基于权重关联性的卷积神经网络模型剪枝方法
2021-07-08严阳春郭荣佐杨锦霞
严阳春,郭荣佐,杨锦霞
(四川师范大学 计算机科学学院,成都 610101)
1 引 言
在近几年,将卷积神经网络模型部署到资源受限的设备上的需求逐渐增大,例如FPGA和移动手机等终端设备.同时,随着模型的精度的不断提高,其参数量和计算量也在不断的增大.因此,在资源受限的终端设备上部署深层模型的难度逐渐提高,使其应用受到了很大的限制.为了打破这种限制,模型剪枝成为了一种在维持模型精度的情况下,十分有效地压缩和加速模型的方法.模型剪枝通过剪除模型中不重要的参数,来减少模型的参数量和相关的计算量,从而使得模型轻量化.模型剪枝按照移除的粒度大小可以被分为两种类别:非结构化剪枝[1]和结构化的剪枝[2].
非结构化剪枝是一种对每个权重单独进行评估的方法,它将被认为是冗余的权重置为零并移除.这样的方法虽然可以更加精准的判断权重的重要性,但也存在着在实际应用中难以部署落地,无法有效压缩加速模型的问题.非结构化的剪枝方法在剪掉不重要的权重后,会产生非结构化的稀疏,需要在支持稀疏矩阵计算的环境下才能实现剪枝效果.然而,对于资源受限的设备,例如FPGA,无法实现对于这些稀疏矩阵计算库的支持,同时也会造成不规则的内存存取,可能会影响到计算的效率.
结构化的剪枝方法能很好的避开上述问题.其核心思想是通过对结构化的权重进行评估,例如过滤器,剪掉相对不重要的过滤器,以此减少模型的参数量和计算量[2].根据剪枝方式,结构化剪枝可以分为局部剪枝和全局剪枝.由于对过滤器评估后得到的评估值一般具有局部性,只能在层内进行比较,局部剪枝的方法要求使用者指定每层的剪枝比例.为了得到每层的剪枝比例,使用者需要进行敏感性分析,不断地进行试错[2,3].然而,全局剪枝的方法则不需要为每层设置剪枝比例.全局剪枝通过对具有局部性的评估值进行全局标准化,从而实现评估值的全局可比较.
模型剪枝的核心是如何定义权重的重要性.目前的方法在进行评估重要性时,例如,文献[2]通过计算过滤器权重的L1范数值,只考虑了过滤器本身这部分的权重值,并没有考虑到依赖过滤器而存在的关联权重,这部分权重会随着过滤器的消失而消失.因此,这些方法忽略了权重的关联性.剪枝过程中,当过滤器的关联权重较为重要,但却随着过滤器而被剪枝掉,这会造成一些本可以避免的损失.同时,局部剪枝的方法需要设定每层的剪枝比例,这个过程需要不断的试错,降低了效率.然而全局剪枝方式,关键点在于利用一种合适的标准化方式实现全局可比较.
为了解决上述的问题,本文提出了一种基于权重关联性的卷积神经网络模型剪枝方法.首先该方法在定义过滤器的重要性时,除了考虑到该过滤器本身,还考虑到该过滤器的输出特征图在下一层的关联权重,即该过滤器的关联权重.其次,该方法通过常见的权重评估方法L1范数来获得该过滤器与其关联权重的重要性.然后,通过对重要性进行全局标准化,实现重要性的全局可比较.最后,根据具体应用场景,设置整个模型的剪枝比例,即设置阈值,在全局重要性排序中,将重要性小于阈值的过滤器剪除,获得紧凑的模型.本文提出的模型剪枝方法,采用结构化的剪枝方式,无需特殊的软硬件环境支持,是一种简单高效的模型压缩方法.
