基于DBNet 网络的瓶盖文字目标检测
2021-07-09吴鑫磊陶青川张畅
吴鑫磊,陶青川,张畅
(四川大学电子信息学院,成都 610065)
0 引言
中国白酒是中国传统文化中久经不衰的一朵奇葩,但是在白酒的市面流通上常常会出现一些假冒伪劣的假酒,为了保护白酒商家的权益和保证消费者能购买到正当的商品,白酒生产厂家都会为每一瓶出产的酒定下编号。但是在酒瓶生产的过程中,由于酒瓶包装工艺技术的不成熟,往往会伴随着酒瓶编码漏打的情况的出现,所以瓶盖文字检测极为重要,识别出生产过程中出现问题的那些酒瓶可以解决编码漏打误导消费者的一些问题,以提升酒瓶包装生产质量和效率。我国制酒工艺虽然成熟,但是在酒瓶文字检测上的研究及其的稀少。由于酒瓶瓶盖目标较小,对应的文字也比较小,而且在拍摄的过程中常常出现反光的情况,导致有时文字难以看清,并且文字有时也会是弯曲的形状,种种的情况都给瓶盖文字检测算法带来了不小的困难。
近些年来,由于机器视觉在各个方面的应用愈加广泛,目前对于实际场景中的文字识别的课题也逐渐变成机器视觉的研究热点。但是在现实场景中,文字并非始终成规则的矩形区域,时常会出现弯曲,或者成不规则的文字区域,因此目前来说对于文字区域的识别仍然是目前文字识别的一大关键性的难点。当今有两种主流的场景文字识别的做法分别是:一种通过回归和一种通过分割,因为利用分割的方法可以在像素水平上进行预测,所以对于不同自然场景下的文字形状能够有着更好的描述效果[1]。图片二值化后的处理过程是利用分割的STD 算法的关键性的步骤,也就是分割后得到的概率图转变成文本框的流程,现在的算法大部分都是在pixel 层面进行后处理过程,中间过程比较复杂而且需要消耗大量的时间,基本流程如下:开始时定一个不变的阈值,来得到二值图,该二值图由分割网络产生的概率图得到;然后利用类似素聚类等启发式技术把像素集合成为文字实例[2]。DB 算法在基于分割的文本检测网络中,对于每一个像素点的二值化都是通过网络学习得到的,每个二值化都是自适应的二值化,由此得到的二值图会有很强的鲁棒行,在简化的同时还提升了效果。传统方法和DB 算法的比较:传统方法在分割之后使用的是固定的阈值求得二值化的分割图,然后利用像素聚类的启发式算法来获取文本区域;而DB 算法与传统算法不同的地方在于阈值的选取上,DB 算法利用网络对每个位置的阈值进行预测,而不是设定一个固定的值作为阈值,以该方法便可以更好的分离出前景和后景,可是这样会带来一个训练梯度不可微的情况,对此DB 便提出了一个叫做Differ⁃entiable Binarization 的方法来解决该问题[3]。
