基于改进注意力机制的图像描述生成算法
2021-07-02李文惠曾上游王金金
李文惠,曾上游,王金金
(广西师范大学电子工程学院,广西桂林 541004)
(*通信作者电子邮箱zsy@mailbox.gxnu.edu.cn)
0 引言
图像描述是将图像用自然语言句子表达出来,它是计算机视觉的主要研究任务之一。图像描述对于计算机而言不仅需要识别图像中的对象,而且还要理解图像中的内容以及对象之间存在的关系,最后计算机还要用自然语言句子去将图像内容正确地表达出来,因此图像描述任务对于计算机视觉领域的研究来说还是存在一定的难度。目前图像描述存在的问题主要包括图像分类问题和自然语言处理问题。针对图像分类问题,卷积神经网络(Convolutional Neural Network,CNN)通过自动提取图像特征,使图像分类的准确率达到甚至超过了人类肉眼对图像分类识别的标准;针对自然语言处理问题,循环神经网络(Recurrent Neural Network,RNN)通过记住句子中词的相对关系,去处理自然语言句子。然而对于上述两者问题的结合而言,虽然目前存在相关网络能够在一定程度上简单地描述图像,但没有在各自领域研究得那么深入。实现图像描述的方法主要分三种:基于模板的图像描述生成方法、基于检索的图像描述生成方法和基于深度学习的图像描述生成方法。近年来,图像描述主流方法是深度学习。深度学习模型的训练方式是端到端,其优点是它可以自己学习特征,避免了人为地去设计参数。对于图像描述生成模型,整体大致分为两个部分:编码(ENCODER)和解码(DECODER)[1]。在图像编码中,通过多层深度卷积神经网络[2-4]针对图像中的物体特征建立起模型;在图像解码中,通过循环神经网络针对文本信息建立起模型。运用循环神经网络[5-6]将文本信息与图像信息映射在同一个空间中,利用图像信息引导文本句子生成。随着深度学习研究的不断深入,强化学习[7-8]和基于注意力机制[9-10]的研究方法相继涌现。该方法对模板、规则的约束少,能自动推断出测试图像及其相对应的文本,自动地从大量的训练集中学习图像和文本信息,生成更灵活、更丰富的图像描述句子,还能描述从未见过的图像内容特征。本文引入改进的注意力机制,不仅可以减少模型参数,而且能更准确地生成描述图像的自然语言句子和提升图像描述生成模型的评价指标。
1 相关工作及本文方法
首先简单介绍有关图像描述生成和注意力机制先前工作的背景。2014 年Vinyals 等[1]提出了一个基本的卷积神经网络(CNN)联合循环神经网络(RNN)的图像描述框架,在图像描述的领域中取得了巨大的突破,同时也提出了评价图像描述生成模型性能的指标,但是依然没有考虑到词对应图像位置这一缺陷。基于此问题,2016 年Xu 等[11]从人的视觉上受到启发,在文献[1]框架中引入了注意力机制,使得计算机描述图像更加符合人类的描述机制,在指标上也得到相应的提升,同时也验证了注意力机制的可行性。上述所说的基于深度学习的描述算法虽能产生描述图像的自然语言句子,但总体上有一定的局限性,如参数过多、注意力还有很大的提升空间。
本文提出了一种基于CNN 和长短期记忆元的图像描述生成,并引入改进的注意力机制的模型。改进的注意力机制是在文献[11]的基础模型上改进的,改进的点是将原全连接层替换成了文中注意力机制(ATTENTION),全连接层不仅参数多而且关注很多无用的信息,造成信息冗余,文中引入注意力机制的结构能有效地避开这些问题。本文提取图像特征采用了两种卷积神经网络,分别是VGG(Visual Geometry Group)和ResNet(Residual Network),解码采用长短期记忆(Long Short-Term Memory,LSTM)网络[12],同时引入改进的注意力机制,最终生成图像描述的自然语言句子,能够有效提升图像中的内容与句子描述的相关联度,同时图像描述的相关评估指标有所提升,生成更接近人类语言的图像描述自然语言句子。
2 本文模型
