基于二次分解和深度学习的PM2.5 集成预测方法
2021-07-05周尧民黄恒君
周尧民,黄恒君
(兰州财经大学统计学院,甘肃兰州730020)
一、引言
改革开放以来,我国的工业、交通和服务业等发展迅速,其发展水平、实力和规模均达到世界先进水平,人们的生活水平不断提高,物质需求得到极大的满足。随着工业发展和城市开发,能源消耗急剧增加,化石燃料、汽车尾气等排放到大气中,大气环境受到严重污染,雾霾天气频发,且从局部污染向区域性污染扩散。大气污染已经成为制约经济发展的重要因素之一,影响了人们的正常生活以及社会的安定(漆威,2015;宋凯艺和卞元超,2019)[1,2]。
近十年来,PM2.5(可吸入颗粒物,即大气中直径小于或等于2.5 微米的颗粒物)一直是我国大部分地区环境的首要污染物,其在大气中的含量虽然很少,但对空气质量和能见度的影响很大(解垩,2011)[3]。更重要的是,PM2.5直径小,成分复杂,含大量的有毒、有害物质,且包含多种细小颗粒物。细小颗粒物进入人体后会附着在呼吸道及肺叶上,对人体的一系列系统产生危害,而有害气体、重金属等会溶解于血液中,对人体健康的伤害更大(张义和王爱君,2020)[4]。PM2.5可以在大气中长时间停留,长期高水平的PM2.5浓度会对生态环境、公共健康及社会经济构成严重威胁(薛涛等,2020)[5]。全球疾病负担研究中心(GBD)发布的报告显示,2015 年全球约有400万人因PM2.5污染而过早死亡,而我国就有100 多万人,远高于欧洲和北美地区(Wang et al.,2020)[6]。PM2.5污染不仅会对健康造成直接损害,而且会增加健康支出,带来经济损失。因此,PM2.5污染已经引起研究者的广泛关注(康晓明等,2015)[7]。
准确预测PM2.5浓度的变化,从数据的角度来讲,就是实时提供未来某时段PM2.5浓度的相关信息,使人们及时采取防护措施,从而在一定程度上降低大气污染对人体的危害。基于此,本文利用“分解—聚类—集成”的学习范式,提取时间序列的各部分特征和长期趋势,构建先分解、再聚类、后集成的预测模型,并以北京市日均PM2.5浓度序列进行实际预测研究。本文首先利用自适应加噪声完备集成经验模态分解(CEEMDAN)将原始序列进行分解,并依据各分量的正则化长短时记忆神经网络(ELSTM)模型的预测效果,将预测效果不好的高频分量利用变分模态分解(VMD)进行二次分解,然后运用基于形状的时间序列聚类(K-shape)算法将子序列进行聚类,将聚类结果作为预测模块的输入,并对各个预测结果进行集成得到最终值。本文构建的CEEMDANVMD-K-ELSTM 二次分解组合模型,可以提高模型的预测精度。
通过对城市空气污染的研究文献进行梳理可以发现,PM2.5浓度预测属于时间序列研究的一类问题,而时间序列预测问题一直受到众多学者的关注,其采用的预测方法主要有经典统计模型、支持向量机模型、神经网络模型等。经典统计模型侧重于线性回归。Sun 等(2013)[8]为应对某些关键气象因素以及PM2.5浓度在先验中所呈现出的非高斯分布,采用服从对数正态分布、Gamma 分布和广义极值分布(GeV)的隐马尔科夫模型,较为准确地预测了北加州某地的PM2.5浓度超限天数,有效地减少了虚假警示。龚明等(2016)[9]建立了灰色马尔科夫链模型,并在此基础上对残差进行修正,融合了灰色模型和马尔科夫模型的优点,提高了预测精度以及预测值与实际值的吻合度。沈劲等(2020)[10]采用气象因子聚类和多元回归方法,基于广东省的空气质量数据建立了统计预报模型,发现该模型能够较好地模拟NO2、SO2、CO、PM10、PM2.5的日均浓度水平和变化趋势。但这类方法容易受到各种空气污染物浓度变化的影响,而且确切掌握其变化有着较大的难度,其预测精度往往有限。因此,经典统计模型难以适应时间序列内含的非平稳、含噪声等特点,在预测中得不到较为准确的结果。
