人大报告内容的文本分类
2021-06-28李红莲吕学强
喻 航,李红莲,吕学强
(1.北京信息科技大学 信息与通信工程学院,北京 100101; 2.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引 言
各级人大在不断完善自身的工作方式,在人大建设的过程中,信息化建设[1]越来越受到工作人员的重视。人大相关工作的总结,所需要的信息量巨大,类别广泛,想要准确找到相对应的工作内容,检索起来并不容易。所以,人大报告辅助生成系统的建立,就需要对文本分类,把文本分成不同的内容写入报告。
文本分类技术是自然语言处理学科领域中一项基本技术[2]。传统机器学习中一般采用Naive-Bayes分类[3]、KNN[4]、SVM[5]、逻辑回归[6]或者随机森林[7]等分类方法。应当依据具体情况来挑选适当的文本分类器。如果遇到巨大数据量,特征向量也非常多时,就要用到神经网络的深度学习模型。
本文对人大报告中必要的两大部分进行文本分类,监督工作和代表工作是每年人大报告中最重要的两大部分,其相关工作内容的资料在收集时较难区分资料的所属类别,用结合TF-IDF的ERNIE文本分类模型可以帮助人大工作人员,在众多的资料中快速准确地分辨监督工作和代表工作。采用了加入TF-IDF的ERNIE模型对人大报告文本分类,其准确率、召回率和F1得分有所提高,收敛速度明显加快。
1 文本分类流程
人大报告的写作内容较为固定。有以下特点,人大报告篇幅长,特征词汇多,篇章结构格式鲜明。在分类之前先对文本预处理。预处理之后进行特征提取。人大报告都是中文语料,ERNIE模型处理中文语料效果好,选用此模型来训练分类器。本文对人大报告中的监督工作和代表工作分类的框架如图1所示。
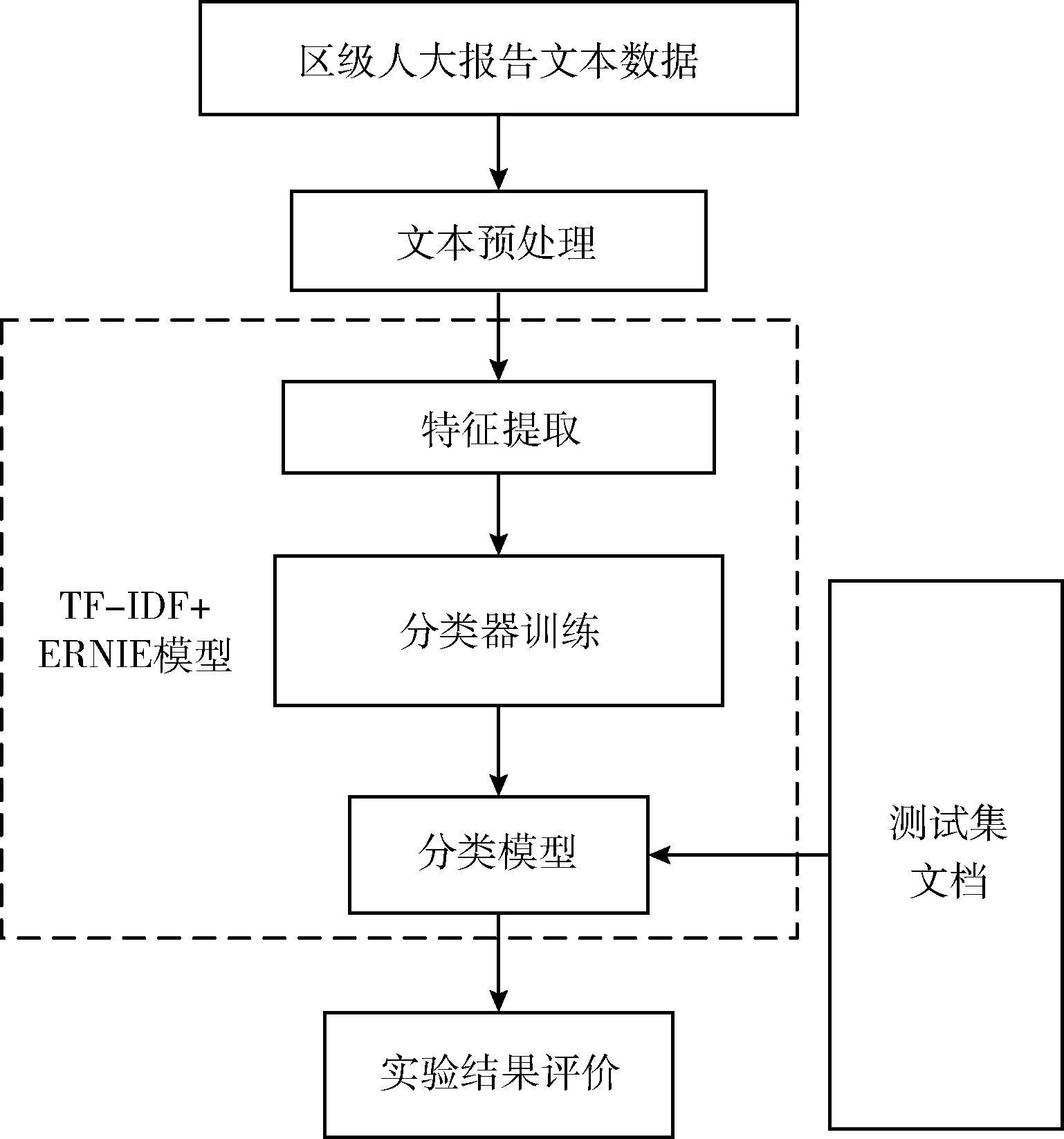
图1 文本分类过程
1.1 数据预处理
本文以人大报告中监督工作和代表工作的相关内容作为训练集和测试集。做文本分类工作,对数据进行预处理是必不可少的过程。对于中文文本而言,数据预处理包括:中文分词、词性标注(如果分类需要词性特征)、去停用词等等。其中的分词是把文本分解成词语的集合,去除停用词是用来去掉一些没什么含义的词语,会对分类产生影响的词,比如:你、我、他、的等等。本文对人大报告的预处理步骤如图2所示。
1.2 基于TF-IDF的特征提取
加入特征提取,就是提取想要用作分类的特征,具体包括TF-IDF计算[8]、n-gram[9]、word2vec[10]、LDA[11]等。本文选用TF-IDF对词向量进行加权平均,其中TF-IDF特征能够在一定程度上表现词的重要性,TF计算的常用式为
(1)
式中:nij表示词i在文档j中的出现频次。IDF计算的常用式为
(2)
式中:|D|为文档集中总文档数,|Di|为文档集中出现词i的文档数量。分母加一是采用了拉普拉斯平滑,以规避出现部分新词没有出现在语料库中导致的分母为0的情形,使算法增加了健壮性。综合使用公式为
(3)
这些作为基于TF-IDF提取出来的特征,作为额外的特征输入。
2 ERNIE
本文提出了一种在ERNIE模型[12]中加入TF-IDF提取的特征来进行区级人大报告内容的文本分类工作。
2.1 Self-Attention机制
ERNIE模型,其建模过程中利用了多头自注意力机制(multi-head attention),来算一个句子中的每个词和这句中其它词的相互联系,Self-Attention机制在本质上是在网络的各个部位对输入向量进行加权,由此表示输入文本中不同词语特征对文本分类的不同影响力。文本的特征表示计算公式如下
at=Wxt
(4)
(5)
(6)
{x1,x2,…,xp}是输入的词向量序列,t=1,2,…,p。每个词向量都通过变换映射出q、k和v这3个矩阵,其中,d的取值为q的维数,然后使用归一化函数计算权重s1,t,把每个权重和对应向量相乘再累加求和就得到第一个词的向量。
2.2 ERNIE模型
ERNIE的建模方式与其它模型相比,可以更好捕捉中文之间的关系。如图3所示,对于朝[MASK]区,通过“朝”与“区”局部的字词搭配,就能够较为容易地推断出掩码字为“阳”,但是,模型却没有学习与“北京市”相关的知识。而ERNIE通过引入对词的整体遮蔽,使模型能够从更长的距离建模出“朝阳区”与“北京市”的关系,学到“朝阳区”是“北京市”的一个行政区以及“朝阳区”是一个举办过奥运会的城区。
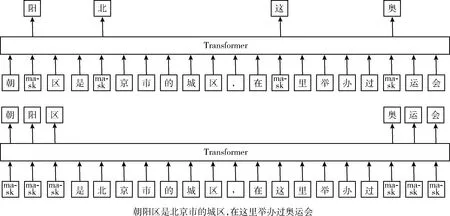
图3 建模方式
在预训练时,把知识图谱的实体通过知识嵌入法与单词相匹配,完成实体对齐任务。在预训练的基础上,ERNIE模型随机mask单词,除了用本地上下文预测单词之外,还加入了实体信息,通过加入的实体信息可以预测单词并学到词之间的语义关系。
ERNIE的整个模型架构由两个堆叠的模块构成:①文本编码器(T-Encoder),如图4所示,负责从文本中捕获基本的单词和语义信息;②知识型编码器(K-Encoder),如图5所示,负责把额外的知识图谱信息整合到来自T-Encoder的文本信息中,这样就可以在一个统一的特征空间中表示词汇信息和实体的信息了。其中,用N表示T-Encoder的层数,用M表示K-Encoder的层数。

