爬虫技术与RPA 在银行运营管理领域的应用
2021-06-24孙乙博
孙乙博
(天津理工大学,天津 300384)
0 引言
随着时代的发展,互联网技术发展日新月异,数字化浪潮席卷而来,人们能够接收到的信息量越来越大,种类越来越繁多,随着云服务的出现,信息的存储也更加方便、快捷。对于商业银行来说,需要保存很多数据到数据库之中,而随着数据量越来越大,数据分类越来越细化,银行各项业务的自动化实现逐渐成了商业银行的一项主要需求。而自动化一定离不开RPA,RPA 一定离不开网络爬虫技术。数据获取,数据挖掘、数据清洗、数据分析等技术都离不开网络爬虫的支持,而这些技术恰恰是当前商业银行提升核心竞争力的重要途径之一。网络爬虫技术与RPA 思发展为银行获取信息及有效整合应用带来了新一轮的变革。
1 网络爬虫与RPA 简介
网络爬虫(Web Crawler)指的是以任何技术手段批量地获取数据。获取数据需要按照一定的流程与规则,首先获取目标网页的URL,再根据设定好的需求分析、提取页面内容;其次各大搜索引擎平台就是目前应用爬虫最为广泛的例子——通过爬虫获取各个URL 中相应的网页信息;之后在应用时,主要起数据采集的作用,采用接口或暴力破解的方式解析网页内容以获取目的资料,采集效率高,会对服务端后台造成巨大负担,也因此会出现反爬虫机制来禁止过多的爬虫。
可以把RPA(Robotic Process Automation,机器人流程自动化)理解为一个“数字员工”或是“人工智能助手”,它可以模拟、代替员工来操控鼠标和键盘,例如打开应用程序,复制信息,发送邮件等。对银行业而言,RPA 技术代表了一种全新的、同时也是未充分利用的方式,它可以提高工作效率,同时最大限度地减少传统的重复性、人工劳动密集型的业务流程。因为它的核心是“模拟人”,所以它对系统施加的压力也如一个人在系统上的正常操作一般,没有多余负荷,不会对系统造成任何影响。
综上,在银行内部业务系统应用中,最好是将RPA 的思路与爬虫技术结合起来,借助Python 爬虫技术实现RPA “模拟人”的功能,从而既能完成RPA 的目标——模拟人工操作获取数据,提高采集效率与准确性,又能将采集效率、操作频率控制在一个合理的范围内,不至于触发反爬虫机制或对业务系统后台造成过大的负担。
2 爬虫技术与RPA 在银行运营管理领域的应用
如今,成熟的银行机构都会在内部部署多个业务系统、管理系统,以实现业务、工作流程的数字化。然而遗憾的是,数字化的成功并没能带动自动化的实现,大多数银行工作人员仍然必须每天往返于多个系统之间执行大量的手动工作,以获取各项工作、交易用数据。在当前银行内部的运营中,银行数据来源主要以银行各个业务系统及内部审计系统的银行内部结构化数据为主,其中可能包含每天的柜员业务量,VTM 业务量,ATM 业务量等运营绩效数据;而对于银行的运营部人员来说,从这些结构化的运营绩效数据中分析、总结出用户的需求、市场的趋势等,就是工作的主要内容。而在数据分析之前,首先需要获取数据。因此,在一个银行运营人员每天的工作流程中往往充斥着大量、重复、单调、枯燥的“低级”操作,这些操作不仅降低了工作效率,更消磨了员工的工作热情。如何快速、有效地批量获取银行内部业务系统的各项数据,进而对数据进行综合分析,是大数据时代银行内部运营部门亟须解决的问题。
