基于协同训练的集成自适应GPR-RVM多输出模型研究
2021-07-12李东黄道平许翀刘乙奇
李东 黄道平 许翀 刘乙奇
(华南理工大学 自动化科学与工程学院,广东 广州 510640)
水处理过程包含了一系列复杂多变的生化反应。近年来,国家对于污水处理过程中出水质量指标的管控越来越严格,但仍有许多重要的出水指标(5日生化需氧量(BOD5)、化学需氧量(COD)等)都无法准确地监测,特别是偏远地区和农村地区的污水厂。超大型城市的污水厂虽然安装了在线监测仪器仪表,但普遍存在价格昂贵、维护成本高、监测精度差、使用寿命短等问题。因此,利用软测量技术实现对污水处理过程重要出水指标的有效监测具有重要的意义[1]。
软测量技术通过收集污水处理过程中的易测量变量,分析易测量变量与难测量变量间的数理关系,从而建立预测模型,实现对难测量变量的预测。近年来,对于污水处理过程难测量变量的预测问题,引起了众多学者的广泛关注。郭晓燕等[2]将粒子群算法与反馈(BP)神经网络结合实现了对污泥容积指数(SVI)的有效预测;赵超等[3]对最小二乘支持向量机(LSSVM)进行改进,实验表明,加权最小二乘支持向量机对总氮(TN)和总磷(TP)的预测结果最佳;然而,这些模型的迭代时间较长,降低了模型的预测效率。邱禹等[4]提出了一种基于深层神经网络的多输出自适应软测量模型,用于对多个出水变量(BOD、COD和SVI等)的同步在线预测;但是,要使多输出模型发挥优势,建模数据的输入-输出分布要具备统一性。卢超等[5]针对氨氮的实时测量问题,提出了一种基于尖峰自组织径向基神经网络(RBF)的软测量方法;然而,预测模型的建立需要收集大量的训练数据。
在污水处理过程中,标记数据(同时包含输入变量和输出变量)和未标记数据(仅包含输入变量)间的比例严重失调。上述的监督学习方法会丢弃大量未标记数据,从而导致数据资源的浪费[6]。此外,采用传统化验测量的方法补充未标记数据缺少的输出变量,成本高昂且缺乏时效性。为了更加充分地使用未标记数据,近年来,半监督学习方法得到广泛地研究。刘小兰等[7]提出了一种基于最小熵正则化的半监督分类算法,该算法能够在标记数据较少的情况下,通过使用未标记数据,保证模型仍具有较高的分类质量;史旭东等[8]对自训练的半监督算法进行改进,并与GPR方法结合,实现对脱丁烷塔塔底丁烷浓度的预测;Yao等[9]用协同训练的半监督方法迭代调用极限学习机,建立了可以广泛应用到工业过程的软测量模型;但是,现有的半监督软测量模型多为离线的单输出模型,模型经过长时间的使用后,预测结果已经不够理想。此外,随着污水处理工艺越来越复杂,需要监测的变量也随之增多,传统的单输出模型效率低下,无法满足需求。
