充油电气设备油色谱故障诊断ANN方法的性能优化
2021-07-02张宝全马雅丽关睿白诗婷李静胡伟涛
张宝全,马雅丽,2,关睿,白诗婷,李静,胡伟涛
(1.国网河北省电力有限公司检修分公司,河北 石家庄 050070;2.华北电力大学 电力工程系,河北 保定 071003)
为了提高电气设备寿命,高压电气设备往往是以油和固体电介质(如纸和高分子材料)作为内绝缘。电气设备在运行中受到电、热、机械和环境应力的作用会逐渐老化[1],当电气和机械性能不满足要求时将会发生故障,影响电力系统的可靠运行。因此,充油电气设备的故障诊断对于保障电力系统正常运行、提高供电质量非常重要。
绝缘电阻、泄漏电流、介电谱[2]、局部放电[3]、温度[4]、振动[5]、红外和紫外[6]、油中溶解气体分析(又称油色谱)[7-9]等是常见的充油电气设备故障检测特征量,每种方法都有自己的特点和适合应用的场合,本文主要针对油色谱法开展研究。由于不同类型和严重程度的故障导致充油电气设备油中产生的故障特征气体含量不同,采用气相色谱法检测获得油中故障特征气体含量,结合故障诊断方法即可判断设备内部发生的故障。该方法适用于诊断局部、慢性、潜在性缺陷,同时由于大型充油电气设备有取油样口,取油样时并不需要停电操作,故也适合于在线监测。
目前现场针对油色谱故障诊断最为常用的方法为比值法[10-11],该类方法中又以国际电工委员会(International Electrotechnical Commission,IEC)推荐的IEC三比值法及其改良版本应用最为广泛。考虑到溶解度和扩散系数的相似性,该方法选择3对气体(C2H2和C2H4、CH4和H2、C2H4和C2H6)的体积分数比值,根据比值确定编码,根据编码确定故障类型。三比值法应用广泛,能比较有效地诊断充油电气设备的故障,但诊断准确率还不够高,不能进一步利用大量特征气体数据所隐含的信息来提高故障诊断准确率。为了解决该问题,人们提出采用机器学习来提高故障诊断的准确率,主要有人工神经网络(artificial neural network,ANN)法[12-13]、专家系统法[14]、遗传算法[15]、证据推理法[16]、云理论法[17]、贝叶斯网络法[18]等,有效推动了充油电气设备故障诊断的智能化,尤其是ANN方法由于具有较好的自学习能力而被广泛应用。针对油色谱的ANN诊断方法尚存在以下问题:①虽然有不少文献采用了不同算法训练ANN[19-22],也给出了故障诊断结果,但这些算法训练速度和诊断准确率关系如何未见文献公开报道,这给算法的选择带来了难度;②有文献给出了隐层神经元数量的选择方法[23-24],但不确定对基于油色谱的ANN方法是否适用,关于隐层神经元数量、隐层和输出层神经元激活函数选择和训练目标选择对基于油色谱的ANN训练速度和诊断准确率的影响未见文献公开报道。以上问题可能会影响网络诊断的准确性,非常有必要进行研究。
为了解决这个问题,本文基于搜集得到的470个典型故障特征气体样本,构建单隐层多层前馈ANN系统,研究训练算法、隐层神经元数量、网络输入和训练目标、隐层和输出层神经元激活函数对训练和诊断效果的影响规律,并给出ANN应用于充油电气设备故障诊断时相关参数选择的建议,为基于油色谱的充油电气设备故障诊断的应用提供参考。
1 基于ANN的充油电气设备故障诊断
1.1 油色谱分析过程
充油电气设备在运行中会受到热应力、电应力等作用导致设备内部温升、局部放电、局部的火花和电弧等故障,这样设备内部的油和纸可能会分解产生气体,通常用于故障特征判断的气体是H2、CH4、C2H6、C2H4、C2H2、CO和CO2,通常称为故障特征气体。产生的气体溶解于油中,通过设备内部的油循环被输运到取油样口。在取油样口取出故障特征气体后,通过震荡脱气等方式可以获得处于混合状态的故障特征气体,然后通过气相色谱、光声光谱、红外光谱等方式实现各种类型故障特征气体含量的测量。不同故障下作用在油和纸上的温度、功率不同,导致油和纸分解产生气体的类型、产气速率和气体的分压比不同,根据检测得到的各种故障特征气体数据即可判断故障类型乃至严重程度。
1.2 基于ANN的充油电气设备故障诊断
从数学角度看,多层前馈ANN可以认为是一个映射,涉及到充油电气设备故障诊断时就是实现从输入特征气体含量到故障类型的映射。多层前馈ANN理论上可以实现任意复杂的映射,且单隐层ANN即具有该能力,适用于本文的充油电气设备故障诊断。多层前馈ANN结构如图1所示,其中:M为输入层神经元数量;N为隐层神经元数量;L为输出层神经元数量;xmq(m=1,2,…,M)为第q个样本向量中第m个元素的值;ω1mn(m=1,2,…,M,n=1,2,…,N)为输入层第m个神经元到隐层第n个神经元的权值;ω2nl(n=1,2,…,N,l=1,2,…,L)为隐层第n个神经元到输出层第l个神经元的权值;ol(l=1,2,…,L)为输出层第l个神经元的输出结果。

