基于仿射传播聚类算法的大数据并行化分析研究
2021-07-11汪俭华陈守维
汪俭华,陈守维
(黔东南州大数据发展中心,贵州凯里 556000)
大数据最早是由IBM 公司于2010 年提出的,其具有海量数据、高速响应、多样化、价值密度低等特性[1],如何将海量的原始数据转换成为有用的数据是当下的热点问题。在这些海量数据内部都包含了具有一定规律的社团结构,针对这一特性,该研究利用仿射传播聚类算法迁移到云平台上实现并行化来改进对海量数据的处理效率[2-3],提升用户体验。
1 云计算技术
1.1 社团结构
社团结构,是网络中的一个共性特征,指网络中的顶点可以形成分组,每个组内顶点之间的相互连接紧密,而不同组间的顶点之间的相互连接则相对稀疏。在海量数据网络中,对社团结构的研究分析可以优化在并行计算中分配任务的合理性,从而减少各个计算节点之间的通信成本,提高大规模计算的效率。目前用于划分网络中社团结构的算法主要包括基于图论、基于模块度优化、基于动态、基于重叠社团4 类算法。
以上几类发现算法中的典型代表是K-means 法(划分类聚算法),但都存在复杂度较高,无法处理海量数据网络,获得结果不稳定等问题[4]。通过利用云计算技术实现仿射传播聚类算法的并行化,能够有效处理海量数据网络。
1.2 Hadoop系统
Hadoop 系统作为云计算技术的基础设施,可以部署服务器集群在大量廉价的硬件设备上,系统的底层用于对服务器集群进行管理,系统的上层能够十分便捷地构建应用,可以动态地调整分布式节点[5-8]。Hadoop 系统由HDFS、MapReduce 和HBase 3 个部分构成,HDFS 用于在多台设备上保存和复制文件,MapReduce 主要是运行并行程序任务,HBase 是一个开源的分布式储存数据库。
HDFS(Hadoop Distributed File System)是一种具有高度容错性的分布式文件存储系统,具有master/slave 的结构,Name node 是主节点,Data node 是从节点[9]。前者用于维护存储在HDFS 中的数据,包含文件的block 及其Data Node 信息;后者将HDFS 中的文件实际存储在本地。
MapReduce 是一种基于集群进行海量数据并行计算的模型,可以便捷地实现对并行计算的开发及应用[10]。其主要由Map 和Reduce 操作构成,Map 操作用于处理一个Key 并得到一组中间结果Key/Value值,Reduce 操作则利用得到的中间结果来处理最终的结果。
HBase 是一个开源的分布式数据库,其原理与Google 的BigTable 相似,运行在HDFS 上,为Hadoop提供BigTable 服务,能够部署大规模结构化储存群集到廉价的设备上[11-13]。
1.3 Mahout学习库
Apache Mahout 是一款开源、可扩展的机器学习库,包含许多实现、集群、分类和进化程序,可以利用Hadoop 快速有效地扩展到云平台中[14-15]。
