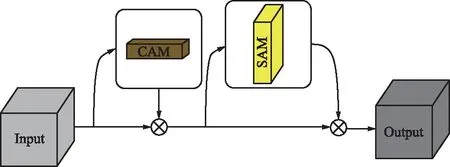
图2 CBAM注意力模块Fig.2 CBAM attention module
1.2.2 ECA注意力机制
ECA(Efficient Channel Attention)注意力机制[10]是对SE模块[11]增加一些改进策略:在对特征通道不降维的情况下,实现局部跨信道信息融合策略,可动态调整选择一维卷积核尺寸,减少模型的复杂度和计算量。
SE模块首先在输入特征的每个通道空间上进行全局平均池化对其压缩(Squeeze),然后通过两个非线性的全连接层(Fully Connected Layers,FC)来对特征层激发(Excitation),SE模块如图3(a)所示。实证分析表明,激发过程中的降维会对通道关注度的预测结果产生影响[10],且对所有通道的信息进行融合时效率比较低。ECA在对输入特征进行全局平均池化之后,不改变通道的维度,使用大小为k的快速一维卷积来捕获每个通道的局部跨通道交互信息。如图3(b)所示,是k=3时的ECA注意力机制块。
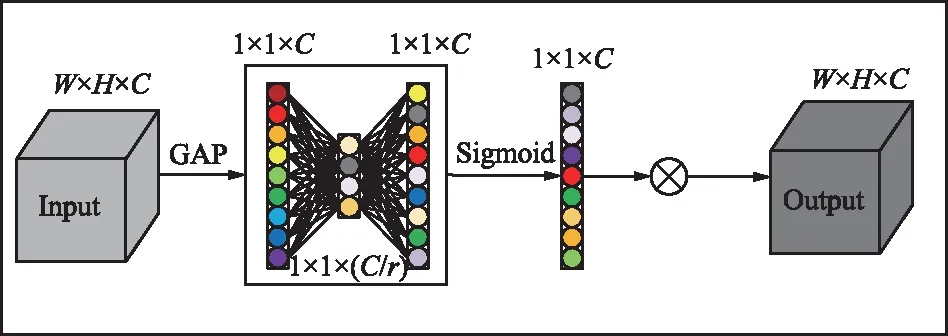
(a) SE注意力机制
图3(b)中,k代表该通道附近通道中,参与该通道的注意力预测的通道数。k值可以通过总通道数C的函数自适应地确定,计算公式为:
(1)
式中,|x|odd表示x最近的奇数,b=1,γ=2。
1.3 空洞卷积
空洞卷积 (Dilated/Atrous Convolution)[12]可以在保证特征图分辨率不下降、网络参数量不增加的情况下,增大卷积操作的感受野,有效捕获多尺度特征信息。空洞卷积就是在普通卷积过程中加入大小不同的间隔,间隔的大小用扩张率(Dilation Rate)表示,普通卷积相当于扩张率为1的空洞卷积。图4为扩张率分别为1、2、3的空洞卷积过程。

