基于边缘计算的故障录波主站信息快速智能处理方法
2021-06-30巫聪云刘斌沈梓正颜丽廖晓春
巫聪云,刘斌,沈梓正,颜丽,廖晓春
(1. 广西电网有限责任公司,南宁530000;2. 武汉华电顺承科技有限公司,武汉430071)
目前电力系统处于大力发展以“控大智移”为目标的阶段,具备继电保护设备信息集成能力的各种系统,注重中心化,将各种数据、信息和资源归集至调控机构,造成传输网络开销大和信息处理延迟的问题,无法满足电网快速发展业务形态的需求。
随着电网规模的持续扩张,录波装置作为基础配套设备,其数量快速增加,录波数据呈爆发式增长,海量录波数据的快速处理成为亟待解决的问题。分析录波数据,发现其存在以下特点:(1)价值密度低:故障数据占比仅为2%;(2)海量骤发性:故障发生时,多个录波装置监测点集中产生海量数据并同时上送,瞬间冲击主站通信、存储和计算资源,考验主站服务器的承载能力;(3)多源异构:异种录波装置产生格式各异的数据,在数据传输过程中出现信息丢失、上传失败等问题。对海量、异构、骤发录波数据稳定传输、快速存储、提炼出2%故障数据高效诊断的研究,具有极大的价值。
近年来,边缘计算的出现,可减轻云计算中心的负荷,减少网络链路数据传输压力,降低实时性数据处理时延。为了缓解信息中心调控机构的压力,可利用录波主站对海量数据进行预处理,筛选出故障信息进行分析,电子化报送故障报告,支持调控机构直接决策,将调控人员从繁琐的信息处理工作中解放出来。
本文通过研究调控机构在电网事故实际处理过程中存在的问题,结合边缘计算对数据高效处理的特点,提出一种基于边缘计算的故障录波主站信息快速智能处理方法,将大量的故障诊断任务下放到录波主站系统进行处理,满足海量录波数据场景的实时处理需求,提高电网故障的诊断效率。
1 基于边缘计算的录波信息快速智能处理设计原理
传统故障信息处理模式为调控机构进行故障信息的集中式管理,但调控机构处理信息压力大、人工干预程度高、故障决策延迟问题频发,在故障信息的实时处理方面已呈现局限性。
基于边缘计算的录波信息快速智能处理模式设计原理如图1 所示,录波主站作为调控机构边缘的故障信息处理系统,不再局限于信息传递,而是具备扰动数据筛选、故障数据高效诊断和信息快速发布的能力,对厂站侧上送的扰动数据,快速进行数据分析和故障诊断工作,直接将故障信息的分析报告电子化报送至调控机构,可实时处理海量录波数据,极大程度缓解调控机构信息处理压力和缩短故障决策时延。

图1 边缘计算设计原理图Fig.1 Edge computing schematic diagram
2 故障录波信息处理的边缘计算框架
故障录波信息的边缘计算框架如图2 所示,从设备、网络、数据和应用四域,利用异步通信、分布式存储和故障快速诊断等技术,实现对海量录波数据的并行处理,提供芯片级的诊断服务并电子化报送故障结果,提高录波主站系统的综合处理能力,降低实时性数据的处理时延,全面促进电网故障录波信息处理模型的持续优化生长。
1)设备域

图2 故障录波信息的边缘计算框架Fig.2 Edge calculation framework of fault recording wave information
设备状态:主要涉及安装在厂站侧的所有录波装置,负责监视电力系统一次设备的正常运行,当线路发生扰动或故障时,正常启动并记录模拟量和开关量的变化情况。
源端信息:将采集到的故障电压、电流信号经过隔离、变送、A/D 转换后,形成COMTRADE 格式连续的数据量,按照通道配置和时标转换成故障波形,清晰再现整个故障过程。
2)网络域
海量数据传输:录波主站提供通信接口,与调度数据网建立网络连接,采用实时通信方式,提高海量录波数据的通信效率。