本文主要工作:前端嵌入式负责智能分析,分析结果由前端传输到中心端,中心端对分析结果进行记录汇总,该分层系统模式极大减小了中心端对多路视频信号的计算压力;利用深度学习的方法来对瓶盖文字进行检测定位,采用DBNet 网络来对文字进行一个预测,但是特征提取层采用Inception 网络轻量级目标检测网络框架,由此可以减少大量的神经网络参数,进而可以降低卷积神经网络对前端嵌入式设备性能的要求。Inception 网络可以对多个不同大小的卷积核进行并行运算或者是池化操作,网络对于尺度的适应性因此也有所增加,对这些卷积运算进行并行处理最后合并所有结果,由此获得的图像表征也将更加优秀。ResNet 网络的残差网络结构有着一个巨大的优势,它可以保证在一定限制内加深网络结构的同时不导致准确率下降。ResNet 残差学习模块将会堆叠每层的输入与输出,并且在堆叠的过程中不会增加网络的参数和计算量,因此模型的训练收敛速度也会有所提升,而且在模型不断加深的情况下,该结构还可以对退化问题有着较好的处理。Inception-ResNetV2 网络是基于In⁃ception V3 采用残差连接的网络结构,该网络结构可以训练更深的网络模型,也因此可以获得更好的训练效果,也由此在图像识别上有更高的识别率。本文在上述网络模型的基础上,以DBNet 为基础网络框架,并将特征提取模块替换为Inception-ResNetV2 网络,提出一种结合二者优势,网络层数更深,性能更优的网络结构,提高文字识别的准确率和其计算效率[4]。
1 算法描述
1.1 DBNet
当前对于文字检测的算法一般可以分为两类:一种基于回归另外一种基于分割。对于基于分割的算法流程一般如下图蓝色箭头所示:首先获取借助网络输出的图片的文本分割结果,即概率图,图片的每个像素点表示是否为正样本的概率,利用预先设置的阈值把分割结果图转变成二值图,最后利用一些类似于连通域的聚合操作把像素级的效果转变成检测结果[5],如图1 所示。
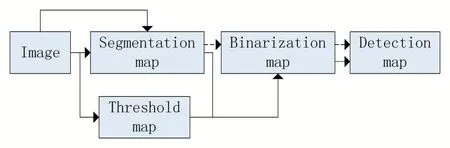
图1
由上述可知,由于判定前景和背景是通过设定一个阈值来进行操作,并且该操作是不可微的,因此我们不能够利用网络把这部分流程放入到网络中进行训练,但是DBNet 可以通过学习threshmap 并且利用可微的操作来把阈值转换放入到网络中来进行训练。其中大致流程如上图中的红色箭头所示。DBNet 基本网络结构如图2 所示,基本训练流程为:首先将图片输入网络,在经过特征提取和上采样融合并concat 操作后便可以得到上图中蓝色的特征图称为F,然后再使用F进行预测得到概率图(probability map)和阈值图(threshold map),分别称为P和T,最后便可以利用P和T 计算得到近似二值图。在整个推断过程中,我们可以通过概率图或者近似二值图来获取文本框。
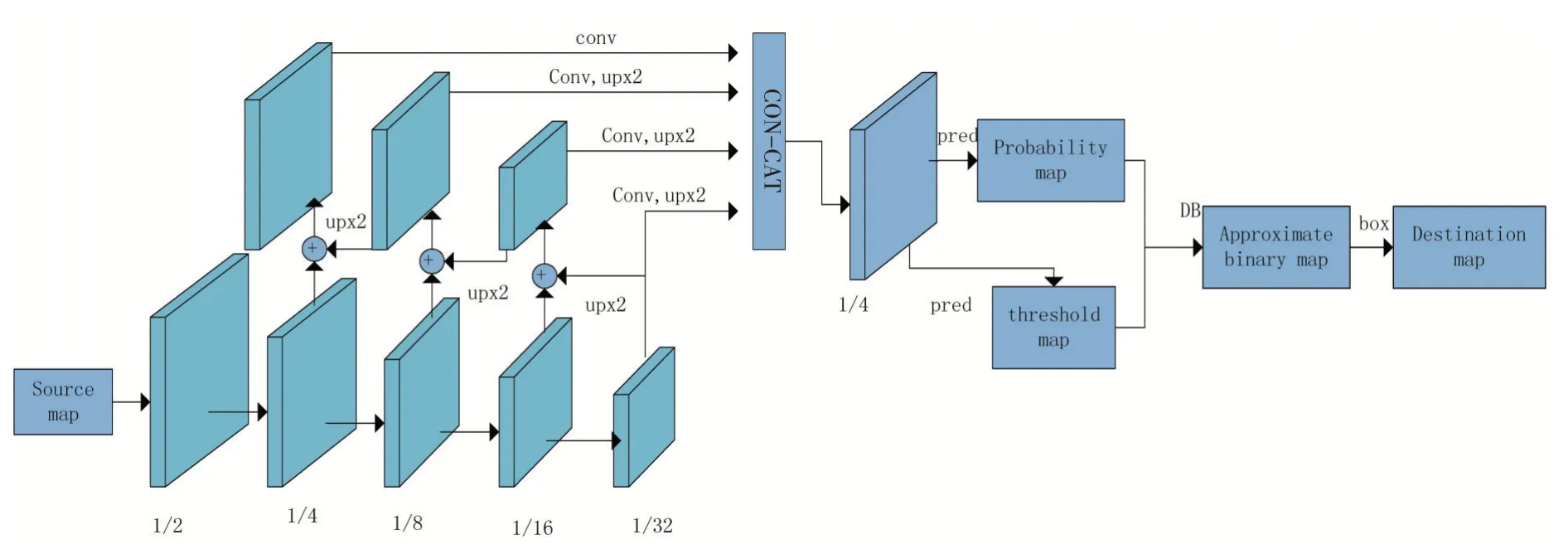
图2
一般的二值化方法不可微,无法放入网络学习中优化,为了解决这个问题便提出了一个近似的阶跃函数:
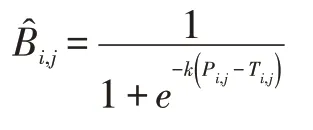
