基于深度学习的OCT图像视网膜积液自动分割
2021-07-09江旻珊
魏 静,江旻珊,茅 前
(上海理工大学 光电信息与计算机工程学院,上海 200093)
引 言
糖尿病性黄斑水肿(dabetic macular edema,DME)是血视网膜屏障破损导致黄斑区液体积聚的一种眼底疾病,是糖尿病患者视力损伤的重要原因[1]。DME患者若未及时得到诊断和治疗,会导致不可逆的视力损伤。DME的主要治疗方式是向玻璃体内注射抗血管皮生长因子(anti-VEGF)来抑制异常的新生血管生长,但是患者的个体注射方案需要医生根据积液的类型和区域大小来决定。视网膜积液根据积聚位置分为视网膜内积液(intraretinal fluid,IRF)和视网膜下积液(subretinal fluid,SRF)。光学相干断层扫描(optical coherence tomography,OCT)是一种无辐射非侵入的成像技术,能提供清晰的视网膜横截面图像。眼科医生通过观察DME患者的视网膜OCT图像中的积液类型和积液区域大小判断病变情况,但不能准确地量化积液并据此制定治疗方案。然而,手动分割视网膜积液在人力和时间上都是一个巨大的挑战。自动准确量化OCT图像中的IRF和SRF可以大大提高医生的诊断和治疗效率,因此,一种能够自动分割积液区域的算法对于临床诊断尤为重要。
近些年,很多自动分割OCT视网膜积液的方法被提出,主要分为传统图像分割和机器学习两类。王杰等[2]通过模糊水平集识别B 扫描和C 扫描上的流体区域边界,组合边界生成视网膜积液的3D分割,并在10只患有DME的眼睛上对算法进行了评估,该方法需要预先分割视网膜层并对分割结果进行手动校正。Chiu等[3]提出了一种基于核回归的机器学习方法对视网膜层进行分类,再结合图论和动态编程的框架识别准确的视网膜层和液体位置,在10名患者的OCT图像上进行了验证,但是这种方法并没有区别视网膜内积液和下积液。Montuoro等[4]使用随机森林分类器结合图论同时分割视网膜层和流体区域,然后利用二者的相互作用提取各种基于上下文的特征改善分割结果。传统图像分割算法和机器学习都依赖于复杂的数学计算和连续的迭代优化,处理图像时间较长。
近几年,深度学习技术不断发展,尤其是卷积神经网络广泛应用于医学图像分割领域。Schlegl等[5]提出了一个编码-解码的卷积神经网络用于检测和量化黄斑疾病的IRF和SRF,在IRF上取得了良好的性能。Roy等[6]开发了ReLayNet同时分割7个视网膜层各流体区域,而没有区分积液类型。Lu等[7]应用图分割算法预先分割内界膜和布鲁赫膜,使用U-net网络自动分割OCT图像中的IRF、SRF。根据已发表的文献,大多数分割多类视网膜积液的方法都需要联合视网膜层分割或使用两级网络,但是错误的层分割或上一级网络也会对最终的分割结果造成影响。
本文提出一种改进的U-net神经网络Res-SE Unet来自动识别视网膜OCT图像中的IRF和SRF区域。用Res-SE Block替代U-net的标准卷积层,残差可以减少梯度消失的问题而SE块可以学习更有效的残差特征,提高网络的分割精度。本文方法不依赖视网膜层的分割或者上一级网络,减少了错误的层分割或上一级网络训练结果的影响,并缩短了算法处理时间。
1 材料与方法
1.1 图像预处理
本文使用了来自加州大学圣地亚分校的Kermany数据集[8],该数据集使用Spectralis(海德堡)成像系统采集,包含了37 205张脉络膜新生血管(CNV),11 348张糖尿病黄斑水肿(DME)、8 616张玻璃膜疣(Drusen)、26 315张正常(Normal)视网膜OCT图像。本文提出的网络目标是从DME的OCT图像中同时检测和量化IRF和SRF,从 DME类别中抽取了80张含有IRF和SRF的OCT图像作为实验样本,由两名眼科专家独立标注病变区域轮廓如图1所示,红色轮廓表示IRF区域,黄色表示SRF区域。当出现明显不一致标注或由于图像质量问题较难标注时,从数据集中排除此实验样本。

