基于中文预训练的安全事件实体识别研究
2021-07-10董林靖黑新宏王一川刘雁孝
朱 磊 董林靖 黑新宏 王一川 彭 伟 刘雁孝 盘 隆
1(西安理工大学 西安 710048) 2(陕西省网络计算与安全技术重点实验室(西安理工大学) 西安 710048)3(深圳市腾讯计算机系统有限公司 广东深圳 518054)
随着我国城市中各种各样的安全突发事件不断增多,形成了大量的案例文本信息.现阶段公共安全事件舆情中的知识与信息不能有效地抽取和复用,无法为公共安全事件管理提供充分的协助和预警.在现有的自然语言处理研究领域,对中文公共安全事件领域的语料分析研究[1]较少.命名实体识别是领域工作中的基础,直接影响自然语言处理任务中语法分析、语义分析和关系抽取任务的性能,其主要的目的是从非结构化文本中识别预定义实体[2].
基于规则和词典的命名实体识别方法[3]主要是人工构建有限规则,结合专家构建的实体词汇表,对每条规则设置权重,然后通过实体与规则的匹配程度来进行实体类型分类.但是人工制定这些规则的成本较大,构建词汇表与数据量相差悬殊,经过制订固定的规则模板来识别出结构复杂的命名实体;这样的方法虽然准确率相对较高,然而工作量巨大,可行性较低;其次,人为制订的规则模板复用性太低,不同领域数据结构可能不同,将此规则模板迁移至其他领域不适用.
基于统计机器学习的方法可以将命名实体识别任务当作词组级别的多分类任务,先使用模型识别出实体的边界,再使用分类器对文本中的命名实体进行分类[4];或者将命名实体识别任务当作字符级别的序列标注任务[5]:首先,根据领域数据人为预先定义若干个实体类别,对于文本中每个字符可以有多个候选的类别标签;然后根据每个字符在实体中的位置,确定每个字符的标签,最终将1组字符的标签整理在一起,获得识别出的实体和实体所属类别[6].
基于神经网络模型的深度学习[7]使用词向量来表示词语的方法,加入词向量减少了人为特征工程的工作量,能够潜移默化地发现人工选择特征时未包含的语义信息.该方法还解决了在基于词典方法中由于高维度向量空间而出现的数据密度稀疏的问题,并且能够将不同结构的文本转化为相同维度大小的矩阵进行向量表示.
为了研究中文公共安全事件的命名实体识别方法,本文分析了《中文突发事件语料库》,将预训练模型作为研究重点.在对比了现有基于BERT模型的工作[8]基础上,本文提出了优化的中文预训练模型RoBERTa+完成公共安全领域的预训练任务.具体地,将更新的安全领域词典和10万条新闻语料嵌入到预训练模型中,同时使用动态的全词覆盖机制修正网络参数.将预训练语言模型以及输出的动态词向量作为下游命名实体识别任务的输入进行微调.接着采用BiLSTM-CRF模型提取文本的上下文关系,并标注出实体字符的类别.经实验证明,基于领域预训练的公共安全事件命名实体识别的性能均得到了提升.
1 模型结构
1.1 RoBERTa模型
BERT模型是基于Transformer模型的双向编码器表示[9],其结构如图1所示.BERT模型能够学习句子中词和词之间的上下文关系,当处理1个词时,能同时考虑到当前词的前一个词和后一个词的信息,从整体获取词的语义特征.
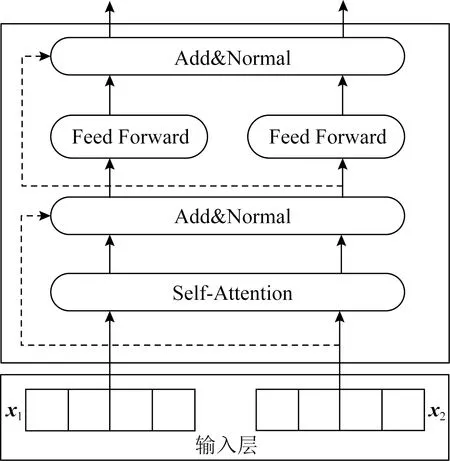
图1 Transformer编码单元Encoder
Transformer编码单元主要运用了多层Self-Attention机制,其中Self-Attention机制为输入向量的每个单词学习一个权重.双向的Transformer编码器的连接组成BERT模型结构,它可以获取所在层中的左右2侧语境.