为了解决这一问题,银行及其IT 部门正在努力将不同的原有IT 系统合并为一个连贯的工作流程,以方便员工的操作并提高效率。不过系统的集成耗费的时间、涉及的成本以及最终的易用性都是阻碍银行实现自动化的绊脚石。
银行内部业务系统获取数据的问题关键在于烦琐却有序的步骤,而这恰恰是RPA 技术的最佳应用环境——基于规则的流程,如果可以将其描述为一组详细的逻辑步骤,则RPA 机器人可以轻松地做到这一点,从而大幅度节省人力资源。RPA的实现离不开网络爬虫技术,而在了解了RPA 的思路、目的后,借用网络爬虫技术及Python 语言,可以轻松地将一个RPA实现出来。以下用一个真实的项目案例来进行分析。
首先分析相关页面的主题特征,该页面为银行内部业务系统的主页,在其前端页面上已经完成了对数据的渲染及可视化,银行内部人员使用时可经过一系列的选项后下载对应日期、银行各个方面的数据Excel 表格;因数据均由JavaScript 对页面进行动态渲染获得,且数据量非常庞大,难以进行清洗及结构化,不易使用Request、Beautiful Soup 等传统的爬虫方式自动进行页面分析及数据提取,且该需求对系统性能及并发能力要求不高,因此技术方面采用了模拟浏览器技术来模仿RPA批量、自动地获取数据。
确定技术使用后,则应继续按照RPA 的思路,确认一个基于规则的流程单元,反映到该实际项目中来就是确定对应数据的提取路径,如:“运营状况—运营业务量-柜员业务量 (折算后)—柜员业务量—查看详细—选择频度—选择日期—选择机构—选择社区银行—点击搜索—Excel 下载”,后再根据路径来确定元素定位及向对应元素发送的需求事件。所用到的技术栈为Python 面向对象编程、Selenium 相关模块应用、Chrome、Xpath;图1 为部分核心源代码。
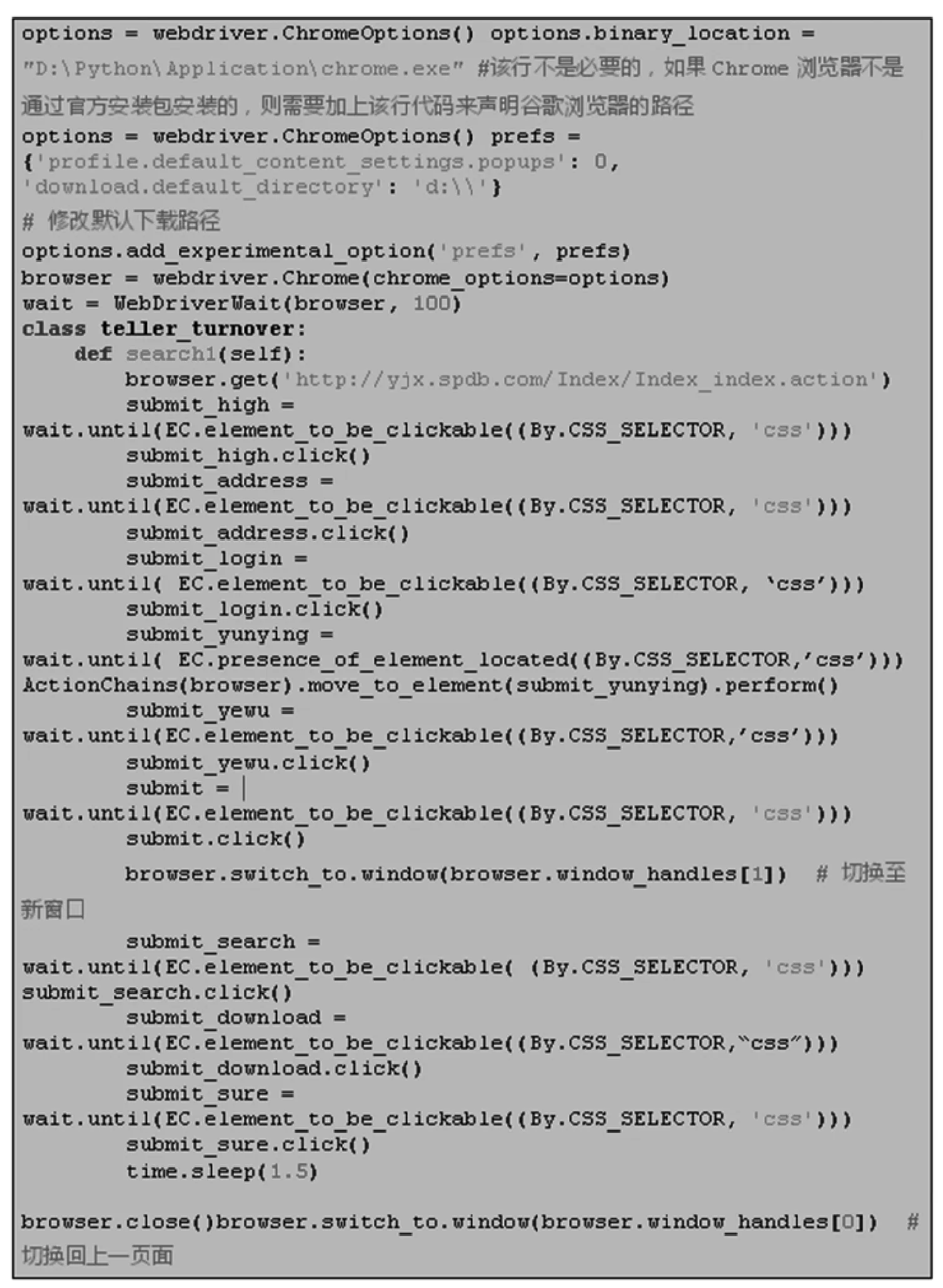
图1 部分核心源代码
另外,如果要实现真正的全自动运行,能够每天自动执行以按天批量获取所需数据,还需要完成自动登录事件,如果是从登录页面进行登录,则直接利用Selenium 获取元素,发送对应文本事件即可;而如果是直接访问对应业务系统的话,则大概率需要进行Nginx 权限认证,此时因为是浏览器的自动弹窗,无法使用常规的Selenium 方法解决,完成自动登录;这时就需要将登录用的账号密码添加到网址内,以通过Nginx 权限认证,添加格式如下:http://username:password@xxxxxxx.com。
但是直接将账号密码写在源代码中,既不方便修改,也存在安全隐患,故将其写入Excel 表中,通过Pandas 库来读取,如图2 所示。
