一种基于双通道残差的场景文本检测方法∗
2021-06-28刘建云李海山
刘建云 李海山 李 恒
(武汉数字工程研究所 武汉 430000)
1 引言
场景文本检测在深度学习领域可被视为计算机视觉中物体检测任务的特定物体检测,也就是说将文本作为一种特定的物体来检测。基于深度学习的文本检测方法按照网络输出的数据分为基于边框回归的方法和基于语义分割的方法。基于边框回归的文本检测方法,如 CTPN[1]、SegLink[2]等,其检测效果严重依赖于锚框或者锚点的选择,导致模型中超参数的数量增加,降低了模型的泛化能力。而 PSENet[3]、DBNet[4]等网络采用语义分割的方法根据图片生成二值图,然后根据二值图生成文本框,因而检测结果更加鲁棒。为了提高检测算法对于自然场景图像中任意形状文本的鲁棒性和检测精度,本文提出了一个以ResNet[5]为基础网络,同时利用特征金字塔(Feature Pyramid Networks,FPN[6])进行特征融合,最后利用双通道残差网络进行语义分割的检测算法。该方法不仅保证了深度学习模型的精度和推理速度,同时通过语义分割网络提高网络模型的泛化能力。
2 本文方案
2.1 基于双通道残差的语义分割网络
本文提出的语义分割网络如图1所示,一共分为上下两个通道,通道中的网络进行残差连接,故而命名为双通道残差。网络的特征输入为经过特征融合网络得到的特征图,输出为通道数为1的概率图,其表示的是每个像素点处于文本区域的概率。由于通道2的网络层数小于通道1,因而通道2相当于是通道1残差连接,加上图1中的1、2、3这三个残差连接,整个语义分割网络中共有4个残差连接。由于输出概率图的分辨率大于输入特征图,因此通道1和通道2进行的都是上采样操作,本文采用反卷积[7]实现上采样。通道1和通道2的最后一层都是对输入图像每个像素点的分类结果,这两层进行逐像素相加后得到网络的最后一层。

图1 基于双通道残差的语义分割网络
2.2 整体网络结构
本文的文本检测算法流程如图2所示,从输入图片到输出图片一共经过;是个阶段,其中前三阶段为网络处理部分,第四个阶段为后处理部分,目的是从二值图中生成文本区域。本文设计整个检测网络分为三个部分,分别为backbone、neck和head。backbone部分采用ResNet作为整个网络的网络骨架,用以提取图像中的语义信息。neck部分采用FPN进行特征融合,特征融合之后对得到的特征图进行concat操作,然后连接注意力层[8],使得分割结构更加鲁棒。head部分采用2.1小节提出的双通道残差语义分割网络,对输入图像中的每个像素点进行预测,输出每个点处于文本区域的概率值。
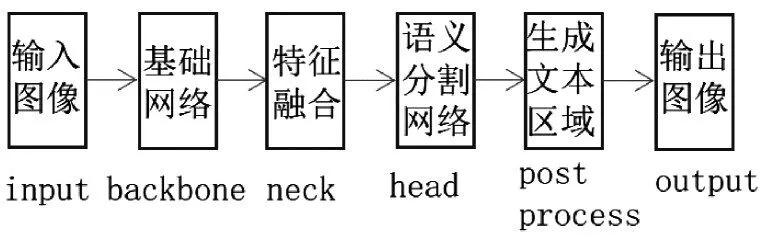
图2 算法流程
网络的损失函数层一共有三个,分别是通道1最后输出的概率图1和通道2最后输出的概率图2,以及网络最后输出的概率图3。其中,由于通道1的深度更深,所以得到特征图的语义信息更强,因而使用交叉熵损失函数,以此来保证每个点分类的准确性,而通道2更短,因而使用IOU Loss来保证文本的召回率。最后概率图3同样使用IOU Loss,以此来提高整体网络对于检测结果召回率。