由于经典统计模型存在局限性,更多的学者开始采用时间序列法对PM2.5浓度进行预测。自回归移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)在时间序列的线性特征提取方面表现较好,Jian Le 等(2012)[11]利用 ARIMA 分析了气压、风速、温度和相对湿度在细微颗粒物浓度预测中的显著影响作用。但这类模型在非线性特征的提取上表现不佳,时间序列的复杂性和非线性使其不能达到令人满意的效果。为了解决以上问题,研究者开始采用机器学习方法进行研究。其中,支持向量机(Support Vector Machine,SVM)在小样本、非线性及高维模式识别中具有独特优势。Sun 等(2017)[12]利用主成分分析和最小二乘支持向量机的混合模型对PM2.5浓度进行了短期预测。李龙(2014)[13]则使用最小二乘SVM 模型结合气象因素和污染物浓度特征预测PM2.5浓度,其与传统的SVM 模型相比具有更好的预测精度和泛化能力。Zhou 等(2019)[14]将多任务算法(Multi-task Learning,MTL)与多输入支持向量机(Multi-output Support Vector Machine,M-SVM)相结合,利用MTL 对M-SVM 模型进行训练,以优化模型参数提取非线性特征,并利用台北市多个检测站点的PM2.5浓度进行了多步预测,以验证模型的有效性。但是,PM2.5这类时间序列的样本量往往很大,SVM 在处理较大的数据集时存在计算量大、处理时间长等问题。因此,部分学者利用神经网络配合其他算法处理较大规模的数据并进行海量数据计算,取得了长足的进步。在PM2.5浓度预测领域,石峰等(2017)[15]建立了基于灰狼群智能最优化算法的神经网络预测模型,从非机理模型的角度结合气象因素和空气污染物对上海市的PM2.5浓度进行了预测,其模型精度优于BP 神经网络模型和支持向量回归(Support Vector Regression,SVR)模型。周杉杉等(2018)[16]提出基于互信息最大相关和最小冗余准则并结合粒子群优化算法的混合特征选择算法,利用递归模糊神经网络以最少的特征获得最小的预测误差,说明该方法适用于PM2.5浓度预测。
为了充分利用不同模型的优势,一些学者开始研究组合模型预测方法。Wang 等(2015)[17]利用泰勒展开修正模型误差项将神经网络与支持向量机相结合,预测了太原市的SO2和PM10浓度。机器学习在时间序列预测中的运用本质上是对序列特征的监督学习,只有最大限度地学习序列的时间窗特征,才能更好地提高机器学习类方法的预测效果,而这是一般的机器学习模型难以做到的。在深度学习中,长短期记忆神经网络(Long Short-Term Memory,LSTM)在空气质量预测中的应用可以克服上述问题。Huang 等(2018)[18]将卷积神经网络(Convolutional Neural Networks,CNN)模型与 LSTM 模型相互融合,利用CNN 提取过去24 小时PM2.5浓度、风力等信息,并将其序列输入到LSTM 预测网络中,其预测误差小于 SVR、随机森林(Random Forest,RF)等传统模型以及单独使用CNN 或LSTM 进行预测的误差。白盛楠等(2019)[19]采用灰色关联度分析方法对多个气象、大气污染指标进行了关联度分析,并通过搭建多变量的LSTM 循环神经网络PM2.5预测模型,实现了PM2.5日值浓度的准确预测。蒋洪迅等(2021)[20]构建了一种集成双向长短期记忆网络的神经网络预测模 型 DLENN (Double -LSTM Ensemble Neural Network),以内含的两个方向LSTM 分别刻画PM2.5浓度变化的趋势性和周期性,并利用线性回归复合神经网络捕捉PM2.5浓度变化的随机性,其结果证明了DLENN 预测模型稳定优于其他集成模型。