网络风暴抑制:通信网络服务器故障、网卡损坏、网络环路等原因造成的网络风暴,配置风暴抑制特性进行预防,避免网络丢包、响应迟缓、时断时通、瘫痪等问题的发生,提高网络性能。
信息安防:录波主站具有网络通信和数据处理能力,将录波数据进行过滤和处理后传输,可有效保护敏感数据不被上传到网络中,保证数据的安全及隐私。
3)数据域
海量数据存储:利用分布式的存储方式,扩展录波主站海量数据的存储性能,提高资源利用效率,达到各存储节点资源的动态平衡。
数据融合与快速诊断:建立录波数据的独立分析诊断机制,主站系统对同故障多来源的录波数据深入挖掘,结合获取到的开关量,进行故障信息融合和快速诊断,生成录波故障报告。
事故复盘:保留所有电网相关业务数据,包含原始数据和故障报告、设备运行有效日志等信息,在检索线路故障、设备故障及历史回溯等场景时进行信息调取和查看,对电网事故复盘,避免同类问题再次发生。
4)应用域
报告发布与直接决策:录波主站系统将生成的故障报告通过电子化报送方式推至Web、云平台和移动终端,实现便捷式故障信息查看,支撑调控机构直接决策。
策略机制管控:设计基于边缘计算的录波故障信息处理策略和共享管控机制,在保证安全性的同时,优化信息处理机制,提高信息共享的范围和深度,面向调度、检修和运行等人员实现电网故障信息利用价值的最大化。
3 基于边缘计算的故障录波信息快速智能处理关键技术
设计故障录波信息快速处理的边缘计算框架,其目的就是从设备、网络、数据和应用四域对录波数据进行智能监控、高效处理和有效利用,降低数据传输网络开销。现阶段重点工作是如何解决录波数据实时通信传输稳定、数据存储和调取便捷以及故障信息快速挖掘和诊断的问题,这是基于边缘计算的电网故障录波信息快速处理方法研究中的关键。
3.1 基于DataSocket的异步并行实时通信网络
录波主站系统通信端口与厂站侧录波装置之间通过调度数据网进行大量的通信工作。主站系统自有规约库,可根据当前主流厂商规约的特性,将非标规约自适应转换成电力系统自动化领域唯一的全球通用标准IEC 61850,对异种录波装置具有极高的兼容性。然而传统主站服务器局域网TCP/IP 通信方式因编程的复杂性,存在网络链路不稳定导致数据传输失败的问题,无法满足在高频通信情况下数据实时传输的需求。
基于DataSocket 的异步并行实时通信网络设计如图3 所示,DataSocket 通信方式能够有效地将厂站侧录波装置采集到的大量数据转化为适合于主站通信网络传输的信号,DataSocket 包含DataSocket API 和DataSocket Server,前者提供独立的编程接口,适应不同编程环境下多种数据类型的通读,后者通过封装底层TCP/IP 协议进行统一管理来控制数据的发送和接收,简化了网络通信方式,且数据传输准确可靠。

图3 基于DataSocket的异步并行实时通信网络设计Fig.3 Design of asynchronous parallel real-time communication network based on DataSocket
基于DataSocket 的分布式实时通信网络,充分利用DataSocket API 提供的传输信道资源,不受限于数据格式的差异和网络间通信协议的不同,利用异步并行方式将通信开销时间进行量化,合理分配每条传输信道的通信时间,为实时性要求高、传输性能要求可靠的录波主站系统的数据通信和集成提供便利,将通信开销维持在最小范围内,有效解决录波主站在海量骤发录波数据传输中通信开销大的问题。
3.2 基于Hadoop的故障录波信息分布式存储
Master/Slave 架构的HDFS(Hadoop Distributed File System)系统可用于分布式数据存储,一个名字节点(NameNode)和多个数据节点(DataNode)组成一个HDFS 集群,分别负责分配文件存储位置和存储实际数据。
