基于Xgboost算法的短时强降水预报方法
2021-06-23朱岩翟丹华吴志鹏张焱
朱岩 翟丹华 吴志鹏 张焱
(重庆市气象台,重庆 401147)
引言
短时强降水是重庆地区最严重的灾害性天气之一[1],由于降水效率高、雨量大,局地性、突发性强,且极易引发山洪、泥石流和内涝等次生灾害,是汛期短临预报预警的重点和难点,因此,当前亟需更多预报产品为短时强降水的预报提供技术支撑。前人针对短时强降水的气候统计、个例分析和复杂地形影响[2]等方面的特征条件已经做了很多有益的探索。李强等[3]分析了川渝地区汛期短时强降水事件日变化特征,指出其多发并加强于夜间,且历时较长,极值降水多持续2 h等特征。袁晨[4]、周北平[5]等人对川渝地区短时强降水时空分布特征和监测预警技术也有研究。
短时强降水临近预报方法主要包括基于卫星云参数预报[6]、雷达定量估测降水、基于配料法的统计回归预报[7]等传统方法以及新兴的人工智能预报。基于配料法和统计回归方法的短时强降水预报技术已得到长足发展,并取得了一系列较好成果[8-14]。但是随着气象大数据的累积以及预报业务对准确率和精细化程度不断提高的要求,这些传统方法在应对高时空分辨率、多变量和高度非线性等挑战上逐渐显露出不足。
随着人工智能在各行各业突飞猛进的发展,气象预报领域也逐渐引入机器学习算法,并在诸如污染物、气温和能见度预报、强对流天气识别、回波预报等方面取得了一些成果。在强降水预报方面,Gagne等[15]建立了基于逻辑回归和随机森林的定量降水校正概率预报。Ma Liang等[16]基于葵花卫星资料和数字高程资料,利用梯度提升树(GBDT)算法建立了降水落区预报模型。刘媛媛等[17]采用动态聚类算法研究了北京城区近12年来短历时暴雨的时空分布规律。杨通晓等[18]采用粒子群优化算法,结合支持向量机开发了双偏振雷达对流降水类型识别方法。基于机器学习算法、针对短时强降水的预报技术研究也陆续见诸学界。路志英等[19]建立了一个深度信念网络(DBNs),利用地面加密观测数据对天津市短时强降水进行预报,检验结果表明DBNs预报明显优于支持向量机(SVM)和逻辑回归(LR)。白晓平等[20]分别运用改进的二元Logistic回归法和综合多指标叠加法建立了西北地区东部的短时强降水预报模型,二元Logistic回归法对独立样本预报的TS评分高达46.6%。钟海燕[21]引入支持向量机(SVM)、梯度提升树(GBDT)、极限提升树(eXtreme Gradient Boosting, XGBoost)3种机器学习方法应用于雷达降雨产品的临近降雨预报,实验表明,基于SVM和GBDT的方法都具有较好效果,而XGBoost方法与PPLK方法相结合的预报性能在所有实验成员中效果最好。孙俊奎等[22]基于概率神经网络(PNN)、支持向量机(SVM)和逻辑回归3种机器学习算法对石林地区的逐3 h间隔降水量的8个等级进行回归建模,业务测试表明,PNN和SVM模型优于逻辑回归模型,TS在45%左右,中雨以上量级预报,3种模型的TS评分达28%。