图4 T-Encoder文本编码器
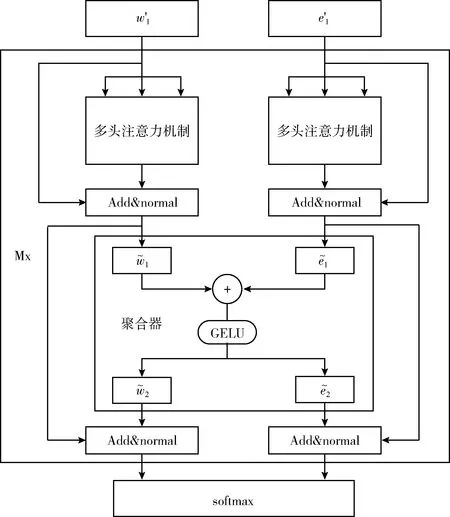
图5 K-Encoder知识型编码器
在T-Encoder这一部分的工作中,首先对词嵌入向量、句嵌入向量、位置信息向量进行对应相加,作为T-Encoder的输入,也就是图4中的输入。然后再计算词法和语义特征,计算公式为
{w′1,…,w′n}=T-Encoder({w1,…,wn})
(7)
式中:{w1,…,wn}为n个输入词语。
在K-Encoder这部分中,通过知识图谱嵌入法(TransE)将实体{e1,…,em}转为对应向量表示{e′1,…,e′m}。然后将{e′1,…,e′m}和{w′1,…,w′n}作为K-Encoder的输入,计算公式为