图1 手动标注的OCT图像Fig.1 OCT image with manual annotation
如图2(a) 所示,IRF和SRF限制在视网膜内界膜(ILM)和布鲁赫膜(Bruch’s membrane)之间,因此,利用视网膜区域与背景的灰度差异对感兴趣区域进行提取,结果如图2(b) 所示。增大积液区域所占像素比例,一定程度上减少背景与积液不均衡对分割结果的影响。OCT图像基于相干光干涉的原理成像,扫描对象亚分辨率的不同会引起反射波随机干扰产生斑点噪声,影响网络的特征提取。为了解决这一问题,采用双边滤波算法来去除噪声,此算法在抑制散斑噪声的同时还可以保持图片边缘,图2(c) 显示了去噪后的OCT图像。Kermany数据集中OCT图像分辨率不同,将图像统一调整为256×256作为网络输入。将OCT图像和标签图作为实验样本按7:3的比例随机划分为训练集和测试集,训练集用于训练和验证网络模型,测试集用于评估网络性能,训练集和测试集的样本互斥。深度学习的训练需要大量数据,而我们的样本数量不足以支撑,且人工标注耗费大量时间,所以本文采用数据增强的技术,通过随机旋转,上下平移和图像翻转等30倍扩充训练集图像数量,减小网络训练过程中的过拟合问题,提高分割准确度。

图2 OCT图像预处理步骤Fig.2 The pre-processing of OCT image
1.2 网络结构
1.2.1 Res-SE Block
Res-SE Block由残差连接和SE块组成。残差连接已被证明是在深层次网络学习特征时克服梯度消失问题的有效方式[9]。2017年,Hu等[10]提出SENet(squeeze-and-excitation networks)获得了ImageNet挑战赛冠军,网络结构单元SE块在特征通道维度上加入Attention机制,通过损失函数学习各维度的权重,根据各维度的重要程度学习残差特征。Res-SE Block的结构如图3所示,Xl经过两次卷积操作得到大小为H×W×C的特征图Xr,通过全局平均池化转换为 1 ×1×C的特征信息,每个二维特征通道的转换公式为
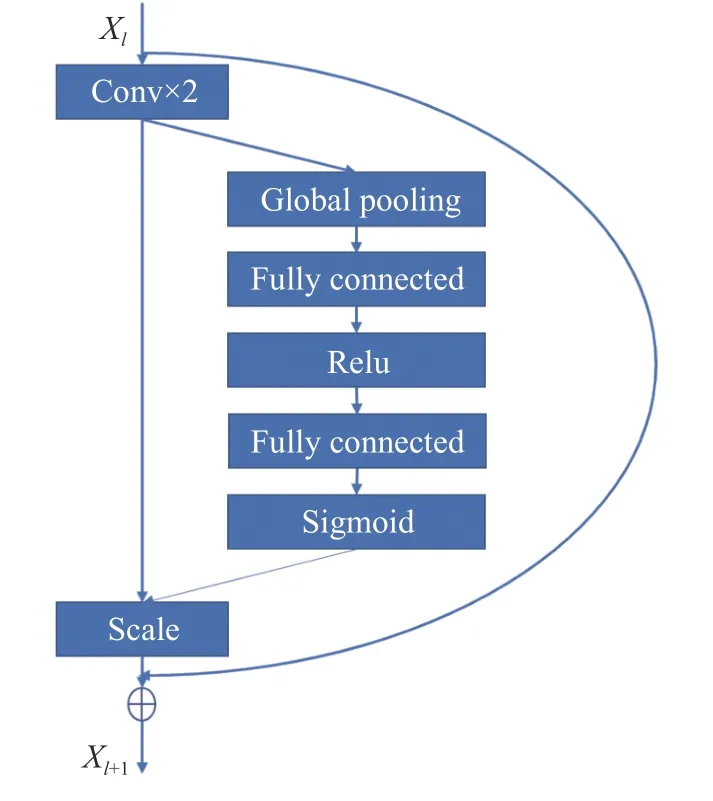
图3 Res-SE BlockFig.3 Res-SE Block

式中:Fsq(·) 表示挤压操作;xc表示Xr第c维度上的特征图;H、W分别表示特征图的长和宽;uc表示经挤压后得到的特征值;h、w分别表示特征图上某一点的横坐标和纵坐标。
经两次全连接层和RELU激活函数学习各个特征通道之间的相关性,通过Sigmoid函数将特征间的相关性进行归一化,得到各特征通道的权重,通过权重与对应的特征通道相乘进行特征重标定