为了提高模型的自适应性,模型的优化方法得到广泛地研究。刘乙奇等[10]对即时学习算法进行改进,应用到污水处理监测中;Cong等[11]提出了一种自适应加权融合的方法来优化小波神经网络模型,在外部条件频繁变化的情况下,对水质COD的预测也能满足监测要求;吴菁等[12]利用时间差分方法改进多核相关向量的动态特征,提升了模型的预测性能。然而,这类自适应方法的优化模式单一,泛化能力弱。
基于上述分析,文中提出了一种基于协同训练的集成自适应多输出软测量模型,首先利用高斯过程回归和相关向量机两种不同类别的方法建立一个异构的软测量模型;然后通过移动窗口[13]和卡尔曼滤波[14]分别对模型的结构和参数进行更新;最后通过实际污水厂的实验对模型的预测性能和自适应性进行验证。
1 基本知识
1.1 高斯过程模型
高斯过程可以表示为随机变量的集合,该集合中的任意随机变量组合都服从联合高斯分布。高斯过程模型是由均值函数和协方差函数唯一确定,并且通常情况下,均值函数可以假定为零,因此,只需要确定协方差函数便可以确定高斯过程模型[15]。文中,将高斯过程模型应用到多输出系统,同时对多个输出变量预测;因此,在保留原有算法结构的基础上,将输出变量定义为多维矩阵。文中将标记数据记为
(X,Y)={(x1,y1),…,(xl,yl)},
其中:X∈Rl×m、Y∈Rl×n,m和n分别表示输入和输出的变量个数,l为数据数量。
输入和输出变量之间的关系如下:
Y=f(X)+ε
(1)
f(X)~GP(0,K(·,·))
(2)

协方差矩阵K的计算函数众多,文中利用径向基协方差函数计算协方差矩阵。
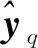
(3)
(4)
其中,k(xq)表示测试数据xq与每个训练数据之间的协方差向量,k(xq,xq)是xq与本身的协方差,K是训练数据集合的协方差矩阵。
对于小样本、非线性但高维度的数据集合,高斯过程回归可以达到令人满意的预测效果。此外,由高斯过程回归建立的预测模型,参数较少,计算过程更快,是一种高效且稳定的概率预测方法。
1.2 相关向量机
相关向量机是一种基于稀疏贝叶斯原理的模型,多用于数据分类和回归[16]。由于文中建立的是多输出预测模型,因此将现有的相关向量机模型推广到多输出系统中,主要的区别在于每个输入样本的权重值都是由同一组数据所共享的超参数控制,使得每一个输出变量都与输入变量存在依赖性,并且输出变量之间也存在相关性[17]。这些超参数描述了权重值的后验分布情况,超参数数值在训练过程中通过迭代估计。其中,绝大多数的超参数数值接近于无穷大,导致后验分布可以将相应的权重值设置为零,而其余对应非零权重值的数据称为关联向量。这种算法使本研究可以为多个输出变量选择相同的输入变量集合,简化了建模结构。具体的回归函数为