鉴于结合机器学习方法建立的组合预测模型存在非平稳数据学习能力不足以及优化过程容易过拟合等问题,一些学者提出了“分解—集成”的研究框架,将信号分解方法用于时间序列分析。Xiong 等(2019)[21]开展的时间序列预测工作就是从信号分解出发,有效降低了时间序列的非线性和非平稳性。黄恒君和王伟科(2020)[22]将多模态分解与深度学习相结合,并利用多视角学习,提高了模型的预测精度。蒋峰等(2021)[23]利用变分模态分解(Variational Mode Decomposition,VMD)对 PM2.5浓度序列进行分解并引入样本熵对其进行重构,采用改进的探路者算法优化极限学习机(Extreme Learning Machine,ELM),最后利用极限学习机对每个重构子序列进行预测和集成,其预测的精度和稳健性均有显著的提升。为了更好地改进预测效果,部分学者提出以二次分解的方式进一步提取数据特征。Wang 等(2017)[24]研究了二次分解结构,将经验模态分解(Empirical Mode Decomposition,EMD)所产生的分解信号利用小波分解(Wavelet Packet Decomposition,WPD)进一步分解获得最终的子序列。基于此,本文在空气污染研究中也采用二次分解结构,以提高PM2.5浓度序列预测精度,并利用自适应加噪声的完备集成经验模态分解(CEEMDAN),改进集成经验模态分解(EEMD)所缺失的完备性。
二、理论模型设计
虽然已有学者将二次分解技术运用到时间序列预测中,并取得了一定的效果,但二次分解方法运算时间过长以及运算效率低等问题仍比较突出。因此,本文将二次分解与聚类相结合,合理减少子序列的数量并将其作为LSTM 神经网络的输入,建立了多模态集成预测模型。首先,本文对数据进行预先处理,运用三次样条插值法填补缺失值,并将无监督序列转化为有监督序列,以配合LSTM 模型的输入。其次,本文采用CEEMDAN 方法将原序列进行分解,以避免模态混叠现象,改进EEMD 对信号分解的不完整性,并进一步将高频信号利用VMD 进行分解,以提取复杂分信号的潜在特征。再次,本文利用基于形状相似度的时间序列聚类算法(K-shape)对分信号进行聚类,用以区分所有成分之间的差异,并依据它们的特性将数据划分为K 类。具体而言,各分信号和残差成分的预测值可以分成不同的类别,每个类别中的序列具有相似的特征。第四,本文将LSTM 神经网络加入正则化项,在规避递归神经网络梯度爆炸问题的同时,提高模型的稳定性及泛化能力。第五,本文采用“分解—聚类—集成”框架作为组合模型的运行机制,以更好地适应时间序列非平稳、高波动、含噪声的特点。具体而言,为了改善PM2.5浓度序列的预测精度,本文在“分解—聚类—集成”的研究范式下,从信号分解、信号预测以及对结果进行集成等方面对已有模型进行优化和改进,构建了CEEMDAN-VMD-K-ELSTM 二次分解组合模型。模型的基本流程如图1 所示。
在图1 的框架中,本文采用如下方法构建二次分解集成预测模型,即CEEMDAN-VMD-KELSTM:(1)利用自适应白噪声的完备集成经验模态分解(CEEMDAN),对PM2.5的原序列进行信号分解;(2)将高频信号通过变分模态分解(VMD)进行二次分解,进一步提取数据序列中的非线性和非平稳性特征;(3)运用基于形状相似度的时间序列聚类算法(K-shape)将二次分解后的分信号进行聚类,以减少预测模块的计算量及运行时间;(4)将聚类结果作为预测模块的输入,通过弹性正则化长短时神经网络(ELSTM)输出各分信号的预测值;(5)对各分信号预测结果进行集成,取其重复10 次的结果做平均,将其最终结果与基准模型进行比较分析,从而降低模型评价结果的随机性。
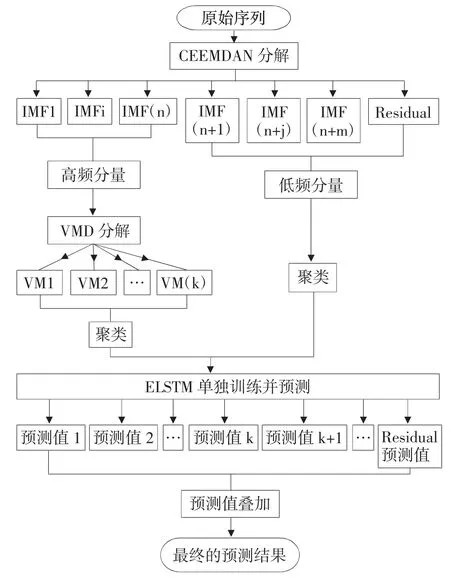
图1 CEEMDAN-VMD-K-ELSTM 模型流程
(一)集成经验模态分解(EEMD)
