改进YOLOv3的安全帽佩戴检测方法
2021-06-23肖体刚蔡乐才黄洪斌张超阳
肖体刚,蔡乐才,高 祥,黄洪斌,张超阳
1.四川轻化工大学 自动化与信息工程学院,四川 自贡643000
2.宜宾学院 三江人工智能与机器人研究院,四川 宜宾644000
在智能监控报警系统中,施工场地安全帽佩戴检测问题十分重要,安全帽是工作人员脑部的防护用具,在发生事故的情况下[1],可以有效地保护施工人员头部免受重压,能强有力地保护生命财产安全;那么,急需在智能监控报警系统中对安全帽佩戴情况进行实时准确地检测,避免事故的发生[1]。
许多研究者使用机器学习和图像处理技术实现了安全帽佩戴检测,胡恬等采用YCbCr[2]色彩模型配合肤色定位到人脸,再结合图像处理[2]和神经网络实现安全帽佩戴检测。刘晓慧等[3]采用hu矩阵和支持向量机相结合的方式完成安全帽检测。李琪瑞[4]采用Vibe算法进行人体检测,再使用凸字算法检测头部,最后使用HOG算法特征提取后结合SVM实现安全帽佩戴检测。这些算法利用了肤色、头部和人脸信息配合图像处理和机器学习实现了安全帽检测,取得了一定的效果,但实际检测环境存在复杂背景、复杂干扰和安全帽体积较小等问题,基于传统特征提取算法的安全帽检测可能存在稳定性差和泛化能力不足等问题,导致安全帽检测不准确。也有研究者采用基于卷积神经网络(CNN)[5]的目标检测算法实现安全帽检测,实现了安全帽佩戴检测,徐守坤等[5]在算法Faster-RCNN的基础上进行改进,实现了安全帽佩戴检测,并且检测准确率高,但是算法实现复杂,训练步骤繁琐,检测速率慢;对比传统特征提取的目标检测算法[5],基于CNN的目标检测算法检测准确率高。
基于CNN的目标检测算法分为两步法和一步法,两步法设计思想是:先单独采用CNN网络或者算法进行先验框(anchor box)的获取,再进行分类和位置回归,代表算法主要有RCNN[6]、Fast-RCNN[7]、Faster-RCNN[8];而一步法是采用端到端(end-to-end)设计思想,直接在同一个CNN中进行anchor获取、类别和位置的预测,代表算法有YOLO[9]、SSD[10]、YOLOV2[11]以及YOLOv3[12]等等;两种类别算法相比较,一步法的检测速度快,模型训练简单,但检测准确率稍弱;YOLOv3算法的检测准确率高检测速率也快。
综上,本文提出一种基于改进YOLOv3[12]的安全帽佩戴检测算法YOLOv3-WH,通过增大输入图像尺度,改进卷积基础结构,增加多尺度预测,引入多尺度融合,并重新训练获取先验框等改进方法,实现安全帽佩戴检测,同时通过自制安全帽佩戴数据集进行改进模型的训练和验证;并在相同环境下与YOLOv3、SSD、Fast-RCNN[7]等检测算法进行性能对比,检验改进算法的性能。
1 YOLOv3原理
YOLOv3汇集了许多深度学习目标检测框架的优点,运用CNN网络Darknet-53[13]来实现特征提取,Darknet-53网络结构使用了残差结构的设计思想,将网络层数设计更深但不会出现梯度爆炸和梯度消失[13]等问题,网络能够提取出目标更深层的信息;该网络有53层,主要由卷积层和最大池化层[13]组成,网络有残差单元,使用3×3和1×1卷积层组成;网络包含批标准化(Batch Normalization)[13],Leaky ReLU激活函数层。另外,YOLOv3采用多尺度进行检测,在三种尺度之间使用了类似于FPN[14](Feature Pyramid Networks)特征金字塔结构,实现不同尺度特征信息的融合;YOLOv3算法分别在13×13、26×26和52×52三个尺度上实现类别和位置预测。YOLOv3[12]的主要结构如图1所示。YOLOv3采用K-Means[15]聚类算法,获取待检测目标的anchor,然后将获取的先验框按检测尺度进行分配,提升模型训练和预测的速率,提升检测的准确率。