图1 多层前馈ANN结构Fig.1 Structure of multi-layer feedforward ANN
图1所示ANN对应的映射
ol(x1q,x2q,…,xMq)=
l=1,2,…,L.
(1)
式中:f1和f2分别为隐层和输出层神经元的激活函数;tn为隐层第n个神经元的阈值。
ANN训练本质上是一个非线性最小二乘问题,即通过调整权值和阈值使目标函数E最小化,
(2)
式中:Q为训练样本数量;εlq为针对第q个样本ANN输出层第l个神经元输出的目标值。
无论采用什么算法,网络可调变量(权值和阈值)ωa的调整公式为:
ωa(k+1)=ωa(k)+Δωa(k),a=1,2,…,A.
(3)
式中:Δωa为第a个可调变量的增量;A为网络可调变量的数量;k为迭代次数。
不同算法之间的差别就在于Δωa(k)的计算方式。除了经典的BP算法[24],为了避免训练时陷入局部极小点同时提高收敛速度,研究人员又提出了变学习速率(步长)和加动量项的BP算法[24]。振荡传播算法[25]从另外一个角度修正可调变量增量的计算公式,即有效利用误差梯度的符号信息。共轭梯度法[26-27]利用搜索方向互相共轭的方式来提高收敛速度,减小计算过程对内存的需求,典型的共轭梯度法有基于Powell-Beale重开始方式和基于Polak-Ribiére修正的算法[26-27]。但是,基于一阶梯度的算法训练速度受到一定程度的限制,为了进一步提高训练速度,有研究人员将基于二阶梯度的算法引入到ANN的训练中来,具体包括拟牛顿法[26]和Levenberg-Marquardt算法[28]。目前已有很多文献对以上典型算法的原理进行了介绍[24-28]。
2 ANN优化
2.1 ANN缺省参数选择
为了确保样本的有效性和典型性,从现有公开发表文献和少量现场实测数据中选择470组油色谱样本。另外,ANN的训练样本要求具有较好的代表性,这样训练得到的ANN才可以学习到训练样本数据中隐藏的故障诊断规则。本文采用聚类分析方法,从470个样本中选择出226个典型样本作为训练样本,剩余的244个样本作为测试样本,具体见表1。