2 相关工作
模型剪枝可以使得存在冗余的模型自身变得更加紧凑,从而实现模型在推理上的加速和减少存储的消耗.由于方法的普适性,最近,学术界和工业界将更多的目光投向了结构化剪枝.文献[2]评估一个过滤器的重要性通过计算过滤器本身的L1范数值,同时由于采用的是局部剪枝的方法,需要设置每层的剪枝比例.文献[4]提出了一种软剪枝的方法,这种方法是一种训练与剪枝相互交替进行的方式,将本该被移除的过滤器权重置为零后,使其在训练时仍然继续更新权重值,其评估方法采用的是计算过滤器本身的L2范数值.文献[5]提出使用几何中值距离来评估每个过滤器的可替代性,对于与其他过滤器的相对距离的总和较高的过滤器,被认为是可替代的,即是冗余的.该方法是在软剪枝上做出的改进,将之前的对权重值大小的L2范数评估,改为了权重可替代性的评估.文献[6]通过对每一层输入少量图像后计算特征图的秩并以此排序,该方法认为秩越大的特征图所包含的信息量越大,相应的过滤器应当被保留.以上提及的方法,评估得到的重要性具有局部性,只能在层内进行比较,采用的都是局部剪枝的方式,需要指定每层的剪枝比例.
目前,全局剪枝的方法由于可以避免设置层级的剪枝比例而获得了越来越多的关注.文献[7]在损失函数中增加了对于BN层缩放因子的约束,进而使模型中的缩放因子较为稀疏,然后使用缩放因子的值作为相应过滤器的全局重要性进行全局剪枝.文献[8]提出了一种通过皮尔森相关系数来衡量过滤器间的可替代性的全局剪枝方法,为了提升效果,该方法在全局重要性上添加了一个层级的约束项.文献[9]提出了一种可学习的全局排列重要性的方式,把L2范数值作为过滤器的重要性,所有层的标准化方式都设置为线性转换,通过进化算法来求解每一层线性转换的参数值,以此实现全局重要性排列.但是,上述的所有方法评估时都只考虑了过滤器本身,并没有考虑到过滤器的关联权重.
最近,个别方法注意到了权重的关联性.文献[10]将过滤器和过滤器的关联权重拼接为一个约束项后添加到损失函数中,使得过滤器和它的关联权重变得同时重要或同时冗余.为了得到更好的效果,该方法需要进行迭代地剪枝.尽管该方法取得了很好的效果,但是该方法无法实现在经过预先训练后的模型上的压缩加速,需要从头开始训练模型,这样无疑增加了压缩过程中的工作量.
3 方法描述
怎么定义结构化权重的重要性无疑是整个结构化剪枝方法的核心.本节主要将通过常规的卷积神经网络模型作为范例来主要介绍如何定义一个过滤器的重要性.
3.1 权重的关联性
过滤器级别的模型剪枝是通过剪掉一部分重要性较低的过滤器,从而减少模型的参数量和计算量.可以发现,在剪掉一部分过滤器后,该过滤器的输出特征图在下一层的关联权重也会随之被剪掉,这一现象说明权重存在着的关联性.之前的一些方法在评估过滤器权重的重要性时,只对过滤器本身进行了评估,并没有将过滤器的关联权重考虑进去一起进行评估,这样可能会导致相对重要的关联权重被剪掉,带来一些原本可以避免的损失.因此,本文同时考虑对过滤器本身权重和该过滤器关联权重进行评估,如图1所示,定义一个过滤器
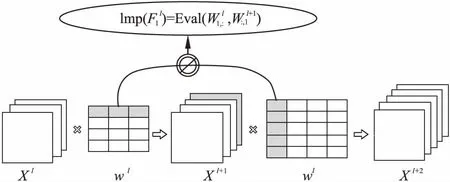
图1 基于权重关联性的过滤器评估Fig.1 Evaluation based on weight dependency for a filter
的重要性如公式(1)所示:
(1)
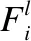
3.2 评估值计算
之前的许多模型剪枝方法都采用了“范数值假设”,即这些方法认为稀疏的权重向量范数值越小则越不重要[2,4].文献[2]采用局部剪枝的方法的同时,通过L1范数来定义一个过滤器的重要性,如公式(2)所示:
(2)

(3)

由于“范数值假设”中范数值的计算结果取决于权重值,然而每层的权重提取的特征不同导致权重值的分布不同,因此,该假设得到的评估值只能在层内进行比较,具有局部性.为了实现全局比较,本文将公式(3)得到的评估值进行全局标准化.经过分析和实验,本文提出通过“log”标准化方法实现全局可比较.本文对过滤器的评估值定义如公式(4)所示:
(4)

3.3 剪枝和微调
通过公式(4)获得整个模型的过滤器的重要性集合M={Imp1,Imp2,…,Impn}后,根据预设的模型剪枝比例P和公式(5)得到剪枝的阈值,对每层的过滤器进行筛选:
θ=sortP(M)
(5)
其中,θ为整个模型过滤器重要性的阈值,sortP(M)表示将M进行升序排序,并返回n×P位置的数值作为阈值,n为整个模型的过滤器数量,P为百分数.
