基于密集深度插值的3D人体姿态估计方法
2021-07-09陈梦婷王兴刚刘文予
陈梦婷, 王兴刚, 刘文予
(华中科技大学 电子信息与通信学院,湖北 武汉 430074)
0 引言
人体姿态估计一直是计算机视觉领域[1]中一个非常基础却又非常具有挑战性的任务。在给定图像或视频的情况下,预测人体关键点的2D或3D位置信息,这对于虚拟现实、增强现实、自动驾驶等需要空间推理的应用场景而言是至关重要的。得益于深度卷积神经网络(DCNN)的快速发展以及大规模手动注释的数据集的获取,目前在2D人体姿态估计方面已经取得了重大进展。
反观3D人体姿态估计的进展仍然有限,主要是由于在不受限制的环境中难以获得人体关节3D位置的真实标签。现有的数据集(例如Human3.6M[2])是使用Mocap系统在受限的室内实验室环境中收集的,这样采集得到的数据集无论是在视角还是在光照和场景的变化上都比较单一。虽然深度卷积神经网络能够很好地拟合这类数据集,但将这样训练得到的模型运用到仅有2D标注的不受限的场景图片上时(例如MPII[3]、MPI-INF-3DHP[4]),模型的表现往往不尽如人意。
研究发现,虽然人体是一个可以活动的结构,但是单个躯干(比如上臂、大腿等)可以近似看作是刚体结构。虽然数据集仅仅标注了关键点的3D信息,本文可以利用躯干两端的深度,通过密集插值估算出整个躯干的深度信息,从而构成密集深度插值特征图。本文将这个深度特征图作为模型训练的中间监督,这样可以为模型提供一个更加结构化的学习目标,而不仅仅是学习离散关键点的信息,从而有效提高模型的泛化能力,避免过拟合。而且在3个维度的学习过程中,深度学习往往是最具有难度的,通过密集深度特征图,可以让模型学习到结构化的深度信息,从而缓解因为遮挡、视觉变形带来的误差。
1 相关工作
1.1 2D人体姿态估计
树形结构模型最早被用来解决2D人体姿态估计问题,比如pictoral structures[5]和mixtures of body parts[6],其主要思路是设计一个用于检测人体关节的一元项,加上用于模拟人体2个关节之间的成对关系的成对项。还有传统方法中建立四肢之间外观的对称性模型或是设计两臂之间的排斥边缘,以解决重复计数问题[7]。最近,DCNN取得了令人瞩目的进展[8]。相较于直接回归关键点的坐标[8],目前更常见的做法是使用热力图,即以人体关节位置为中心的二维高斯生成的特征图作为模型回归的目标。常见的主干网络有ResNet[9]、hourglass[10]和multi-stage网络[11]。本文使用最新的HRNet[12]作为网络的主干架构。
1.2 3D人体姿态估计
3D人体姿态估计与2D人体姿态估计一直有很多相关之处。Lee等[13]首先研究了从相应的2D投影中来推断3D关键点的方法。后来的方法有的是利用最近临近算法来完善姿态推断[14],有的是提取手工特征来完成回归[15]。
后来越来越多的研究致力于利用深度神经网络来完成这一任务。可以大致分为单阶段方法和两阶段方法。单阶段的方法希望可以直接由输入图像得到3D人体姿态的估计结果。Pavlakos等[16]提出了3D关节的体积表示,并使用了从粗粒度到精粒度的策略来迭代地精修预测结果。此类方法都需要具有相应3D标注的图像。由于缺乏带有3D标注的室外场景图像,这些方法往往会在跨域数据集上效果较差。Yang等[17]将3D姿态估计器看作是生成器,并使用对抗学习的方法生成令判别器无法区分的3D姿态,以保证预测结果结构上的真实性。而两阶段方法主要是先学习一个2D人体姿态估计的模型,再学习从2D到3D的映射模型。比如在2D人体姿态估计模型的后面加一个优化模型[18]或者是回归模型[19-20]来完成对3D姿态的估计。比如Martinez等[20]引入了一种简单而有效的方法,可以仅通过对关键点的2D预测得到3D关键点的预测结果。Fang等[21]通过姿势语法网络进一步扩展了这种方法。这类方法往往能更好地泛化到其他室外场景数据集上。
2 密集插值姿态估计网络
2.1 密集深度插值
作为3D关键点任务检测,数据集只有离散的关键点的3D标注信息,所以很多方法仅仅通过2D的热力图作为中间特征,来帮助最后的3D回归。本文发现,虽然人体是非常灵活的结构,但是单独去看人体的某个躯干(比如左小臂、右大腿),可以近似地把它们看作一个刚体。因此,当仅仅只知道躯干两端点的深度信息时,可以近似估计出整个躯干的深度。
如图1所示,此处以一个小臂为例。Pw和Pe代表关键点手腕w(wrist)和手肘e(elbow)的2D位置,它们构成第m个躯干。这两点的深度真实值分别为Dm(Pw)和Dm(Pe)。那么Pw和Pe连线上的任意点P′的深度Dm(P′)都可以通过线性插值进行估算:

图1 密集深度插值示意图Figure 1 Diagram of dense depth interpretation map
(1)
不仅仅是两点连线上的点,本文对于位于躯干上的点P1都可以给出估计深度,只要P1满足:
(2)

除了上述矩形空间,本文对关键点附近的区域点P2也进行了深度估计:
(3)
(4)
所有满足式(3)范围内的点的深度等于Dm(Pe);所有满足式(4)范围内的点的深度等于Dm(Pw)。最后得到的范围区域以及对应的预估深度图如图1所示。
每个躯干由一个单独的特征通道表示,本文采用一共有16个关键点组成的15个躯干,因此密集深度插值构成的目标特征共有15个通道,如图2所示。每个通道仅有部分属于躯干的点才有深度回归的目标,其他点因为没有目标值,所以在计算损失函数时不考虑。最后构造得到的目标特征图用D表示,它的第m个通道为Dm,代表第m个躯干的连续深度分布。
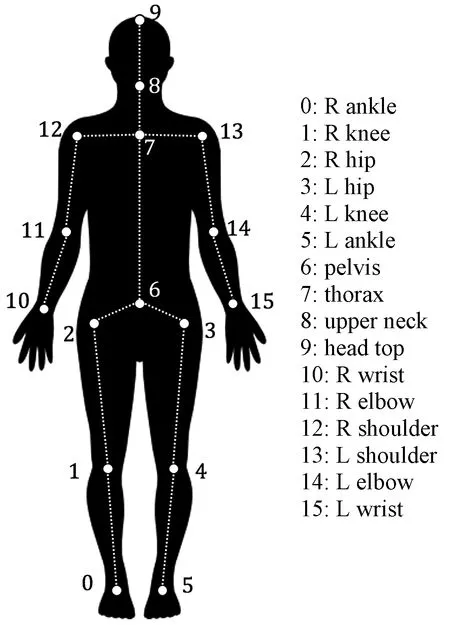
图2 人体躯干示意图Figure 2 Diagram of human body
2.2 辅助2D热力图
上述密集深度插值特征既包含了躯干在2D平面的位置信息,还包括了躯干的连续深度值。但是相对而言学习起来比较困难。为了能够更好地学习拟合该特征图,本文用另外两个2D热力图作为辅助分支,如图3所示。

图3 辅助2D热力图示意图Figure 3 Diagram of auxiliary 2D heat map
在关键点热力图中,每个关键点单独占一个通道。假设Pk是第k个点在图像中的真实位置,且Pk∈R2。那么第k个关键点在位置P的置信度为
(5)
其中,σ控制山峰的陡峭程度。由此构造得到的辅助2D热力图如图3 (b)所示。
上述辅助2D热力图仅仅表征了关键点的2D位置,为了能更好地辅助躯干的深度图,本文构造了另一个代表躯干位置置信度的热力图。同样,本文以Pw和Pe代表关键点手腕w(wrist)和手肘e(elbow)的2D位置为例,它们构成第m个躯干。对于所有满足式(2)的点P1属于第m个躯干的置信度为
(6)
对于所有满足式(3)或式(4)的点P2,它们的置信度分别为
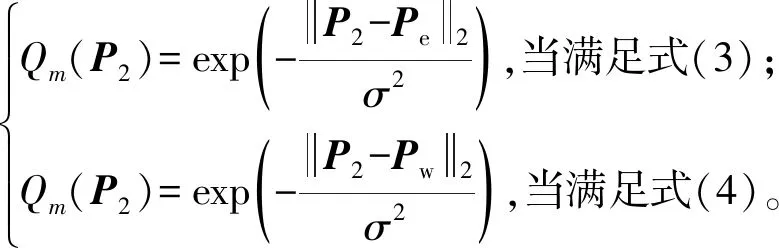
(7)
由此构造得到的辅助热力图如图3(c)所示。
2.3 整体网络结构
当获取了上述3个目标特征图后,网络的整体框架如图4所示。整个训练过程分为2个阶段。第一个阶段是输入图像到中间特征的训练。这里的Backbone使用的是HRNet[12]结构,本文的最后一个模块分成3个不同的分支,来分别预测3个特征图,之前的所有网络都是共享参数。对于关键点和躯干的热力图,本文使用的是均方误差(MSE)损失函数。辅助关键点热力图的损失函数为

图4 模型整体框架图Figure 4 Diagram of model structure
(8)