2 仿射传播聚类算法并行化研究
2.1 仿射传播聚类算法
仿射传播聚类算法利用各个数据点传播消息,可以自动发现聚类中心,从而实现数据点的自动聚类。仿射传播聚类算法较传统的类聚算法,不需要对类聚的类别、类聚中心进行预设,每一个数据点都视为潜在的聚类中心,其类聚中心是在迭代计算的过程中自动优化结果生成的,所得到的类聚结果更准确[16]。
1)仿射传播聚类的输入首先需要计算相似度矩阵,该矩阵由节点之间的相似度组成,在这个矩阵中的每个元素s(i,j)表示节点i与j之间的相似度,也定义了节点j作为i的聚类中心的适配度。其计算公式如下:
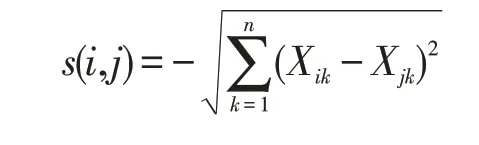
Xik表示节点之间的邻接矩阵X第i行第k列的元素,n表示矩阵中节点的总数。
与传统的聚类算法需预设类簇的个数不同,仿射传播将一对多节点k赋值为s(k,k),该值反映相似矩阵s对角线上第k行的元素,这些对角线上的值称为倾向值,其与第k个节点作为聚类中心,呈正相关[17]。仿射传播中所有的节点作为潜在聚类中心的概率均相同,使所有节点倾向值都应相同,“倾向值”的选择与最后获得类簇的数量呈负相关。
2)仿射传播聚类算法在每个节点之间传播吸引值和归属值。
吸引值是从节点i传播到作为潜在聚类中心的节点k的信息,r(i,k)为节点k对于节点i的吸引值,该值是节点k与其他节点k′相互竞争后,作为节点i的聚类中心的适配程度。r(i,k)需要引入节点i对其他潜在聚类中心节点k′的归属值a(i,k′)来获得,其计算式如下:
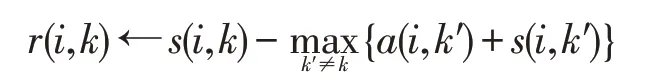
归属值是从潜在的类聚中心节点k传递到节点i的信息,a(i,k)为节点i对节点k的归属值,该值反映的是节点i选择节点k作为其类聚中心的适配程度,表示的是将潜在类聚中心的节点k与其他节点i′的吸引值进行比较的结果,其计算式如下:
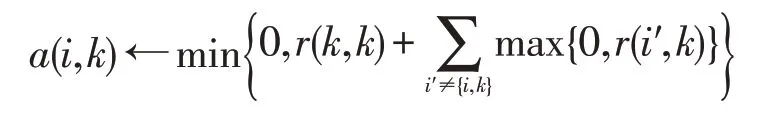
基于非负的其他节点与候选节点k的吸引值的计算结果用a(k,k)定义,该值反映了节点k作为潜在类聚中心的能力,其计算式如下:
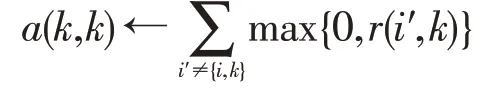
仿射传播聚类算法流程如下:
Step.1 初始化,将所有节点的a(i,k)全部设置为零,输入相似矩阵s,其中,s(i,k)是节点i与节点k之间的相似值,而s(k,k)则是k点作为潜在类聚中心的倾向值。
Step.2 计算获得节点k对于节点i的吸引值:
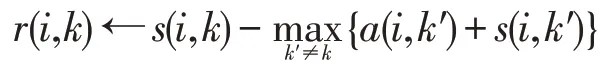
Step.3 计算节点i对于节点k的归属值:
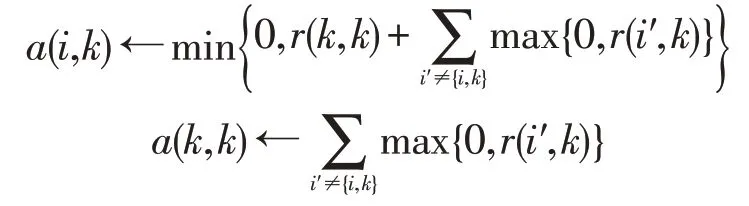
Step.4 通过迭代Step.2、Step.3,直至得到计算结果,此时得到的最优结果就是类聚中心。
