基于机器学习的信贷逾期检测模型研究*
2021-07-10侯浩鑫赵志红
侯浩鑫,赵志红
(北京理工大学珠海学院,广东 珠海 519088)
1 引言
随着互联网金融行业的兴起,银行和贷款机构通过互联网为有贷款需求的客户提供线上金融服务。在带来更好服务体验的同时,也存在着诸多信用风险问题,急需建立信贷风险检测模型提高风控水平。根据信贷客户还款的具体情况,将客户分为正常和逾期两种类型。以三个月的时间作为观察窗口,还款连续逾期三个月的,判定为逾期客户;其余正常还款情况的,为正常客户。通过采用机器学习和统计方法得出的信用检测模型,能够较为准确地预测个人未来的信用表现,估计每笔信贷是否逾期,方便银行提前预知可能存在的风险。
现代治理理论与实践表明,多元主体的有效协作配合,是推进国家治理现代化的有效路径。在一定意义上可以说,社会组织发展与治理现代化之间的关系,是检验国家治理现代化深度、广度、力度和效力的重要标志。
2 数据预处理
分析来自某贷款机构的历史业务数据,包含贷款基本表、报告主表、贷款记录、贷记卡记录、信用提示、未销户贷记卡和未结清贷款信息汇总、逾期信息汇总、查询记录汇总、信贷审批查询记录明细、贷款特殊交易、透支记录、诈骗记录等12个数据集,涉及3万名客户和100多个特征,数据预处理较复杂,需尽量减少信息损失。
为了获得更好的训练数据特征,通过特征工程将原始数据转换成模型训练数据,使得机器学习模型逼近这个上限,提高模型性能。主要运用了特征构建和特征选择。例如针对“数据集:信贷审批查询记录明细表”,利用日期函数计算查询间隔月份数,通过总查询次数除以查询间隔月份数构建出新属性“月查询次数”。
通讯模块电路中S1为拨码开关,当码位为00时为固定周期传输,即每隔2 min采集一次数据并传输。当码位选择01时为变周期数据传输。微控制器检测当前周期环境数据后,与上一周期数据进行对比,如果差值小于设定阀值,则当前周期不发送数据。如果超过设定阀值,则将变化的参数发送到路由节点。上位机如果未收到本周期某一节点数据,则默认当前周期该节点环境参数未有大的改变,使用上一周期检测值为本周期环境参数值,减少数据传输过程中的能耗。检测器器变周期数据传输机制工作流程图如图5所示。
通过特征分箱离散化连续变量,同时将离散变量合并成少状态。经特征分箱后的数据,具有更易于模型快速迭代和降低模型过拟合风险等优势。
四种模型的AUC值均低于0.8,预测准确性不是很高,离想要检测逾期客户的目标还有一定差距。其中表现较好的模型为逻辑斯蒂和BP神经网络,AUC值为0.71。