yh=Φ(x)βh+h
(5)
其中:yh表示第h列的输出向量;βh表示第h列的权值参数;h表示均值为0、协方差为σ2的高斯白噪声;Φ(x)是以输入向量为基础的函数,其函数形式为
Φ(x)=[1φ(x,x1)φ(x,x2) …φ(x,xl)]′
(6)
φ表示用于比较任意两组输入变量特性的函数,其中Gaussian、Polynomial和cubic等核函数都可以作为基本函数。本研究以Gaussian核函数作为基本函数。
(7)
通过期望最大化算法(EM)对参数进行识别。该算法迭代两步:第一步计算每个变量中映射函数的概率,第二步使用前一步中计算的概率估计每个映射函数的参数。
(8)

(9)
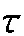
(10)
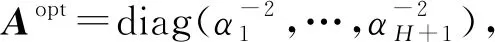
(11)
(12)
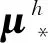
2 基于半监督学习的集成自适应多输出软测量模型
2.1 基于协同训练的集成自适应多输出软测量模型
协同训练方法作为半监督学习中最常见的方法之一[18],它能够将标记数据均分为两组,并同步对两组数据集用不同种类的回归方法进行互不影响的训练和建模,提高了回归模型的独立性和多样性。此外,由两个相互独立的训练集合对未标记数据进行评价和选取,减少了不合格未标记数据的选入,提高了模型的精度。然而,软测量模型在经过长时间的运行后,预测性能会下降。为了解决这一问题,本研究提出一种集成自适应方法,将移动窗口法与卡尔曼滤波结合,同时对模型的结构和参数更新。基于协同训练的集成自适应多输出软测量模型的框架图如图1所示。

图1 基于协同训练的集成自适应GPR-RVM多输出模型框架图
2.2 基于协同训练的集成自适应GPR-RVM多输出模型
本研究以多输出的高斯过程回归和相关向量机作为回归方法,构建基于协同训练的集成自适应异构多输出软测量模型。半监督学习方法的核心是利用未标记数据所携带的数据信息,实现对预测模型的改进和优化。为了选择出最合适的未标记数据,文中以文献[19]在协同训练回归(Coreg)中提出的置信度评价标准作为依据,将置信度的计算公式也扩展到多输出系统:
(13)
此外,多输出预测模型考虑输出变量之间的相关性,通过一次建模实现对多个输出变量的同步预测,有效地提高模型的预测效率。高斯过程回归和相关向量机作为两种不同的非线性回归方法,无论是训练还是建模过程,都保证了模型之间的独立性,增强了预测模型的泛化能力。最后,集成自适应方法对预测模型的结构和参数同步更新,互相补充,模型的自适应性可以得到显著地提升。