针对较为复杂的模型,本文在剪枝具体流程上做出了一定的适应性改变.例如,在 DenseNet的“dense block”结构中,下一层的输入特征图为前面一些卷积层的输出特征图的集合[11].由于前面层过滤器产生的特征图不仅会输入到紧邻的下一层,还会作为输入到接下来的一些层,存在着过滤器的“复用”.因此,在“dense block”中无法直接剪掉一个过滤器.在对DenseNet进行压缩时,可以先将计算得到的过滤器本身的评估值看作特征图的评估值,然后随着特征图输入到不同的层,在不同的层中加上对应的关联权重的评估值,然后仍然按照上述方法将估值进行全局标准化,并以此来剪掉特征图,即是剪掉相应的关联权重.最后,通过本文提出的剪枝算法可以得到更加紧凑的网络模型.在进行较大比例的剪枝后,移除一部分的模型权重,对模型的精度可能会造成一些损失,可以通过对剪枝后的模型进行一定的微调,恢复模型的准确率.
本文提出的模型剪枝算法可以总结为以下3步:首先,通过所提出的算法计算得到模型所有过滤器的重要性;其次,对重要性进行排序,并通过指定模型的剪枝比例来移除重要性相对较小的过滤器权重;最后,对剪枝后的模型进行微调,恢复模型的精度.同时,可以选择性地将该算法从如上所述的一次剪枝扩展为迭代剪枝的方法,重复上述的剪枝流程对模型进行压缩.在扩展为迭代剪枝的方法后,可以将每次的模型的剪枝比例调低,重复对压缩后的模型进行剪枝,使得剪枝流程更加平滑,模型更加紧凑.
4 实验与分析
4.1 实验设定
为了验证该模型剪枝算法的效果,本文在常见的公共数据集CIFAR-10和CIFAR-100上进行了实验.这两个数据集中图片的大小为 32 × 32,CIFAR-10和CIFAR-100中分别含有10个和100个类别的图片.它们的训练集和测试集的数量分别为50000张和10000张.本文在一些常见的卷积神经网络模型上测试了压缩效果,包括:VGGNet[11]、ResNet[12]和DenseNet[13].特别地,本文在压缩ResNet时,采用了更为轻量化的“bottleneck”结构[12].
参考之前的一些相关研究,本文将算法的评价指标设置为剪枝微调后的模型的准确率,以及相对于原模型,参数量的降低比例和计算量的降低比例.
本文的模型训练都采用的随机梯度下降(SGD)的方式进行优化,批量训练数量(batch size)为64,设置训练160个epoch.学习率的初始值为0.1,在训练到50%和75%时,学习率的值会衰减到之前的1/10.权重衰减的值被设置为10-4,同时,动量系数被设置为0.9.
4.2 实验结果
本文在CIFAR-10和CIFAR-100上的各个模型压缩前后的测试结果如表1和表2所示,同时将实验结果与目前的一些主流剪枝方法进行了比较.参数量和计算量减少比例分别代表的是剪枝算法在减少参数量和计算量上的效果,比例越大,说明压缩和加速的效果越好,模型在推理时所消耗的空间和时间上的资源越少.