目前,机器学习算法在短时强降水预报中的应用研究为数尚少,而重庆也缺乏本地化的短时强降水客观预报方法及产品,因此本文将针对重庆地区短时强降水,基于二源或三源融合的逐小时格点降水资料和EC细网格再分析资料,通过箱线图差异指数寻找预报变量阈值并建立消空规则,结合K均值聚类算法和Relief算法重建训练集并优选建模变量,最后建立基于Xgboost算法的短时强降水客观预报模型,为重庆和周边地区短时强降水预报提供技术支撑和客观预报产品。
本文基于配料法选取了两方面预报变量,一是短时强降水短临预报业务中常用的基本诊断量,如可降水量、K指数和水汽通量散度等,二是由这些基本量衍生得到的具有综合指示意义的复合因子,如湿位涡、湿热力平流等,它们在高守亭等[23-24]对暴雨预报的理论和预报系统研发中得到了检验和推广。
1 资料和方法
1.1 观测和预报资料
实况降水数据取自中国气象局国家气象信息中心的高分辨率融合降水产品[25]。考虑到重庆地区短时强降水主要集中在每年的5—9月,因此选取的数据时段为2011年至2015年的5—9月。其中2011年至2014年数据为地面-卫星二源融合产品,水平分辨率0.1°×0.1°,2015年数据为地面-卫星-雷达三源融合产品,水平分辨率0.05°×0.05°。为统一分辨率,从0.05°×0.05°降水场中抽稀取出与0.1°×0.1°格点场相同的格点,并截取重庆和周边地区(28°~32.5°N,105°~110.5°E)作为研究区域,共2475个格点。根据中央气象台标准,短时强降水阈值为1 h降水量≥20 mm,为方便数据处理和计算,这里取逐小时的整点值。由于本文预报对象为短时强降水是否发生,因此样本的标记采用二分类,达到阈值的样本记为1,未达到的记为0,文中分别称为正例和负例。实际业务中,在不利于短时强降水的大尺度天气形势下,中小尺度局地环流或者较好的环境场配置也会引发极少数孤立的短时强降水。以达标站数是否满足总格点数的1%为判断标准,剔除了低于1%的时次,减少了短时强降水比例过低时次对建模过程的干扰。
预报场采用EC细网格(0.25°×0.25°)2011—2015年的5—9月逐日02:00、08:00、14:00、20:00(北京时,下同)起报的再分析资料,包括位势高度、温度、相对湿度、风速、风向等基本气象要素用于计算物理量场,以及相同网格分辨率的逐小时总降水量再分析场作为基准,用于对比评估本方法相对模式预报的效果。另外,EC资料中不包含地形数据,而重庆地区山脉纵横,地形复杂,地形对强降水的触发作用应当考虑在内。因此,地形数据采用重庆市气象局与美国Oklahoma大学共同研发的中尺度数值模式输出的水平分辨率3 km地形高度值。空间上,采用双线性插值将EC细网格上的要素插值到0.1°格点场上;时间上,以距离当前降水时次最近的前一再分析场时次作为相匹配的预报场,经过整合后形成一套完整统一的样本集。其中2011—2014年样本作为训练集,2015年样本作为测试集。除地形高度以外所有变量的计算均基于EC细网格高空形势场的基本要素,中英文变量名及其单位见表1。
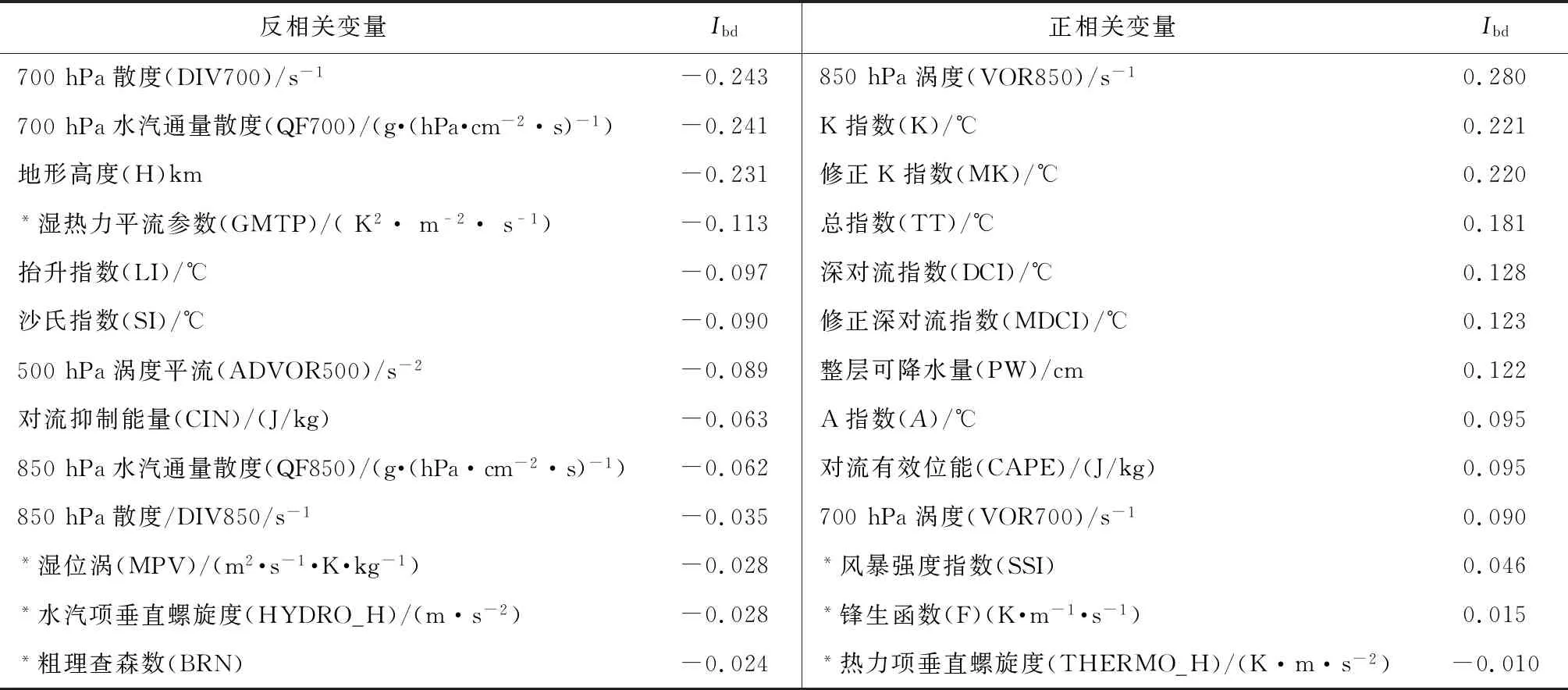