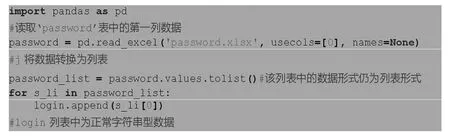
图2 Pandas 库
通过以上编码,即可实现一个全自动、批量、准确地获取业务系统中整理好的Excel 表格数据的模拟浏览器爬虫,类似于一个功能单一的RPA。除获取指定运营数据外,也可利用该爬虫获取更加广泛的信息,如员工岗位信息、轮岗信息等,可对各部门的运营调度工作提供基础数据,大大提高工作效率。
3 RPA 技术与网络爬虫的优势
RPA 与网络爬虫技术之所以受到如此多的青睐,原因总结下来就一句:RPA 与爬虫技术在某些方面做得比人工更好、更快、更准确。
RPA 与网络爬虫通过在高频率、可重复的任务中代替人力来降低运营成本,同时也减少了这些任务的处理时间。降低成本的估算因研究和使用案例而异,但降低50%以上并非不切实际。准确性对各个行业来说都很重要,但是对于金融服务行业这种高度管制、高风险高回报的行业,尤其是银行来说,确保准确性更是业务中至关重要的一环。与可能错过某一步骤,改变步骤顺序或是引入其他不同步骤的人工操作不同,RPA极其精确,不会有任何的偏差,只要是准确的基于规则的流程,RPA 就会支持规则的一致运用以及每次执行都遵守设定好的规则流程。
RPA 与网络爬虫在金融行业中还有一项重要的优势——合规,银行中需要遵守的规则是如此之多,这对员工来说是一项艰巨的任务,而只要能够提前设定好对应的规则,RPA 就能很好地帮助公司遵守规则。
4 总结与展望
在当下的大数据时代,如何更好、更快地利用数据对业务进行分析、审计、预测,是运营人员需要不断思考的问题,运营人员也需要把更多的时间和精力投入到这方面,而进行分析的前提及首要条件就是获取数据,“工欲善其事,必先利其器”,RPA 与爬虫技术就是这样的一把“利器”。随着数据量越来越大,种类越来越繁多,自动化、批量化、准确化一定是未来运营人员获取数据的主要趋势。而在这个趋势下,RPA 不仅能自动、高效、实时地提取需求数据,更能减少重复性工作,提高工作效率,降低错误发生率,高效支撑运营管理工作,是运营管理工作向数字化、智能化发展的重要举措,为“智慧运营+”体系建设扎实推进夯实基础。RPA 技术使银行业能够以前所未有的方式整合业务流程的“最后一公里”,银行业也将RPA 视为其新一轮变革的核心技术之一。不仅仅是RPA,爬虫技术也是如此,利用Python 语言包含的各种强大的函数库,能够轻松按照RPA 的思路来实现一个基于爬虫技术的简易RPA,大大降低了RPA 的开发及使用门槛;RPA 思路的提供,爬虫技术的实现,两者的成功结合将会为银行业运营管理带来全新的变化。
当然,RPA 与爬虫技术仅能解决部分烦琐的数据获取问题,而面对实际工作中更为复杂的运营管理任务,还需要更精细的数据分析并同时结合运营人员的专业知识及经验,才能做出合理的选择与判断;同时,不局限于一方面的数据,如果能够采集多方面的数据统一进行专业、细致的分析,那么一定能够更好地实现运营管理的职能。