表1 不同故障类型的训练和测试样本数量Tab.1 Numbers of training and test samples for different fault types
单隐层ANN能保障足够的学习能力,而且相较于多隐层ANN具有更高的泛化能力,即更高的故障诊断准确率,因此本文选择单隐层ANN。输入层和输出层神经元数量分别由特征气体种类和故障种类决定。故障诊断用的特征气体分别为H2、CH4、C2H6、C2H4和C2H2,输出为6种故障类型——低温过热、中温过热、高温过热、局部放电、火花放电和电弧放电,因此输入层和输出层神经元数量均为6。
ANN结构以及输入数据方式、训练目标等默认取值如下:考虑到诊断的准确性,训练算法选择Levenberg-Marquardt算法;隐层和输出层神经元的激活函数分别设置为sigmoid函数和线性函数;考虑到实际情况下特征气体含量可能会在很大范围内变化,故用于训练的输入数据为每种气体体积分数与总气体体积分数的比值;对于输出结果,如果属于某类故障则对应的神经元应该输出为1,其他神经元应该输出为0;训练目标是均方误差为0.01,一旦误差满足要求则网络收敛,停止迭代。
后文对网络结构、激活函数和训练目标三者之一进行优化时,其他两者保持不变。另外,由于10个ANN训练时间存在一定的波动性,有时波动较大,为了更好地反映训练时间的变化规律,如无特殊说明,后续的训练时间指10个ANN训练时间的中位数。
2.2 训练算法
采用8种不同算法对ANN进行训练,具体为BP算法、加动量项的BP算法、变学习速率的BP算法、振荡传播算法、基于Powell-Beale重开始方式和基于Polak-Ribiére修正的共轭梯度法、拟牛顿法及Levenberg-Marquardt算法,训练至误差趋于稳定值。综合考虑诊断准确率和训练耗时后,以上算法对应隐层神经元选择了不同值——BP算法及其改进算法选择为400,其他算法选择为50。不同算法下训练样本的均方误差与训练时间的关系如图2所示,其中的训练时间为具体某ANN的训练时间。
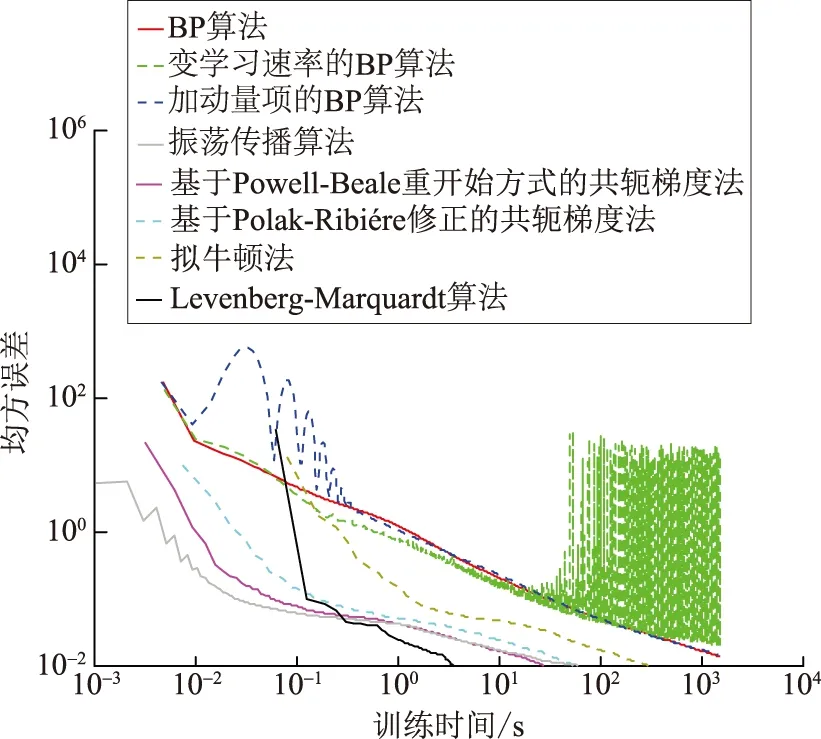
图2 不同算法下训练时间与训练误差的关系Fig.2 Relationship between training time and errors of different algorithms
为了减少训练结果的随机性,采用每种算法成功训练10个ANN,后续针对训练样本和测试样本的诊断结果均为10个ANN结果的均值。采用不同算法训练得到的ANN针对训练样本和测试样本的故障诊断准确率见表2、表3。

表3 采用不同算法训练得到的ANN针对测试样本的故障诊断准确率Tab.3 Fault diagnosis accuracy of ANN method for test samples using different algorithms %
由表2和3可知,不同算法训练得到的ANN诊断的准确性比较接近,尤其是针对测试样本的诊断准确率非常接近。但从训练时间上看不同算法差别较大:前3种BP类算法训练1个ANN耗时分别为1 669.14 s、1 558.46 s和1 647.13 s。后5种算法成功训练完成1个ANN需要的时间分别为27.27 s、26.93 s、231.74 s、35.96 s和4.60 s。Levenberg-Marquardt算法的训练速度最快,而BP算法的训练速度最慢。考虑到各种算法训练得到网络的故障诊断准确率接近,但Levenberg-Marquardt算法的训练速度最快,故选择该算法训练ANN。

表2 采用不同算法训练得到的ANN针对训练样本的故障诊断准确率Tab.2 Fault diagnosis accuracy of ANN method for training samples using different algorithms %
2.3 网络结构
隐层神经元数量在30~60范围内变化,针对每个隐层神经元数量,成功训练10个ANN。网络训练时间随隐层神经元数量的变化如图3所示,针对测试样本的诊断准确率如图4所示。隐层神经元数量不同时,训练得到的ANN针对测试样本的故障诊断准确率见表4。