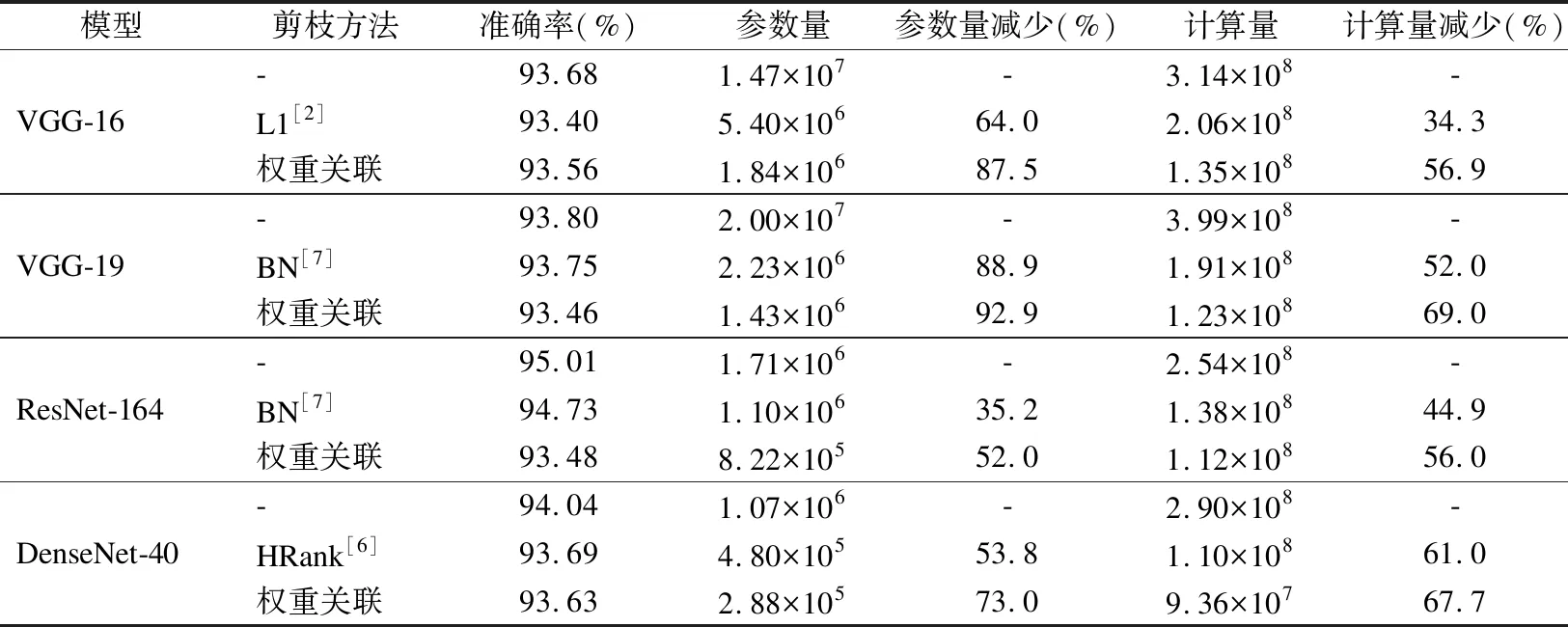
表1 在CIFAR-10上的测试结果Table 1 Test results on CIFAR-10

表2 在CIFAR-100上的测试结果Table 2 Test results on CIFAR-100
在实验过程中,通过设置不同的剪枝比例,在准确率损失可以接受的前提下,选择最大的剪枝比例.然后,多次实验计算出准确率的平均值.实验对VGG-16采用了50%或70%的剪枝率,对VGG-19采用了60%或80%的剪枝率,对ResNet-164采用了60%的剪枝率,以及对DenseNet-40采用了70%或80%的剪枝率.从实验结果中可以看出,经过本文所提出的剪枝算法,模型的参数量和计算量都得到了一定的减少,但最重要的是,模型的精度却没有受到影响.在CIFAR-10数据集上,特别是在进行了较大比例的剪枝后,VGG-16、VGG-19和DenseNet-40分别获得了8倍、14倍和4倍的压缩,而模型的精度却几乎没有损失,进一步的证明了原本模型的过度参数化,也验证了本文所提出的剪枝方法的有效性.同时,相比于目前的一些主流剪枝方法,本文所提出的方法更加的高效,压缩和加速的效果更加的好.
