基于图像识别和BP神经网络的灌溉模型的研究
2021-07-07邱意敏欣龙武鹏
邱意敏,欣龙,武鹏
(1.安徽工程大学 电气工程学院,安徽芜湖241000;2.安徽工程大学 检测技术与节能装置安徽省重点实验室,安徽芜湖241000)
1 引言
我国水资源总量位居全球第四,但由于人口众多,人均水资源量远低于世界平均水平。作为我国水资源利用的主要部分,作物灌溉用水不仅影响水资源的利用效率,还影响农作物的生长。如何用有限的水资源对农作物进行合理的灌溉已经成为我国农业发展进程中需要解决的主要问题。
目前,我国大多作物的灌溉仍采用人工灌溉,该方式浪费人力,只能对农作物进行粗略灌溉,且易造成水资源的大量浪费。近几年,很多学者利用回归分析法、公式计算法、区域水量平衡预测法[1]、灰度系统预测法[2]以及神经网络预测法[3]等建立了一系列的灌溉模型,以改善我国农作物灌溉的现状。但这些灌溉模型大多将土壤指标作为影响农作物生长的主要因素,很少将作物指标和气象指标考虑进去[4-5],易造成无论农作物病态与否均按照灌溉模型的灌溉量进行灌溉。此外,多数模型仅适合于室内温室作物的灌溉,很少有专门针对农田作物的灌溉模型。因此,研究与设计一个能够区分农作物生长状态的适用于农田作物灌溉的灌溉模型具有一定的现实意义。
2 总体设计
针对目前灌溉模型存在的问题,结合我国国情,设计了一个基于图像识别和BP神经网的灌溉模型。该模型以小麦为研究对象,利用图像识别技术对小麦是否处于病态进行判断,若不处于病态则根据CWSI指数判定是否进行浇灌,若需要进行浇灌则利用BP神经网络对小麦生长相关较大的五个因素进行训练,以得到小麦的灌溉量,具体流程如图1所示。
3 作物状态区分
3.1 病态区分
农作物的生长状态和众多因素相关,在这里通过拍摄农作物的图片[6]以提取作物指标,并利用图像识别和卷积神经网络实现对小麦病态与否的分类。
3.1.1 图像处理 小麦的病态分为变色型、坏死型、萎蔫型、畸形型等。将事先采集的1200张小麦处于正常态和不同病态的图片进行图像处理,包括灰度化、消除噪声和图像增强等。图2和图3分别为正常型小麦和变色型小麦的图像处理结果。
3.1.2 数据集制作 将处理后的图像经过随机旋转90°、180°、270°来增大样本的数量,并统一裁剪成100×100的小图像,利用如图4所示的卷积神经网络结构完成样本的训练,得到小麦图像的数据集。
3.1.3 图像识别 将采集的小麦图片进行预处理,再进行区域定位和特征提取,最后将提取的特征与之前得到的图像数据库进行比较,判断小麦处于正常型、变色型、坏死型、萎蔫型和畸形型中的哪种状态,即可区分小麦是否病态。
3.2 灌溉状态区分