(8)
2.3 TF-IDF+ERNIE人大报告分类算法
综上所述,本文所提TF-IDF+ERNIE对人大报告内容分类的算法,步骤如下:
步骤1 用TF-IDF算法首先对训练集进行特征词抽取,并将得到的特征词ti作为额外的特征输入。
步骤2 把训练集进行预处理,得到经过预处理的训练集D={(x1,y1),(x2,y2),…,(xp,yp)},其中,xp是经过预处理的人大报告文本,yp是每段经过预处理人大报告所属类别,p=1,2,…m。
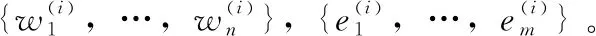
步骤4 将得出的特征表示输入进Softmax模型中,对人大报告文本进行分类。
3 实验以及结果分析
3.1 实验环境
本实验的实验环境为Intel Core i5-8250U处理器,主频为1.6 GHz,内存为8 G、64位的PC电脑。操作系统为Windows10,编程使用Python语言,编译环境使用JetBrains PyCharm Community Edition 2017.3.4 x64。
开发平台为PyTorch 1.1.0,此外,主要用到的工具包还包括numpy等等。
3.2 数据集和参数设置
为测试此项文本分类方法的性能,本次使用全国20个城市所属的各个区县的人大报告数据进行实验。本次的数据集包含了从2009到2019年一共5584段报告内容,实验用4472段作为训练集来训练模型,使用1112段语料作为测试集测试性能好坏。实验数据分布见表1。