移动窗口通过更新建模数据实现对模型结构的更新:
(14)

基于协同训练的集成自适应GPR-RVM多输出模型的具体步骤如下:
步骤1 将收集到的数据分为标记数据集合L={(x1,y1),(x2,y2),…,(xl,yl)}和未标记数据集合U={x1,x2,…,xu}。将标记数据集合L编号后,利用奇偶分组的方法均分为L1和L2(若l为奇数,L1={(x1,y1),(x3,y3),…,(xl,yl)},L2={(x2,y2),(x4,y4),…,(xl-1,yl-1) };若l为偶数,L1={(x1,y1),(x3,y3),…,(xl-1,yl-1) },L2={(x2,y2),(x4,y4),…,(xl,yl) }) ,再利用高斯过程回归和相关向量机对L1和L2两组标记数据集合构建回归模型f1和f2。不同于随机分组和前后均分的方法,奇偶分组的方法虽然破坏了数据的连续性,但分两组标记数据能够包含全局信息,有利于建立更准确的预测模型。用两种不同类型的回归方法,可以提高训练和建模过程中模型的多样性,减少不适合未标记数据的选入。另一方面,多类型的回归方法,使模型的泛化能力得到提高,适用于更广泛的工业数据。
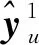
步骤3 建立预测模型。对最终的标记数据集合L1和L2分别用高斯过程回归和相关向量机构建预测模型h1和h2。两个回归模型相较于之前的回归模型f1和f2,由于标记数据组的数据数量和信息都得到了提高,模型的预测结果将更加准确。
步骤4 由文中提出的集成自适应方法,对模型进行动态优化。利用移动窗口法对建模数据实现动态更新,以达到更新模型结构的效果。由于工业过程中,各阶段数据的状态是不同的,利用移动窗口法可以实现建模数据随时间的变化而变化,模型的结构也因为数据信息的变化而更新。同时,在每一步的预测过程中,利用卡尔曼滤波中的卡尔曼增益系数,对预测模型h1和h2得到的预测结果加权,实现对模型参数的更新,得到最终的预测结果。卡尔曼增益系数为Gk,由h1和h2计算得到的预测结果分别为h1(x)和h2(x)。
(15)
(16)
(17)

卡尔曼增益系数是由上一时刻的Ri(i=1,2)决定,因此。利用卡尔曼增益系数对预测模型h1和h2得到的预测结果加权有效地保留了上一时刻的预测信息,使得模型预测结果具有连续性。
2.3 模型分析和讨论