上式中T代表了网络学习的阈值图,k是一个因子,输出的表示近似的二值图。
该DB 网络能够改善网络性能的最主要原因,我们可以从反向传播梯度的方向来解释。首先定义:
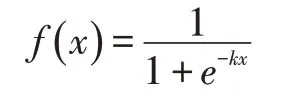
其中x=Pi,j-Ti,j是上述定义中的DB 函数。在利用二值交叉熵来作为loss 的情况下,对于正样本的lossl+和负样本的lossl-计算可以表示成如下两式:
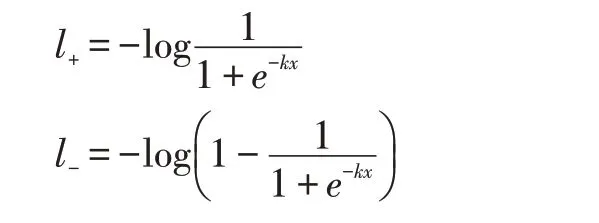
loss 对于输入x 的偏导数为:
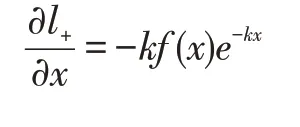
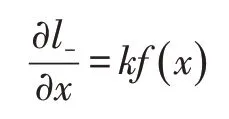
由微分公式可以得出:
(1)k为梯度的增益因子
(2)梯度对于错误预测的增益幅度很大
上述讲述了如何在获取到阈值图T和概率图P之后,将概率图P二值化为近似二值图。接下来将讲述如何获取二值图、阈值图T、概率图P的标签。由于瓶盖文字检测的图片较小需要大的感受野,文章将形变卷积应用到ResNet-18 或ResNet-50 的网络中。
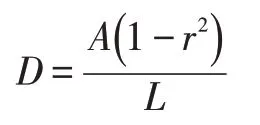
式中,r是预先设置的缩放因子,L为标注框的周长,A为标注框的面积。
阈值图T的标签生成过程如下:首先,使用上述偏移量D来对原始标注框G进行扩充,得到的框为Gd。然后,计算出在框Gd内的所有的点到G的四条边的最小距离(即Gd框内点距离最近的G框边的距离)。接着,将求得的最小距离通过除以偏移量D来进行归一化,要求将归一化的距离限制在[0,1]内,也就是将大于1 的改为1,小于0 的改为0。然后使用1 减去上一步中得到的map,由此便可以得到Gd框和GS框之间的像素到G框最近边的归一化距离。由于阈值图T的la⁃bel 不能是一或零,因此需要对label 值进行一定的缩放,我们可以将1 缩放为0.7,将0 缩放为0.3。loss 函数公式如下所示:
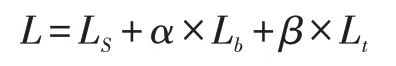
其中,Lt是阈值图的loss,LS是概率图的loss,Lb是二值图的loss。其中α和β分别取值为1.0 和10。于是我们可以利用二值交叉熵(BCE)对LS和Lb进行求解:
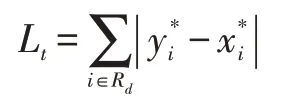
最后到了推断阶段,我们既可以由概率图来得到文本区域,也可以使用近似的二值图来生成文本区域。但是为了更加高效,使用概率图就足够了。生成文本区域的过程主要有如下几步:首先对近似的二值图或者概率图使用0.2 的阈值来获取二值图,接着利用上一步得到的二值图来求文本的连通区域,最后使用偏移量D'把连通区域进行放大就可以得到文本区域了,D'的计算方法如下:
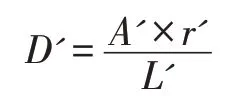
式中,r'设为1.5,A'表示连通区域的面积,L'是连通区域多边形的周长。
1.2 Inception-ResNetV2模型
Inception-ResNetV2 采用的是“Inception+残差设计”的一种网络结构,既保留了Inception 的高效率计算功能,又具有ResNet 的高深度学习的能力。Inception模块之所以计算较为高效,主要在于其是一种具有优良局部拓扑结构的网络,当我们输入图像时可以同时并行地执行多个卷积运算或者是池化操作,例如其可以同时并行执行1×1、3×3、5×5 和7×7 等多个卷积核大小不同的卷积操作,因此便可以获取输入图像的不同层次的特征信息,最后再将这些卷积输出结果进行合并拼接,以获得一个更深的特征图谱,这样便可以获得更优的图像表征。Inception-ResNetV2 网络主要利用的是分解的方法,其中Inception 结构部分做法就是把尺寸较大的一个二维卷积分解成两个不对称较小的一维卷积,例如把一个7×7Conv 拆分成一个7×1Conv 和一个1×7Conv,把一个3×3Conv 拆分成一个3×1Conv和一个1×3Conv,这样做可以减少计算量和参数量,并且由于拆分成的是不对称的卷积,所以也因此可以获得更加多样的特征。Inception-ResNetV2 网络输入在从224×224 变成为299×299 的时候,而在网络Incep⁃tion-ResNetV2 的内部结构中其中Stem 结构部分中使用了Inception V3 模型里的并行结构与分解思想,这样可以使得在信息损失足够小的前提下,保证减少其计算量,而在该结构下的1×1 的卷积核的作用是用来降维,并且其也增加了网络的非线性。Inception-ResNet-A、Inception-ResNet-B 和Inception-ResNet-C 等网络结构都采用的是“Inception+残差设计”的网络结构,因此这些网络的层次可达到更深,而其结构更加复杂,得到的特征图的通道数也将变得更多。而其中的Reduc⁃tion-A、Reduction-B、Reduction-C 三种结构则是用来降低计算量和缩放特征图谱的尺寸。Inception-ResNetV2 融合了Inception 模块和残差网结构两者的优点,既可以使得网络的深度和宽度得到增加,并且还可以避免梯度的消失[6]。图3 只给出Inception-ResNet-A结构,Inception-ResNet-B 和Inception-ResNet-C 结构类似。
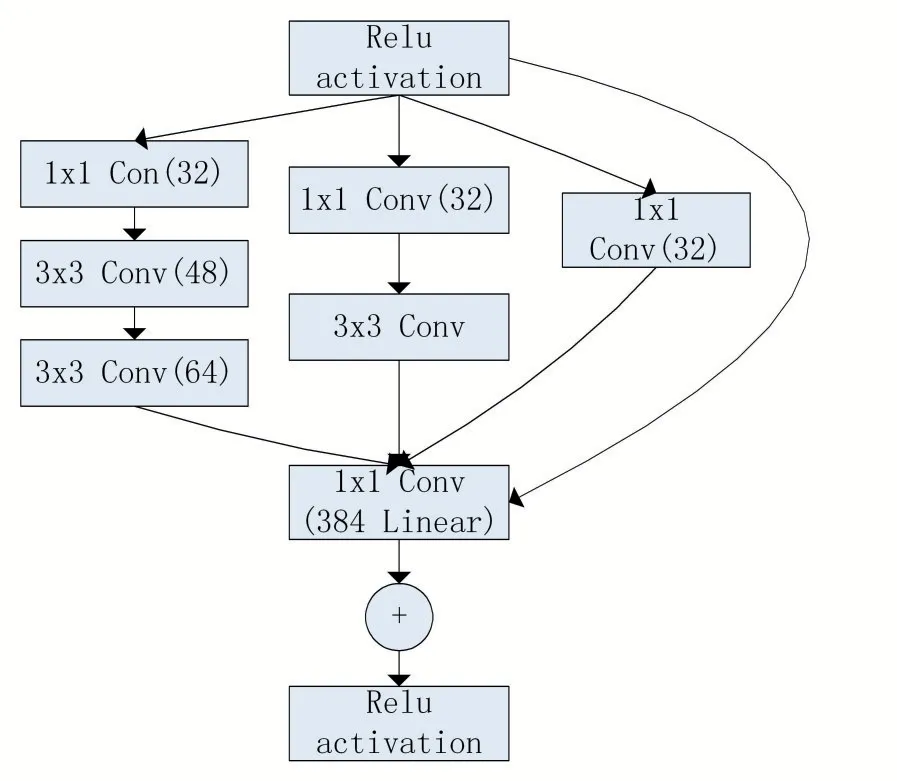
图3
1.3 算法改进