本文模型分为两个模块:ENCODER 模块和DECODER 模块。ENCODER 模块采用卷积神经网络,其功能在于提取图像的特征,对图像进行编码,将图像编码为特征向量;DECODER 模块是将编码后的图像解码成自然语句,它主要通过长短期记忆网络解码图像信息,其功能是提取句子单词之间的句法特征,依据选择的图像特征生成图像描述的自然语言句子。本文使用CNN+LSTM+ATTENTION 的基本框架[13]来完成。将图像输入到卷积神经网络中,得到网络输出的特征向量,文本的词通过嵌入(EMBEDDING)层将词转成词向量,将特征向量和词向量拼接后输入到长短期记忆单元,产生新的预测词,通过集束搜索(Beam Search)的方式产生预测的句子。模型整体结构如图1所示。
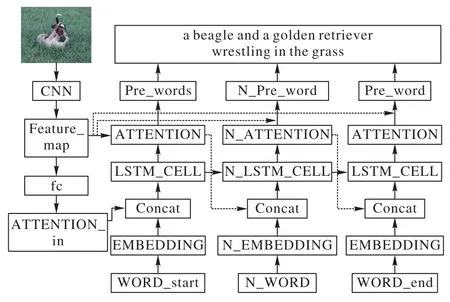
图1 本文模型整体结构Fig.1 Overall structure of the proposed model
ENCODER 模块采用的是VGG19 网络和ResNet101,VGG19网络是使用3×3卷积核的卷积层堆叠并交替最大池化层,VGG 网络的一大优点是简化了神经网络结构,本文选取VGG19 网络中最后一个最大池化层的输出特征图,再加一个1×1 卷积使得VGG19 和ResNet101 的输出特征图维度相同,1×1 卷积输出的特征图经自适应池化层后,得到的自适应特征图作为整个网络中的ENCODER 模块输出特征图。VGG19只有19 层,ResNet101 有101 层,它们在网络深度上完全不是一个量级,ResNet101可以使用一个称为残差模块的标准网络组件来组成更复杂的网络,网络加深的同时也保持了网络的性能,解决了深度网络的退化问题,本文选取ResNet101 网络平均池化层的输入特征图,将经自适应池化层后的特征图作为整个网络中的ENCODER 模块输出特征图。DECODER 模块采用LSTM 网络,该网络可以连接先前的信息到当前的信息,语句的预测是和词的先前信息有一定的关联的,而LSTM网络适合处理这类时间序列问题[14]。
本文引入分组注意力机制,结构如图2 所示。Encoder_out 是卷积神经网络输出的特征图,大小为2 048×14×14,Decoder_hidden是LSTM的隐藏输出,大小为512×1×1。
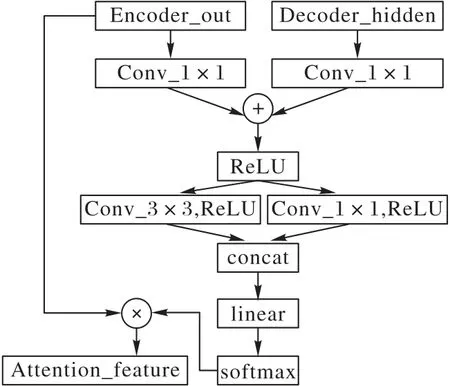
图2 改进的注意力机制Fig.2 Improved attention mechanism
本文设计的是分组卷积注意力,通过1×1 卷积(Conv_1×1)分别整合图片特征和词特征,用激活函数ReLU(Rectified Linear Unit)将整合的特征引入非线性,得到激活特征并将其分成两组卷积,分别是3×3 卷积(Conv_3×3)和1×1 卷 积(Conv_1×1),且都使用激活函数ReLU 引入非线性,再拼接输入到线性层(linear)中,通过softmax函数得到图像和词的关联度,进而形成新的注意力分布。通过分组的特征注意力,可以更加合理地分布原图和词对应的注意力,新的注意力分布与输入的图像相乘,得到词对应图像的注意图(Attention_feature)。
3 实验设置
实验环境 本实验使用pytorch 作为深度学习底层框架,计算机内存为32 GB RAM、英特尔i7-6700K 四核八线程CPU以及NVIDIA-GTX1080Ti GPU,操作系统为Windows 10 64位。
3.1 评价指标
本文使用了多种评价指标:BLEU(Bilingual Evaluation Understudy)[15]、CIDEr(Consensus-based Image Description Evaluation)[16]、ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation)[17]和METEOR(Metric for Evaluation of Translation with Explicit Ordering)[18]。与此同时,本文列出了上述评价指标的计算公式。
3.1.1 BLEU
BLEU 用于比较候选译文和参考译文里的n-gram 的重合程度,重合程度越高就认为译文质量越高。pn中的n表示ngram,pn表示n-gram的精度。