(a) 扩张率=1
2 改进的YOLOv4-tiny算法
对YOLOv4-tiny网络进行分析后,提出了3种改进的新网络结构(YOLOv4-tinye、YOLOv4-tinyr和YOLOv4-tinyer)。YOLOv4-tinye模型对原模型的CSP结构进行分析,在CSP结构尾部添加ESA-CSP,计算特征图在通道位置和空间位置上的权重信息,根据权重分配使网络更多关注特征图中有利于检测任务的行人区域特征信息,抑制背景及其他非行人次要信息,从而提升网络模型性能[13]。
低层特征含有的目标位置信息比较准确,使用最大池化层能降低图像尺寸,但最大池化层不更新权值参数,可能会丢失目标位置信息[14]。带参数的卷积层会保留更多特征图信息,因此使用大小2×2、步长为2的卷积核代替主干网络结构中的最大池化过程。
经过一系列下采样CBL结构和多次卷积操作,会使得深层网络的目标定位存在误差,因此在主干网络后,构建一个RFBs结构增大提取目标的感受野,得到YOLOv4-tinyr模型,提高网络的特征融合能力。融合YOLOv4-tinye和YOLOv4-tinyr得到最终的YOLOv4-tinyer模型。改进后的3种模型获得两种不同尺度的检测头输出,分别检测大目标和小目标。YOLOv4-tinyer模型结构图5所示。
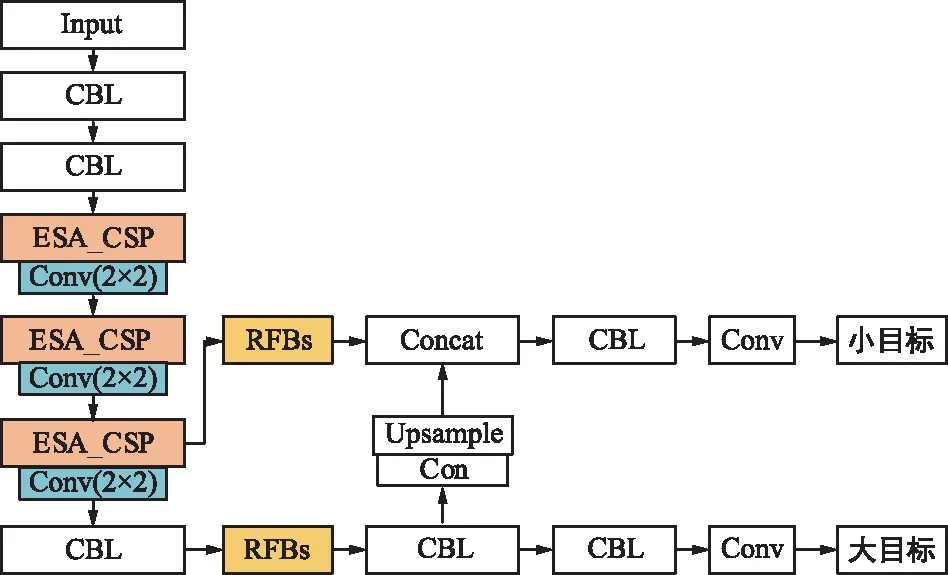
图5 YOLOv4-tinyer网络结构Fig.5 YOLOv4-tinyer network structure
2.1 改进的ESA_CSP结构
卷积神经网络除了学习到目标的特征外,还包含了大量无效背景信息,这就会导致在神经元中含有大量背景信息,影响检测性能。另外,YOLOv4-tiny中使用剪枝处理后的CSPDarknet53-tiny主干网络结构,大量剪枝的卷积层和残差单元造成了边缘特征信息不易捕捉,学习的特征表现不够好,有效特征不够明显影响识别精度。针对这个问题,借鉴CBAM和ECA注意力机制思想,在CSP残差结构输出通道后添加ESA注意力机制,提出ESA_CSP注意力残差块结构,如图6所示。
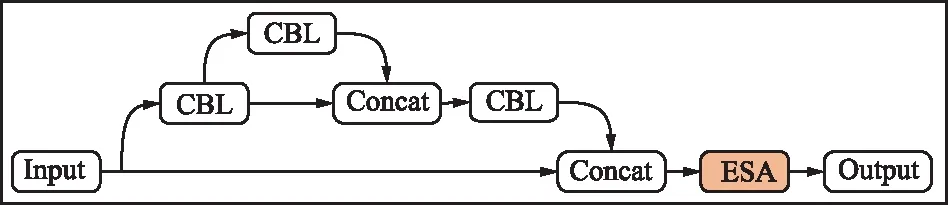
图6 ESA_CSP注意力残差块结构Fig.6 ESA_CSP attention residual block structure
ESA_CSP中的ESA注意力块借鉴CBAM思想,首先根据模型的首层特征图,获得通道、空间注意力权重图,然后分别将其和原特征图点乘,得到带有权重的空间和通道特征图。最后对空间和通道特征图进行并联相加操作,得到带有注意力权重的特征图,ESA注意力结构如图7所示。

图7 ESA注意力结构Fig.7 ESA attention structure
其中,ESA注意力机制中的SAM在空间位置上对输入特征图上相同位置的像素值进行全局的MaxPooling和AvgPooling操作,分别得到两个空间注意力权重FSA和FSM,通过Concat操作将FSA和FSM在通道维度合并为一个2通道的特征图。然后使用3×3的卷积核构成的卷积层,对FSA和FSM压缩通道为1,得到的特征图大小为W×H×1,最后经过Sigmoid函数对其激活,得到空间注意力块。ESA注意力机制中SAM注意力块,如图8所示。