式中:Fex(·) 表示激励操作;W1和W2表示两个全连接层;Xc表示Xr第c维度上的特征图;Vc表示该特征图通过激励操作得到的权重。
将SE块嵌入残差连接,根据重要程度对不同维度的残差特征进行提升或抑制,提高网络学习能力:

式中:Xl表示Res-SE Block的输入;X表示Xl经过SE块的变换结果;Xl+1表示Res-SE Block的输出结果。
1.2.2 Res-SE Unet
2015年,Ronneberge等[11]提出了U-net网络用于医学图像的语义分割,由具有相同卷积数量的收缩路径和扩展路径对称组成,收缩路径包括四个下采样层提取图像语义信息,扩展路径包括四个上采样层还原图像尺寸重建图像。U-net神经网络首次提出跳跃连接将下采样层和上采样层的特征融合,多尺度融合使底层的细节信息能够补充高层相对抽象的语义信息,提高分割精度。
Res-SE Unet神经网络使用Res-SE Block 代替U-Net 神经网络的标准卷积模块,学习重要特征,网络结构如图4所示。相比于标准 U-net 神经网络,本模型的最大通道数为 512,减少网络参数数量,同时保持较好的泛化能力。本模型收缩路径和扩展路径中的单元数量与标准U-net相同,每一个收缩单元包括一个Res-SE Block提取图像特征和一个下采样层,下采样层采用2×2的最大池化,特征图尺寸减小一半;每一个扩展单元包括一个Res-SE Block和一个上采样层,上采样采用转置卷积,特征图尺寸扩大2倍,通过拼接方式与收缩路径中对应的特征融合。在最后一层,网络采用通道数为3的3×3的卷积层,压缩扩展路径输出的特征图维度,3个通道分别对应IRF、SRF和背景。网络还使用Softmax激活函数将最后一层的输出归一化,取每个像素的最大概率对应的通道作为分类结果。

图4 Res-SE Unet 网络结构Fig.4 Res-SE Unet architecture
1.2.3 损失函数
视网膜积液分割是通过神经网络将OCT图像的像素分为背景、IRF、SRF三类。将图片的像素看作分类样本,积液类别的样本数量较少,为了使神经网络学习时更加关注IRF和SRF的特征,赋予样本较少的类别较大的权重,提高网络对积液的分割性能。每个类别的权重为
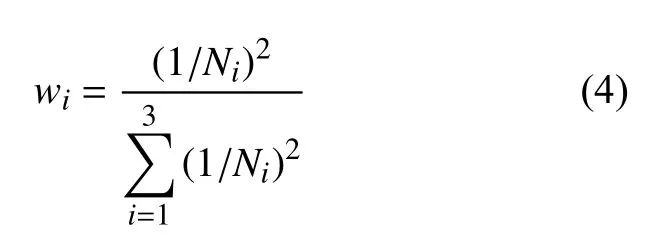
式中:wi为每个类别的权重;Ni为图中每个类别的像素总数。
本文使用加权多类损失函数,该损失函数由Dice损失函数和交叉熵损失函数结合共同优化模型。Dice损失函数和交叉熵损失函数公式分别为


最终,加权损失函数为

式中 λ1和 λ2分别表示Dice损失和交叉熵损失在总损失中的比例。
1.3 训练过程
本研究的运行环境为NVIDIA cuDNN7.5、CUDA10.0、Python 3.7、Anaconda3,硬件配置为RTX 2080Ti GPU,256 GB容量的硬盘,深度学习的框架为tensorflow。神经网络通过训练数据学习各层权重并通过验证数据验证模型性能选择最优模型,每一轮学习从训练集中随机抽取80%训练模型,剩余20%用于验证模型,提高模型学习能力。分批输入数据减少训练时间。本研究采用Adadelta优化方法对网络参数进行优化,使用式(7)提出的加权联合损失函数判断网络模型的训练过程。根据训练结果调整参数,损失函数的 λ1和 λ2分别设置为0.3和0.7,设置训练批大小为6,训练数据集迭代100轮。
1.4 统计方法
为了定量评估本文算法的分割性能,采用Dice系数和IoU系数作为评价指标,通过计算神经网络预测和专家标注之间的区域相似性衡量IRF和SRF分割的准确性。
Dice系数的计算式为