式(2)中:BP表示长度惩罚因子,lc表示翻译译文的长度,ls表示参考答案的有效长度,当存在多个参考译文时,选取和翻译译文最接近的长度。当翻译译文长度大于参考译文的长度时,惩罚系数为1,表示不惩罚,只有机器翻译译文长度小于参考答案才会计算惩罚因子。
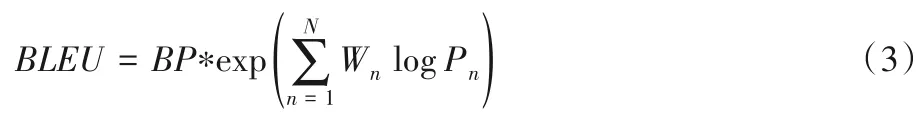
由于各n-gram 统计量的精度随着gram 阶数的升高而呈指数形式递减,所以为了平衡各阶统计量的作用,式(3)中对其采用几何平均形式求平均值然后加权,再乘以长度惩罚因子,得到最后的评价公式,n的上限取值为4,即最多只统计4-gram的精度。
3.1.2 ROUGE-L
ROUGE-L 计算的是候选摘要与参考摘要的最长公共子序列长度,长度越长,得分越高。

其中:X表示候选摘要,Y表示参考摘要,LCS(Longest Common Subsequence)表示候选摘要与参考摘要的最长公共子序列的长度,m表示参考摘要的长度,n表示候选摘要的长度,Rlcs和Plcs分别表示召回率和准确率。
3.1.3 CIDEr
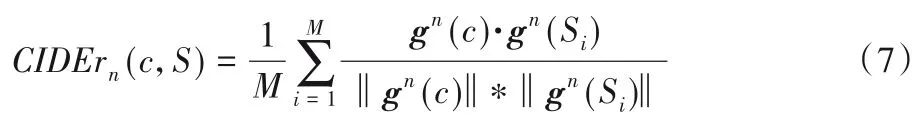
式中:c表示候选标题,S表示参考标题集合,n表示评估的是n-gram,M表示参考字幕的数量,gn(·)表示基于n-gram 的TFIDF(Term Frequency-Inverse Document Frequency)向 量。CIDEr 是把每个句子看成文档,然后计算其TF-IDF 向量的余弦夹角,据此得到候选句子和参考句子的相似度。
3.1.4 METEOR
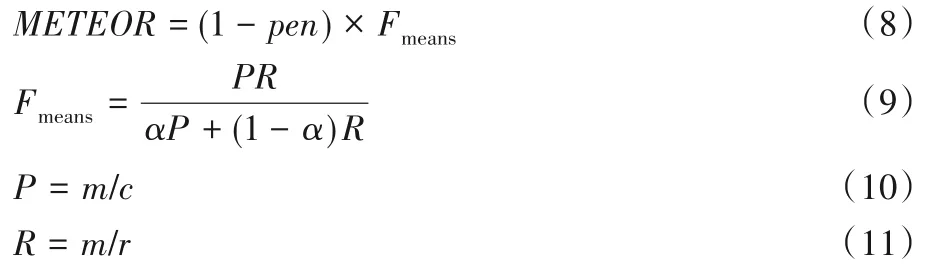
其中:α为可调控的参数,m为候选翻译中能够被匹配的一元组的数量,c为候选翻译的长度,r为参考摘要的长度。式(8)中,pen为惩罚因子,惩罚的是候选翻译中的词序与参考翻译中的词序的不同。
3.2 实验数据集
本次实验采用了Flickr8K[19]和Flickr30K[20]数据集,两个数据集都是一张图片对应5句描述自然语言句子,Flickr8K数据集约8 000 幅图像,Flickr30K 约30 000 幅图像,这两个数据集中的图像都是针对特定对象和动作的。如图3所示。

图3 某张图像对应的自然语言句子Fig.3 Natural language sentences corresponding to one image
3.3 参数设置
本文设置的词嵌入维度是512,LSTM 的输出维度为512,输入数据的batch size 为32。微调卷积神经网络,训练网络时,卷积神经网络的学习率设置为1E-4,长短期记忆网络学习率设置为4E-4。整个网络采用Adam 优化器训练,防止反向传播梯度爆炸,如果连续8 个epoch 评价指标都没有改善,则学习率降低为原来的0.8,并在20 个epoch 后终止训练,实验时在反向传播中加入了梯度截断,可以有效地避免梯度爆炸。损失函数使用的是交叉熵损失函数。在测试中使用集束搜索的方式,假设词汇表关联词汇beam size的大小为5。
3.4 实验结果及分析
在Flickr8K 和Flickr30K 两个数据集的比对实验中,数据集使用的是公共划分标准[21],使用数据集中的1 000张图像进行验证,1 000 张图像进行测试,其余用于训练。根据文献[21]可知数据集拆分的差异不会对整体性能产生实质性的影响。用传统的CNN+LSTM 网络和本文所使用的CNN+LSTM+ATTENTION 网络在上述的两个数据集上做对比实验,对图像描述的各项指标如表1所示。