集成经验模态分解(EEMD)来源于经验模态分解(EMD),而EMD 是一种提取信号中非线性和非平稳特征的技术,其本质是将信号分解为具有不同频率的本征模态分量(IMF)(陈仁祥等,2012)[25]。但分解过程中出现的跳跃式变化,会使EMD 的分解结果产生模态混叠现象,即一个IMF 中包含差异极大的特征时间尺度,或者相近的特征时间尺度分布在不同的IMF 中,出现相邻两个IMF 波形混叠难以分辨,从而使分解结果失去实际意义(张袁元等,2016)[26]。EEMD则可以有效改善EMD 所产生的模态混叠,其步骤可以简述为:(1)s(t)为原始信号序列,vi(t)代表第i 次实验中添加的白噪声序列,其分布为标准正态分布,第i 次的信号序列可以表示为Si(t)=s(t)+vi(t),其中,i=1,…,i 代表实验的次数;(2)将分信号序列 si(t)利用EMD 进行分解,得到其中,k=1,…,K代表分解的模态个数;(3)s(t)的k 个模态分量为IMFk,对进行平均可以得到
(二)自适应完备集成经验模态分解(CEEMDAN)
EEMD 所添加的白噪声序列会对原始信号产生一定程度的破坏并有残余,而且求均值过程的处理较为复杂。针对以上问题,Torres 等(2011)[27]提出自适应加噪声的完备经验模态分解(CEEMDAN),即引入自适应高斯白噪声这一概念,通过在每个阶段添加有限次的自适应白噪声,实现在较少的平均次数下,其重构误差接近于0。CEEMDAN 可以有效避免模态混叠问题的出现,并弥补EEMD 分解不完整的缺点,解决EEMD 计算效率低的问题(李峰等,2016)[28]。本文归纳出CEEMDAN 的算法步骤。
第一,利用EEMD 算法分解得到第一个模态分量:

第二,在第一阶段(k=1)计算第一个余量:

第三,分解R1[n]+ε1E1(ωi[n])(i=1,…,I)到第一个模态分量,则第二个模态分量可以表示为:
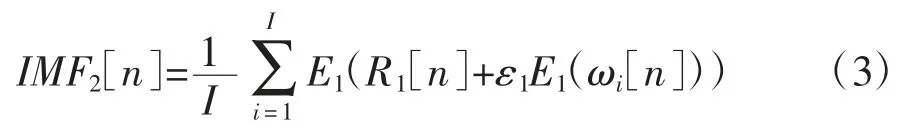
第四,对于k=2,…,K,我们计算第k 个余量:
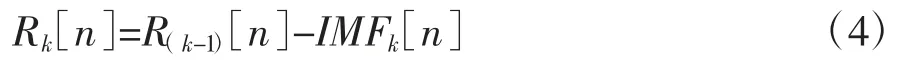
第五,分解Rk[n]+εkEk(ωi[n])(i=1,…,I)到第k个模态分量上,则第k+1 个模态分量可以表示为:
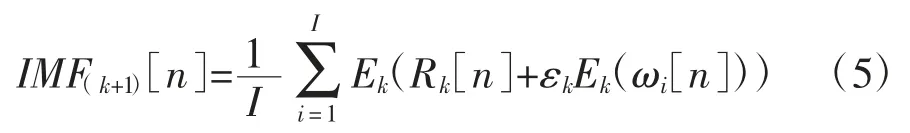
第六,重复第四和第五步,直到残差分量不适合被分解时停止分解。最终的余量满足:R[n]=X[n]-其中,K 表示分解得到的固有模态函数的数量,参数X[n]表示为
(三)变分模态分解(VMD)
变分模态分解(VMD)是Dragomiretskiy 和Zosso在2014 年提出的,它是一种新的混沌数据处理技术。VMD 分解是将信号分解为K 个本征模态函数(IMF),通过寻找一系列模态及各模态的中心频率,重构原始数据。VMD 分解的目的是使K 个本征模态函数的带宽之和达到最小,进而利用L2范数的平方最小达到上述要求。因此,分信号的瞬时频谱具有一定的现实物理意义,其具体步骤分为两步。
首先,构造变分问题。假设原始信号f 被分解为k 个分量,为保证分解序列为具有中心频率的有限带宽的模态分量,同时确保各模态的估计带宽之和最小,其约束条件为所有模态之和与原始信号f 相等。具体的变分约束表达式为:

式中,{uk}={u1,u2,…,uk}是模态,{ωk}={ω1,ω2,…,ωk}是模态的中心频率,δ(t)为狄利克雷函数,*为卷积运算。
其次,求解变分问题。我们引入拉格朗日乘子λ,转变为无约束变分问题,得到如下增广拉格朗日表达式:
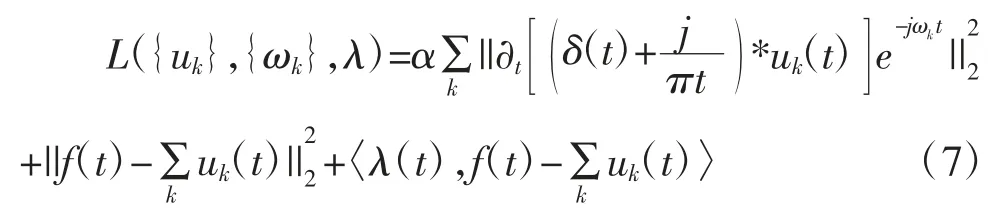
式中,α 为平衡参数,其作用是减少高斯噪声的干扰(朱敏等,2018)[29]。式(7)的优化问题采用迭代方向乘子法(ADMM),即利用式(8)至式(10),迭代更新 u、ω、λ。
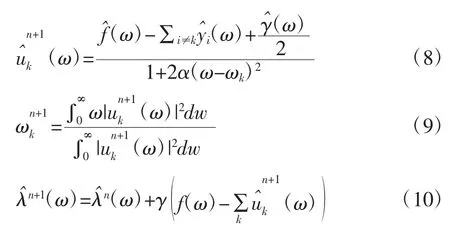
(四)基于形状的时间序列聚类算法(K-shape)
由于时序数据具有特殊性,其聚类方法与截面数据聚类有所区别,因此,本文根据动态规划原理,对时间序列进行扭曲,进行必要的错位处理,以计算出最合适的距离,并依据时序数据的形状相似性,将形状相似的序列聚为一类,即K-shape 聚类算法(Gravano et al.,2016)[30]。