表1 区级人大报告分类实验数据
在ERNIE神经网络模型中,不同参数的设置对最后得到的实验结果影响很大,所以通过参阅相关文献,对参数进行微调,本次实验使用的主要参数见表2。
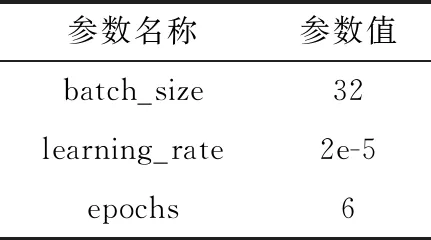
表2 ERNIE分类模型主要参数
3.3 评价指标
对本文的文本分类的方法进行评价,使用准确率(Precision)、召回率(Recall)并且使用F值(F-Measure)来对模型进行综合评价。其中,准确率和召回率是检索(IR)系统中的概念,也可使用于对分类器的性能进行评价。将正确分到某类的文本数记为A,错误分到该类别的文本数记为B,把错误地分到了其它类的文本数记为C。其中,各个指标的计算公式如下
(9)
(10)
(11)
准确率和召回率是相互影响的,一般情况下准确率高、召回率就低;召回率低、准确率高。指标P和R有时可能出现矛盾的情况,这就需要将它们进行平衡,最常见的方法为F1-Measure(又称为F1-Score)。F1-Measure是Precision和Recall的加权调和平均。
3.4 结果分析
为测试模型的有效性,实验使用多种方法进行比较,对比实验是在分类器之前,采用不同方法对文本提取特征,分别为基于词袋模型特征的方法,以及基于TF-IDF的方法来计算特征权重,对比模型使用的3种分类器分别为贝叶斯、逻辑回归和支持向量机,对人大报告中的监督工作和代表工作进行分类。8组实验都是在同一个数据集上进行实验。文本分类的结果见表3和表4。

表3 监督工作分类结果/%

表4 代表工作分类结果/%
通过实验结果可以看出,基于ERNIE模型进行区级人大报告内容的文本分类方法,相较于贝叶斯、逻辑回归和SVM,在准确率、召回率和F1得分上都有大大提升。传统的分类器,性能都远远落后于ERNIE。由于ERNIE在T-Encoder和K-Encoder里都引入了多头注意力机制,注意力机制更加强化了重点信息的权重,从而可以在特征选择方面取得更出色的效果。
此外,ERNIE模型输入是以词为单位,标记的内容也是以词为单位,不但利用局部上下文预测标记,而且同时学习了上下文和知识图谱的信息,通过预测标记,来构建的知识化语言模型。所以该模型可以充分利用词语、句子和知识信息,通过对知识图谱的利用,能更全面对语言进行理解。
使用ERNIE模型进行监督工作和代表工作的文本分类时,加入TF-IDF提取出的特征作为额外补充后,加快了模型的收敛速度,提升了其准确性。
为了更全面展示基于TF-IDF的ERNIE模型在算法收敛性上的优越性,记录了ERNIE模型和TF-IDF+ERNIE模型不同Epoch下的损失值情况,ERNIE模型和TF-IDF+ERNIE模型的损失值变化分别如图6和图7所示。

图6 ERNIE模型的损失值变化

图7 TF-IDF+ERNIE模型的损失值变化
两种方法的训练集和测试集的损失值在第2个Epoch都有明显下降。在测试集上两个模型的损失值对比如图8所示。其中,ERNIE模型在第6个Epoch上达到了0.1080。而TF-IDF+ERNIE模型在第6个Epoch上就达到了0.1024,其收敛速度快,模型计算效率高。

图8 损失值对比
总之,通过实验结果数据可以得出结论,本文提出基于TF-IDF加ERNIE模型的文本分类方法,在区级人大报告的内容分类工作中得到了不错的效果,该方法在准确率、召回率和F1得分上都有明显提升。将不同模型的分类效果进行结果比对,部分分类结果对比见表5。

表5 分类结果对比
其中,TF-IDF+ERNIE对这6段文本的分类预测为监督和代表工作的概率分别达到了96.69%、96.40%、95.33%、95.23%、94.93%、94.78%,由此可以看出该模型的分类效果不错。
4 结束语
本文将基于TF-IDF的ERNIE模型应用于区级人大报告内容分类,通过对监督工作和代表工作这两部分内容进行分类实验,验证了基于TF-IDF+ERNIE模型的优越性和有效性。在同一个数据集下TF-IDF+ERNIE模型与ERNIE、传统的贝叶斯、逻辑回归和SVM分类器模型进行实验比对,表明了ERNIE模型不但学习了上下文的语义特征,还考虑了知识图谱的信息,能够理解连续词语的相关关系。使得最大程度地理解了文本的原始信息,通过TF-IDF加入额外特征让模型收敛更快。虽然模型引入了TF-IDF,但是加入的特征还比较单一,导致在实验过程中的训练时间还是无法与传统学习方法的速度相媲美,以后还可以研究更多方面的特征。此外,由于语料的限制,算法性能还可以继续提升。总之,区级人大报告内容的文本分类是一个重要且很值得投入研究的方向,针对智慧人大的研究还很少,有许多工作都需要继续完善。