表4 不同隐层神经元数量下训练得到的ANN针对测试样本的故障诊断准确率Tab.4 Fault diagnosis accuracy of ANN for test samples with different numbers of hidden layer neuron
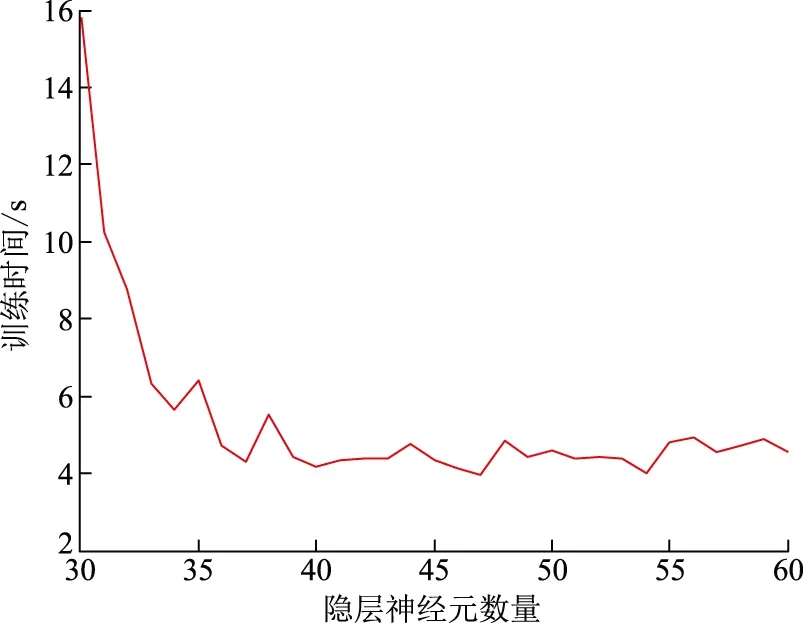
图3 训练时间与隐层神经元数量的关系Fig.3 Relationship between training time and numbers of hidden layer neuron

图4 针对测试样本的故障诊断准确率与隐层神经元数量的关系Fig.4 Relationship between fault diagnosis accuracy for test samples and numbers of hidden layer neuron
由图3可知,在本节设定的仿真范围内,随着隐层神经元数量从较小值(30)开始增加,训练时间快速下降,当达到最小值(此时神经元数量为40)之后,随着神经元数量增加训练时间又略有增加。由图4可知,随着隐层神经元数量从较小值开始增加,网络诊断准确率先增加,然后趋于稳定值。综合分析以上研究结果可知:隐层神经元数量不建议选择过小值,因为这样训练时间太长且诊断准确率未必是最高;也不建议选择过大值,因为从更大的范围来看,随隐层神经元数量增加网络泛化能力下降,即此时诊断准确率未必是最优。因此,应该选择一些居中的值,比如本例建议选择50。
2.4 训练目标
训练目标为均方误差,其值在2×10-3~0.04范围内变化。针对每个训练目标,成功训练10个ANN。训练时间与训练目标的关系如图5所示。不同训练目标时,训练得到的ANN针对测试样本的故障诊断准确率见表5。

图5 训练时间与训练目标的关系(1)Fig.5 Relationship between training time and training goals (1)
由图5可知,随训练目标(均方误差)从较小值开始增加,训练时间先快速下降然后趋于稳定值。由表5可知,随着训练目标(均方误差)的减小,ANN诊断准确率先增加,达到最大值后又逐渐减小。因此,训练目标不应该选择过大值或过小值,对于基于油色谱的充油电气设备的故障诊断建议选择0.01。

表5 不同训练目标下,训练得到的ANN针对测试样本的故障诊断准确率(1)Tab.5 Fault diagnosis accuracy of ANN for test samples in different training goals (1)
为了增加结论的可靠性,针对网络结构和隐层、输出层激活函数不同时也开展了训练目标对ANN训练效果影响的研究,隐层神经元数量选择100,隐层和输出层激活函数均设置为sigmoid函数,训练目标在5×10-4~0.04范围内变化,其他参数保持不变。训练时间随训练目标的变化如图6所示。不同训练目标时,训练得到的ANN针对测试样本的故障诊断准确率见表6。