图8 SAM注意力模块Fig.8 SAM attention module

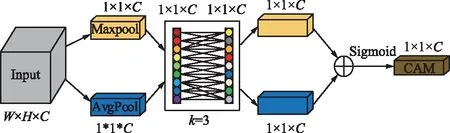
图9 ESA中的通道注意力结构Fig.9 Channel attention structure in ESA
ESA_CSP结构将经过残差结构操作后特征层的空间位置、通道位置等相对重要的特征提取出来并赋予较高权重,从而保留目标区域特征,提高检测性能。
2.2 改进的RFBs结构
为了捕获行人的多尺度特征信息,在改进后的主干网络后连接RFBs结构模块。该结构模块主要引入空洞卷积,实现增大感受野、融合不同尺寸特征的目的。
RFBs结构首先将特征图进行1×1卷积进行通道变换,然后进行多分支空洞结构处理,用来获取目标多尺度信息特征。多分支结构中采用普通卷积层+空洞卷积层的结构,普通卷积层中原RFB结构中的3×3卷积核用并联的1×3和3×1卷积核代替,5×5卷积核用两个串联的1×3和3×1卷积核代替,这样可以有效减少网络的计算量,保证整个网络轻量化。空洞卷积层分别由3个大小为3×3的卷积核组成,卷积核的扩张率分别为1、3、5,防止扩张率太大造成卷积层退化。最后将经过多分支空洞结构处理过后的不同尺寸的特征层进行Concat操作,并输出新的融合特征层。为了保留输入特征图的原有信息,将新的融合特征层经过1×1卷积层变换通道,与原特征图构成的大残差边进行累加操作后输出。多分支结构中的RFBs连接结构如图10所示。
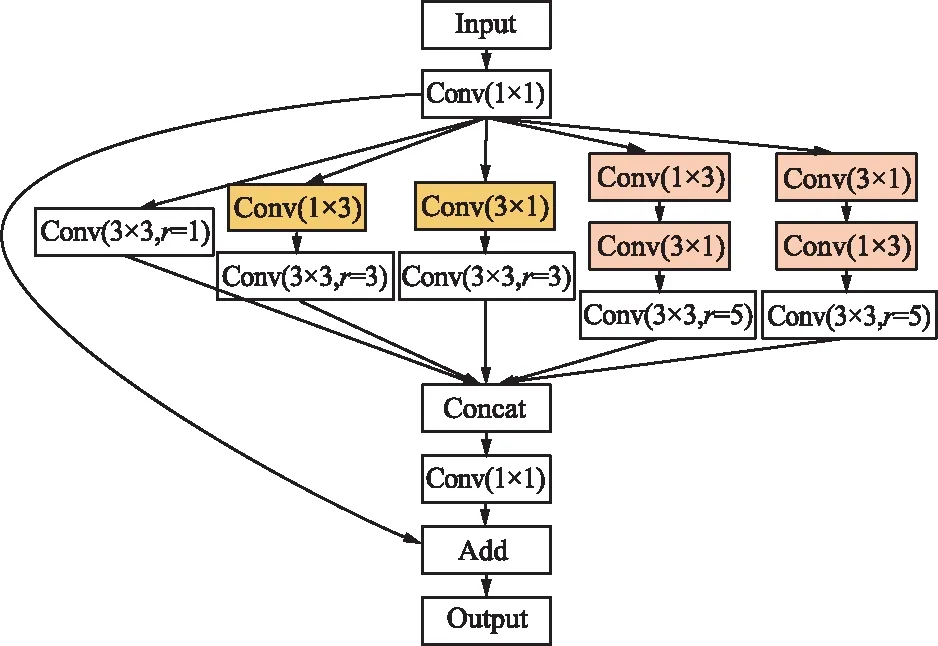
图10 RFBs结构Fig.10 RFBs structure
3 实验
实验所使用的操作系统为Win10 64位;内存大小为32 G;GPU为NVIDIA GeForce GTX1080ti;学习框架采用Tensorflow2.2.0/cuda10.1/cudnn7.6.3;编译环境为Pycharm/Python语言。
3.1 数据集
实验所使用的数据集是WiderPerson。该数据集是户外的行人检测基准数据集,其图像不再局限于交通场景,而是从多种场景中选择更符合视频监控的真实场景。数据集中共包含5种类型的行人实体:pedestrians、riders、partially-visible persons、ignore regions和crowd,实验时选择前3种行人实体。原数据集中共包含13 382张图像,训练集、验证集和测试集分别有8 000、1 000和4 382张图片。由于原数据集中的测试数据集真实框标签未公布,实验中将原8 000张训练集图像根据9:1的比例划分为训练集和验证集,将原验证集图像作为测试集。
3.2 先验框聚类分析
为了适应实验数据集中行人宽高比固定的特点,需要对数据集重新聚类出符合目标的anchor boxes。先验框的大小与检测目标越接近,检测效果越好。实验选用k-means++聚类算法[15]对聚类中心的选择进行改进,得到更符合行人目标的anchor boxes。k-means++算法具体步骤如下所示。

