动车组数据资源目录
2021-07-06李静雪
李静雪
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
为支撑动车组相关业务,中国国家铁路集团有限公司(简称:国铁集团)已建成多个动车组相关信息管理系统。这些系统中的动车组数据在含义结构、存储组织和维护管理等方面都存在差异,增加了系统间信息交换与共享的难度,不利于业务部门便捷地利用已有信息资源开展动车相关业务。
因此,确定动车组信息资源的信息语义、数据范围和数据规范,采用信息类、数据元等概念对动车组信息资源进行规范化描述,对目前分散在多个系统中的动车组信息资源进行整理、归类和建档,建立统一、规范的数据目录,形成系统间、部门间有序开放的动车组主数据共享模式,方便业务部门发现、定位和共享多源异构的动车组信息资源的需求已迫在眉睫。
1 现有动车组数据资源业务域划分
数据资源的分类是根据数据内容的属性或特征,遵循科学性、系统性、可扩展性、实用性等原则,将数据按照一定的原则和方法进行区分和归类,这对于数据资源共享有着极其重要的作用[1]。根据动车组实际业务与数据来源情况,动车组数据资源以业务主题为主、数据类型和来源为辅进行数据分类,按业务域进行规划。
目前,动车组信息资源主要来源于动车组管理信息系统(EMIS)、动车组轨旁声学早期故障监测系统(TADS)、动车组运行故障动态图像检测系统(TEDS)、动车组车载信息无线传输系统(WTDS),后续将根据实际业务需求继续扩充数据来源。
EMIS 的数据可划分为基础字典、履历信息、配属信息、开行实绩、检修作业记录等[2-3],详情如表1 所示。

表1 EMIS 业务数据分类
动车组TADS 的数据划分为基础字典、轴承故障和过车管理记录;动车组TEDS 的数据划分为探测站报文、报警处置和人工报警信息;动车组WTDS数据划分为GPS 信息、故障信息、运行信息等。
与国铁集团主管处室、铁路局集团公司、主机厂、设备厂家等相关各方充分沟通后,对这些系统的业务数据与实际应用进行分析与梳理,确定了动车组数据业务域划分及对应数据分类,如表2 所示。
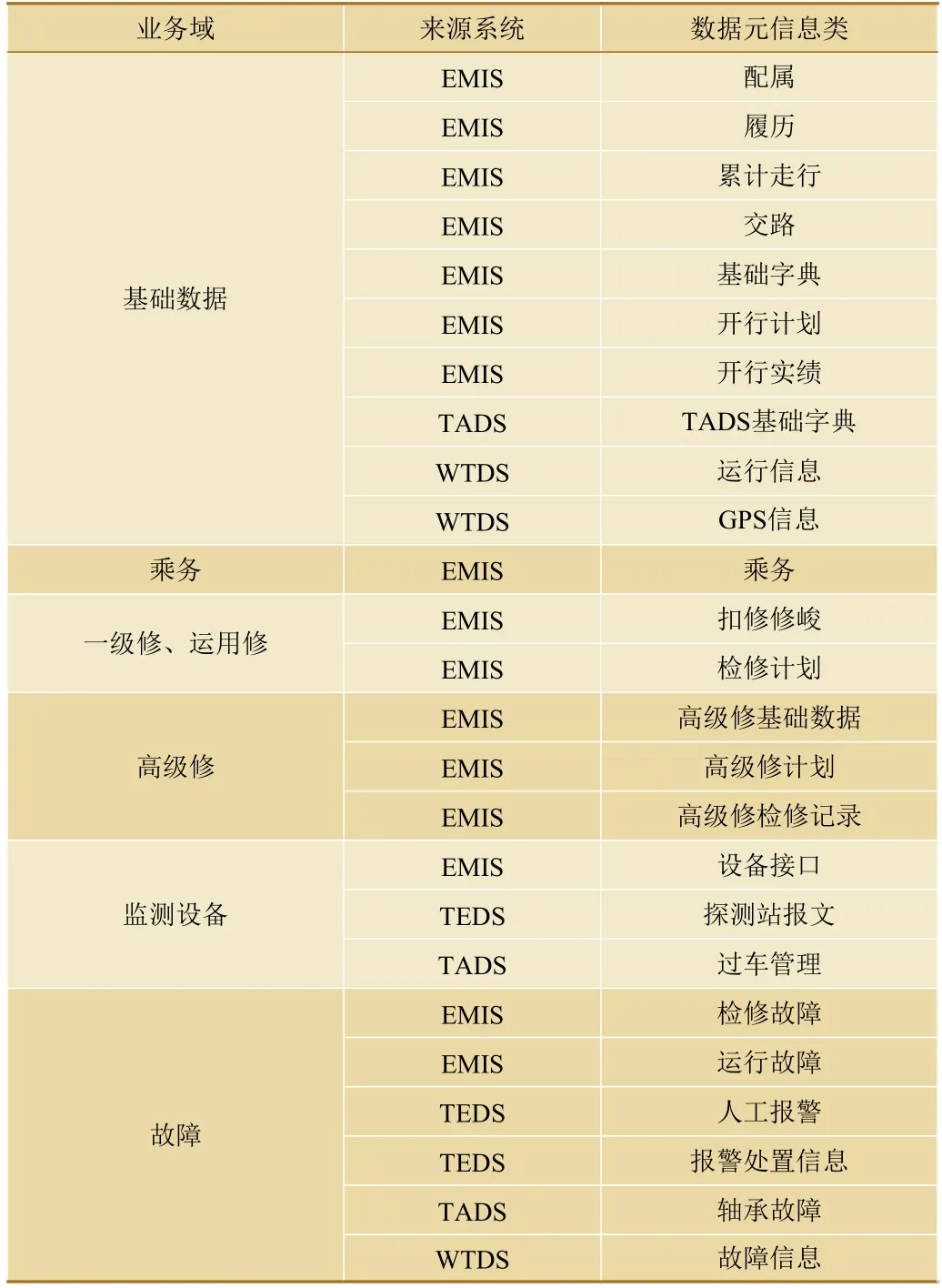
表2 动车组数据业务域划分及对应数据分类
2 数据规范
由于实际意义相同的数据项在不同系统中存在不同描述,或相同描述的数据项在不同系统中对应不同实际意义,为了让用户快速、便捷地获取《动车组数据资源目录》所包含的数据项,了解这些数据项的含义、内容、结构,必须制定统一的数据规范[4]。
2.1 数据元定义
数据元是通过定义、标识、表示以及允许值等一系列属性描述的数据单元[5],是特定的语义环境中不可再分的最小数据单元。业务部门可以通过查询数据元来了解数据项的数据格式、取值范围、编码方式等数据属性。在《动车组数据资源目录》中,数据元是每个系统中的最小字段,按定义明确、存储无冗余的原则进行采集。
根据实际使用需要,《动车组数据资源目录》的数据元结构描述如下。