1.时间序列形状相似度。互相关测度是一种统计度量,由此可以确定x 和y 两个序列的相似性。要实现平移不变性,计算互相关时应保持y 序列不变,并将x 在y 上滑动,计算x 的每一个位移s 的内积。若考虑所有的移动,CCw(x,y)=(c1,c2,…,cw),我们可以得到的互相关序列长度为2m-1,则有如下定义:
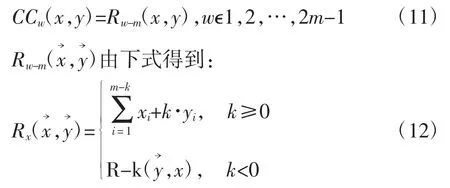
我们计算出使CCw(x,y)最大的ω,进而得到x相对于y 的最佳移动s=w-m,进而得到距离测度:
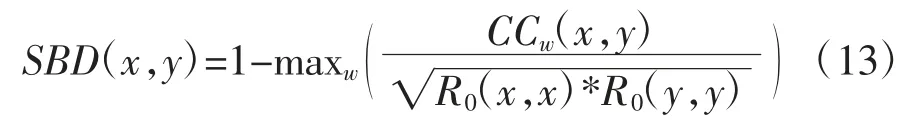
取值范围是[0,2],0 表示两个序列最相似。
2.时间序列形状提取。时间序列分析中的许多任务依赖于通过一个序列有效地总结一组时间序列的方法,这个摘要序列通常被称为平均序列,其在聚类中则被称为质心。我们的目标是找到与类内所有其他时间序列之间距离平方和的最小值,这就变为一个优化问题:

该式需要对类内所有的时间序列计算一个最佳的偏移。因为这里提到的方法是用在迭代聚类当中,所以需要把前一次计算得到的聚类中心作为参考,并把所有的序列与这个参考的序列对齐。省略式(14)的分母可以得到:
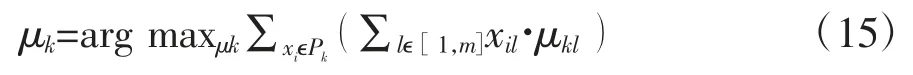
为了简单起见,我们用向量表示此方程,并假设序列已经进行了归一化处理,得到下式:
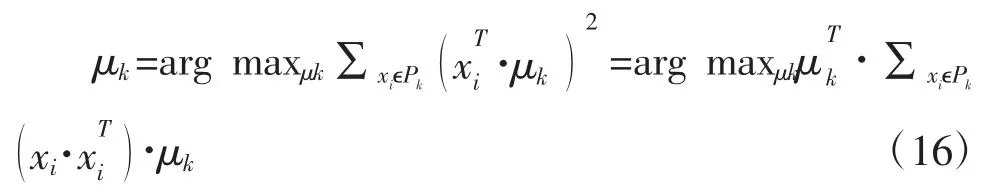
归一化数据,令 μk=μkQ,其中是单位矩阵,O 是全幺矩阵。用 S 代替我们得到:
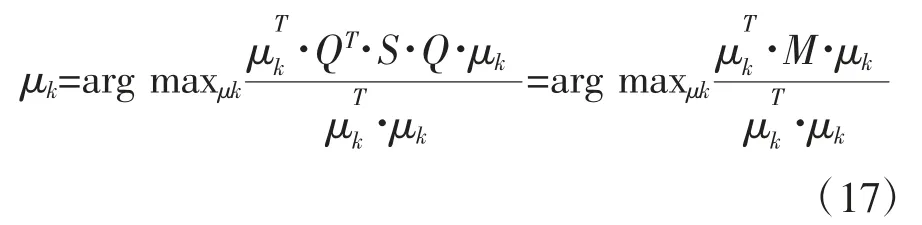
其中,M=QT·S·Q,最大值 μk即为求瑞利商(Rayleigh quotient)最大化问题,同时最大值为矩阵M 对应最大特征值的特征向量。
3.基于形状的时间序列聚类。K-shape 算法需执行两个步骤:(1)在分配步骤中,算法通过将每个时间序列与所有摘要序列进行比较,并将每个时间序列分配给最接近摘要序列的一类,以更新聚类中的成员关系;(2)在细化步骤中,通过更新聚类中心,反映前一步中聚类成员的变化。算法重复这两个步骤,直到集群成员没有变化,或者达到允许的最大迭代次数。在赋值步骤中,算法主要依赖时间序列形状相似度中的距离测度,而在细化步骤中,算法主要依赖时间序列形状提取中的聚类中心进行计算。具体的算法流程如下:

(五)ELSTM 神经网络
长短时记忆神经网络最早是由Hochreiter 和Schmidhuber 提出的,它是循环神经网络(RNN)的改进和发展(Dragomiretskiy,2014)。LSTM 因其独特的单元结构,在处理长期相关关系方面具有较明显的优势,其结构如图2 所示。
从图2 中可以看出,LSTM 包含一个或多个储存器以及三个自适应乘法门,分别为输入门、输出门和遗忘门。其中,输入门是控制是否允许写入,遗忘门是控制记忆单元的值是否需要更新,输出门是控制是否允许输出,通过这三个门就可以实现信息的保存和控制。
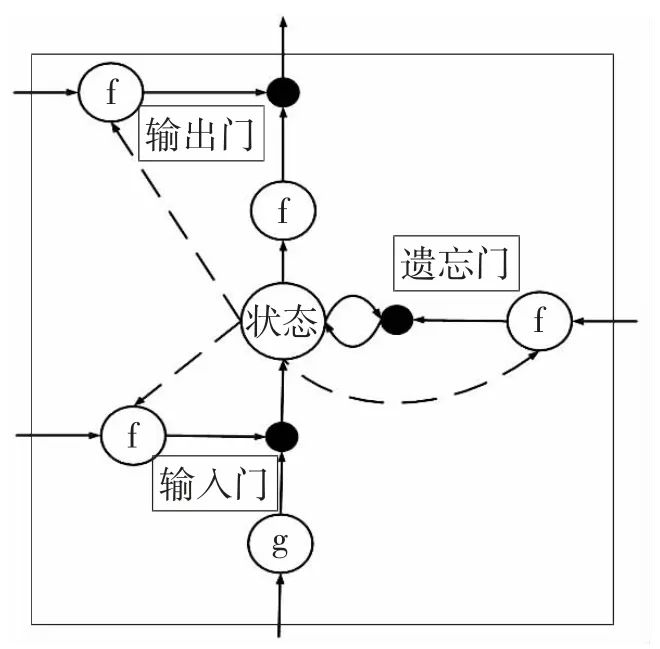
图2 LSTM 神经网络的神经元结构
在时刻t,设xt代表PM2.5的时间序列,yt代表LSTM 的预测结果,ct和ht分别为神经元状态值和隐藏层状态值,则LSTM 各单元的更新情况如下:

其中,Wih、Wfh、Wch、Woh分别是隐藏层状态值 ht的权重矩阵,Wix、Wfx、Wcx、Wox分别是时间序列 xt的权重矩阵,Wic、Wfc、Woc分别是神经元状态值 ct与三个门函数的对角矩阵,bi、bf、bc、bo分别是偏置向量,Wyh和by是LSTM 网络的输出权重和偏置向量,σ(*)是 sigmoid 激活函数,g(*)和 h(*)是 tanh 激活函数,Φ 是softmax 激活函数。上述模型中所需学习训练的参数有:各个节点间的有偏连接权重、神经元内部的输入连接权重、神经元递归连接权重。我们对权重学习设置了不同系数的正则化项,进而使用弹网惩罚项将其添加到目标函数中,以防止模型学习过程中的过拟合,即有:
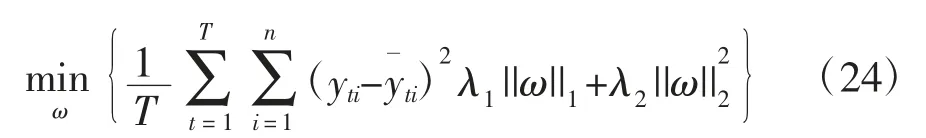
当 λ1≠0,λ2≠0 时,上式即为弹网惩罚,可以构成ELSTM 模型,以提高模型的泛化能力。
三、实证分析
(一)数据描述
本文所用的北京市PM2.5浓度数据来自于中国空气质量在线监测平台(http://www.cnemc.cn)。北京四季分明,冬天寒冷干燥,夏天炎热少雨,再加上城市汽车总量和燃煤需求量大以及周边城市的影响,北京的雾霾天气频发,一年中大多数时间的PM2.5浓度都高出正常值,呈现出明显的非线性和非平稳性特征(马忠玉和肖宏伟,2017)。因此,选取北京市PM2.5浓度序列进行预测,可以对模型的有效性进行全面、系统的检验。本文以2014—2018 年的日均数据作为训练集,以2019 年一年的数据作为测试集,对预测模型进行有效性检验。
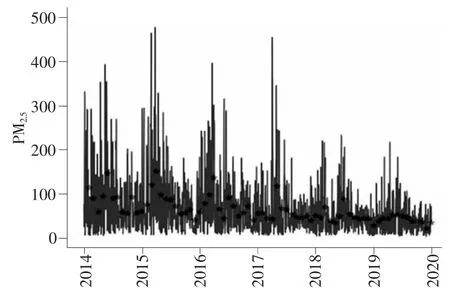
图3 PM2.5 浓度原始序列
从图3 中可以看出,原始数据序列具有含噪音、高波动等特点。将月平均数据点标注在图中可以发现,每个年份的数据集均呈现较明显的周期性和季节性。在长期趋势中,北京市PM2.5浓度在2014—2017 年度水平较高、极值较多,在2018—2019 年度PM2.5浓度水平有所改善,突破 200(μg/m3)的天数明显减少,总体呈现下降趋势。

表1 PM2.5 数据的描述性统计分析
从表1 来看,数据集为非对称分布,偏度较高,峰度值为6.83,数据较标准正态分布更为陡峭。在数据的前期处理中,本文运用拉伊达法则(张德然,2003)对数据中的异常点进行处理,对数据原有缺失点和被剔除的异常点利用三次样条插值法进行重新插值,得到处理后的数据集。以上的数据分布以及描述性统计分析充分说明,使用基于分布理论的传统统计预测方法难以在PM2.5浓度序列预测中取得理想的效果。同时,数据的高波动、含噪声、含缺失以及非线性等特点也证明了在进行预测分析前进行数据预处理具有合理性和必要性。
(二)评判标准
为了检验聚类任务的效果,本文利用轮廓系数评价聚类结果。轮廓系数可以同时计算类内聚集度与类间分离度,检验簇内样本紧密程度以及簇间样本远离程度。样本i 的轮廓系数如下:
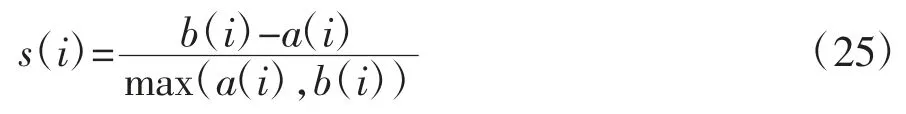
其中,a 为某个样本与其所在簇内其他样本的平均距离,b 为某个样本与其他簇样本的平均距离。本文计算所有样本对应的轮廓系数并取均值作为该聚类结果的评价指标,其取值范围为[-1,1],越接近1 说明聚类效果越好。
为了检验模型的有效性,本文采用了三种误差分析方法,即平均绝对误差(MAE)、均方根误差(RMSE)和平均绝对误差百分比(MAPE),这三种误差分析方法的计算公式如下:
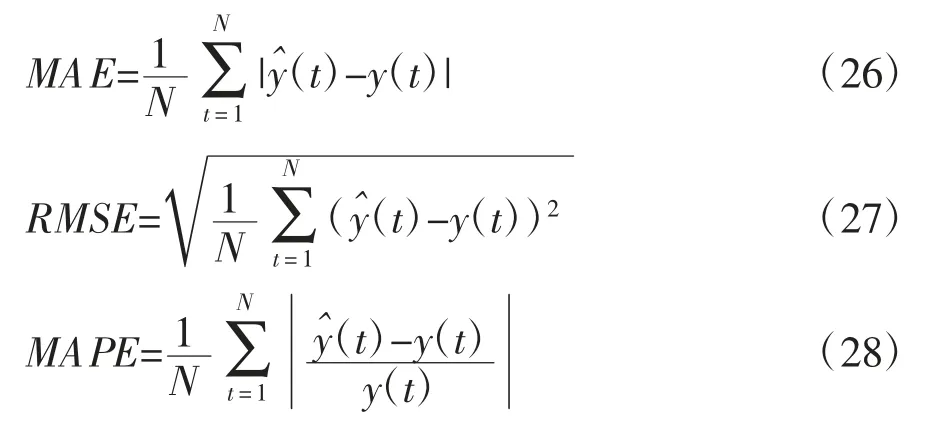
其中,yt和分别代表t 时刻的真实值和预测值,N 代表测试集中的时间点个数,即测试集的大小。
为了进一步从统计学视角对不同预测模型的水平精度进行比较分析,本文采用Diebold-Mariano 统计量测试不同模型的统计显著性(孙少龙,2016)。DM 检验的原假设是测试模型与基准模型的预测精度处于同一水准,备择假设是测试模型的预测精度显著优于基准模型,损失函数选择均方误差(MSE),则DM 统计量的定义如下:

本文在集成预测时采用了滑动窗口前向滑动测试的方式,其目的是适应时间序列数据的测试要求,即在测试集上统计真实值与预测值误差的同时,随测试的不断进行,将前一天的真实值纳入模型的历史数据集中,同时更新窗宽。该方式较固定分段的测试方式和不断更新窗口的测试方式更符合预测时间序列的实际运用,能够在最近历史数据和较远历史数据的影响之间取得平衡。
(三)预测过程
本文将原始PM2.5浓度时间序列分解为多个子序列,其结果如图4 所示。
