基于深度学习的垃圾图像分类模型的研究
2021-07-12洪树亮巴丽合亚卡里布汗程丽娟
洪树亮,巴丽合亚·卡里布汗,程丽娟
(新疆工程学院,新疆 乌鲁木齐 830023)
0 引言
为将垃圾分类真正落实到每个人身上,积极引导市民参与垃圾分类,提升居民的垃圾分类意识,同时将加强社区定时定点的督导工作,引导社区居民进行准确的垃圾分类,增强人们垃圾分类意识的同时更需要提升垃圾分类的技术。传统的目标检测主要以人工特征检测算法为主,通常用滑动窗口的方式,即一个窗口,在检测图片上滑动进行依次选取感兴趣区域,分别对滑动的每个窗口进行特征提取,比如SIFT,HOG等特征提取算法进行提取特征,之后对提取的特征利用机器学习算法,比如支持向量机等进行分类,最终得到该窗口是否包含某一类物体。
1 相关工作
随着卷积神经网络(CNN)在2012年的兴起,目标检测开始了在深度学习下进行分类识别。在深度学习下,目标检测的效果比传统手工特征效果更加突出。目前,基于深度学习的检测算法依然是目标检测的主流。
深度学习目标检测的框架主要分为两类:两阶段(Two Stages)算法和单阶段(One Stage)。两阶段(Two Stages)目标检测算法首先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类,常见的算法有R-CNN、Fast R-CNN、Faster R-CNN等。单阶段(One Stage)不需要产生候选框,直接将目标框定位的问题转化为回归问题处理,无需候选区域(Region Proposal),常见的算法有YOLO、SSD等。
R-CNN[1]是目标检测的开山之作,首先由Selective Search图像聚类算法生成大约2000个区域候选框(Region Proposal),将生成的每个区域候选框(Region Proposal)分别送入到CNN进行特征提取,接着送入全连接网络,最后使用SVM线性分类器进行分类,检测准确率较传统的目标检测提高了很多,但检测运行时间比较慢。
Fast R-CNN[2]是在R-CNN基础上进行改进,将生成的候选区域(Region Proposal)整体送入CNN,同样使用SVM线性分类器进行分类,检测速度较R-CNN有明显提升。
Faster R-CNN[3]是在Fast R-CNN基础上进行改进,将R-CNN和Fast R-CNN生成候选区域(Region Proposal)的Selective Search图像聚类算法用RPN网络替代,最大的优势在于共用Faster R-CNN的Backbone,在准确率和检测速度较Fast R-CNN有较大提升。
YOLOv3[4]算法也借鉴了Faster R-CNN算法的思想,检测准确率比Faster R-CNN要低,但在检测速度上较Faster R-CNN更胜一筹。
对于上述两种方式,基于候选区域(Region Proposal)的方法在检测准确率和定位精度上占优,基于端到端(End-to-End)的算法速度占优。本文基于深度学习的垃圾图像分类,涉及到检测准确率、定位精度、算法速度以及小样本目标检测,实验结果验证,采用改进YOLOv3深度学习架构垃圾图像分类模型的效果最优。
2 YOLOv3算法原理
本文YOLOv3使用的基础网络是Darknet-53,Darknet-53深度学习框架有着非常好的图像识别的效果[5],网络结构如图1。
YOLOv3算法的基本思想,一般使用416×416大小的图片作为输入,首先进行特征提取生成固定大小的特征图,主干网络使用Darknet-53结构,最后得到特征图大小为13×13、26×26、52×52,YOLOv3的网络结构图如图2[5]。
图1中的DBL是YOLOv3的基本组件,Darknet53的卷积层后接Batch Normalization(BN)和Leaky ReLU。除最后一层卷积层外,在YOLOv3中BN和Leaky ReLU共同构成了最小组件。

图1 Darknet-53网络结构

图2 YOLOv3网络结构图
主干网络中使用了5个resn结构,n代表数字,有res1,res2, ,res8等等,表示这个res_block里含有n个res_unit,这是YOLOv3的大组件。从YOLOv3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深。
输入图像分成13×13的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。每个object有固定数量的bounding box,YOLOv3中有三个bounding box,使用逻辑回归确定用来预测的回归框。
边框回归主要是解决目标框和锚框之间的相对位置关系,通过边框回归使得锚框更接近目标框,提高目标检测的准确度,边框回归如图3[5]。
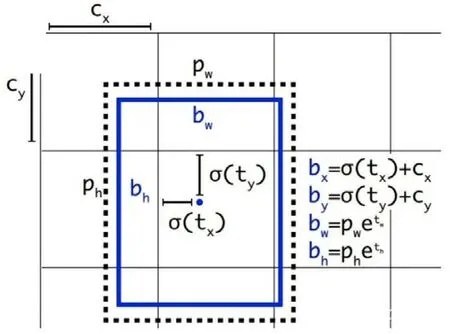
图3 边框回归图
边框回归公示如下所示:

3 数据集训练
人工智能快速发展,相关的框架、算法等层出不穷,要检验一个算法的好坏,就需要用有关的数据集进行实验,目前一些AI领域公开的数据集,如COCO,ImageNet等数据集,用户可以在AI算法项目中直接使用,使用训练好的模型测试自己的数据集,同样地,用户可以建立自己的数据集在AI算法上训练和测试[6]。
建立数据集:
第一步,准备图片。本文主要以生活垃圾分类为主,先从网上下载生活垃圾图片,每个种类下载200张左右即可,保存在YOLOv3相应的目录下。第二步,用Labellmg标注图片,标注文件为.txt格式,与图片同名。第三步,制作训练数据和测试数据集文件。用下面的Python脚本文件制作训练数据集文件“train.txt”和测试数据集文件“test.txt”。第四步,创建类别名文件,文件夹的每一行是一个对象的名称。第五步,数据集配置文件。第六步,模型配置。第七步,下载Darknet源码。第八步,启动YOLOv3模型训练。第九步,测试训练模型。
4 实验结果
本文垃圾图像分类YOLOv3算法在深度学习中的tensorflow2.0和Open CV平台。本实验首先使用COCO数据集训练的模型进行测试,COCO数据集主要是针对目标检测所创建的数据库,类别比较丰富,可以用COCO数据集训练的参数对自己建立的数据集进行测试[7]。其次使用自己创建的数据集在改进YOLOv3进行训练和测试,利用改进YOLOv3算法精度要高。通过实验验证了改进YOLOv3用于垃圾图像目标检测的可行性和高效性,但存在数据较少、目标标注引入干扰背景的问题, 后续的工作可以针对数据集进行优化扩展。
5 结语
随着视觉大数据的出现,单阶段的YOLOv3深度学习算法的准确率相比两阶段Faster R-CNN深度学习算法要低,但是在检测快速性上YOLOv3更胜一筹,本文提出了使用YOLOv3算法进行垃圾图片的识别和分类,系统使用自己建立数据集,用于对象检测的模式预测和训练算法。