1.2 Bi-LSTM算法
Hochreiter等人[10]在1997年提出了长短时记忆网络(long short-term memory,LSTM)能够解决循环神经网络(recurrent neural network,RNN)在时间维度上出现的梯度消失问题.LSTM主要利用其特有的3个门结构来保持和更新状态,以达到长期记忆功能,并能够选择性地遗忘部分历史信息.LSTM模型将部分输入信息与通过遗忘门、输入门和输出门获得的状态结合形成输出状态,从而达到可以比RNN捕获更长距离的依赖信息.此外,为了同时反映每个字符与上文信息和下文信息之间的关系,Graves等人[11]提出了BiLSTM模型.将文本向量按照从左向右及从右向左的顺序分别输入正序及逆序LSTM单元.BiLSTM模型可以考虑上下文2个方向的信息,综合输出字标签得分向量.
1.3 CRF算法
Lafferty等人[12]在2001年首次提出条件随机场模型CRF,条件随机场模型在自然语言处理领域中主要应用是文本序列化标注.条件随机场可以实现在给定一组随机的X的条件下,它能够输出目标Y的条件概率分布.在命名实体识别任务中使用CRF模型主要是为了给BiLSTM模型输出的每组预测标签添加一些实体内位置约束,从而保证每组预测标签的有序性.
事实上,相邻字标签之间是存在约束关系的.如图2所示,例如标签“B-PER”和标签“I-LOC”相邻,文本开头的字标签不可能是“I-”标签或者“O”标签.CRF模型能够自动学习到各字标签之间的约束信息,利用每个字标签的得分与字标签之间的转移得分来计算不同标签序列出现的概率,从中选取出现概率最大的序列,并将具有合法性的序列作为文本最优标签序列.

图2 CRF线性链式结构图
1.4 PreTrain100K+RoBERTa+-BiLSTM-CRF模型
为了提升公共安全领域事件实体的识别效率,本文在公开的新闻领域数据集上进行预训练,对RoBERTa进行优化,提出基于领域预训练的公共安全领域命名实体识别模型.在提出的模型中:首先对输入字符进行向量映射,接着使用RoBERTa进行预训练,生成预训练语言模型及含有语义的动态字词向量;然后使用BiLSTM对输入信息进行上下文特征提取,对每一个字符输出每个预定义类的标签预测分值;最后,使用CRF自动学习转移特征,通过添加约束条件保证预测的标签顺序的合法性,选取最优标注序列生成实体识别结果.模型结构如图3所示:
国家对建筑材料的质量有着严格的规定和划分,个别企业也有自己的材料使用质量标准,但是个别施工单位为了追求额外效益,会有意无意地在工程项目建设过程中使用一些不规范的工程材料,造成工程项目的最终质量存在问题。
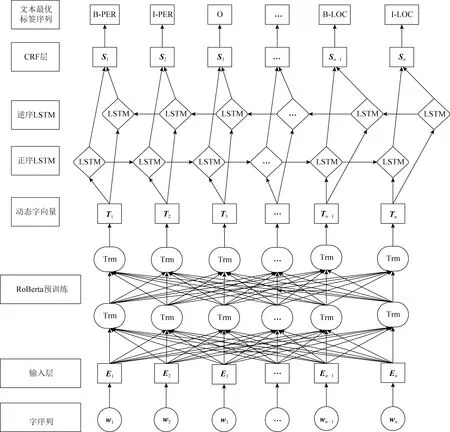
图3 RoBERTa-BiLSTM-CRF模型结构
RoBERTa 模型的输入是由3种embedding相加得到:token embeddings,segment embeddings,position embeddings.token embeddings是词向量,第1个单词是 CLS 标志,可以用于分类任务;segment embeddings用来区分2种句子,可以用于以2个句子为输入的分类任务;position embeddings表示位置.3种embedding都是通过训练得来的.
本文提出PreTrain100K+RoBERTa+-BiLSTM-CRF模型主要是对RoBERTa模型进行改进,采用数据增强的方式加强深度学习模型对公共安全领域的命名识别能力.在爬取的部分公共安全事件词典的基础上,对RoBERT进行了2步改进:1)将原始的单字符掩码机制修改为全词掩码机制,并在分词函数中引入公共安全事件实体词典;2)对改进的RoBERTa模型进行领域预训练,即在爬取的10万条新闻语料库上进行词掩盖预训练任务.
RoBERTa模型在输入时采用动态掩码机制,该机制采用以字符为单位进行切分.在生成训练样本时,句中的词会被切分为多个词组,并且这些词组会被随机掩码.但是中文和英文的区别是英文最小的单位是一个单词,而中文最小的单位是以字为粒度进行切分,单个字可能不包含完整的语义信息.在中文中包含语义信息的单位是词,词是由1个或多个字组成,并且1个完整的句子中词和词之间没有明显的边界标志.