表1 不同模型在Flickr8K数据集上的几种评价指标对比 单位:%Tab.1 Comparison of several evaluation indicators of different models on Flickr8K dataset unit:%
本文提出的注意力机制是通过对图像的特征和词的特征分组卷积,得到不同的注意力,再经过线性层整合这些不同的注意力,生成一个图像和词相关联的新注意力分布,将提出的注意力机制嵌入到传统的模型中,能更加准确地生成描述图像的自然语言句子。因此当选取的卷积神经网络为VGG19时,VGG19+LSTM+ATTENTION 比VGG19+LSTM 网络在指标上都有所提高,引入分组注意力的模型比传统模型的BLEU_4提升了1.08 个百分点,ROUGE_L 提升了0.91 个百分点,CIDEr提升了3.06个百分点。
从表1 可知,当卷积神经网络为更深、更复杂的ResNet101 时,ResNet101+LSTM 网络在各评价指标已经高于VGG19+LSTM+ATTENTION 和VGG19+LSTM 网络。在引入改 进 ATTENTION 的 ResNet101+LSTM 网 络 之 后,比ResNet101+LSTM 网络的评价指标有更加明显的提高,特别是,BLEU_4 和CIDEr 分别提升了1.94 个百分点和6.13 个百分点。在Flickr8K 数据集上引入注意力机制的VGG 网络和ResNet,通过各项指标的比较,验证了本文提出的注意力机制的可行性和高效性。为了进一步验证改进的注意力机制的高效性,在数据集Flickr30K 上做了相同的对比实验,实验结果如表2所示。

表2 不同模型在Flickr30K数据集上的几种评价指标对比 单位:%Tab.2 Comparison of several evaluation indicators of different models on Flickr30K dataset unit:%
传统的模型没有考虑到词和图片位置的关系,而本文所提的改进注意力机制,使模型能够关注到词和图像的对应位置,更加符合人类的肉眼观察机制,在较大的Flickr30K 数据集中,通过引入改进注意力机制模型和传统编解码模型这两种模型的对比,ResNet101 网络的各项指标比VGG19 网络有更为突出的效果,在该数据集上,引入改进的注意力机制ResNet101 和VGG19 网络在评价指标BLEU_4 上各提升了4.91个百分点和4.71个百分点。
在Flickr8K 数据集和Flickr30K 数据集中各自随机选取一张图像,并可视化描述语句对应该图片的注意力分布图,如图4和图5所示。

图4 Flickr8K数据集中单词对应的注意力热力图Fig.4 Attention heat map corresponding to words in Flickr8K dataset