HDFS 系 统通过 NameNode High Availability 机制可启动两个Namenode,一个处于active状态,负责所有的客户端操作,另外一个处于standby 状态,负责维护数据状态,具备随时切换的条件,其作用是降低Namenode 并发访问时单点失败的风险,形成彼此协同的处理模式。
HDFS 分布式存储示意如图4 所示,系统中数据存储不受单一节点磁盘大小的限制,可将录波文件分散存储到集群的各个节点,而且采用副本存放与读取策略,备份文件分布于不同的DataNode,具有较高的容错性。

图4 HDFS分布式存储示意图Fig.4 Flow chart of HDFS distributed storage
相较于传统Oracle 数据库的存储仅集中于一台物理服务器节点,磁盘写入时间随存储数据量的不断增加呈线性快速增长而言,HDFS 分布式存储优势整理如下:
1)HDFS 节点管理性能:存储着HDFS 文件系统目录树和录波数据操作日志的fsimage 和edits 大小直接影响NameNode 的启动速度,Active Na⁃meNode 通过 HTTP 从 Standby NameNode 获取最新的fsimage 文件命名为fsimage.ckpt_txid,并生成MD5 文件,与 Standby NameNode 的 MD5 值比对校验,在确认收到的fsimage 文件正确后将其重命名为fsimage_txid,并清理掉旧的fsimage 和edits 文件,以此确保 Standby 和 Active 2 个 NameNode 都拥有最新的fsimage 和edits 文件,从而增强2 个节点协同管理的性能。
2)信息存储的安全性:对所有录波数据复制相同的3 个副本,通过机架感知的策略,将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上,3个副本有序分开保存于不同的存储节点,在提高写操作效率的同时,也保证了数据的安全性。
3)信息调用的可靠性:DataNode 的存储设备错误、网络错误或者软件bug 可能造成从某个DataNode 获取的数据块是损坏的,在调用数据时,可对文件的内容进行checksum 检查,通过check⁃sum 一致性匹配,确认是否为目标调用数据,如果不一致,可选择从其他DataNode 获取该数据块的副本,减少损坏数据误用的发生,提高信息调用的可靠性。
4)信息存储的利用率:HDFS系统文件切分后分散存储至不同的DataNode,满足流式访问数据读取需求,响应不同任务请求,按录波启动时间进行数据有序存储,提高存储数据的使用频率。
存储数据库分为静态和动态两部分,静态数据库保存电网拓扑结构、录波装置规格和属性等信息,一次写入可供多次读取,后期维护量小;动态数据库用来记录故障录波波形的变化,数据存储量大,采用基于Hadoop 的录波信息分布式存储方法,可以快速保存、检索和调用启动时间序列相似的录波数据。
3.3 基于改进SSDA 算法的故障录波信息并行智能诊断
3.3.1 故障录波信息的预处理
1)智能容错:读取录波文件,查验文件中装置ID、线路名称、模拟量和状态量通道采样信息、线路两侧的CT/PT 变比等不可或缺的信息是否齐全。若信息不全或出现乱码,调取含有错误类型相对应的补偿信息列表,予以信息补充或更正。对录波文件中经常发生的数据缺失、异常或不识别等问题进行智能容错处理。