图1 YOLOv3网络结构
YOLOv3是一种检测准确率高且实时性好的目标检测算法,图2是YOLOv3与主流检测算法的性能对比图,可以看到YOLOv3检测速率和准确率比大部分算法优秀。YOLOv3虽然在开源数据集[16]上检测精准度和速率优于其他算法,但是在安全帽佩戴检测问题上,需要进行改进,安全帽佩戴检测主要解决安全帽是否佩戴到人员头部的问题,因此目标大多数都是比较小,检测背景也比较复杂;另外检测速率需要实时性。为解决这个问题,本文在YOLOv3[16]的基础上进行改进优化,提出一种安全帽佩戴检测算法YOLOv3-WH,通过实验和测试,验证了改进算法在安全帽佩戴检测上的有效性。
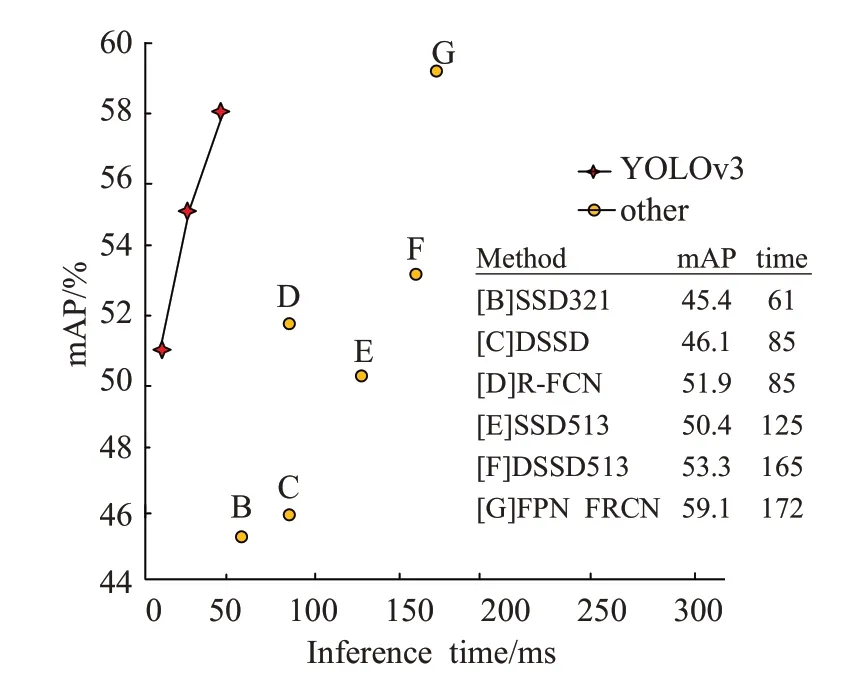
图2 YOLOv3与其他算法性能对比
2 YOLOv3改进
2.1 基础网络改进
YOLOv3的主干卷积网络是Darknet-53[15],Darknet-53网络是在Darknet-19[15]的基础上去掉了全连接层和池化层,再融合了ResNet[16]残差网络的跳跃连接层结构。网络结构中主要使用1×1和3×3的卷积层,分别实现增加特征通道和压缩特征增强网络性能的作用。
本文使用深度可分离卷积(Depth Separable Convolution,DSC)结构的思想替换Darknet-53网络里面残差块(Residual)[16]的传统卷积部分,残差[16]结构使CNN网络的层数更深,提取目标深层的语义信息,但会丢失小目标特征信息,降低检测精准度,同时加倍了计算量,降低检测速率;为了提高算法在安全帽佩戴检测上的检测准确率和速率,本文引入深度可分离卷积结构,减少CNN网络特征提取中目标信息的丢失,同时减少检测模型的计算量,提升检测模型的检测速率。图3中(a)图是Darknet-53网络中残差块的卷积结构,直接使用1×1和3×3连续卷积,然后使用跳跃连接组合通道输出;本文的改进结构如图3(b)所示,保留了1×1卷积结构,增加3×3的深度可分离卷积[16](DSC)进行特征图通道卷积,然后使用1×1的卷积进行点卷积,实现通道特征层的融合;再使用跳跃式[16]连接组合特征,最后增加1×1卷积平滑特征输出。