只要小麦不处于病态,就需对它的灌溉状态进行判断,即是否需要灌溉。由于农业生态环境具有多样性,且需要水分的是小麦,故利用作物指标来监测小麦水分的状况比监测土壤水分可靠性更高[7]。作物指标包括叶指标、茎指标、冠层温度和作物群体反射率等[8]。由于农作物的冠层温度对水分胁迫相对比较敏感,且利用红外遥感检测技术即可完成对作物冠层温度的监测,故这里通过监测小麦的冠层温度来判定小麦是否需要灌溉。
若仅通过设置小麦冠层温度的阈值来判断其是否需要灌溉,易受时间和空间影响,且阈值的设定较为困难。CWSI指数[9]以热平衡原理为基础,利用农作物的冠层温度和冠气温差上、下限来衡量其水分多少,估算精度较高,适用于农田灌溉。
首先,分别检测喷水的小麦叶面和涂凡士林的小麦叶面的冠层温度,以确定冠层温度的上限和下限;再检测当前小麦冠层温度与空气温度;最后,将数据代入至式(1)计算CWSI数值。
(1)
其中,Tl是当前小麦冠层温度与空气温度的差值;Tmax和Tmin是小麦冠层温度与空气温度差值的上限和下限。由于空气温度可以相互抵消,式(1)可以化简成式(2)的形式。
(2)
其中,Ta是当前小麦冠层温度;THigh和TLow是小麦冠层温度的上限和下限。
CWSI值在0到1之间,CWSI的值越大,表示植物越缺水。据文献统计[10],小麦高产条件下的CWSI阈值为0.26,故一旦检测到CWSI的值高于0.26时,则需对小麦进行灌溉。但由于不同地区地理、气候和环境各不相同,该值存在些许差异,可以根据具体情况进行适量的调整。
4 灌溉量的确定
4.1 影响农作物灌溉量的因素
根据水平衡公式(3),可知农作物各生育期的灌溉量Mi与农作物蒸腾量ETi、土壤贮水变化量ΔSi、地下水利用量WGi与降水量Pi有关。
Mi=ETi+ΔSi+WGi-Pi(3)
(3)
其中,降水量可以根据天气预报直接得到相对精确的值,土壤贮水变化量[11]可以根据时段初末土壤含水率差值乘以计划湿润层深和土壤孔隙率算出相对精确的值。而地下水位深度大于3米时,可将其视为0。由此可见,若知道农作物的蒸腾量,只需加减土壤贮水量和降水量即可得到农作物的灌溉量。
而农作物的蒸腾量是一个动态变化的值,常见的影响农作物蒸腾量的因素分为土壤指标、作物指标和气象指标[12]。其中,土壤指标是土壤含水量;作物指标是作物自身生理变化指标,包括叶指标、茎指标、生育期等;气象指标是作物生长环境的气象指标,包括环境温度、空气湿度、净太阳辐射等。为了使农作物的蒸腾量不单独与某类指标相关,这里分别选取三大指标中对农作物需水量影响最大的5个因素,即环境温度、空气湿度、净太阳辐射、土壤含水量以及作物种植天数作为确定灌溉量的参考因素。
4.2 构建灌溉量模型
由于小麦灌溉量和影响小麦灌溉量的因素之间的关系较为复杂,难以通过搭建线性系统的模型来建立相应的映射关系。人工神经网络具有很强的非线性拟合能力[13-14],且自学能力、自适应力和鲁棒性很强,能够实现较为复杂的非线性映射的功能。而BP神经网络作为人工神经网络的重要组成部分,主要是通过利用误差信息更新参数,经过多次迭代得到最优化参数集合,以实现处理信息的同时不断自主学习的功能。