本节分析和讨论基于协同训练的集成高斯过程回归-相关向量机模型(Co-training GPR-RVM)的优点和缺点。首先,在数据的预处理阶段,奇偶分组的方法将数据编号后按照奇偶属性将标记数据均分为两组,虽然这种分组方法破坏了标记数据的连续性,但是分组得到的两组标记数据集合都可以包含原始数据的全局信息,使得建立的训练模型更准确。在模型结构上,协同训练方法属于半监督学习方法,不同于监督学习方法,半监督学习方法可以充分使用未标记数据来优化模型,提高模型的预测性能。然而,半监督学习方法需要对未标记数据进行评价和选择,因此,模型结构变得更复杂。此外,文中提出的Co-training GPR-RVM模型通过应用高斯过程回归(GPR)和相关向量机(RVM)两种相互独立的非线性回归算法建立和优化模型,极大地提高了模型的多样性,能够使模型适用于不同的数据预测问题。最后,文中提出的集成自适应方法分别对模型的结构和参数进行了更新。在模型的在线应用中,可以更全面地提高模型的自适应能力,避免模型的衰退。
然而,Co-training GPR-RVM模型也存在一些缺点。相较于监督学习模型,协同训练模型因为增加了未标记数据的评价和选择过程,使得模型结构更复杂,预测的效率更低。其次,不难发现的是模型在初始的预测阶段,预测表现较差,这主要是因为在模型训练初期,初始的卡尔曼增益系数较差,需要通过不断地调试来优化;为解决这一问题,可以通过不断地调试,寻找最佳的初始卡尔曼增益系数。最后,集成自适应方法容易受到数据中个别异常值的影响,从而影响模型整体的预测表现。
3 案例分析
本研究以加州大学数据库(UCI)所收集到的污水数据为例对该方法的有效性进行验证,以证明基于协同训练的集成自适应GPR-RVM多输出模型能够实现对污水处理过程中难测量变量的有效预测。模型预测的表现不仅通过图中预测曲线和真实曲线的拟合来反映,还可以通过均方根误差(RMSE)、多元相关系数(RR)、对角线均方根平方和(RMSSD)以及相关系数(R)来评价;其中,RMSE和RR是模型对各个变量的评价指标,RMMSD和R是模型整体的评价指标。
(18)
(19)
(20)
(21)

3.1 研究背景和变量选择
UCI所收集的数据来自于一个采用活性污泥处理工艺的污水厂,该厂的污泥处理系统主要由预处理池、初沉池、曝气罐、二沉池和污泥回流5部分组成,如图2所示。该污水厂的污水处理量为3.5×104m3/d,主要对污水进行去氮除磷处理。在处理过程中,由于需要大量的微生物对化学反应进行催化、对磷酸盐进行吸附,随着生化反应的进行,微生物质量和种类数量会发生变化。因此,需要对整个污水处理的过程进行全面的监测[20]。

图2 污水处理过程原理图