图3 特征提取结构对比
深度可分离卷积[17]实现过程如图4(a)图所示,图4(b)是传统卷积实现过程,传统卷积将所有通道一起卷积计算,深度可分离卷积[17]将输入特征图的每个通道分离,分别实现卷积操作,最后使用点卷积实现分离通道卷积的组合,达到与传统卷积计算相同的效果。实现压缩计算量,提升检测速率,减少特征丢失的效果。
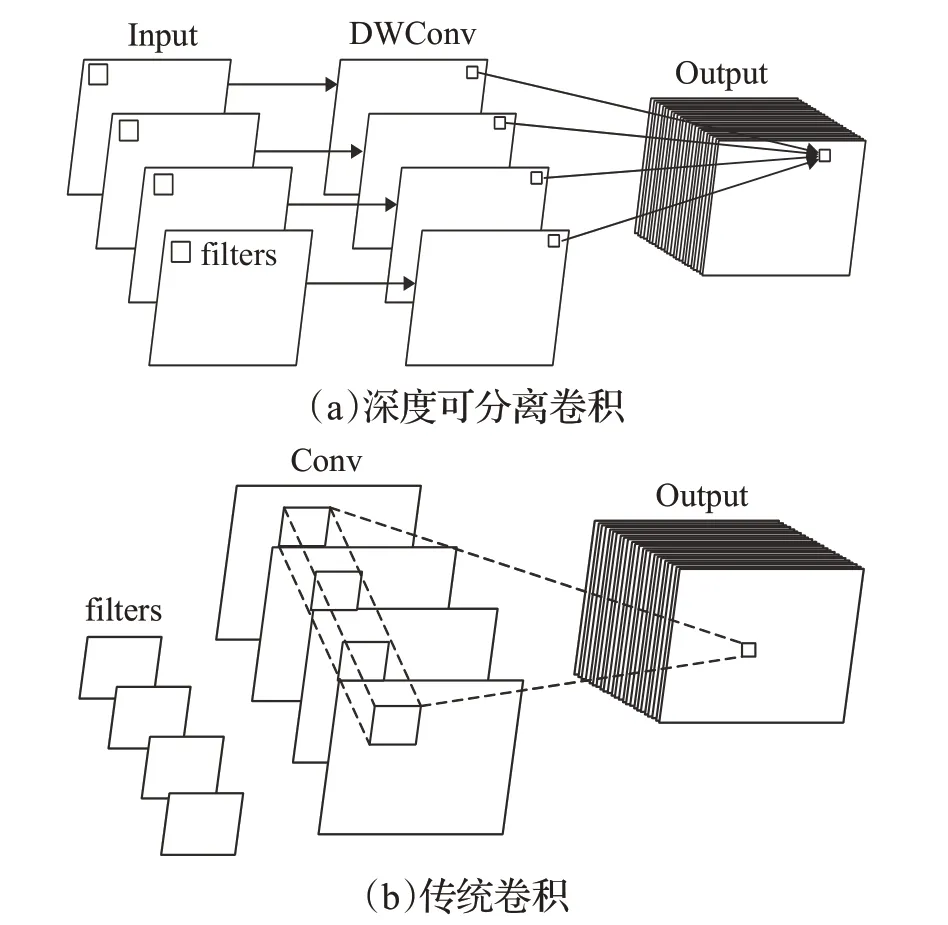
图4 两种卷积对比
通过计算公式对比效果,公式(1)是传统卷积计算量,公式(2)是深度可分离卷积计算量,公式(3)是计算量压缩比值;其中D K×D K是卷积核的大小[18],D F×D F是输入特征图的大小,M是输入通道,N是输出通道。将深度可分离卷积计算量和传统卷积[17]计算量进行比值,如公式(3)所示,可以将计算量压缩为原来的