表1 预报变量Ibd值
1.2 样本中变量和预报对象的三维分布特征
为初步观察预报变量对短时强降水的区分程度,分别从训练集的基本和衍生诊断量中选取K指数、整层可降水量、850 hPa水汽通量散度和对流有效位能、湿热力平流参数、风暴强度指数两组变量,绘制正、负例在变量构成的特征空间中的分布。由于各变量量级差异以及自身变化幅度均较大,为方便对比数据和可视化的美观,将以上变量标准化为无量纲数值。
如图1所示,选取的变量是具有一定识别作用的,部分正例处于负例之外,但是也存在很多重叠、交叉样本,且负例总量远远大于正例。因此,需要根据变量对正负例的区分度初步筛选样本消除负例,并选择预测能力较强的变量进行建模,以增强分类效果。另外,严重的类别不平衡性也要求在建模和预报时必须根据样本权重在重采样、误分代价、判定阈值等至少某一环节中采取措施,以免模型的响应能力被多数类样本“淹没”。

图1 2011—2014年样本集变量和预报对象的三维分布:(a)K指数(K),整层可降水量(PW)和850 hPa水汽通量散度(QF850),(b)对流有效位能(CAPE),湿热力平流参数(GMTP)和风暴强度指数(SSI)(红点为正例,绿点为负例)
1.3 方法
1.3.1 阈值法和消空规则
由于样本集存在的严重类别不平衡性会削弱分类效果,因此需要在建模前寻找特征变量进行消空,通过剔除负样本在一定程度上削弱不平衡性。为考察所有预报变量对短时强降水的区分度,引入Fu等[26]定义的箱线图差异指数(box difference index,Ibd),对于变量的选取和预报前的消空具有很好作用:
(1)
式(1)中,M1表示短时强降水发生时某变量的均值,M0为无短时强降水时的相应值,σ1和σ0分别为该变量在两种情况下相应的标准差。如果事件发生和不发生时变量的平均值差异大而总方差小,也即Ibd较大,则该变量对事件是否发生的区分度高,适于在预报前初步消空潜势低的样本。
各预报变量的Ibd如表1所示,左右两列已按照Ibd绝对值降序排列。在与短时强降水呈反相关的变量中,地形高度、湿热力平流参数、700 hPa散度和水汽通量散度的Ibd相对较高,绝对值超过0.1;在与短时强降水呈正相关变量中,850 hPa涡度、修正K指数和K指数等变量的Ibd相对较高。这些具有相对大值Ibd的变量将被赋予更高权重加入消空过程,以体现其对短时强降水更强的区分能力。另外,衍生量虽然综合反映了动、热力和水汽条件,具有更全面的指示意义,但Ibd都相对较低。
如图2所示,以K指数和700 hPa散度为例,训练集负例对应的两个变量值域分别为12~48 ℃、-10~32 s-1,且该值域完全包含了正例的值域。负例对应的变量奇异值可能为模式的错误预报,在实际情况中极少出现。因此如果分别选用训练集中的最小、最大变量值(通常为负例的最值)作为短时强降水发生的临界阈值,而无视利于降水发生的最小、最大变量值(正例的最值),就会引入大量负例从而造成空报过多。为此引入消空所依据的阈值法:选取短时强降水发生时某变量剔除异常值后的最小值和最大值作为阈值。