(1)数据元编码:数据元的唯一标识,由组织机构、系统代码、数据表类型代码、数据表代码和数据元数据代码组成。
(2)数据元名称:数据元的中文名称。
(3)数据元描述:描述数据元含义的说明。
(4)数据类型及长度:数据元的数据值的类型及字符长度的表示格式。
(5)值域:数据元的取值范围(含义清楚、无须说明的可省略;若使用代码集,则需指明相应的代码集)。
2.2 代码集定义
代码集是编码对象集和代码元素集的映射关系表[6]。对于以代码集形式表示值域的数据元,可通过查询代码集确定其具体取值范围。
在动车组相关信息系统中,铁路局、探测站、车组状态、检修修程等数据字典一般有约定俗成或由公文明确规定的取值,其对应数据元的值域为代码集。代码集描述如下:
(1)代码集编码:代码集唯一编码,由系统来源代码和顺序码组成。
(2)对应的数据元编码:代码集对应的数据元编码。
(3)对应的数据元名称:代码集对应的数据元名称。
(4)编码方式:代码集的编码规则。
(5)代码表:用表格形式描述代码及代码含义的对应关系,包含代码、名称、及含义说明。
3 数据采集
目前,EMIS 系统、TADS 系统和TEDS 系统的结构化数据存储在关系型数据库中,而WTDS 系统的非结构化数据存储在非关系型数据库中,两种不同存储模式的数据分别使用不同的数据采集方式。
3.1 结构化数据采集
存储在关系型数据库中的结构化数据具有明确的数据项及数值范围,可分业务域梳理相关数据表,按如下步骤进行清洗与采集:
(1)明确业务域中包含的所有数据表范围,将范围内所有表进行筛选,剔除不需要的表(如临时备份表、不再使用的表、操作日志表等),最终保留的数据表能描述出完整业务且无冗余;
(2)明确各数据表中字段含义及数据使用与维护情况,将未使用、不需要、不再维护的字段剔除,这些字段不纳入《动车组数据资源目录》中,且后续无需进行数据清洗;
(3)明确数据表中每一字段的定义,包括字段名称、数据类型、数据长度、默认值、数据含义,不同表中相同字段尽量统一(不同表中,相同含义和取值的字段,如果字段名称不同,则明确标识),并明确数据表主外键、索引、分区情况;
(4)明确字段编码规则和取值范围,如枚举型字段需列出每个取值对应的含义,字段取值有明文规定的需列出所参考的公文;
(5)明确表中数据的质量,对于数据质量不佳或需要清洗的表,列出需清洗的字段、清洗规则及处理结果,规则描述应完整、准确、清晰。
3.2 非结构化数据采集
WTDS 系统的非结构化数据不规则[7],不适于采用关系型数据库二维表来存储,需根据实际数据情况对WTDS 数据进行元数据结构的分析与重构。
WTDS 系统的数据分为实时数据和非实时数据2 类,这2 类数据具有相同的元数据结构,在数据资源目录中可使用同一数据元。
同时,按数据业务及Kafka 传输的数据类型分类,WTDS 系统的数据可分为当前故障、历史故障、列车运行信息、GPS 数据、车辆信息5 类;其中,车辆信息暂未使用,故只将其余4 类数据纳入数据资源目录:
(1)故障数据包括当前故障和历史故障,两者的元数据完全一致,可按相同方式进行整理;故障数据的元数据描述如表3 所示。