本文为了提升安全帽检测的准确率和检测速率,将在Darknet-53网络的基础上进行改进;主要分为两部分改进,第一部分上面已叙述,引入深度可分离卷积结构;第二部分将输入图像尺度从416×416增大为608×608尺度,减少CNN网络下采样时小目标特征的丢失,在Darknet-53网络的基础上,结合以上两部分改进点进行优化,优化网络如图5所示。
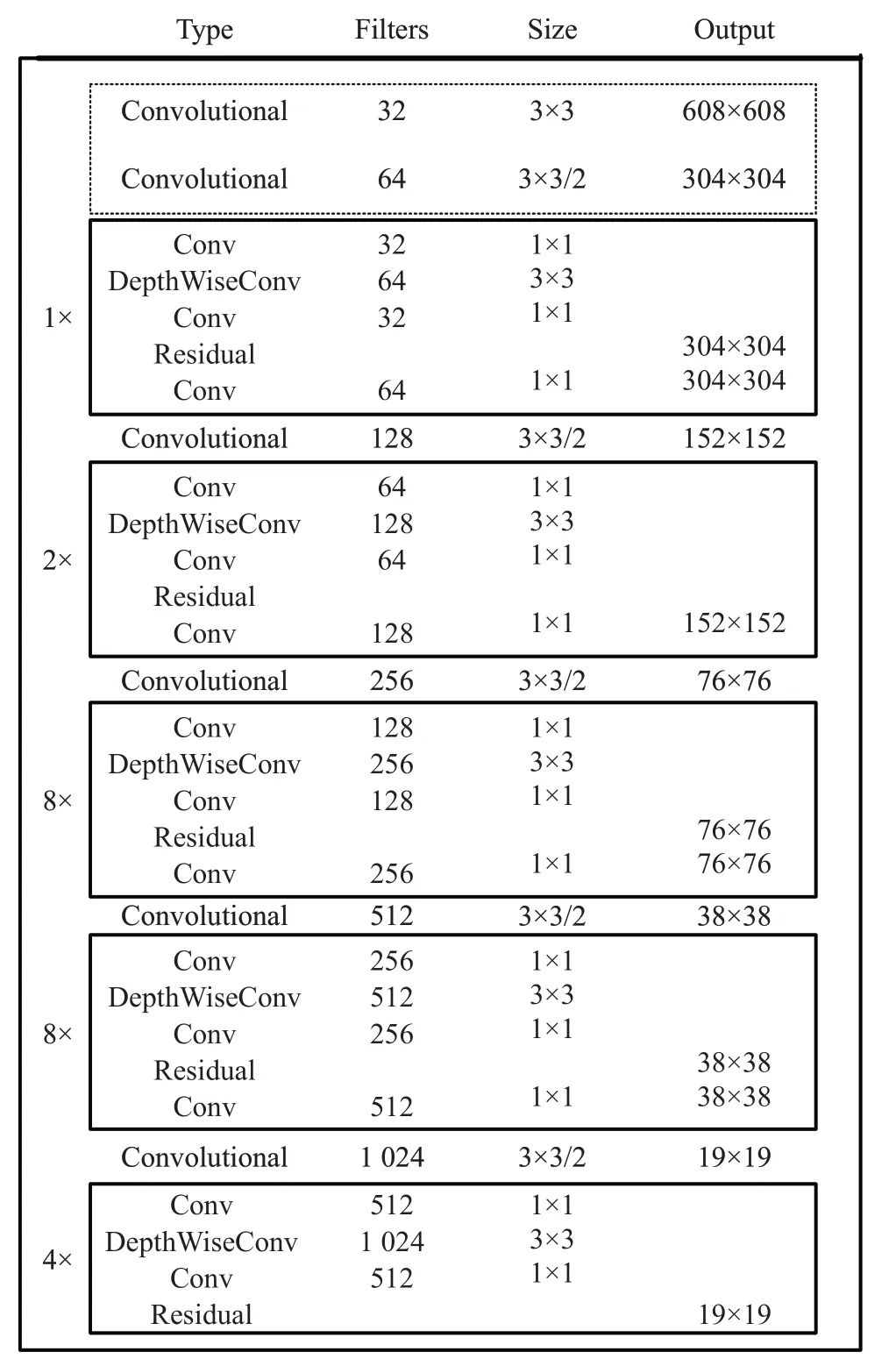
图5 改进网络结构部分
2.2 多尺度检测改进
YOLOv3采用多尺度检测,获取13×13、26×26和52×52三种特征层尺度进行预测;分别将13×13特征层2倍上采样和26×26特征层进行融合预测,将26×26特征层2倍上采样和52×52特征层进行融合预测,所以YOLOv3相比于SSD等算法,其检测准确率较好。
YOLOv3主要在开源数据集[18]COCO和VOC[18]进行实验,这些数据大部分检测的目标物较大,安全帽作为防护用具佩戴在人员的头部位置,大部分检测目标区域较小,在经过多次卷积后较小安全帽区域的信息会丢失,导致整个安全帽佩戴检测准确率降低。
为解决这个问题,本文将在多尺度检测基础上进行改进,添加低维的尺度检测来增强对浅层的特征学习能力,在原算法的3尺度检测基础上拓展为4尺度检测,根据输入尺度为608×608,本文将添加152×152的检测尺度;另外,原YOLOv3算法采用2倍上采样,不能很好地融合浅层特征信息,本文将采用2倍上采样和4倍上采样相结合的方式实现不同浅层特征信息的融合,进一步减少卷积过程中较小安全帽区域的特征信息丢失,同时也使得深层特征信息得到更好的利用,提升安全帽佩戴检测的准确率。
本文多尺度检测改进结构如图6所示,采用608×608的输入图像尺度,改进算法将在19×19、38×38、76×76和152×152四类特征尺度上进行检测;在原YOLOv3算法的基础上增加两层4倍上采样结构,其中主要改进点是将19×19特征层经4倍上采样后与2倍上采样特征层和76×76特征层进行级联,将38×38特征层经4倍上采样后与2倍上采样特征层和152×152特征层进行级联,另外两层19×19和38×38与原算法一致;通过改进可以充分地利用安全帽的浅层特征信息,将不同尺度的特征融合后再进行安全帽佩戴检测,进一步减少特征的丢失,提升安全帽佩戴检测的准确率。