2.2 利用MapReduce实现并行化
仿射传播聚类首先需要获得相似度矩阵,然后进行多次迭代计算矩阵值,在此过程中要多次调用mapreduce job,单次迭代过程包括获得吸引值、计算归属值和对归属值矩阵的行列文件进行转置,当迭代过程停止或聚类中心稳定不再变化后,发现聚类中心并划分节点[18]。


3 实验分析
3.1 实验环境搭建
实验平台:一台Master 操作系统为Ubuntu 16.04 LTS 64 位、Java SE 11.0.2(LTS)、CPU 为Intel Xeon E-2699 v4 2.20 GHz、内存容量为64 GB 3 200 MHz、硬盘容量为4 TB;4 台Slave 操作系统为Windows 2012 R2、CPU 为Intel core i5-4590 3.30 GHz、内存容量为16 GB 3 200 MHz、硬盘容量为1 TB。虚拟机设置:操作系统为Ubuntu 16.04 LTS 64 位、Java SE 11.0.2(LTS)、CPU 为Intel core i5-4590 3.30 GHz、内存容量为8 GB 3 200 MHz、硬盘容量为1 TB。
实验数据采用美国Minnesota 大学计算机学院GroupLens 项目组创建的MovieLens 数据,该数据由3万名用户对3.5 万部电影做出的2 500 万个评分以及50 万个标签组成,数据版本为4.4.1。
3.2 算法模型设计
该实验以基于仿射传播聚类算法为例,对MovieLens 数据进行资源调度实验,并与基于划分类聚算法进行比较,请求服务分别为100、500、1 000、2 000、4 000 次,运行时间实验对比如图1 所示,所需内存实验对比如图2 所示,CPU 利用率实验对比如图3 所示。
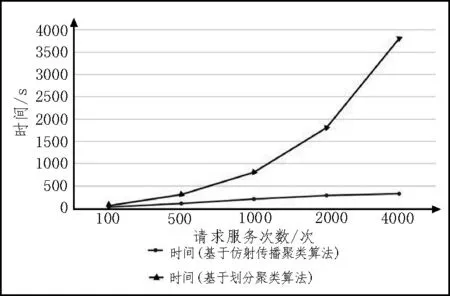
图1 运行时间实验对比图
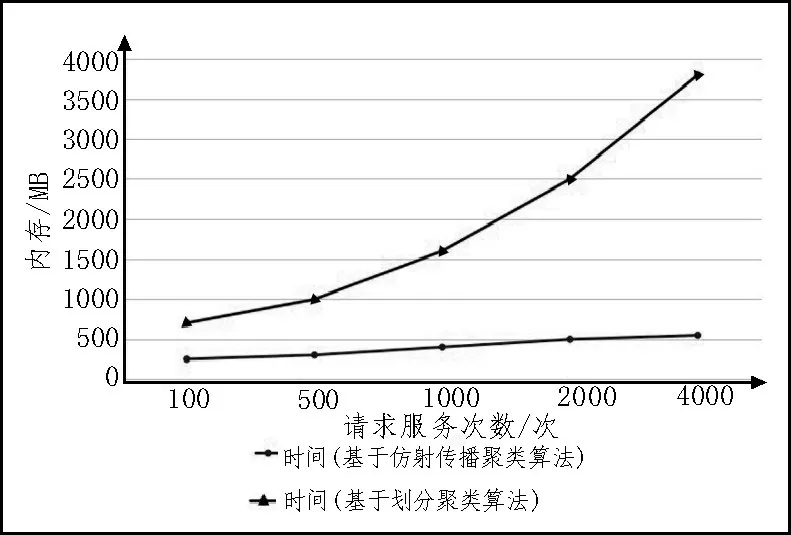
图2 所需内存实验对比图
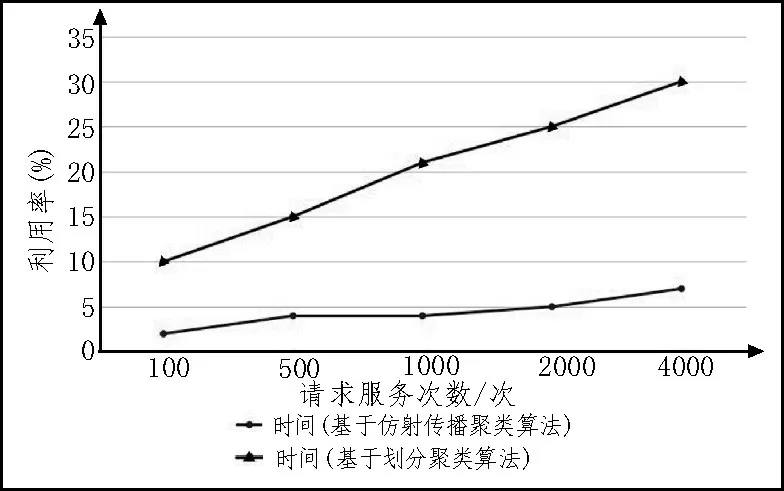
图3 CPU利用率实验对比图
从上述实验可知划分聚类算法分析过程中,随着实验规模的增大而导致效率低、资源占用率高、运行时间长、所需内存多和占用CPU 率高等缺点,这是因为划分聚类算法需要先选择一个聚类中心,如果聚类中心选择不恰当,则会影响分析过程。基于仿射传播聚类算法的并行化分析,使用该算法不需要先选择聚类中心,减少了不必要的操作,使得运行时间和资源占用率大幅得到改善。
4 结论
该文在基于仿射传播聚类算法的基础上搭建了MapReduce 并行化平台,详细论述了分析中涉及的关键技术。通过对比实验来进行评估,仿射传播聚类算法并行化后具有节省运行时间、降低内存使用量和CPU 利用率等优势,具有较高的实用性。下一步研究工作是将该算法进行可视化应用,以方便用户的使用,带来更佳的体验。