3 实验分析
3.1 数据集
本文选择的实验数据集为ICDAR2015。该数据集一共包含1500张图片,按照2:1的比例分为训练集和测试集,每张图片的大小都为1280×720像素。该数据集中的图像都是通过可穿戴设备随意采集的,图像中的文本大小、文本行方向等都具有随机性,这些因素增加了其文本检测的难度。
3.2 实验环境
实验基于Pytorch,利用ICDAR2015开源数据集对本文提出的方法进行了性能评估。实验中的硬件平台配置如表1所示。
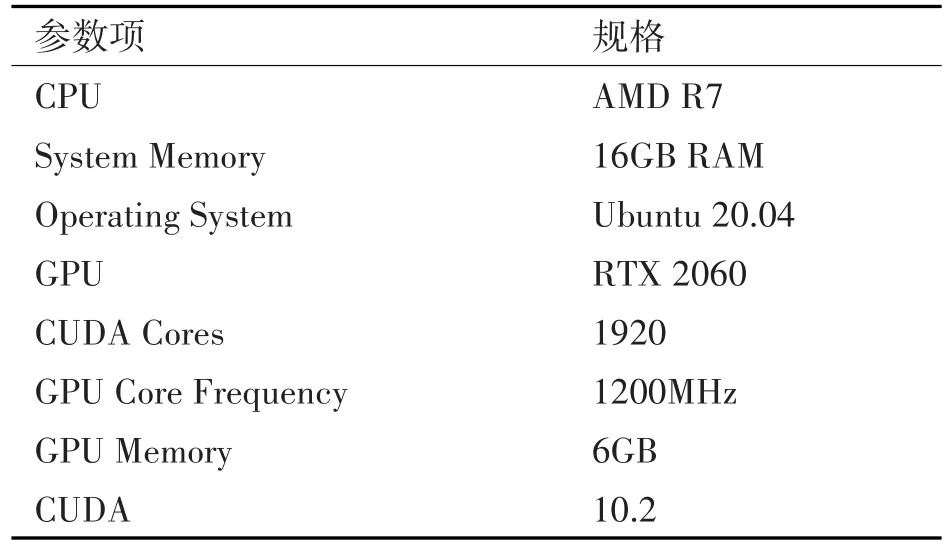
表1 实验环境
3.3 实验验证
在实验中,我们将训练的batch size设为6,初始学习率设为0.001,优化器选择Adam,一共迭代1200个epoch。图3为模型在测试集的准确率和召回率的变化曲线,图中的横坐标表示迭代次数,纵坐标为百分比,可以看到随着迭代次数的增加,网络的精度也在逐渐提升。当迭代次数过少时,深度学习模型的精度会比较差,反之,模型可能会出现过拟合,使得在训练集的精度上升而测试集的准确率下降,因此,在我们的研究中每训练完一个ep⁃och,就将此时得到的模型权重与之前迭代得到的最高精度的模型权重进行对比,如果此时的模型权重测试结果更优,则将权重保存下来,同时将其更新为当前的最优结果。最终,本文提出的场景文本检测算法在ICDAR2015数据集中取得了88.99%的准确率和80.16%的召回率。图4显示了测试集中的部分检测结果。
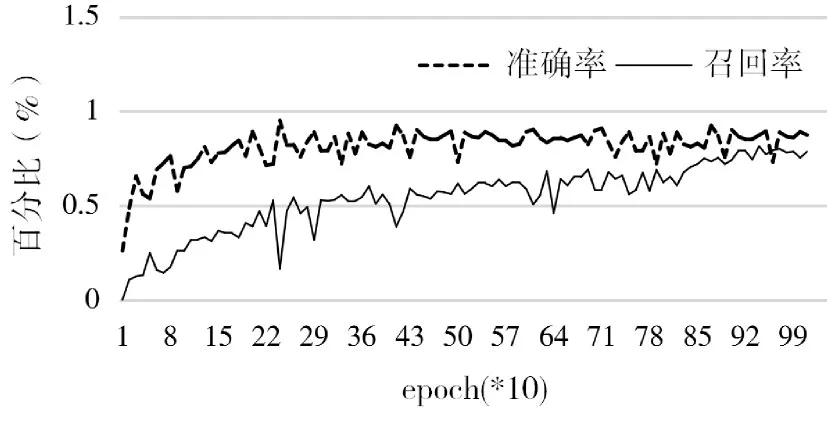
图3 测试集准确率和召回率变化曲线

图4 部分检测结果
表2是目前主流的文本检测方法与本文方法的对比结果,本文的baseline算法为DB-ResNet-18[8],它发表在AAAI2020,是当时场景文本检测的最佳算法。本文的检测网络与DB-ResNet-18都是采用resnet18+特征金字塔的网络结构进行特征提取和融合。本文所提出算法的准确率、召回率、F-mea⁃sure相比于DB-ResNet-18分别提升了2.19%、1.66%、2.05%,这表明本文所提出的基于双通道残差的语义分割网络对于分割精度的提升是有效的。同时可以看到本文提出的方法相比于SegLink[2],PixelLink[9],EAST[10]等多方向文本检测网络有所提升,与FTSN[11]等目前检测效果优异的网络相比性能接近。
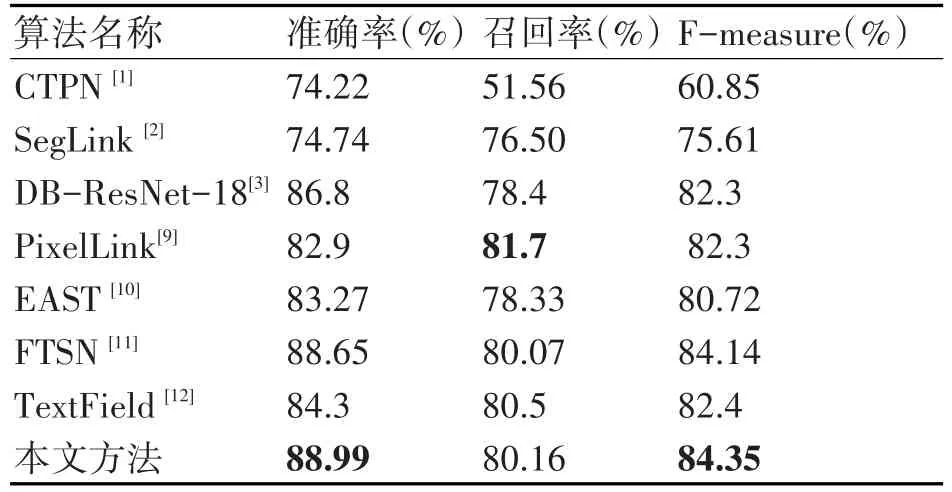
表2 ICDAR2015检测结果对比
4 结语
为了提高场景文本检测的精度和模型的泛化能力,本文将基于双通道残差的语义分割网络应用在场景文本检测算法中。特别地,我们利用ResNet作为基础网络进行特征提取,同时利用FPN对提取的特征进行融合,最后送到语义分割网络中。与基于边框回归的检测算法相比,检测网络的泛化能力得到增强,同时提高了模型的推理速度。最终的实验结果证明,本文提出的网络是行之有效的。其在ICDAR2015的测试集的准确率达到88.99%,召回率达到80.16%。在未来,我们可以进一步优化分割网络的结构以提高深度学习模型准确性。