图6 多尺度检测改进结构
2.3 anchor参数优化
YOLOv3[18]中使用了先验框(anchor box)思想,采用了K-Means[18]聚类算法根据标注的目标框(ground truth)获取K个anchor box;获取合适的anchor box可以提高检测的准确率和检测速率;YOLOv3算法根据COCO和VOC2007[18]等开源数据集获取anchor box,开源数据集检测的目标较大,获取的anchor box也较大,不适合bounding box较小的安全帽检测任务,那么就需要重新进行anchor box的选取。
在安全帽佩戴检测任务中,聚类的目的是使anchor box与ground truth的IOU[19]越大越好,所以不能采用一般聚类方法的欧式距离,应该采用IOU来作为度量函数,公式(4)是新的度量函数;其中box是标注的真实目标框,centroid是聚类的中心点,IOU越大,距离越小,anchor box与真实框越接近。
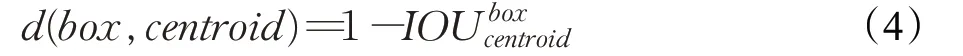
使用标注的安全帽数据集进行聚类计算,获得anchor box个数K与IOU的关系曲线如图7所示,图中IOU随着anchor box数量增加而增加,在K=12后逐渐居于平稳,并且IOU值较大;所以本文选择K=12,统计的anchor分配如表1所示,获得12组anchor:(9,10),(12,13),(13,16),(15,18),(15,21),(17,19),(18,21),(22,26),(30,35),(47,54),(89,103),(205,237)。将anchor按照预测层尺度进行分配,最大感受野特征层19×19上使用(47,54),(89,103),(205,237)这三种anchor来检测较大安全帽佩戴情况;在38×38特征层上使用(18,21),(22,26),(30,35);在76×76特征层上使用(15,18),(15,21),(17,19);在152×152特征层上使用(9,10),(12,13),(13,16),用于检测较小安全帽佩戴情况。