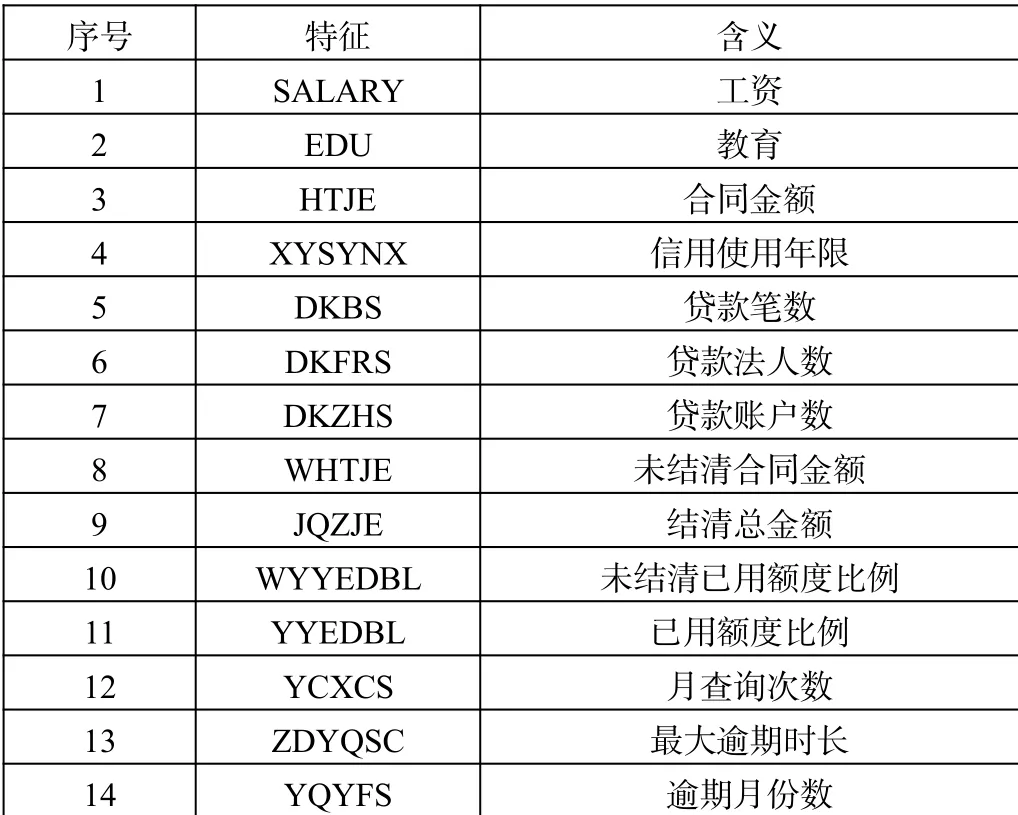
表1 特征选择结果
基于“smbinning”包对各特征进行最优分段,通过分段结果对数据进行封闭性分箱和转换,如特征“信用使用年限”的分段结果如表4所示。

表2 训练集和测试集数据概况
3 初步建立逾期检测模型
将“xgboost”函数的目标设为逻辑斯蒂模型,由于逻辑斯蒂为广义线性模型,表达能力有限,而特征分箱后每个变量有了权重,即引入了非线性到模型中,显著提升了模型的表达能力和拟合效果。
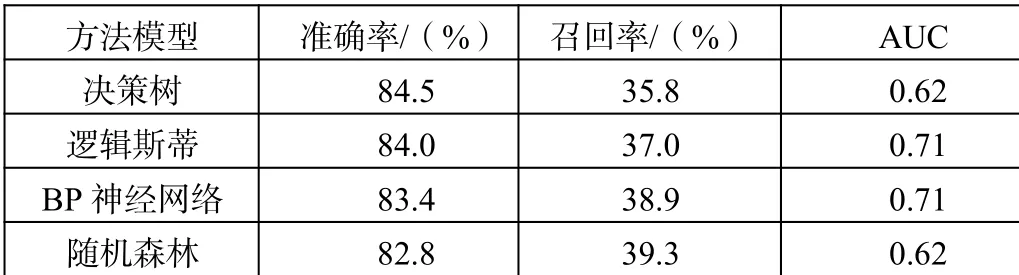
表3 四种模型结果对比
在弹体打击岩石条件下,弹靶间形成应力波并向地下传播,在冲击波或接近于冲击波的短应力波中,岩石介质压缩行为是在受限条件下发生的[7],从物理力学本质上讲,岩石介质的变形状态可以用刚性壁圆筒中的单轴压缩描述。设沿圆筒的轴向应力σr为垂直于弹靶接触面的法向应力;沿圆筒的径向应力σθ为平行于弹靶接触面的切向应力。由于应变仅发生在轴向,因此,这时,体积应变ε约等于轴向应变εr,径向应变εθ约为0。
随着全球信息技术主导的技术革命不断加快,人类社会正在逐渐步入信息社会。随着信息化、大数据等技术不断深入,在信息化时代背景和思维模式下,建立固定资产信息化管理平台对高校固定资产进行管理,不断提高固定资产管理效率,深入优化固定资产管理手段,是高校固定资产管理的发展目标和趋势。
4 特征分箱
例如针对“数据集:贷款记录”,由ID将贷款状态拆分成“呆账、结清和正常”三类属性的数据。最终从100多个指标中初步构建了42个特征。接着,利用R语言“informationvalue”函数计算各定性指标的IV值,选择有高预测性能的前两个显著特征“工资”和“教育”;再通过广义交叉验证法得到10个显著性指标,主要包括信用状况、偿还历史和逾期行为3个维度的指标,结合Boruta算法得出变量对逾期状态影响的显著性,根据变量间相关性图和现实意义,筛选出“信用使用年限”和“贷款账户数”;最终,经过定性指标和定量指标的筛选,从42个初选特征中选择了重要程度前14的特征。特征选择结果如表1所示。
(3) 采用场变量法模拟浆液初凝及硬化过程:①浆液注浆阶段,认为其有内压,其弹性模量取1 MPa;②浆液硬化阶段,经过10 h 浆液凝固后,其弹性模量取50 MPa[5]。
处理完缺失值后,采用无放回随机抽样方式,将总体以7∶3的比例拆分成训练集和测试集,数据基本情况如表2所示。
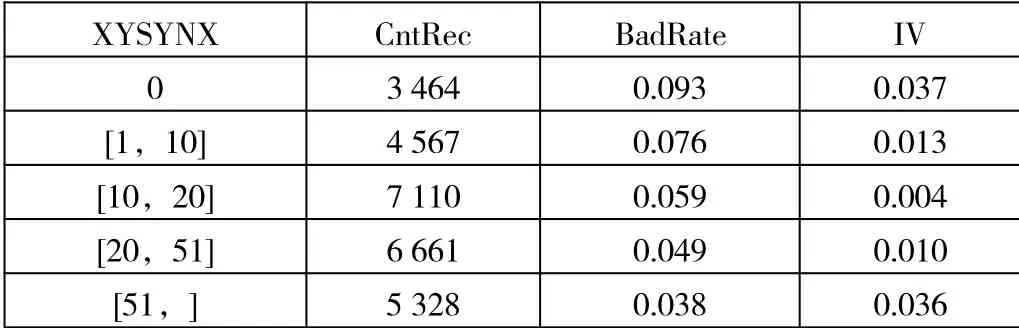