4.3 标准化方式选择
在全局剪枝算法中,不同的标准化的方式使得评估值在标准化后的值不同,这会使算法在剪枝时产生不同的效果.为了更好实现全局比较,本文提出对评估值进行“log”标准化.该标准化方式简单有效,将评估值进行了非线性的转换.将该标准化方式与常见的“max-min”标准化进行两组在CIFAR-100数据集上的实验对比,结果如表3所示,可以发现在对模型的压缩和加速效果几乎相同时,使用“log”标准化方式得到的紧凑模型的准确率要比使用“max-min”的更高.因此,使用“log”标准化方式能更加准确地将重要的过滤器权重保留,是一种相对高效的选择.

表3 使用不同标准化方式的测试结果Table 3 Test results of using different normalization
4.4 剪枝效果分析
在CIFAR-10数据集上训练的VGG-16在剪枝前后,模型的准确率分别为93.68%和93.56%,可以发现模型在剪枝后精度上几乎没有损失.值得注意的是,模型在剪枝过程中参数量减少了87.5%,计算量减少了56.9%,压缩和加速效果十分明显.如图2所示,模型剪枝前后卷积层各层的过滤器数量对比,可以看到剪枝操作主要发生在网络的第一层和最后几层,而中间层的参数在剪枝后有较大的保留,同时,模型在剪枝后被压缩了近8倍,而准确率仅降低了0.12%,模型精度几乎没有损失.因此,可以通过分析得到,模型的大部分的重要性较低的参数集中在模型较深的网络层.
同时,从图2中可以看出,模型剪枝之后,模型结构呈现的是两端窄,中间宽的特点,尤其最后几层保留的过滤器数量较少.这表明模型在该任务下,较为深层的网络结构存在着大量的冗余.因此在针对具体任务时,本文提出的剪枝方法也可以看作一种针对任务的最佳网络结构搜索方法,通过剪枝前后模型结构的对比,可以验证当前模型设定是否冗余,从而发现更为紧凑高效的网络结构.

图2 VGG-16中各卷积层过滤器数量剪枝前后对比Fig.2 Number of filters before and after pruning in VGG-16
4.5 剪枝比例分析
在对一个训练完成后的模型进行剪枝时,需要根据具体情况设定一个对于整个模型的剪枝比例.如果这个比例设置得过大,会使得一些相对重要的权重也被减去,模型精度的损失较大,并且可能微调后精度也不能被恢复.然而,如果这个比例设置得过小,会使得减掉的过滤器权重数量较少,剪枝效果不明显.本文通过DenseNet-40在CIFAR-10上进行实验来分析剪枝比例的设定,结果如图3所示.

图3 DenseNet-40在CIFAR-10上的剪枝比例分析Fig.3 Analysis of pruning ratio from DenseNet-40 trained on CIFAR-10
在图3中,横轴为模型的剪枝比例,纵轴为测试时的错误率.通过分析可以发现,当剪枝比例超过一定阈值后,剪枝后或者微调后的模型测试时的错误率会急剧上升.虽然微调能使得剪枝后的模型的性能得到一定恢复,但如果剪枝的比例设置在80%这个阈值以上,可以看出微调后模型在测试时的错误率超过正常训练后的错误率这条基准线,急剧上升.
5 总 结
目前,深度卷积神经网络模型应用广泛,但在推理时,其消耗的资源巨大.本文提出了一种基于权重的关联性的卷积神经网络模型剪枝方法,在评估一个过滤器的重要性时,将对过滤器的关联权重的评估考虑进去,避免了关联权重较为重要但却被移除所带来的损失.通过计算L1范数得到基于权重的关联性的过滤器评估值后,由于评估值具有局部性,无法实现全局比较.本文提出使用特定的标准化的方式对评估值进行处理,以此实现全局可比较.对多种模型进行实验,结果表明,所提出的剪枝方法可以有效地压缩和加速模型,并且模型推理时的准确率几乎没有损失.特别地,在CIFAR-10数据集上,剪枝后的VGG-19模型减少了92.9%的参数量和69%的计算量,模型的准确率只损失了0.34%.
同时,本文的所提出的方法不需要特殊的软硬件环境支持即可部署应用,该方法高效地实现了对模型的压缩和加速.下一步将研究模型剪枝与其他模型压缩方法的结合,比如知识蒸馏,量化等,进一步使得模型更加轻量化.