图7 先验框个数K与IOU分析图
2.4 YOLOv3-WH损失函数
YOLOv3-WH的损失函数公式(8)由位置损失公式(5)、置信度损失公式(6)以及分类损失公式(7)组成,在分类和置信度预测中,采用二元交叉熵损失[18](Binary Cross-Entropy)进行分类和置信度预测,使用多个独立的logistic函数替换原本的softmax[18]分类;在位置信息回归中,采用均方差误差[18](Mean Square Error,MSE)实现预测。损失函数中λcoord和λnoobj是损失权重系数,分别代表坐标权重和不包含目标的置信度权重;添加权重系数是为了调节坐标误差和置信度误差的权重,本文参考YOLOv3算法的参数设置,调高位置误差权重,将λcoord取值为5;另外,由于检测图像的大部分区域不包含目标物,在检测过程中会导致网络倾向于预测单元格不包含物体的情况,所以需要减少不包含目标物的计算权重,即将λnoobj取值0.5;N是anchor个数;x i、y i、w i、h i、C i和pi分别是预测目标横纵坐标、目标框宽高、置信度和类别概率;x̂i、ŷi、ŵi、ĥi、Ĉi和p̂i分别是真实的目标信息。

3 实验和结果分析
3.1 实验环境
本文的实验环境为:Intel®CoreTMi7-9750H CPU@2.60 GB 2.59 GHz,32 GB运行内存,Nvidia Gefo-rece Gtx1080ti,ubuntu18.04,64位操作系统,Tensorflow[18]深度学习框架。编程语言是Python,GPU加速软件CUDA10.0和CUDNN7.6[19]。
3.2 实验数据集
实验数据分为两部分,一部分从网络爬取,然后进行数据清洗选取适合的安全帽佩戴图片;另一部分通过视频帧获得;大概覆盖了工厂、工地、矿产以及车间等场所,避免了检测背景环境的单一性,提升模型的泛化能力;两个部分数据集综合总计获得7 000张安全帽佩戴图像。采用开源工具Labelimg[19]标注数据,标注数据分为两个类别,佩戴安全帽样本标注为hat,未佩戴全帽样本标注为person;最后按照5∶1比例分配样本为训练和测试样本,分配情况如图8所示,其中横坐标表示的是标注的样本数量。

表1 anchor box分配表

图8 数据集分配统计
本文的实验样本数据集采用VOC2007[19]数据集的格式进行处理,需要对数据图像进行统一的编号后使用Labelimg[19]标注软件进行类别和位置信息标注,生成XML[19]脚本文件,图9是标注和脚本数据制作过程;最后编写Python脚本程序将标注好的数据转换成TXT文件用于改进算法的训练。