由于该污水厂的结构相对简易,监测设备不足,UCI所收集的数据共包含38个变量,采样周期为1 d,共400 d数据。其中前200 d的数据作为训练数据构建模型,后200 d的数据用来检验模型的预测性能。出水指标化学需氧量(COD)、生物需氧量(BOD)和回流出水指标RD-COD、RD-BOD在整个过程中最难监测,将它们作为输出变量对软测量模型的预测性能进行验证。根据对活性污泥处理工艺的机理分析,将各个阶段其他变量,如悬浮物浓度(SS)、挥发性悬浮物浓度(SSV)、pH值等作为输入变量,共计34个,详细的变量介绍可参看文献[21]。
3.2 预测结果对比和分析
为了验证模型的预测性能,文中在相同的数据及条件下,比较了以下4种模型的预测性能:监督学习的异构高斯过程回归-相关向量机模型GPR-RVM;协同训练的高斯过程回归模型Co-training GPR;协同训练的相关向量机模型Co-training RVM;协同训练的异构高斯过程回归-相关向量机模型Co-training GPR-RVM。
此外,为了验证文中提出的集成自适应方法,分别对4种模型进行集成自适应处理后再次进行对比。其中,未进行集成自适应处理的模型被称为离线模型,经过集成自适应处理的模型被称为在线模型。
各个模型预测结果见表1。首先,比较在集成自适应方法下4种模型的预测结果,Co-training GPR-RVM模型的RMSSD值比GPR-RVM模型的RMSSD值减小了17.25%,这主要是因为协同训练方法能充分使用未标记数据优化模型,提高了模型的预测性能;此外,Co-training GPR-RVM模型的RMSSD值是最小的,为9.986 5,这说明了在集成自适应方法下,异构多输出软测量模型的预测效果整体上优于同构模型。但是也不难发现,Co-trai-ning GPR-RVM模型对于个别输出变量的预测效果并不是最佳的,主要的原因是在训练学习过程中,未标记数据的置信度是在多输出系统下计算得到,输出变量间将会存在相互的影响,最终影响模型对个别输出变量的预测表现。此外,为了更直观地反映异构模型和同构模型的预测表现,文中给出了集成自适应条件下3种协同训练模型预测结果的多元相关系数(RR)的条形图,如图3所示。
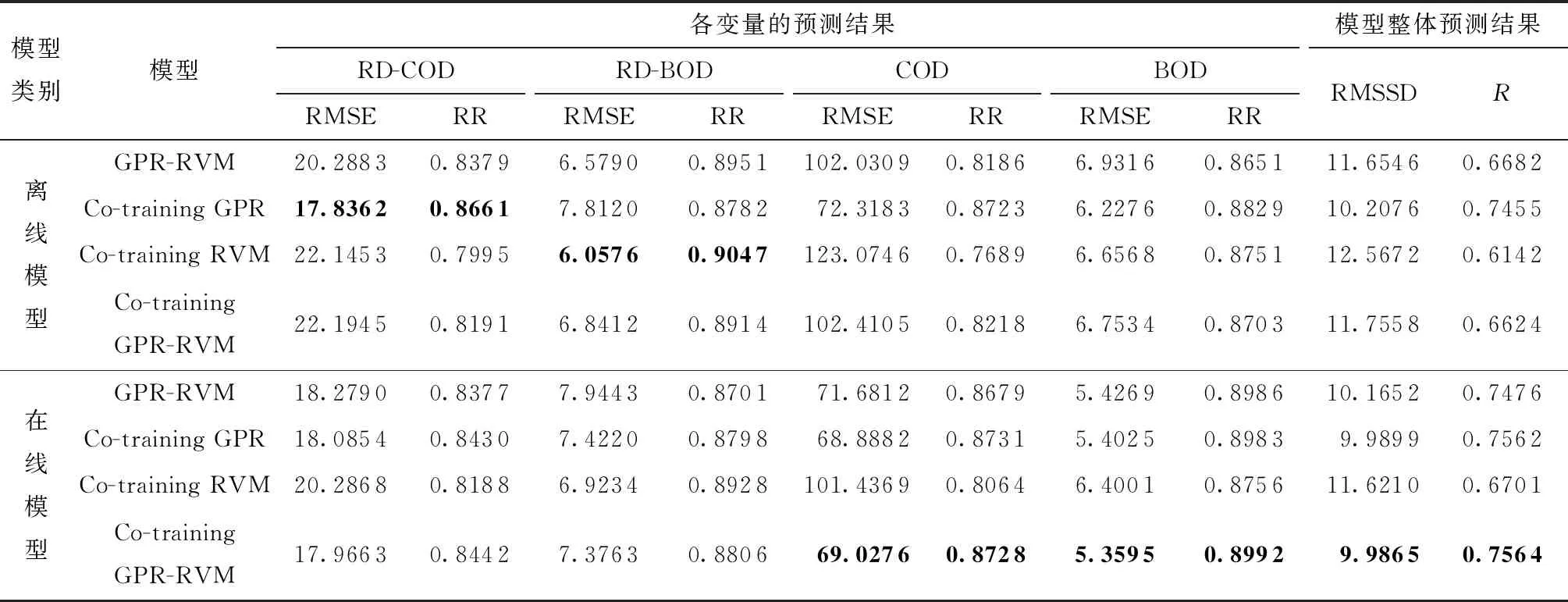
表1 模型预测结果对比
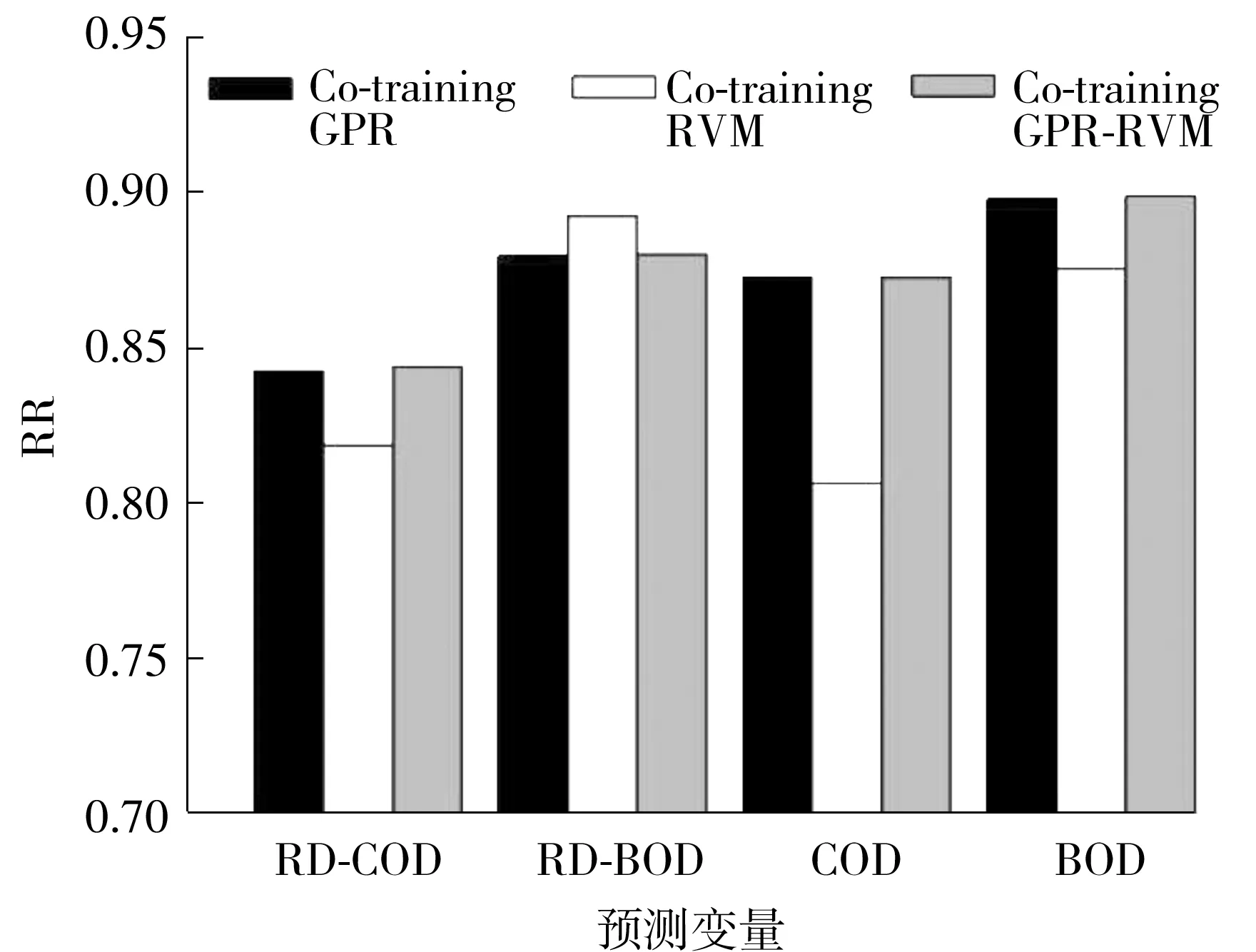
图3 多元相关系数直方图
由图3可知,Co-training GPR-RVM模型对于每一个输出变量的相关系数基本都是最大的,尤其是BOD和COD两个重要出水指标的,分别为0.899 2和0.872 8,这可以为污水处理厂在最终排污时,污水指标是否达到安全指标提供一个可靠的监测结果。