本文采用全词掩码机制来替换字符掩码机制.如果1个完整的词的部分子词被掩码,那么意味着同属于该词的其他部分也应该被掩盖掉.基于这个中文语法,全词掩码使模型能够更好地学习中文语言表述方式.具体实例如表1所示:
学校对实验教学的管理是根本性管理。对是否能够真正实现、实践实战能力强的应用型专业人才培养目标,具有根本性、决定性作用。
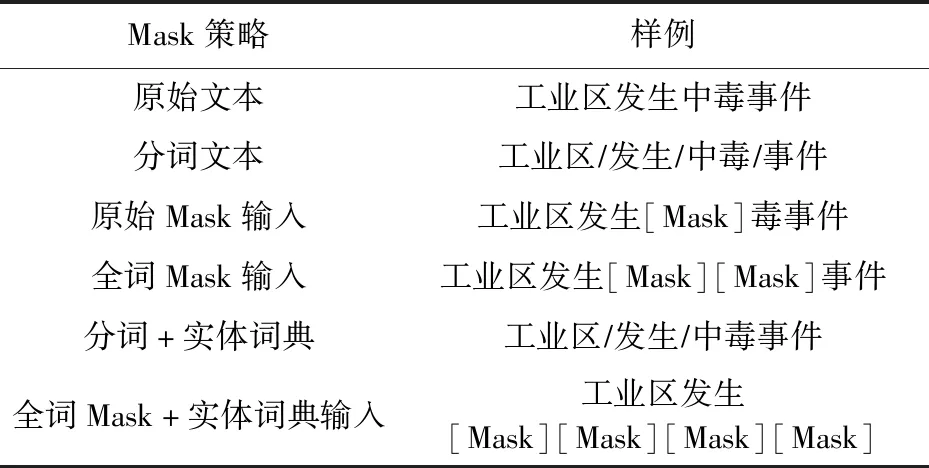
表1 全词Mask
针对表1的情况,在全词掩码机制中,首先对文本进行分词操作,并且在分词过程中引入公共安全事件的实体词典,使其能全词掩码机制预测时保留公共安全事件文本实体完整的语义,具体模型结构如图4所示:

图4 PreTrain100K+RoBERTa+模型结构
同时,为了增强中文相关背景知识的迁移和学习,本文以公开的微软亚洲研究院MSRA数据集、人民日报语料集和今日头条中文新闻数据集作为预训练语料.新闻语料中也包含公共安全事件的语料,与本文特定任务语料十分相关,方便用于领域预训练.这些新闻语料包含了10万条未标注的新闻,将这些语料输入到RoBERTa-base版本[13]预训练模型中.在大规模无标注的语料上采用自监督的方式训练语言模型,并且将训练后的语言模型与下游任务模型连接,采用微调方式调优模型参数.在预训练语料中,MSRA语料集包含46 365条数据,人民日报语料集包含23 061条数据,今日头条新闻数据集包含30 626条数据,共计10万余条语料数据.
2 实验设计及分析
2.1 实验环境
本文使用Python语言和Tensorflow框架.实验运行环境为Win10操作系统,内存64GB,处理器型号为lntel®CoreTMi7-10700CPU@2.90 GHz,GPU显卡型号为NVIDIAGeForceRTX2080Ti.
2.2 实验数据
本文的实验数据是公开的安全事件案例《中文突发事件语料库》(Chinese Emergency Corpus,CEC).CEC[14]数据集共有332条公共安全事件实例,该数据集含有5类预定义的实体.针对denoter,time,location,participant,object标签进行命名实体识别,将标签分别简记为DEN,TIME,LOC,PAR,OBJ,分别表示行为、时间、位置、参与者和对象.