图9 训练样本制作
3.3 评测指标
为了验证YOLOv3-WH改进算法的性能,本文采用平均精准度(mean Average Precision,mAP)和每秒检测帧数(FPS)两个指标对算法进行评估。其中,mAP是对所有类别的平均精度(Average Precision,AP)求取均值后获得。精确度(P)如公式(9)所示,召回率(R)如公式(10)所示,平均精准度(mAP)如公式(13)所示。其中,TP[20](True Positive)表示检测结果为正的正样本[20],FP(False Positive)表示被检测为负的正样本;FN[20](False Negative)表示被检测为负的正样本。另外,本文统计了实验过程中的FPS参数,以检验模型的检测速率。


3.4 模型训练
使用前面制作的安全帽佩戴数据集进行训练,一共训练四个网络模型,分别是SSD[10]、Faster-RCNN[8]、YOLOv3[12]和本文改进模型YOLOv3-WH,训练的目的是统一做对比分析。训练的参数设置参考了YOLO官网上的训练参数,设置批训练数据量(batch_size)为32,输入图像尺度设置为608×608,权重衰减值[20](Decay)为0.000 5,训练动量配置为0.9,整个训练过程有40 000步分200个epoch(轮次)完成,实验采用小批量梯度下降法[20]的方式进行优化参数,其中本文训练过程中学习率(learning rate)呈动态变化,开始训练的学习率为0.000 1,训练次数7 000次后,学习率动态设置为0.000 03,训练达到11 000次时,学习率稳定为0.000 01。
3.5 实验结果与分析
在对改进模型的训练过程中,使用Tensorboard[20]统计训练中的日志信息,并保存训练的权重参数;通过统计的数据信息绘制了模型在训练过程中损失函数的变化曲线,图10是实验过程原算法与改进后的算法损失值变化曲线对比结果,黄色曲线是未改进YOLOv3损失值变化情况,蓝色曲线改进YOLOv3-WH损失值变化情况,横坐标是训练迭代次数(Iteration),纵坐标是总损失值(Loss),可以发现,两个算法在初始时刻的损失值都很大,但是本文改进算法YOLOv3-WH初始损失值较小;在训练次数超过20 000次后,模型开始逐渐收敛,最终训练达到40 000次后,YOLOv3模型的损失值收敛到2.5,而本文改进算法损失值收敛到0.5。可知,改进的算法YOLOv3-WH使得最终的损失值收敛更小。

图10 训练损失曲线对比
通过保存训练中预测边界框与真实边界框的交并比(IOU)来评估模型的性能[20],本文实验统计了模型预测边框和真实边界框的平均交并比(AVG IOU)变化值,并绘制曲线图,如图11所示,可知,模型训练在10 000次以内,平均交并比在不断升高,但是YOLOv3-WH变化较未改进前稳定;30 000~40 000次迭代训练后,本文改进算法平均交并比稳定在0.92附近,未改进YOLOv3算法则稳定在0.8附近,可知,本文改进算法YOLOv3-WH在针对安全帽检测上的预测边界框更加接近真实边界框。

图11 平均交并比对比
3.6 对比实验分析
本文将YOLOv3-WH算法与目标检测模型[21]Faster-RCNN、SSD和YOLOv3使用相同的测试数据集进行对比实验,统计并计算AP[20]指标进行对比,如表2所示。同时,将上述算法的检测平均精准度(mAP)、检测速率(FPS)和模型大小进行对比统计,如表3所示。