IoU的计算式为

式中:A为积液的真实标注图;B为预测的分割结果。
本文对IRF和SRF的分割效果进行独立评估,将非指定类型的流体区域视为背景。
2 结 果
2.1 实验结果分析
利用本文模型在20张包含IRF和SRF的OCT B扫描图像上进行测试评估,计算每张图像与预测结果的Dice系数和IoU。图5箱线图显示了测试集图像IRF的Dice系数分布情况,网络对IRF分割的Dice系数最高达到了0.90,SRF的Dice系数最高达到了0.96。Dice系数的分布也较为集中,这表明网络在一般情况下对流体都能进行有效的分割。表1显示了我们的方法在整个测试集中的平均表现,IRF的Dice系数为0.84,IoU系数为0.72;SRF的Dice系数为0.86,IoU系数为0.74。

表1 测试集积液分割评估结果Tab.1 Evaluation of the fluid segmentation results for test OCT image
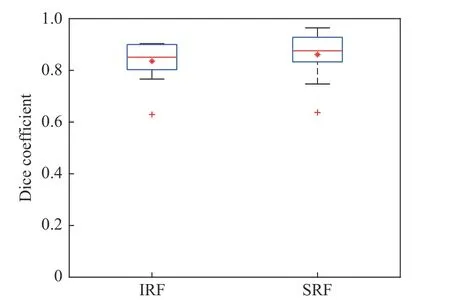
图5 Dice系数箱线图Fig.5 Boxplot of Dice coefficient
本文还比较了Res-SE Unet与U-net[7]、基于膨胀卷积的分支残差U-net(BRUNet)[12]、使用补丁的含有两个额外最大池化操作的PaEX-Unet[13]。表2描述了四种网络自动分割IRF和SRF的Dice系数,Res-SE Unet相比于其他网络,IRF和SRF的Dice系数都有一定程度上的提高,这表明该网络可以更加有效地分割OCT图像中的流体区域。这主要是由于Res-SE Unet利用残差连接,在一定程度上减小了特征信息在传播时的损失,同时SE块提高了图像有用特征的权重,提升了模型的分割性能。

表2 不同网络在测试集上的Dice系数比较Tab.2 Comparison of Dice coefficients between different networks on test dataset
图6展示了本文模型对测试集内一些OCT图像的分割效果。第一行是DME患者的OCT图像,第二行是专家手动标注的标签图,第三行是网络对积液区域的预测结果,其中白色区域表示IRF,红色区域表示SRF。第一列至第三列显示了一种简单情况,OCT图像中表现出明显的黄斑囊样水肿或浆液性视网膜脱离时,我们的方法表现出了良好的性能;第三列和第四列显示了OCT图像信噪比相对较低时的分割结果,图像对比度较低,流体边界不明显导致分割效果较差,但是网络基本可以检测到流体位置;第五列显示了测试集中IRF分割效果最差的情况,这种情况主要是由于一些IRF区域面积过小,网络对这些区域的识别能力较低,或是流体与视网膜组织中的阴影区域难以区分,专家未标注的阴影区域也被网络标记为IRF。

图6 测试集中IRF 和SRF的分割示例Fig.6 Example segmentations of IRF and SRF from the test set
3 结 论
本文中提出了U-net改进网络Res-SE Unet,用于自动分割视网膜OCT图像中的IRF和SRF区域。所提出的网络使用Res-SE Block替代Unet中的卷积层,更加有效地学习图片的特征信息。为了减小图片中背景与流体区域不平衡的问题,在训练之前先进行图像剪裁,去除大部分背景,在训练中还使用加权损失函数优化模型,增加IRF和SRF的权重,提高积液分割的准确度。我们的网络在测试集中取得了良好的分割效果,测试样本中IRF的Dice系数和IoU平均值达到了0.84和0.72;SRF的Dice系数和IoU平均值达到了0.86和0.74。Res-SE Unet可以较为快速准确识别IRF和SRF,有助于眼科医生根据病情调整治疗方案。基于深度学习检测和分割DME中的积液需要大量图像数据用于模型训练,但由于分割目标限制,Kermany数据集中DME组同时含有IRF和SRF的样本数量较少,限制了模型训练效果。随着未来公开可用的DME OCT图像数量增加,所提出的网络的分割性能也会进一步提高。我们的网络对小区域的流体分割还需要进一步的提升,在未来的工作中,将继续研究损失函数减小目标与背景不平衡对分割结果的影响,在网络结构中加入生成对抗网络模型,增加特征图像的数量,提高网络的分割性能。