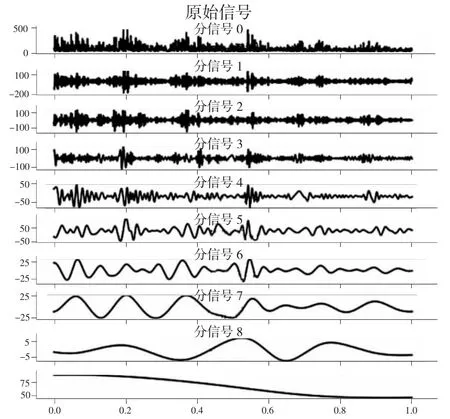
图4 PM2.5 原始序列CEEMDAN 分解
在图4 所示的时域图中,原始序列被分解为8条分量以及1 条趋势项(Residual),且各个分量按照频率从高到低依次排列,不同的分解信号反映了不同的信息。高频数据分信号1 与分信号2 包含原始序列的震荡信息,趋势项则包含原始PM2.5浓度序列的趋势信息。本文使用ELSTM 模型预测每一条分量与趋势项,在ELSTM 模型的预测过程中,利用PM2.5浓度序列的连续7 个数据点预测第8 个数据点并依次向后滑动。由于本文采用的是日均数据,考虑到实际情况,每日的PM2.5浓度与附近7 日的PM2.5浓度应有较明显的相关关系,故按此设置,并对数据进行一阶差分,以缓解数据的不平稳性。算法的迭代次数为100 次,每个小批量中包含的样本数为50。为了确保对比的公平性和有效性,以上参数将用于本文所有的对比算法中。
基于上述设定,本文利用ELSTM 对每一条分量和趋势项进行预测,并对高频分量的预测结果进行展示。在图5 的预测结果中,预测值与真实值较为接近,但频率波动较大,包含的非线性特征明显,预测效果也较差。因此,为了提高模型的预测能力,本文对难以准确预测的高频分量运用VMD 方法进行二次分解。VMD 方法要求预先设定分解模态数K,本文通过观察各模态中心频率的接近程度确定K 值,即各分量中心频率出现相近的值时,就认为出现VMD 过分解现象(陈东宁,2017)。高频信号经VMD分解后,不同K 值下各模态分量的中心频率如表2所示。

图5 高频信号序列的ELSTM 预测
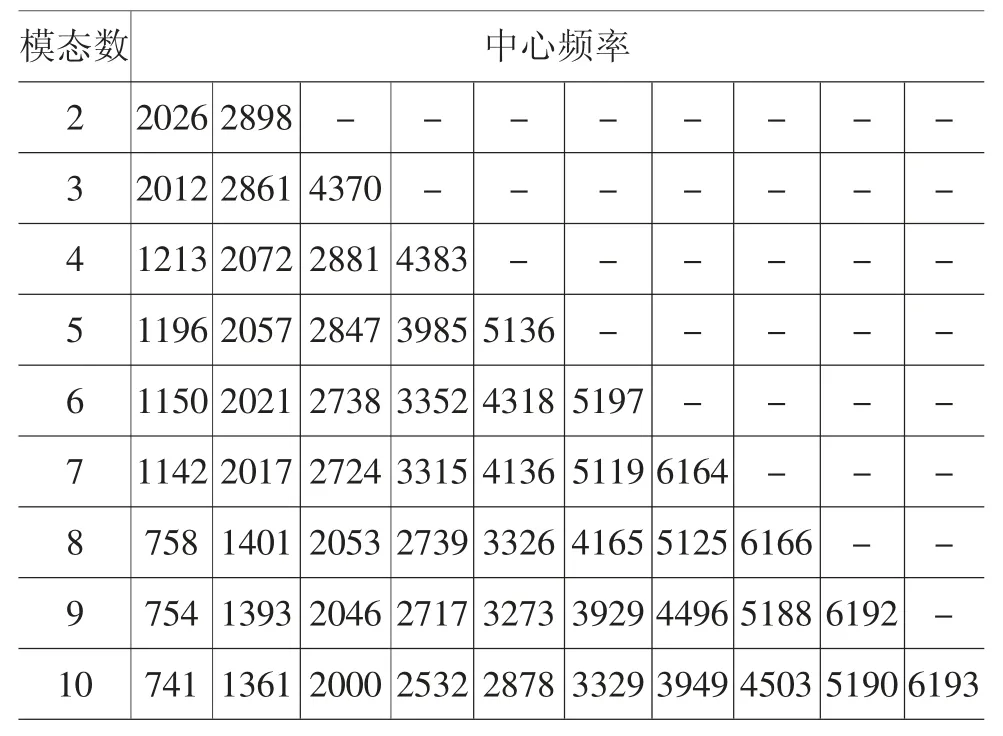
表2 不同K 值对应的中心频率
由表2 可知,模态数为10 时出现了中心频率相近的模态分量,即出现过分解,故分信号数量确定为9。图6 为高频信号经VMD 分解后的时域图。
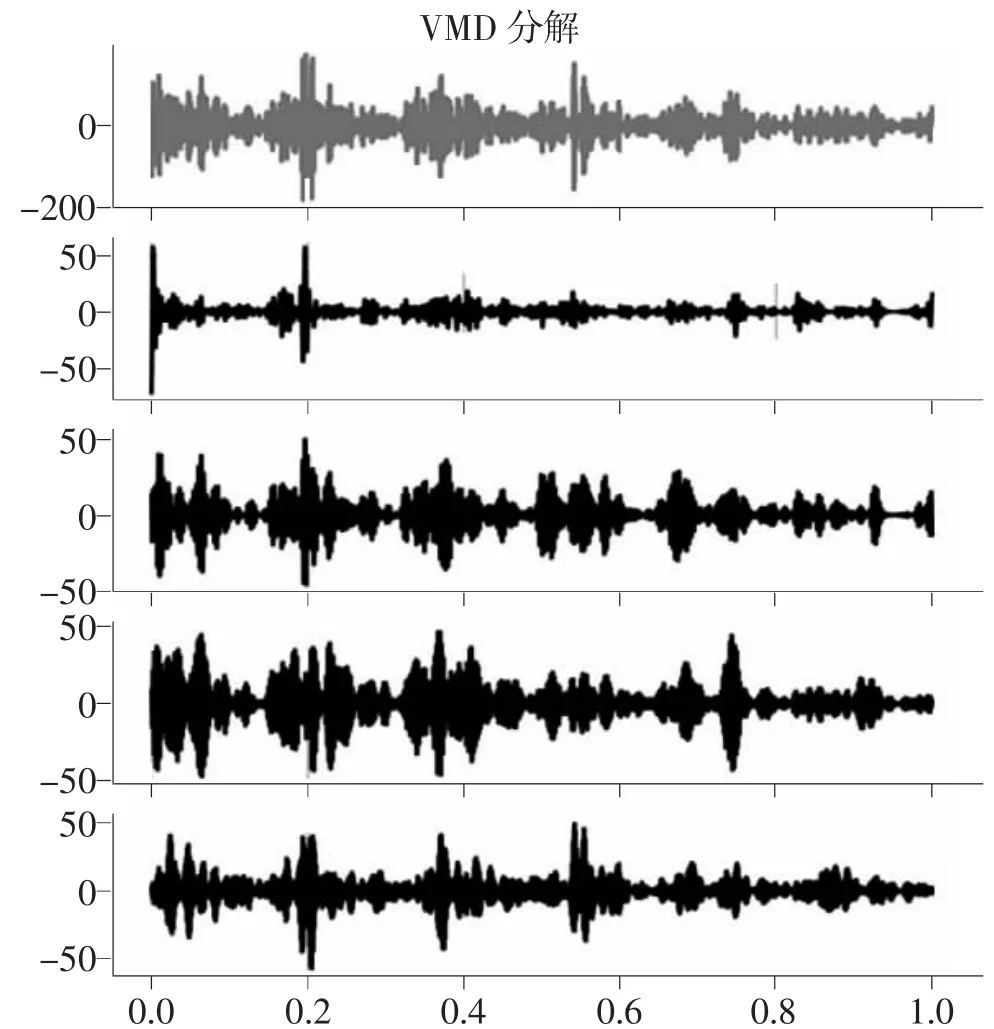
图6 高频信号VMD 分解时域
将高频信号做二次分解可以获取高频信号中的非线性特征,但这同时会使子序列的数量成倍增加,加之ELSTM 神经网络的训练过程本来就很复杂,这样会使预测模块的训练时间过长。因此,本文采用时间序列聚类算法(K-shape),将具有相似特征的分信号进行聚类,并将轮廓系数作为评价指标。高频信号1 的聚类结果如表3 所示。

表3 不同聚类中心数对应的轮廓系数
由表3 可知,当聚类中心数量为3 时,轮廓系数值最大,聚类效果最好。进一步地,本文将所有高频信号和低频信号的分解结果进行聚类,以提高预测模块的运行效率,降低预测模块的运行时间。
本文利用上述运算得到的数据以及确定的模型参数作为预测的初始参数,对每个分信号进行数据集分割、模型学习与预测。在训练模型之前,考虑时间序列的顺序特点,本文将数据转化为监督问题的可训练形式,与ELSTM 神经网络的数据输入要求进行匹配,并将预测结果进行逆差分转换,还原为目标预测值,最后进行集成预测,将各个分信号的预测结果进行叠加,作为最终的预测值。模型的预测效果如图7 所示。
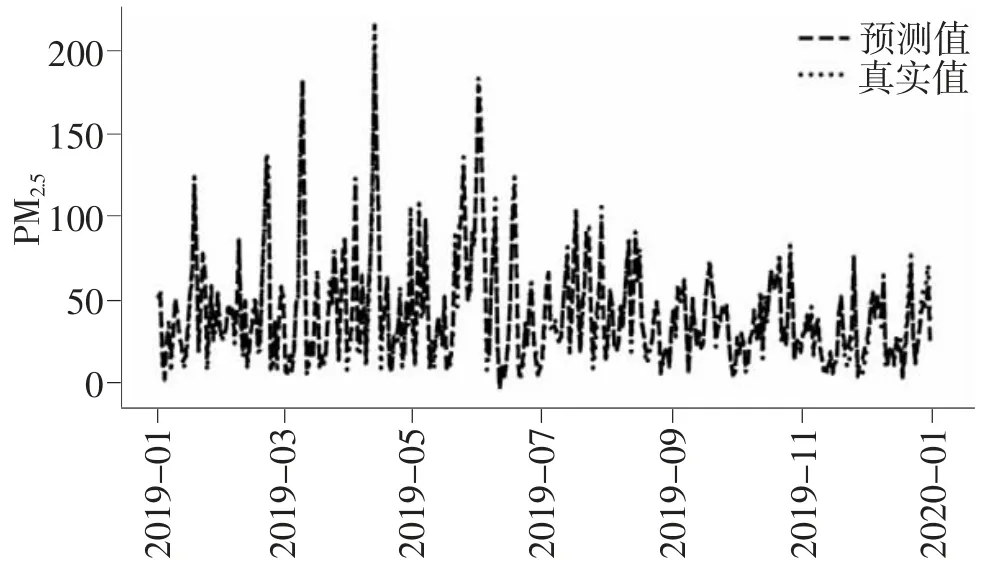
图7 多模态集成预测效果
四、模型比较和鲁棒性
为了说明基于“分解—聚类—集成”研究范式的二次分解组合模型的有效性,本文将CEEMDANVMD-K-ELSTM 模型与单一模型、一次分解集成模型、二次分解集成模型进行对比,以探究模型复杂度的提升以及分解方法的组合对预测结果的影响,并利用DM 检验分析模型的预测精度是否存在显著性差异。表4 为各个模型在北京市PM2.5浓度预测中的误差值,本文分别从RMSE、MAE 和MAPE 标准方面对所有预测模型的性能进行评价。
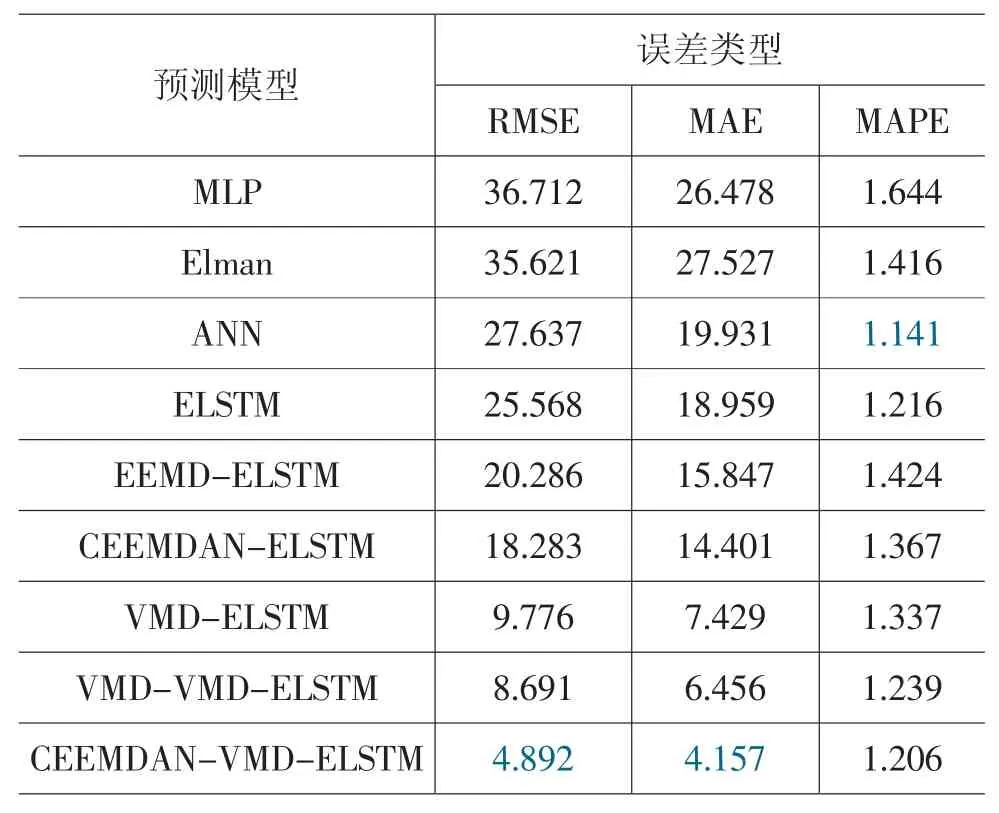
表4 不同模型的预测结果对比