2)无损转换:不同厂商、不同型号录波装置采集的故障文件格式各异,通过录波文件查询对应的录波装置型号,获取对应的文件格式转换接口表,解析文件格式并读取文件数据,最终将不同格式的录波文件转换成标准的COMTRADE 格式的数据文件。将不同采样率的波形通过拉格朗日插值法进行采样率归一化处理,便于后续对录波波形快速诊断。
3.3.2 基于改进SSDA算法的录波信息并行诊断
故障录波数据可靠,但信息量大,需要从海量录波数据中提炼出2%的故障信息,传统队列式串行分析不利于故障信息的快速识别。
波形在某种程度上可以视为特定的图形,只需要提取疑似故障段波形,将故障波形匹配问题转换为直观的图像匹配问题进行简化。序贯相似度检测匹配法(Sequential Similarity Detection Algorithms,SSDA)最主要的特点是图像匹配处理速度快。
基于改进的SSDA 算法的故障录波信息快速智能诊断详细流程如图5所示,关键步骤介绍如下:
1)建立故障波形库,记录常见电网故障(单相接地、两相短路、两相接地、三相短路)波形特征信息。
2)并行计算目标波形和故障库波形之间的绝对误差:(,) =|S(,) -(,)|。
式中:S(,)是故障波形库中第个波形中的点;(,)为目标匹配波形中的点。
3)将故障库波形当作模板,计算波形库中波形模板与目标待匹配波形点的绝对误差,并将每一点的误差累计,计算残差和,作为初始阈值T。
4)阈值选取对于算法的精度有较大影响,若阈值较大,运算速度较慢;阈值过小,匹配精度会降低,故采用改进后的自适应阈值进行阈值更新。将故障库波形模板不断移动,记下一个匹配区域的残差和为T,如果T≥T,则搜索完成;如果T< T,则用T来更新T,并记录该区域起始点位置坐标,当目标波形搜索完成,则可得目标匹配波形的最佳匹配结果,记录累加次数r。

图5 基于改进的SSDA算法的故障录波信息快速智能诊断Fig. 5 Fast and intelligent diagnosis for power grid fault based on improved SSDA algorithm
5)并行计算故障库中波形和目标波形的匹配 集 合 {,,...,r}, 最 终 的 匹 配 结 果=max{,,...,r},即使得阈值最小且累加次数最多的波形即为最终的故障匹配结果。
对于大部分非匹配点来说,只需计算波形中的前几个点即可算出残差和超过阈值,波形不具有故障特征。只有匹配点附近的点才需要扩宽计算,这样平均起来每一点的运算次数将远远小于实测波形的点数,从而达到减少整个波形匹配过程计算量的目的。
采用SSDA 算法并行匹配故障库常见故障波形,可以满足90%常见故障快速诊断的需求。对于剩余10%特殊故障或复杂故障无法快速识别的情况,可以利用与其他主站交互的信息进行交叉验证或采用D-S证据理论进一步融合诊断故障。
4 应用实例
为了验证DataSocket 实时数据通信传输的稳定性,在实验室局域网利用5 台录波装置、2 台PC 组建数据采集(发布端)、DataSocket server 和测控应用(接收端)3 部分,采用南瑞NEP4A-E1 2 M 通道复用装置模拟调度数据网2 M 专线进行录波数据传输,为增强系统的安全性,可以在计算机之间用防火墙隔离。
利用IEEE 39 节点系统Simulink 软件对高压输电线路进行仿真,利用5 台录波装置监测仿真产生的故障信号,采集到的5 000 个实时数据通过2 M通信通道传输方式发送到DataSocket server,不同类型的数据写入不同路径,接收端从相应的路径中取出数据,实现分布式数据的实时通信和监控。通过客户端监控显示,通过2 M 通信通道传输的数据发包率和接收成功率均为100%,表明利用Data⁃Socket异步并行方式可实现通信数据稳定传输。