算法 k-means++锚框聚类算法 输入 数据集中行人宽高集合S和聚类中心数量k输出 k组锚框① 随机从集合S中选某个点,成为第一个聚类中心О1。② 计算S中其余各点x到其最近聚类中心Оx的距离D(x),距离越远的锚框点成为下一个聚类中心的概率P(x)越大。重复此步骤,直到找到k个聚类中心。③ 计算所有S中的点分别到k个聚类中心的距离D(x),将该点划分到距离最小的聚类中心类别中。针对聚类结果,重新计算每个聚类类别的聚类中心Ci。④ 重复步骤③,每个聚类类别的聚类中心Ci不再变化时,输出k个聚类中心结果。
在k-means ++算法中,选择IOU作为距离D(x)度量标准,IOU为真实框x和与x最近的聚类中心锚框Оx的交并比。距离D(x)、概率P(x)和聚类中心Ci的计算公式分别为:
(2)
(3)
(4)
经过聚类,得到了6组锚盒:(6,14)、(10,27)、(15,47)、(21,77)、(33,118)、(51,188),avg-iou值为71.63%。
3.3 评价指标
实验中使用的评价指标为FPS和 mAP。FPS为每秒检测图像的帧率;mAP为多分类检测模型中所有类别的AP均值,其值越大表示该模型的定位与识别的准确率越高,mAP的计算公式为:
(5)
式中,C表示类别数;AP表示每个类别的平均精确率,由Precision-Recall曲线下的面积计算得出。
3.4 实验结果与分析
实验中训练行人检测网络模型的参数设置如下:采用的初始学习率为1×10-4,当验证集的准确率在10个时期内没上升,则学习率衰减1/2;优化器使用Adam;根据显存大小,将批处理数量设为16。网络训练迭代时期设为200,并设置了早停(Early Stopping)机制,即在网络性能连续20个时期没有改善或完成最大200个时期的循环时,训练过程就会终止,并保存训练模型的权重。
为了进行充分对比实验,分别对YOLOv4-tiny模型与加入ESA_CSP的模型(YOLOv4-tinye)、加入RFBs的模型(YOLOv4-tinyr)以及同时加入ESA_CSP和RFBs的模型(YOLOv4-tinyer)进行训练对比,实验结果如表1所示。

表1 各模型的实验效果对比
由表1可知,与模型参数量相差不大的YOLOv4-tiny模型相比,YOLOv4-tinye模型、YOLOv4-tinyr模型和YOLOv4-tinyer在整个数据集中平均准确率分别提高了2.27%、2.45%和4.78%。其主要原因是加入注意力机制的ESA_CSP残差结构能更关注特征图中空间和通道位置上的关键信息,更好提取图像特征,多尺度融合增强模型RFBs加强对特征的利用率,提高行人检测的准确率。FPS略低则是由于随着mAP的提高,会检测出更多目标框,增加了时间开销,但该检测速度仍符合实际检测场景的实时性要求。
为了直观展示出原YOLOv4-tiny算法和提出的YOLOv4-tinyer检测算法的不同之处,选取了一些检测图像进行对比分析,YOLOv4-tiny和YOLOv4-tinyer的检测结果,分别如图11和图12所示。
由图11和图12可以看出,YOLOv4-tinyer检测算法与YOLOv4-tiny检测算法相比,行人检测的目标框定位的精确度提高。同时,对于相对较远的目标来说,YOLOv4-tinyer算法仍能够识别出,但是原YOLOv4-tiny则无法检测。因此,相较于原YOLOv4-tiny算法,YOLOv4-tinyer检测算法的检测效果更好。

图11 YOLOv4-tiny检测结果Fig.11 Detection results of YOLOv4-tiny

图12 YOLOv4-tinyer检测结果Fig.12 Detection results of YOLOv4-tinyer
4 结束语
本文基于YOLOv4-tiny网络模型提出了3种改进的YOLOv4-tinye、YOLOv4-tinyr和YOLOv4-tinyer网络行人检测模型。YOLOv4-tinye模型中将注意力机制引入到CSP残差网络结构中,提出ESA_CSP结构,使网络对图像中主要的特征信息附有更多的权重。YOLOv4-tinyr模型中在主干网络后添加RFBs结构,通过不同尺度的空洞卷积获得更大的感受野,并对多尺度信息进行融合,有效提升了模型特征利用率。YOLOv4-tinyer模型是YOLOv4-tinye和YOLOv4-tinyr模型的结合版。在实验过程中,使用k-means++算法重构WinderPerson数据集中的锚框,使目标定位更加准确,加快模型损失收敛速度。实验结果表明,在WinderPerson数据集中,本文模型的参数量和检测速度与原模型相当,但检测精确度均取得了更好的效果,更适用于小型设备的实时行人检测任务。