由于我们需要检测瓶盖上的文字区域,因此我们必须选取能够检测识别不规则文字区域的网络结构算法,而DBNet 对于不规则的文字区域的检测有着比较好的检测识别效果,因此我们选取DBNet 来作为我们的网络结构算法。但是由于我们需要我们的算法需要能够在低性能的计算机上跑起来,并且我们使用的开发板的具体情况为:主板AIO-3399J、芯片RK3399、处理器为ARM Cortex-A72(双核)及Cortex-A53(四核)主频2.0GHz,内存2GB。于是我们需要一种轻量级的卷积神经网络文字检测算法。由于DBNet 的特征提取模块采用的是ResNet50,而ResNet 计算量过大权值参数过多,我们需要对ResNet50 做出一些修改,来降低我们的参数和计算量。而Inception-ResNetV2 既保留了Inception 的高效率计算功能,又具有ResNet 的高深度学习的能力,因此我们选取Inception-ResNetV2 来对ResNet 来做一些替换,这样就能够在保证算法的准确性的前提下来对算法的效率进行提升。修改后的网络结构如下,主要针对特征提取模块,后面还是采用保留了原来的多尺度预测,主要突出ResNet50 和Incep⁃tion-ResNetV2 的性能和参数差别。
2 方法验证和实验对比
2.1 实验环境
本地计算机的基本配置如下:Intel Core i5-7400 的处理器,频率为3.GHz 的CPU,内存为8G,NVIDIA Ge⁃Force GTX1080 Ti 的GPU,显存为11GB,操作系统是Ubuntu 16.04。本实验所使用的前端嵌入式开发板的基本配置如下:主板为AIO-3399J、处理器为ARM Cor⁃tex-A72(双核)及Cortex-A53(四核)主频2.0GHz,内存为2GB;芯片为RK3399、操作系统为Ubuntu 16.04。
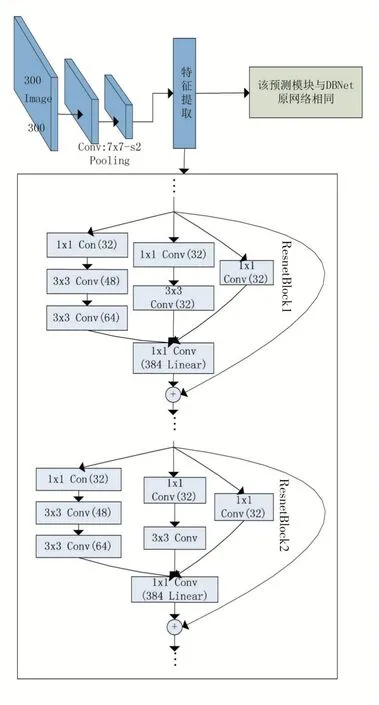
图4
2.2 瓶盖文字模型检测评价方法
在本文中我们使用的评判模型是mAP(mean Aver⁃age Precision),模型性能的评价常用的指标有:Accura⁃cy、Precision、Recall 等。由于mAP 是多个类别的评判方法,即mAP 是多个AP 求取平均值,因此次数的AP即是我们所求的mAP。Precision 代表的是精度,Recall代表的是召回率。mAP 就是用来评判我们算法的重要指标,各参数的计算方法分别如下:
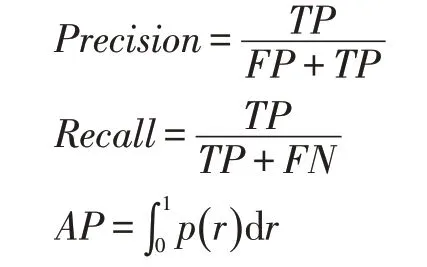
在式子中:FN(False Negative)代表实际为文字但是被判定为非文字的个数;TP(True Positive)代表实际为文字但是被判定为非文字的个数;FP(False Positive)代表实际为非文字但是被判定为文字的个数;而p(r)代表Precision 关于Recall 的函数关系。