表4 “信用使用年限”分段结果
5 逾期检测模型探索和优化
5.1 基于XGBoost的集成学习模型
前面几种机器学习模型的预测精度相对不高,尝试基于XGBoost算法的集成学习模型以提高预测模型的精度。同时,将分别对原数据和特征分箱变换后的数据进行预测,以观察特征分箱是否提升了模型的表达能力和拟合度。XGBoost模型结果如表5所示。

表5 XGBoost模型结果
通过R语言“xgboost”函数建立模型,经参数调试后对原数据进行预测,得到预测准确率为84.5%,召回率为37%,AUC值为0.72。
对特征分箱后数据进行预测,预测准确率为91.2%,召回率为52.7%,AUC值为0.82。
分别通过“gbm”函数建立决策树逾期检测模型(GBDT)、“glm”函数建立逻辑斯蒂回归模型,并通过逐步回归剔除非显著变量、“nnet”包所得BP神经网络模型、“randomForest”函数建立随机森林逾期检测模型,结果如表3所示。
5.2 基于CooK距离的多元模型
通过统计学方法分析得到离群点,观察离群点与逾期客户是否有显著的关系。一般如果观测样本的Cook距离比平均距离大4倍,则该数据点被判定为离群点。通过Cook平均距离的4和24倍分别进行离群值检测,其中显著离群点和全部离群点如图1所示。
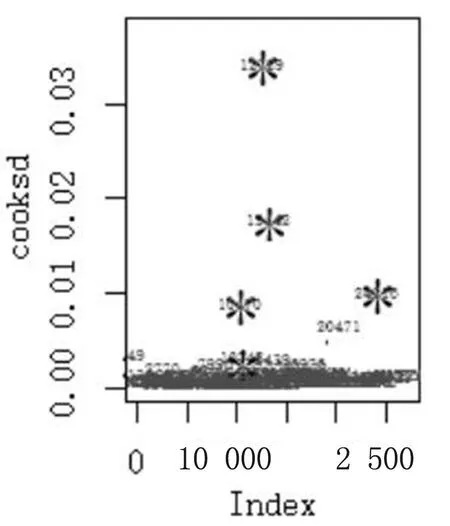
图1 异常值检测
经匹配样本号发现,基于Cook距离的多元模型检测法所得出的离群点基本为逾期客户,该模型表现出了较高的检测准确率和召回率。当Cook距离为4倍时,99.3%的逾期客户被检测出来,而此时模型的准确率仍非常高,为96.7%。具体如表6所示。

表6 基于Cook距离的多元模型
6 结论
进行分析的目的是检测出可能存在逾期行为的客户,基于这个业务背景,主要从模型的准确率、召回率和AUC值来评价模型的优劣。
四种机器学习模型的AUC值均低于0.8,预测准确性不是很高。模型优化上,通过XGBoost集成学习模型对原数据和分箱后数据分别建立模型,AUC分别提高到0.72和0.82,说明集成学习模型和特征分箱均有优势,且经特征分箱后的XGBoost模型预测准确率达到91.2%,召回率达到51.7%,模型有很好的预测效果。
模型探索上,由于逾期客户均在数据的某些特征取值上较为极端,故通过统计学方法,基于Cook距离的多元模型检测出来的离群点,与逾期客户有着显著的关系。当Cook距离为4倍时,99.3%的逾期客户被检测出来,而此时模型的准确率仍非常高,为96.7%,该模型表现出了非常高的分类效果。