由表4 的预测结果可知,ELSTM 较其他神经网络模型的精度更高,预测效果更好。基于“分解—聚类—集成”的组合模型在预测性能上均优于单一模型,表明“分解—聚类—集成”研究范式可以有效克服PM2.5浓度数据的高波动性、非线性特征对模型预测精度造成的影响,显著提高模型的预测能力。本文所提出的二次分解模型在RMSE 和MAE 两类评价中取得的效果最好,表明不同分解技术的组合对预测效果也有一定的影响,CEEMDAN 方法与VMD 方法组合的二次分解方法使得实验结果达到最优。
为了判断CEEMDAN-VMD-K-ELSTM 模型的预测结果是否在统计学上显著优于基准模型,本文利用DM 统计量进行检验。DM 检验是根据DM 统计量的值判断模型之间的预测精度是否在统计意义上具有显著差异,表5 为DM 检验结果。

表5 DM 检验结果
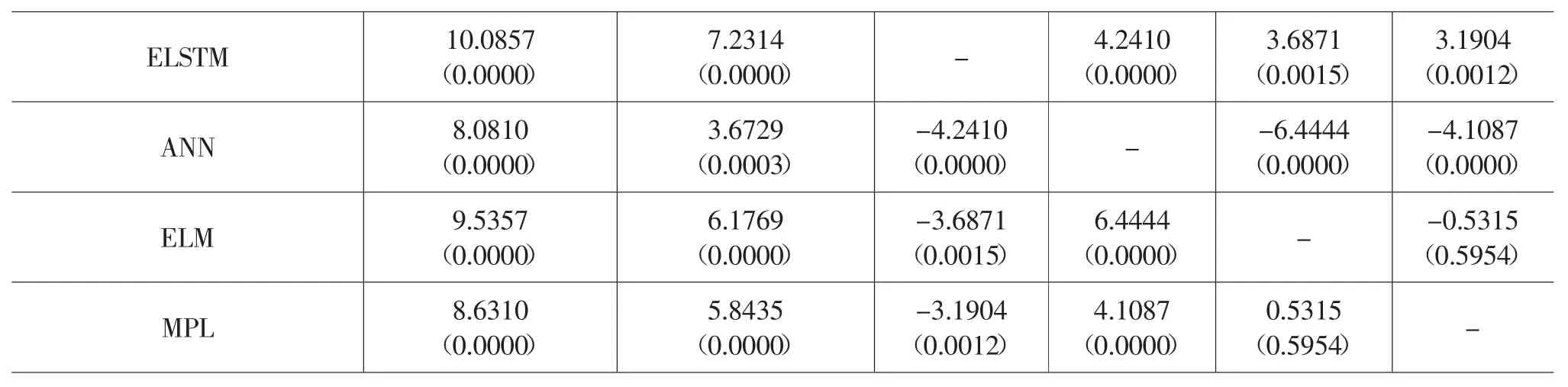
(续表5)
由表5 可知,以本文提出的CEEMDAN-VMDK-ELSTM 作为测试模型时,其预测精度在0.01 的显著性水平上显著优于其他基准模型,二次分解组合模型显著优于一次分解模型,而单一模型中的ELSTM 神经网络显著优于其他网络。
为了进一步验证模型的有效性,检验数据变化对模型的鲁棒性影响,本文利用2015 年1 月1 日至2020 年6 月31 日的日均PM2.5浓度序列检验模型是否仍能保持较好的预测性能及稳定性。窗宽设定为 30,验证集数据为 2020 年 3 月 31 至 2020 年 6月 31 日。图 8 为 CEEMDAN-VMD-K-ELSTM 模型与基准模型在不同数据集上的预测比较结果。
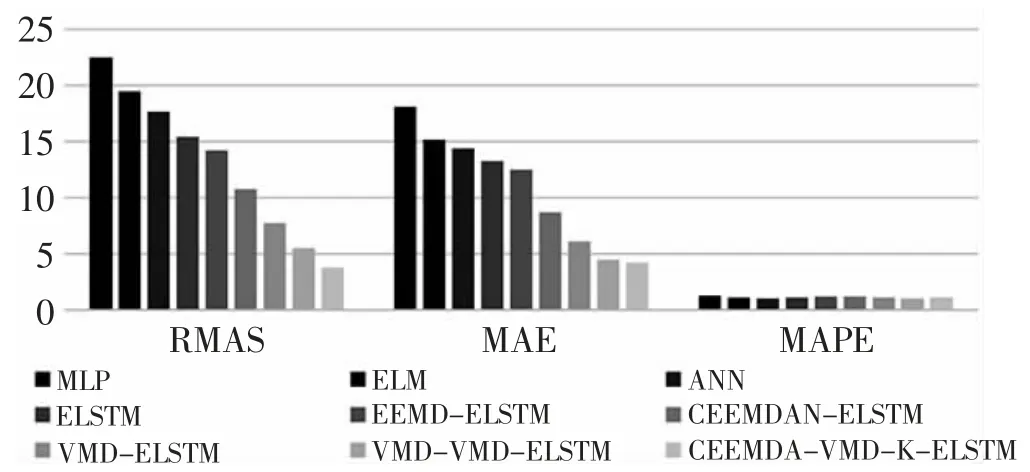
图8 不同数据集上的预测模型误差对比
由图 8 可知,CEEMDAN-VMD-K-ELSTM 组合模型在RMSE 和MAE 标准下仍具有最高的预测精度,即模型能够对不同的PM2.5浓度时间序列进行较为准确的预测,具有良好的鲁棒性。
五、结论与展望
空气质量研究一直是国内重点关注的问题,污染物浓度预测更是空气质量研究的重中之重,其不仅可以有效预防严重空气污染事件的发生,还可以帮助人们及时采取应对措施。因此,构建一个行之有效的空气质量预测模型具有重要的现实意义。
本文引入分解算法作为预处理工具,以提取输入原始数据的内在特征,而分解算法和深度学习在自然语言处理、计算机视觉等领域已经取得很大的成就,尤其是在空气质量预测方面。由于数据存在非线性、非平稳性及波动性的特性,以往的空气质量预测准确率并不能令人满意。因此,本文通过将不同的模态分解技术与常用机器学习模型、神经网络模型进行组合对比分析,提出一种二层分解多模态集成预测方法,并在“分解—集成”的研究范式下进行进一步的拓展,将“分解—聚类—集成”的研究范式应用于PM2.5浓度序列预测,采用基于时间序列形状的聚类算法将分解后的时序数据进行聚类,提高了模型整体的运行效率。本文对北京市PM2.5浓度的实证分析,证明了二层分解与ELSTM 神经网络的组合在时间序列预测上可以获得更为精准的预测效果。
本文提出的基于聚类的二次分解集成模型还可以应用于其他一些较为困难的预测任务,如金融时间序列预测、风速预测、电力消耗预测等。就空气质量预测问题而言,本文依然存在诸多可拓展之处。首先,由实证分析可知,数据分解在混合集成学习范式中具有重要地位,今后应探索更高效、可行的数据分解算法。其次,在单一预测中,为保证预测精度所使用的复杂模型,其时间复杂度大大提高,今后应探究更高效的数据压缩算法,以加快单一预测的速度。再次,影响PM2.5浓度的温度、空气、湿度等因素的相关数据量都较大,这使得精确预测PM2.5浓度存在困难,今后应加入气象数据、地理信息数据等影响空气污染的其他因素,以提高预测精度,这有助于研究者提高对空气质量预测问题的认知,构建更广义的数据融合预测模型。此外,人口规模、经济产业结构与量级、政府空气污染治理政策等因素也是除空气和气象地理数据之外应考虑的重要方面,如何将这些因素与空气质量研究相结合也是一个需要解决的实际问题。