图5 Flickr30K数据集中单词对应的注意力热力图Fig.5 Attention heat map corresponding to words in Flickr30K dataset
改进的注意力模型根据对语句中当前单词和图像关注到接下来需要描述的图像部分,将局部注意力映射到原图中,模型中分支的3×3 卷积和1×1 卷积可以分别关注词对应的不同局部特征,再连接分支的不同局部特征输入到全连接后,得到词对应多个存在关联的局部特征区域即注意力分布,不仅有效地减少特征的冗余,而且得到多个局部注意力特征。
表3 中Google NIC 模型是首次提出图像描述生成的编码-解码基本框架,图像描述生成任务中引入这样的架构已成为主流。注意力机制的基本思想是利用卷积层获取图像特征后,对图像特征进行注意力加权,之后再送入RNN 中进行解码,表3 中 的SCA-CNN-VGG(Spatial and Channel-wise Attention in Convolutional Neural Networks)模型是用通道注意力和空间注意力结合的方式来进行图像描述生成,Hard-Attention 是即将图像中最大权重置为1,而将其他区域权重置0,以达到仅注意一个区域的目的,双向单注意力网络和双向双注意力网络都是近年对注意力较新的改进,ATTENTION 机制已经成为一种主流的模型构件。
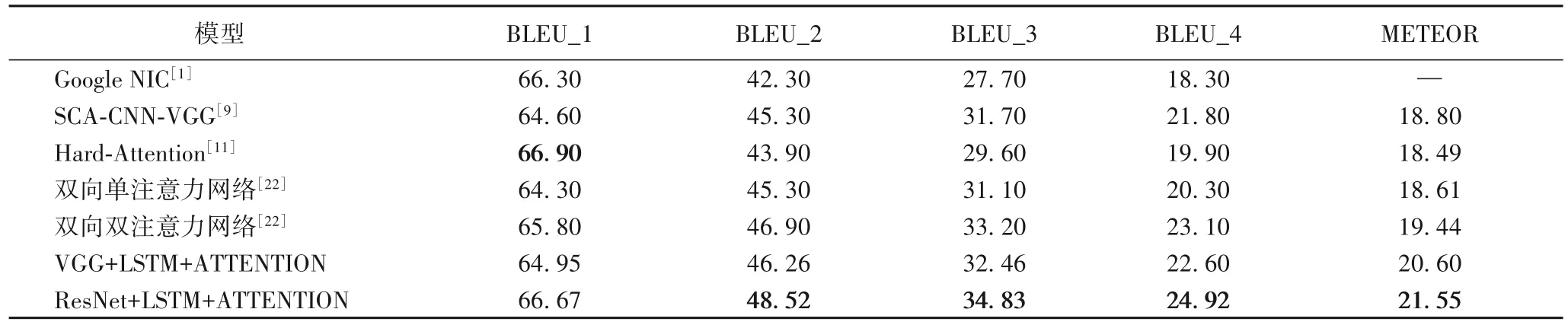
表3 所提模型与其他模型几种评价指标对比 单位:%Tab.3 Comparison of several evaluation indicators of the proposed model and other models unit:%
由表3 可知,有注意力机制的模型比Google NIC 指标都有比较明显的提升,ENCODER 模块是使用相同的卷积神经网络,DECODER 模块是使用相同的长短记忆元网络,保证了实验的合理性和公平性。本文提出的改进注意力机制通过分组卷积注意力,更合理地分布原图和词对应的注意力。相对于其他的注意力模型,进一步提升了准确率,说明本文改进的注意力机制能更有效地筛选有用特征作为长短记忆元网络的输入,表3中所有的模型都在Flickr30K数据集上验证,表明本文改进模型有较好的泛化性。随机选取Flickr8K 数据集和Flickr30K的示例图分别为图6和图7,对比传统模型和改进模型对图像描述生成效果。

图6 Flickr8K示例图片对应的自然语言句子Fig.6 Natural language sentences corresponding to Flickr8K sample image

图7 Flickr30K示例图片对应的自然语言句子Fig.7 Natural language sentences corresponding to Flickr30K sample image
传统模型(ResNet101+LSTM)生成的自然语言句子:
a man in a blue jacket is sitting on a wooden bench.
改进模型(ResNet101+LSTM+ATTENTION)生成的自然语言句子:
a man in a red jacket is sitting on a bench.
传统模型将图片中的红色夹克信息生成了错误的蓝色夹克信息,而改进模型准确地生成了红色夹克信息。
传统模型(ResNet101+LSTM)生成的自然语言句子:
a little girl in a pink shirt is playing with a hula hoop.
改进模型(ResNet101+LSTM+ATTENTION)生成的自然语言句子:
a little girl in a pink shirt pushing a green stroller.
传统模型对Flickr30K 示例图片中生成了错误的呼啦圈信息,而改进模型准确地生成绿色的婴儿推车信息。
在Flickr8K 数据集和Flickr30K 数据集中,ResNet101+LSTM 生成的语句中存在一些错误,翻译得不是很准确,而ResNet101+LSTM+ATTENTION 模型能较为准确地翻译图片内容,且基本没有语法错误。
4 结语
本文提出了一种基于CNN 和LSTM 且引入了改进的注意力机制的网络模型,采用了经典VGG19 网络以及具有更深层的ResNet101网络对图像进行特征编码,通过用EMBEDDING对自然语言句子的词进行词编码进而得到词向量,经LSTM将特征向量和词向量映射到同一空间中,在引入改进的注意力机制作用下,使图像信息引导生成与图像更加符合的自然语言句子,同时也提升了本文所提出的模型的鲁棒性。实验结果表明,本文提出的模型泛化能力明显更好一些,在图像描述生成的自然语言句子和评价指标上都优于传统的模型。