在实验中,根据CEC实例数目对文档进行划分,在332条数据集中选取30条规范作为验证集,其次对332条数据集按7∶3的比例划分训练集和测试集,具体数目信息如表2所示:
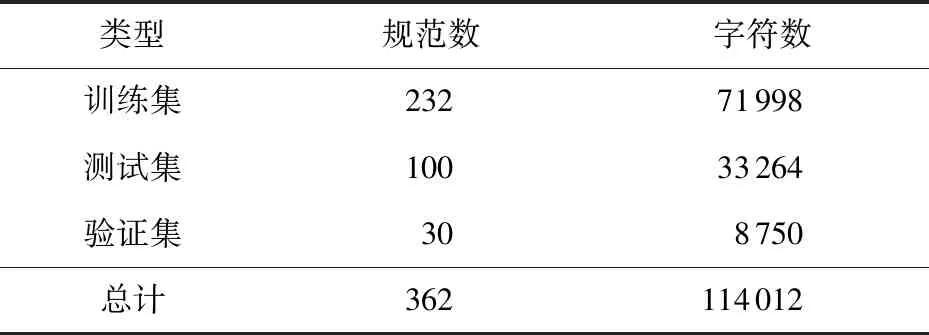
表2 数据集类别及字符数
注:362条数据中有30条重复实例.
2.3 标注策略
本文以汉字作为输入单元,标注体系选用经典的BIO方法.BIO是B(begin),I(intermediate),O(other)的缩写,其中,begin指所识别对象开始位置上的字符,intermediate指所识别对象最中间的字符,other指所识别对象中的非实体字符.本文数据集中5类预定义实体转化的待预测标签如表3所示:

表3 待预测标签
2.4 评价标准
实体边界和实体标注是NER评估主要的方向.在预测过程中,只有当实体标签的类型与预定义的实体类型完全一致时,才判断该实体预测正确.NER的评价指标为:Accuracy(精确率)、Precision(准确率)、Recall(召回率)和F1值.具体公式为
(1)
(2)
(3)
(4)
其中:TP统计实体实际标签和预测标签都是正确的实体数目;TN统计实体实际标签和预测标签都是错误的实体数目;FP统计实体实际标签是错误的但预测的标签是正确的实体数目;FN统计实体实际标签是正确的但预测的标签是错误的数目.
2.5 参数选取
深度学习的效果很大程度上取决于参数调节的好坏.深度学习超参数中最重要的2个可调参数是学习率和批样本数量.由于硬件限制,批样本数量的选取存在上限.针对RoBERTa-BiLSTM-CRF模型,在机器上训练:当batch_size>22时,就会出现内存溢出;当batch_size=22时,既可以保证不发生内存溢出,还能够保证GPU利用率达到90%以上.因此本文将确定batch_size的大小,分别研究学习率和迭代次数对模型拟合度的影响.
2.5.1 学习率对模型训练的影响
学习率在模型迭代训练中把握着整个过程的学习进度,直接关系到模型的可优化空间.同时,将学习率调至最优才能够让梯度下降得最快.设置不同学习率观察RoBERTa-BiLSTM-CRF模型的准确率、精确率、召回率和F1值变化,实验结果对比如图5所示:

图5 学习率对模型性能的影响
在图5中,当学习率大于10-4时,准确率不超30%,精确率、召回率和F1值都不到10%.以指数形式逐渐减小学习率,当学习率等于10-4时,准确率和F1值达到最优.但是当学习率小于10-5时,性能在不断下降.所以,本文的模型将学习率设置为最优值10-4.
2.5.2 迭代次数对模型训练的影响
用全部数据对模型进行多次完整的训练称为迭代训练.确定batch_size和learning_rate的大小,多次改变迭代次数的大小,观察模型的准确率的变化情况.在实验中,设定迭代次数范围为[50,350],从50开始步长为50依次增大设置,实验结果如图6所示.

图6 迭代次数对模型性能的影响
从图6可以看出,当迭代次数为250时,准确率和F1都达到最优.同时,在250次时模型性能已经趋于稳定,并且波动较小,所以将迭代次数设置为250为最佳.
除了学习率和迭代次数,模型的其他参数同样通过类似的部分实验获取,具体超参数设定如表4所示:

表4 参数值设置
2.6 实验过程及结果分析
本文针对中文公共突发事件语料库CEC进行分析,通过对中文预训练模型的优化,构建公共安全领域的PreTrain100K+RoBERTa+-BiLSTM-CRF模型.在实现中,我们选择BiLSTM-CRF,BERT-BiLSTM-CRF和未加领域预训练的RoBERTa+-BiLSTM-CRF等模型作为对比实验,具体的实验结果如表5所示.