表2 算法的AP值对比 %
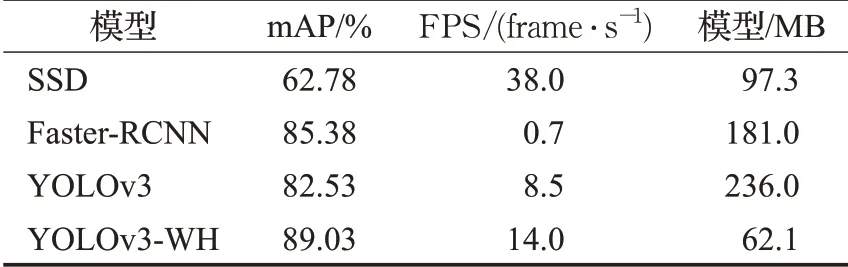
表3 整体检测性能对比
通过对统计的表2和表3分析可知,本文算法YOLOv3-WH的mAP达到了89%,相对比与Faster-RCNN[8]、SSD[10]和YOLOv3[12]算法性能分别提高了3.36个百分点、26.25个百分点、6.5个百分点,可知本文算法在安全帽佩戴检测性能上要优于上述三种算法。另外,从统计的检测速率分析上可知,本文算法检测速率要优于YOLOv3和Faster-RCNN算法,检测速率比YOLOv3提高了64%,但是相对比SSD算法,检测速率还远不及。并且,本文采用深度可分离卷积结构,使得模型的参数量大大压缩,比上述三种算法模型参数都小,相对比YOLOv3算法,YOLOv3-WH模型参数量仅为原来的1/5。
本文进行了消融实验对比分析,以检验各个改进点的优化作用,实验统计结果如表4所示,其中改进点1、2、3分别对应基础卷积网络改进、多尺度检测改进以及anchor优化,从表4中可知,引入深度可分离卷积改进基础卷积网络,可以提升检测的速率;多尺度检测改进点提升了检测的平均检测准确度,但是检测速率变慢;而改进优化K-Means后,平均检测准确度和检测速率都提升了;结合上述三类改进点后,相对于YOLOv3,本文算法在安全帽佩戴检测上相对可靠。

表4 消融实验结果
3.7 图片检测结果
下面随机选取测试数据集的图片进行检测结果分析,对YOLOv3和YOLOv3-WH进行对比分析,图12是YOLOv3算法改进前后的效果对比结果,从左往右分别是图(1)、图(2)、图(3)和图(4),可以看到图(1)存在5个目标,并且安全帽目标较大,两种算法都准确检测到安全帽;图(2)存在5个目标,存在图片清晰度较差、安全帽较小以及部分遮挡等问题,YOLOv3检测到3个,漏检2个,YOLOv3-WH检测到4个,漏检了1个,图(3)存在7个目标,图片中背景复杂以及部分遮挡等问题,YOLOv3漏检2个目标,YOLOv3-WH全部检测准确。图(4)是安全帽密集数据,YOLOv3-WH漏检1个,YOLOv3漏检6个。综上各种环境下的图片检测结果可知,YOLOv3-WH可以准确检测到安全帽佩戴情况,虽然存在小部分漏检,但相比于YOLOv3算法,改进算法的检测准确率提升了许多,同时泛化能力较好。图13是本文算法YOLOv3-WH部分检测结果,背景包含了建筑、工厂以及施工场所,佩戴或者未佩戴安全帽的人员存在于密集、遮挡或者干扰等位置,可以看到,YOLOv3-WH准确地检测出安全帽佩戴的情况,也说明改进算法YOLOv3-WH的实用性。

图12 改进前后效果对比

图13 YOLOv3-WH部分检测结果
4 结论
针对在智能监控中安全帽佩戴检测准确率低和检测速率慢的问题,本文在YOLOv3的基础上提出改进安全帽佩戴检测算法YOLOv3-WH,通过增大输入尺度,添加深度可分离卷积结构;采用四种尺度检测,增加4倍上采样结构层;以及优化K-Means聚类算法等改进措施。实验结果表明,YOLOv3-WH损失函数收敛值更小,平均IOU值更大,YOLOv3-WH算法的mAP比YOLOv3提高了6.5%,检测速率提高了64%,模型大小仅为YOLOv3的1/5,所以YOLOv3-WH安全帽佩戴检测算法具有可行性。