基于Hadoop 集群和Oracle 数据库两种存储方式,在存储硬件配置基本一致的前提下,进行录波数目量级递增情况下数据读写响应时间的对比实验,两种存储数据库的硬件环境如表1所示。

表1 Hadoop和Oracle存储数据库配置Tab.1 Data base configuration of Hadoop and Oracle storage modes
以广西电网历史库中录波数据作为研究对象,选取 100、1 000、10 000、20 000、40 000、60 000、80 000、100 000 个大小为0.5~5 MB 录波文件,分别采用传统Oracle 与文中所提分布式Hadoop 集群两种方式进行数据存储实验,最终取3 次存储响应时间的平均值,记录结果如图6所示。

图6 Hadoop与Oracle存储方式响应时间的比较Fig.6 Response time comparison of Hadoop and Oracle storage modes
从图6 可以看出,当文件数量较少时,Oracle存储效率比较高,原因是Hadoop 集群存储方式涉及到节点的选取,系统自身开销导致存储响应耗时较长,随着存储数据量的逐步增加,在超过临界点10 000个以后,Oracle存储方式响应时间快速增长,而Hadoop 通过内部节点协同和分配处理机制,使得数据写入和读取所需时间显著缩短,在海量录波数据的存储效率方面显示出了绝对性的优势。
录波数据实时传输和分布式存储都是服务于录波数据快速诊断,基于改进的SSDA 算法进行波形匹配,阈值T的选取非常关键,本文采用自适应阈值方法,初始阈值T设定在0.4 附近,避免搜索过早结束,匹配过程中不断自适应修正阈值,将目标波形与故障库波形模板进行快速匹配,较少的时间就可以完成海量录波数据诊断工作,挖掘出2%故障信息中的常见故障。相较于传统方法故障特征量提取和精细分析来说,基于改进的SSDA 算法更适合于价值密度仅2%的故障录波数据快速分析,可以提高故障诊断效率。表2 整理了传统和边缘计算两种架构的海量录波数据处理的指标对比数据。
从表2可以看出:
1)录波数据量级递增,导致传统架构主站性能大幅度衰减,当录波数据冲击量达到100 GB/min时,已接近传统主站系统的性能极限,但基于边缘计算架构的主站系统可继续维持系统稳定。
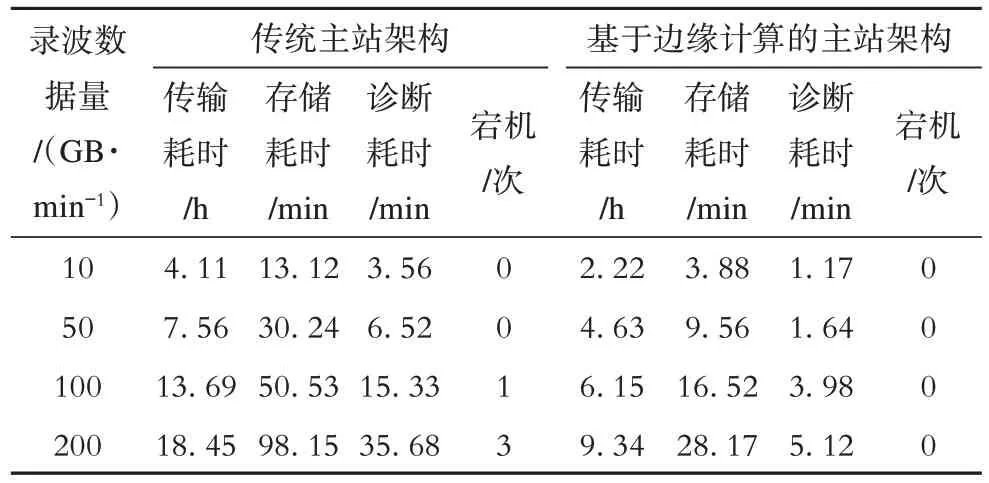
表2 传统和边缘计算架构海量录波数据处理的对比指标Tab.2 Comparison of edge computing and traditional architectures for processing mass recording wave data
2)数据存储和诊断耗时受存储方式和诊断算法的影响较大,分布式存储和并行诊断方法的应用可以大幅度缩减用时,但数据传输速率受网络带宽限制,虽然采取DataSocket 实时通信方式,传输速率有所提升,但在海量数据骤增的情况下,网络开销仍相对较大,是主站系统故障分析耗时的瓶颈。
5 结 论
基于边缘计算的故障录波主站信息快速智能处理方法,利用DataSocket 异步并行实时通信方式进行数据稳定上送;采用Hadoop 分布式存储保证各个存储节点的动态平衡,便于数据的快速写入和调取;利用改进的SSDA 算法快速筛选故障数据,常见故障可以高效匹配判定,电子化报送故障报告支持调控机构直接决策。实验证明,该方法在数据稳定传输、高效存取和故障快速诊断方面有良好的应用效果,缓解了调控机构信息处理的压力,解决了数据传输开销大和故障决策延时的问题。
由于网络通信数据传输是录波主站故障快速诊断中的瓶颈,受网络带宽影响较大,后续将从源端录波数据处理着手,进一步优化厂站侧海量录波数据的传输策略,提高录波数据实时通信效率。