因为对于躯干而言,不同的躯干的长度差异较大,为了避免因非0值的数量造成的差异,本文设置权重因子来平衡这种差异:
(9)
(10)

对于密集深度插值特征图,因为只考虑躯干位置的深度,其他位置不参与损失函数的计算,所以通过躯干的辅助热力图对不考虑的点的损失函数设置为0,并且也通过权重因子来平衡不同躯干的权重:
(11)
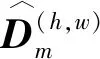
L1=LD+w2D(LS+LQ)。
(12)
式中:w2D是辅助2D任务所占的权重。
第一阶段训练完成之后,用将第一阶段模型预测得到的3个输出作为输入,通过网络直接回归最后的3D姿态。使用的网络是由卷积层、最大池化层、ReLU层以及全连接层组合得到。最后得到关键点的3D位置预测,采用两阶段的训练方式,主要是为了防止回归网络过拟合,中间监督失去作用,从而使网络的泛化性能变差。
3 实验结果
3.1 数据集
在3个最常见的人体姿态估计数据集上进行了实验。Human3.6M[1]数据集是最大的3D人体姿态估计数据集,它包含了3.6×106张图片,来自11个人。每人会表演15个日常动作,比如:吃、坐下、行走和拍照等。数据集的3D姿态真实标签由Mocap系统获取,2D姿态真实标签可以通过已知的摄像机内外部参数投影得到。参照Human3.6M上的标准协议,评估指标为在对齐根关节深度后,所有关节的真实值与预测值的平均位置误差(MPJPE),单位为mm。
MPI-INF-3DHP[4]数据集是最近提出的由Mocap系统构建的3D人体姿态数据集。本文仅使用该数据集的测试集,其中包含来自6个人的7个动作,共2 929张样本。本文用3DPCK(阈值150 mm)和AUC两个指标来定量评估模型的泛化能力。
MPII[3]数据集是2D人体姿态估计任务中使用最广泛的数据集之一。它包含从YouTube视频中收集的2.5万张图像。数据集提供了2D标注,但没有3D的标注。因此,直接使用此数据集进行3D姿态估计训练是不可行的,故本文将此数据集用于多任务网络的训练。
3.2 实验结果
在目前最常用的3D人体姿态估计数据集Human3.6M上进行了评估。和之前的许多方法一样,在第一阶段的训练过程中,联合MPII数据一起训练。因为MPII只有2D标注, 所以只参与辅助2D分支的训练。详细的结果和对比如表1所示。可以看出,本文方法和之前的方法相比,结构更加清晰简单,而且具有更好的性能。

表1 在Human3.6M上的MPJPE比较结果Table 1 Results of MPJPE on Human3.6M mm
3.3 跨域泛化结果
本文使用数据集MPI-INF-3DHP来验证模型到另一个全新的3D人体姿态估计数据集上的跨域迁移能力,该数据集的所有数据都不会参与训练过程,比较结果如表2所示。可以看出,通过密集插值特征图训练得到的模型具有更强的泛化迁移能力。

表2 在MPI-INF-3DHP上的跨域验证实验结果Table 2 Results of domain transfer on MPI-INF-3DHP mm
模型在数据集MPI-INF-3DHP[4]上的可视化结果如图5所示。可以看出,即使在出现物体遮挡或者姿态比较独特的时候,本文的模型也可以给出精确的结果。

图5 在数据集MPI-INF-3DHP上的可视化结果Figure 5 Visualization on MPI-INF-3DHP
3.4 消融实验
首先比较了分两个阶段训练与单阶段联合训练的区别,实验结果如表3所示。可以看出,如果采用单一阶段的训练方式,在Human3.6M上的MPJPE结果会有细微提升,但是如用训练好的模型直接在数据集MPI-INF-3DHP做跨域验证时,3DPCK和AUC都有大幅度下降,说明只有分两阶段训练,才能强制模型去学习有用的结构化信息,而不是直接去拟合离散关键点。这也进一步证明了本文所提出的密集深度插值特征图可以为模型带来更强的泛化能力。

表3 不同训练方式在Human3.6M和 MPI-INF-3DHP上的结果Table 3 Results of different training strategy on Human3.6M and MPI-INF-3DHP mm
4 结论
提出了一种基于线性插值的密集深度插值特征图作为3D人体姿态估计任务的中间监督,并通过两个辅助2D热力图来降低学习难度。通过在公认基准Human3.6M上的实验证明了该特征图的有效性和简洁性。并通过在MPI-INF-DHP上的跨域验证实验展示了模型强大的泛化迁移能力。由此可以看出,用结构化的深度信息作为学习目标可以有效地提高模型的性能。这种结构化也可以直接拓展到整个3D空间,将这种插值结构信息的作用发挥到最大,这也是本文未来的研究目标之一。