4.2.1 BP神经网络模型的构建 文章构建的灌溉量模型的输入有5个,输出有1个,具体的结构如图5所示。
4.2.2 数据的获取与预处理 据上所述,需将环境温度、空气湿度、净太阳辐射、土壤含水量以及作物种植天数作为BP神经网络的输入,灌溉量作为BP神经网络的输出。通过中国气象数据网下载安徽省地面累年值日值数据集、中国气候辐射国际交换站基本要素日值数据集和安徽省中国农作物生长发育的农田土壤湿度旬值数据集获取相应的环境温度、空气湿度、净太阳辐射和土壤含水量(取20 cm土壤相对湿度),而作物种植天数以作物播种时间作为起始时间计算。灌溉量则是用作物的蒸腾量加上土壤贮水量变化量再减去降水量作为终值,其中土壤贮水量变化量和降水量可以采用上述数据集中的数据,而作物蒸腾量可以利用上述数据集中的数据通过Hargreaves-Samani[15]公式(4)计算获取。
ET0=0.0023·Ra(T+17.8)ΔT0.5
(4)
其中,T为平均气温,ΔT为气温差值,Ra为大气顶太阳辐射。
考虑到数据的完整性和时间连续性,将上述三个数据集中的数据进行预处理,主要包括剔除由于人为和设备原因缺失的数据、相同时间点的数据整合、相近或同一站点的数据整合和数据单位的统一等。值得一提的是由于农田土壤湿度是按照旬值进行采集的,这里取与当前日期最近的日期所采集土壤湿度值作为当前的土壤湿度值。
4.2.3 BP神经网络的训练 经过预处理后,得到300组样本数据,将它们随机分成三个部分,其中240组作为训练集,30组作为验证集,其余30组作为测试集,部分样本数据如表1所示。对数据进行归一化处理,设定网络训练的最大次数为1000次,设定网络的学习速率为0.05,训练目标最小误差为0.001,并选取Levenberg-Marquardt算法对BP神经网络进行训练。
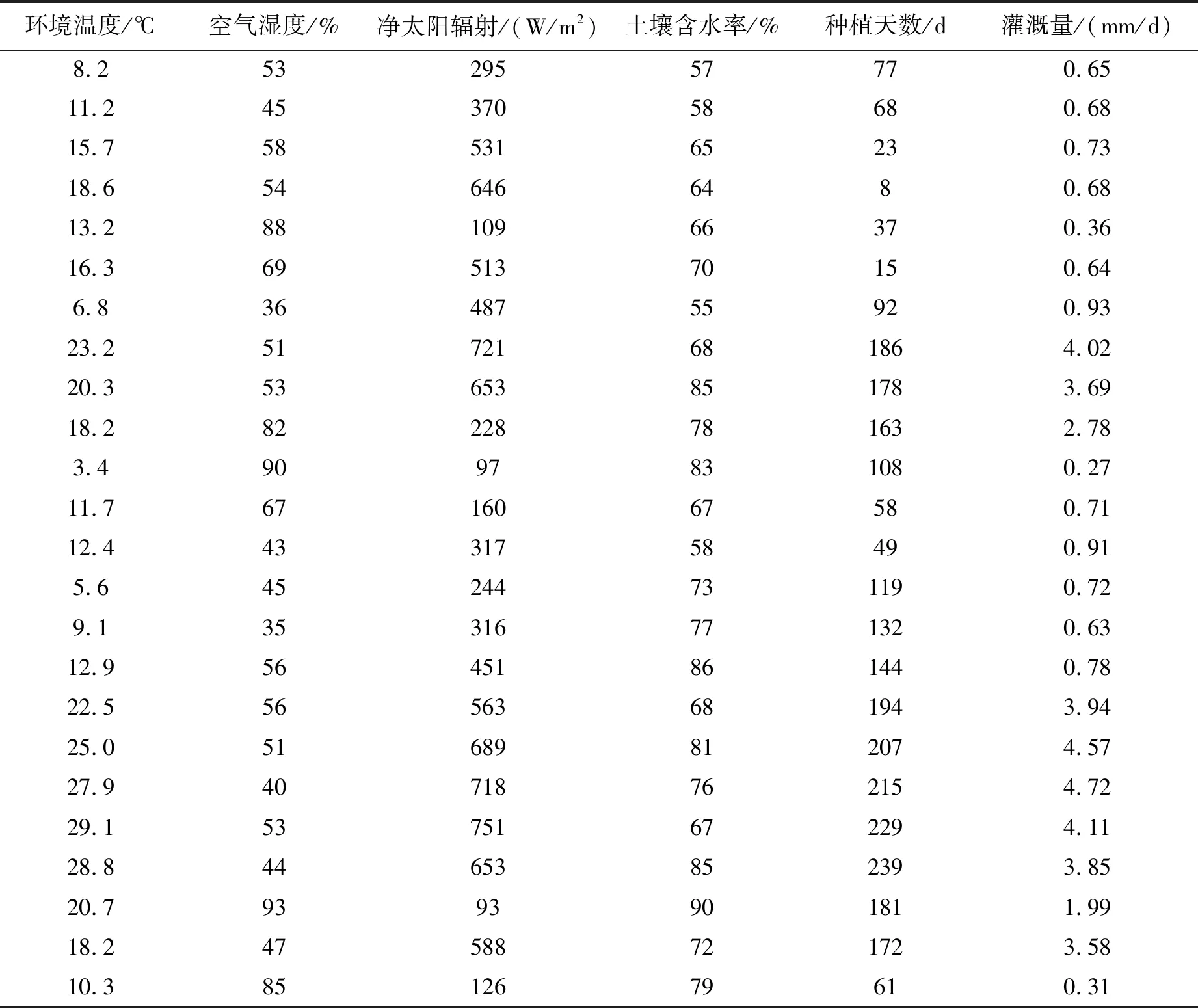
表1 小麦灌溉量部分样本数据
4.2.4 仿真结果分析 BP神经网络训练的仿真结果如图6和图7所示。
从图6和图7中可以看出,BP神经网络的权值更新8次后能达到性能最优,验证集的均方误差仅有0.024193,与此同时,训练集、验证集、测试集和整个样本数据集的回归系数均十分逼近1。综上可知,构建的小麦灌溉量模型的指标选取较为合理,预测的灌溉量数值符合小麦生长规律的需要,能够实现对小麦的合理灌溉。
5 结论
文章以小麦灌溉模型作为研究对象,首先利用图像识别技术判断小麦是否处于病态,再利用CWSI指数判断非病态小麦是否需要进行灌溉,最后结合影响小麦生长的关键因素和BP神经网络构建了灌溉量模型。仿真结果表明,该文构建的小麦灌溉量模型具有一定的准确性,能够满足小麦不同生育期的灌溉需要,对提高灌溉用水的利用率有一定的帮助。