为了验证集成自适应方法对模型预测性能的影响,在相同的回归方法下,比较在线模型与离线模型的RMSSD值可知,集成自适应方法下模型的RMSSD都有显著地降低,相较于离线的GPR-RVM、Co-training GPR、Co-training RVM 和Co-training GPR-RVM模型 的RMSSD分别减小了12.78%,2.18%,8.14%和17.72%,尤其是Co-training GPR-RVM模型的优化效果最为明显。这说明随着时间的推移,集成自适应方法能够保证模型性能维持在一个令人满意的状态。
Co-training GPR-RVM模型在集成自适应方法和离线方法下的预测结果如图4所示。
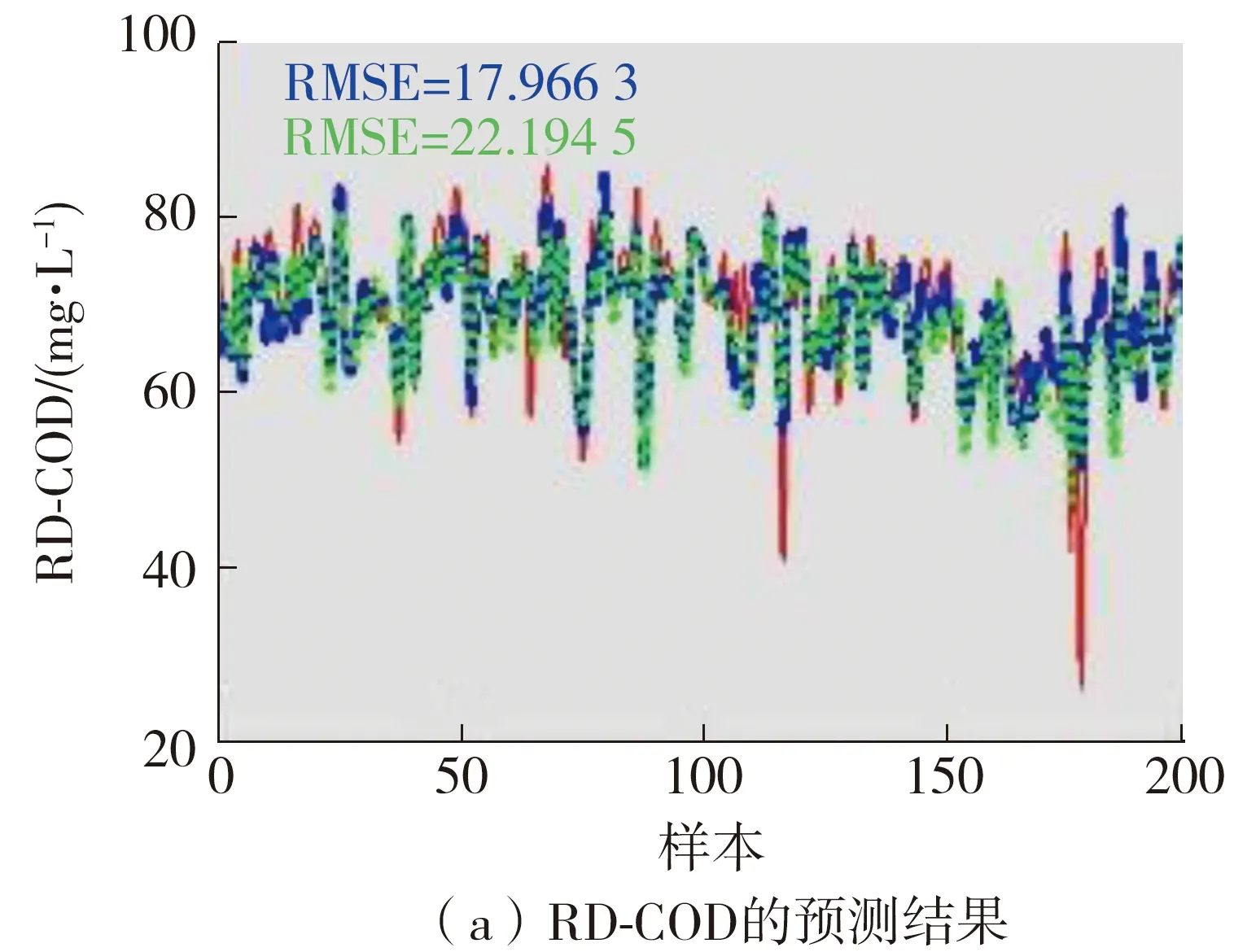
图4 模型的预测曲线
由图4可见,两种模型均表现出良好的跟踪性能,但对于峰值和谷值点的拟合较差。相较于离线模型,集成自适应模型对峰值与谷值点的跟踪较好,这主要是因为集成自适应模型会根据上一时刻的预测误差对这一时刻的模型系数进行更新。对峰值与谷值点实现更好的跟踪,可以对污水处理过程中的故障进行及时地判断和反馈,减少不必要的损失。
3.3 讨论
针对UCI收集的采用活性污泥处理工艺的污水厂的数据,本研究提出的基于协同训练的集成自适应GPR-RVM多输出模型实现了对出水指标 COD、BOD和回流出水指标RD-COD、RD-BOD的有效预测。主要原因是:
首先,该污水厂由于结构简易、监测设备不足,导致数据量较小,严重影响预测模型的建立。文中采用协同训练的半监督学习方法对标记数据集合进行扩充,并且将非线性回归算法GPR和RVM结合,建立了异构的软测量模型。
其次,由于污水处理是一个复杂且多变的工业过程,离线的软测量模型无法满足预测精度的要求。因此,文中提出的集成自适应方法,利用移动窗口和卡尔曼滤波同步对模型的结构和参数进行实时优化,保证了模型的预测精度。
最后,在污水处理过程中,难测量变量间存在相关性,本研究将软测量模型推广到多输出系统,实现了对多个变量的同步预测;不仅提高了模型的预测精度,模型的预测效率也得到提升。
4 结论
本研究以半监督学习方法为出发点,提出了一种基于协同训练的集成自适应GPR-RVM多输出软测量模型,并以通过污水处理过程中的重要出水指标变量(COD和BOD)验证了异构的半监督软测量模型的预测性能和集成自适应方法对模型的优化能力。最后以实际污水厂为对象进行了实验,对模型的预测性能和自适应性进行验证,结果表明该模型预测表现优于同条件下同构的半监督软测量模型,模型的自适应性在集成自适应方法优化下也得到了显著地提升。