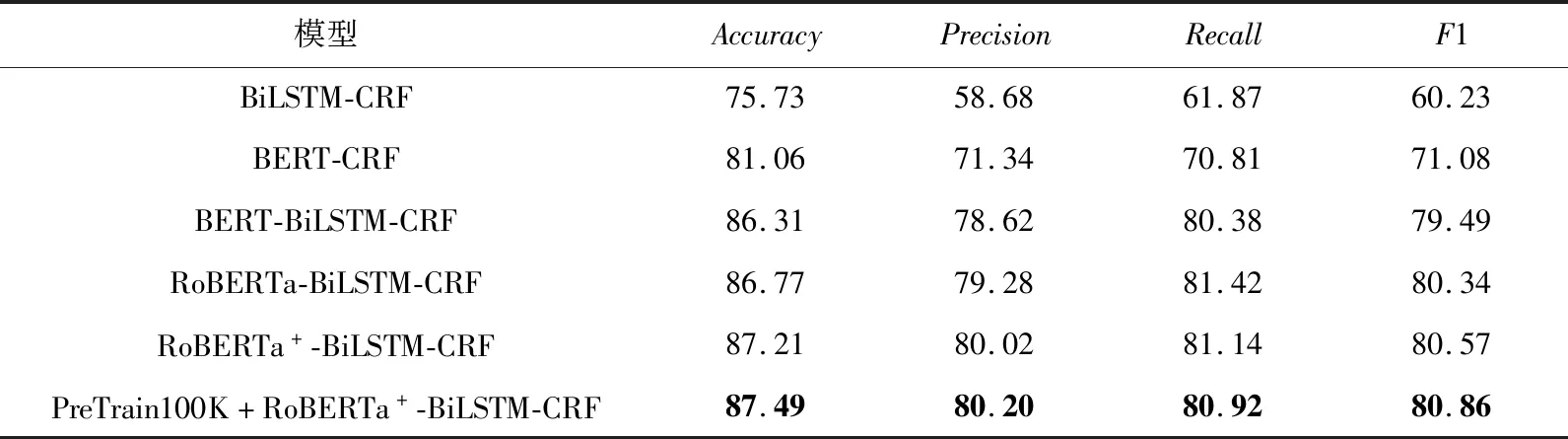
表5 实体识别模型实验结果对比 %
首先,对比BiLSTM-CRF和BERT-CRF模型的实验结果,后者的F1值比前者高10.85%.由此可看出,BERT模型[15]依据单词上下文计算的表示向量,比Word2Vec直接在此表中查找某个词的表示向量更具有语义信息.因此,后者的效果要优于前者.
对比BERT-CRF,增加了BiLSTM模型,性能得到了显著提高,F1值提高了8.41%.这种情况说明了在BERT预训练模型后直接使用CRF模型,缺少BiLSTM学习观测序列上的依赖关系,整个模型在观测序列上学习力就会下降.相比较BERT-BiLSTM-CRF,RoBERTa的预训练效果性能更好,从结果可以得到RoBERTa-BiLSTM-CRF模型将精确率提高了0.66%,F1值提高了0.85%.因为原版的BERT依赖随机掩码和预测token,在数据预处理期间执行1次掩码,得到1个静态掩码;借助于动态掩码机制,RoBERTa模型对预训练语料中的实体名词进行不同概率和顺序的多次训练,从而增强安全领域的实体名词嵌入表示.因此,后者表现优于前者.对比加入原始版的RoBERTa的模型,本文改进的RoBERTa+-BiLSTM-CRF模型的F1值表现较好.说明了加入实体词典的全词Mask机制能够保留领域实体完整的语义,对下游公共安全事件命名实体识别任务有一定的提升.
对比RoBERTa+-BiLSTM-CRF模型,本文提出的PreTrain100K+RoBERTa+-BiLSTM-CRF模型将准确率和F1值分别提高了0.28%和0.29%.说明了对RoBERTa+模型在大规模的无标注语料上进行领域预训练后能够在一定程度上使模型学习到公共安全领域文本的领域特征,进而提升命名实体识别的性能.同时,实验结果对比提升效果较小,说明领域预训练语料不足,需要大量相关领域数据进行充分预训练.
3 结 论
本文主要是对公共安全领域进行中文命名实体识别研究,提出了改进的命名实体识别模型PreTrain100K+RoBERTa+-BiLSTM-CRF.在对原始的RoBERTa模型进行领域预训练优化过程中,加入公共安全领域词典的全词Mask机制,并且对相关的10万条中文语料库进行预训练,使PreTrain100K+RoBERTa+模型具备更好的中文语言模型能力.然后,将生成的预训练语言模型和领域实体输入到BiLSTM-CRF模型[16]中进行实体识别训练.该模型在中文突发事件语料库CEC上取得了较好的性能.
未来计划在扩充公共安全事件语料的基础上再进行预训练模型的优化,并且还计划在命名实体识别任务中加入领域实体关系特征,从而提升公共安全领域的信息识别能力.