表3 WTDS 故障数据的元数据描述
故障数据中,每一种故障代码都对应一种具体故障类型,虽然具体故障种类很多,但各类故障字典的数据结构是一致的,整理后的故障数据的元数据描述如表4 所示。

表4 整理后的故障数据的元数据描述
(2)通过GPS 原始结构和实际数据可知,无论任何车型或车辆,其GPS 数据均包括时间、速度、经度、经度方向、纬度、纬度方向等数据项,GPS数据的元数据描述如表5 所示。
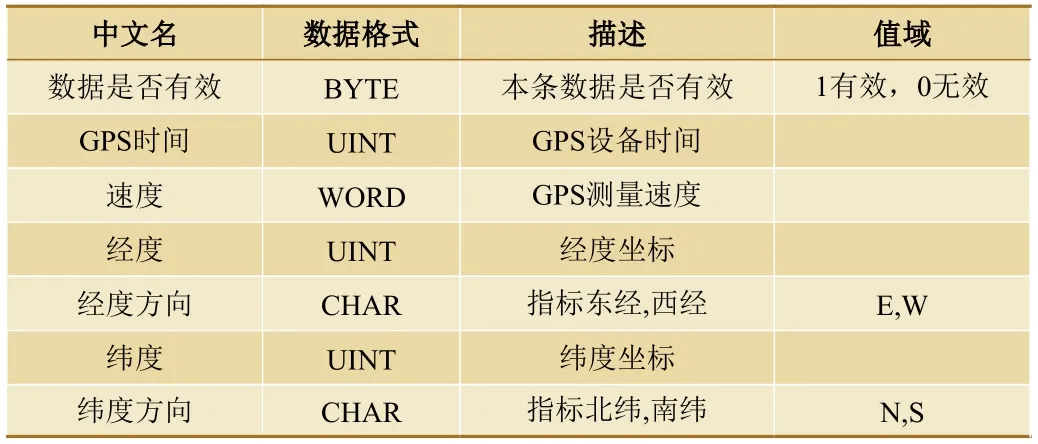
表5 整理后的GPS 数据的元数据描述
列车运行信息中包括车代码/单元代码、模块代码和模块值3 部分;其中,模块代码对应不同车型的参数协议[8],参数协议中每一个数据项均代表一项实际动车组或配件参数,可为参数协议中每一个数据项单独定义元数据。WTDS 系统的参数协议按动车组和辆序分组,可将车型和车辆信息保留在数据元的描述中。列车运行信息中的数据项是通过截取字符串获取的,不能确定其中数据项的具体类型和长度。
4 资源目录的整合
在充分调研动车组相关信息系统的业务场景、数据内容、数据结构、数据元的基础上,按数据业务域对现有数据进行业务和数据盘点,借鉴其它行业先进的数据管理模式,构建《动车组数据资源目录》。
以基础数据中的基础字典为例,基础字典包含路局字典、单位字典、车型字典等,通过数据清洗与合并,保留最少的公共基础字典;按照数据元描述规范,基础字典数据元描述如下:
AA001-B0001-0001 路局编码
描述:路局编码
数据格式:CHAR(1)
值域:参见代码集:路局代码集
AA001-B0001-0002 动车组型号及车组号
描述:动车组型号及车组号,详见铁总运【2017】99 号 中国铁路总公司关于印发《动车组型号车组号、车种车辆号和席位号编制规则》的通知
数据格式:VARCHAR2(20)
值域:无
AA001-B0001-0003 路局简称
描述:路局简称,一个汉字
数据格式:VARCHAR2(10)
值域:参见代码集:路局代码集
AA001-B0001-0004 单位编码
描述:单位编码,包括段级单位、所级单位、主机厂级单位和高级修级单位
数据格式:VARCHAR2(10)
值域:参见代码集:单位代码集
AA001-B0001-0005 单位名称
描述:单位名称,包括段级单位、所级单位、主机厂级单位和高级修级单位
数据格式:VARCHAR2(100)
值域:参见代码集:单位代码集
其中,动车组型号数据元有公文明确规定,其数据元描述中包含公文名;现有路局代码集作为路局数据元的值域。
5 结束语
目前,《动车组数据资源目录》已用于支持国铁集团与主机厂的造修数据贯通,对动车组履历填报规范、自动化设备接口技术条件等技术标准的修订也起到指导作用。
今后,《动车组数据资源目录》的修订与版本更新将成为一项周期性工作,及时将动车组相关信息系统的新增数据纳入资源目录中,促进动车组数据资源的有序增长和充分利用。