由于在实际应用场景中,瓶盖的文字在某些情况下呈现一个弯曲或者不规则的形状,因此本文训练以及验证采用的是ArT 数据集,其中包括了Total Text、SCUT-CTW1500 和Baidu Curve Scene Text 等数据集,ArT 是如今规模较大的场景文本数据集之一。ArT 数据集中共有10,166 张图像。它分为带有5603 个图像的训练集和包含4563 个新收集的图像的测试集。其中有许多不规则的形状文字区域的图片,可以用于关于任意形状文本识别任务的研究。由于在该数据集中包含许多不规则的文字区域的图片,使用该图片来做训练能够更加符合实际酒瓶瓶盖文字的识别场景。
2.3 实验结果与分析
我们实验时将参数设置如下:批大小设置成64,将最大的迭代步数设置成200000,将识别部分的学习率设置成0.01,把权重衰减设置成0.001。将算法置于开发板下跑的结果实际原图(图5、图7)以及检测效果图(图6、图8)。

图5

图6

图7

图8
为了检验本文网络的实际应用价值,本文在ArT数据集文字数据集上分别从参数量、计算量、mAP 值、计算速度等评判标准上将YOLO、SSD、Mobile-SSD 和本文网络进行对比,具体的表格如下表所示。在评判的过程中,我们将所有的算法移植在AIO-3399 嵌入式平台上,然后运行算法获取其各项数据,并记录在下表中。由表1 中的数据可以得出修改后的网络参数相对于YOLO、SSD、Mobile-SSD 分别减少了98.8%、97.2%、88.7.%;并且在速度上对于每张图片的检测速度也有了大幅的提升,在开发板上可达到73ms 每张的速度,相对于以往的神经网络的文字检测算法有着巨大的提升。由于本文网络的设计目的在于提高算法的速度,降低算法的参数值和计算量,因此在瓶盖文字检测的实际使用场景下,该算法相较于其他算法是有着巨大的优势的,它能够在算法准确率下降不明显的情况下显著提高了算法的速度,使其能够在嵌入式开发平台上有效运行,满足实际的运用要求。并且由于工厂内的场景相对来说比较单一,光线稳定,该前提条件也使得算法的准确率有着较好的表现。
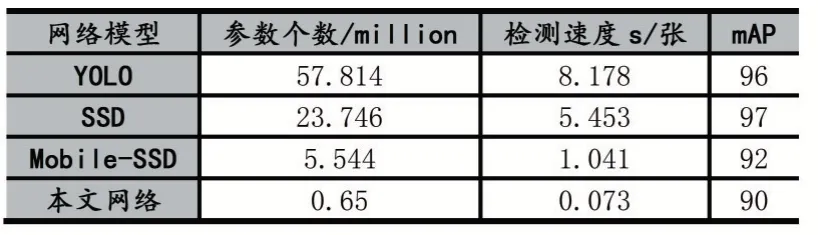
表1
3 结语
由于传统算法对于文字检测的速度和准确度上都不是很理想,但是对于一般的深度学习的方法却又参数量较大,速度不理想,并且难以移植入嵌入式开发板中进行运行,而且很难对弯曲情况下的文字区域进行有效检测。基于这些等等问题,本文提出了一种基于DBNet 的网络结构,将其占据大量参数的ResNet 特征提取模块采用Inception-ResNetV2 进行替换,在保证准确率下降微小的情况下,减少其所使用的参数量,大大地提高了文字检测算法的检测速度,并且由于实际生产环境较为单一,光线稳定,该前提条件也大大提高了本文算法的准确性,使得该算法在实际生产中有着非常好的使用效果。