图6 训练时间与训练目标的关系(2)Fig.6 Relationship between training time and training goals (2)
显然,图6、表6与图5、表5的结果在定性上能很好吻合。
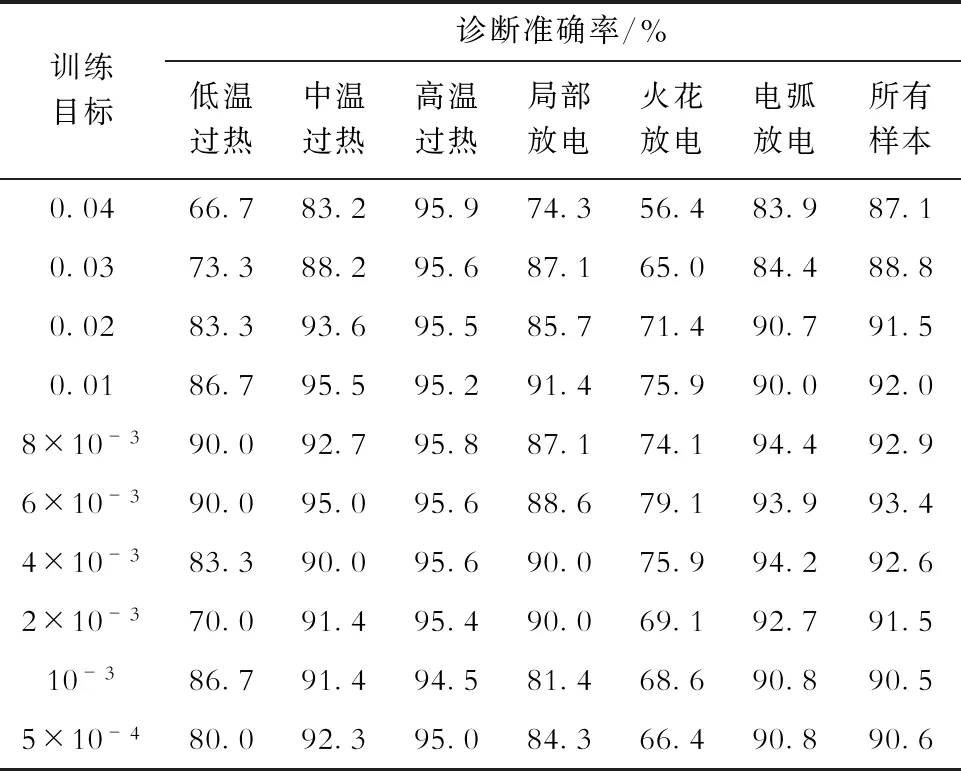
表6 不同训练目标下,训练得到的ANN针对测试样本的故障诊断准确率(2)Tab.6 Fault diagnosis accuracy of ANN for test samples in different training goals (2)
2.5 激活函数选择
常见的激活函数为sigmoid函数和线性函数,隐层和输出层激活函数分别设置为线性函数-线性函数、sigmoid函数-线性函数、线性函数-sigmoid函数、sigmoid函数-sigmoid函数4种组合。针对每种隐层和输出层神经元激活函数组合,成功训练10个ANN。图7为不同激活函数组合下训练误差与训练时间的关系,针对训练样本和测试样本的诊断结果见表7、表8。

图7 不同激活函数下训练误差与训练时间的关系Fig.7 Relationship between training errors and training time for different activation functions

表7 采用不同激活函数时,训练得到的ANN针对训练样本的故障诊断准确率Tab.7 Fault diagnosis accuracy of ANN for training samples using different activation functions %

表8 采用不同激活函数时,训练得到的ANN针对测试样本的故障诊断准确率Tab.8 Fault diagnosis accuracy of ANN for test samples using different activation functions %
由图7可知:当隐层神经元激活函数为线性函数时,训练结果均不能收敛于训练目标(均方误差为0.01);而隐层神经元激活函数为sigmoid函数时,输出层神经元不管是采用线性函数还是sigmoid函数,训练结果均能收敛。由表7可知,即使针对训练过的样本,隐层神经元激活函数为线性函数、输出层神经元不管是采用线性函数还是sigmoid函数时,训练得到ANN的诊断准确率均明显低于其他情况下ANN的效果。表8中数据与图7和表7吻合,即:当隐层神经元激活函数为线性函数时训练得到ANN的诊断准确率偏低;当隐层神经元激活函数为sigmoid函数时,不管输出层神经元激活函数是线性函数还是sigmoid函数,诊断准确率都较高且接近。因此,选择sigmoid函数作为隐层神经元激活函数。
3 结论
本文基于搜集得到的大量油色谱样本,从训练和诊断2个角度系统研究了隐层神经元数量、训练算法、训练目标、隐层和输出层神经元激活函数对网络性能的影响,结论如下:
a)训练目标一致时,8种不同算法训练得到的ANN具有相近的故障诊断准确率,但从训练时间上看Levenberg-Marquardt算法最快,BP类算法最慢,因此建议选择Levenberg-Marquardt算法训练ANN。
b)隐层神经元数量在一定范围内对故障诊断准确率影响不大;隐层神经元数量不建议选择过大或过小的值。
c)随训练目标(均方误差)的减小,训练时间增加,诊断误差先增大后减小,建议均方误差选择0.01。
d)隐层神经元激活函数选择线性函数时,训练难以很好收敛,诊断准确率低。建议隐层神经元激活函数选择sigmoid函数,输出层神经元激活函数可以选择线性函数或sigmoid函数。