异常值的定义为:令Q3,Q1分别对应某诊断量箱的上下边界值,Q3-Q1则为上下四分位距,当某值小于最小阈值Q1-1.5(Q3-Q1)或大于最大阈值Q3+1.5(Q3-Q1)时,则为异常值。根据以上规则,如图2所示,K指数最小、最大阈值分别为32 ℃、44 ℃,700 hPa散度最小、最大阈值分别为-4 s-1、4 s-1。阈值法消空会以剔除一小部分正例为代价,大幅降低空报率,使整体TS评分得到提高。最后,即使K指数的Ibd在所有正相关变量中名列第3,已具有较好的区分能力,正、负例的K指数箱线仍非常接近,可见满足单一或者少数几个变量的阈值仍然难以区分两类样本并有效消空,因此应建立多变量阈值规则判断降水潜势,剔除潜势较弱的格点或满足潜势条件的格点数占总体格点数比例过低的时次。应该注意到,由于不同地形高度处均有发生短时强降水可能性,如果只预报满足某高度阈值的格点,则会造成低于此高度阈值格点从来不进入预报的不合理现象,故地形高度不进入消空环节。
图2 训练集短时强降水发生(1)和不发生(0)时K指数(a)和700 hPa散度(b)分布箱线
具体消空规则为:对于某一时次预报场,计算每个格点的多变量阈值条件加权和。对每个格点有:
(2)
式(2)中,|IBD|为各变量的IBD值绝对值,Bool为1或0的布尔值,表示是否满足该变量的阈值,n为变量数,S为所有变量的IBD绝对值在该格点上的加权和。判断总体潜势是否达到消空标准,即S值非零的格点数是否达到总格点的1%,若未达到,则认为该时次发生短时强降水潜势很低,不进入模型预报,所有格点预报为无短时强降水发生。表2为训练集和测试集在经过消空前后的正、负例数量和比例。消空后,正例占比都有一定升高,但相对负例仍然很低,类别不平衡现象依然明显。

表2 训练集和测试集消空前后正、负例数量和比例变化
1.3.2 类别平衡和特征选择
初选的预报变量为半经验性,且各因子之间存在一定程度共线性,可能会对机器学习过程带来负担。由Ibd值可见,若干变量对短时强降水的区分度很低,其预测能力可能也较低,需要进一步筛选预报变量。而且,经过初步消空以后正例所占比例仍然很低,两类样本依然很不平衡。处理类别不平衡数据分类问题主要有两大途径:在算法层面,采用集成学习稳定整个分类器的预测性能并提高泛化能力,或者引入惩罚机制,根据不同类别的风险偏好对错误分类设置相应的代价函数加深学习“记忆”;在数据层面,采用过采样、欠采样、人工合成新样本等方式平衡类别或者设置非常规的判定阈值。

(3)
其中,diff(xi(j),yi(j))为样本与其临近样本在第j维特征上的距离函数。M为随机抽样次数。
当第j维特征为非数值型变量时,距离函数为:
(4)
当第j维特征为数值型变量时,距离函数为:
(5)
其中,max(j)、min(j)分别为第j维特征数值的最大、最小值。
由式(3)可见,对于第j维特征,当样本到不同类最近样本的距离大于同类最近样本的距离时,该样本在第j维特征上有利于分类器分类,因此w(j)累加正数,否则该特征不利于分类,w(j)累加负数。
然而在不平衡数据集上,多数类样本被选中的概率远远高于少数类样本,等比例更新权重可能使特征权重伪偏大从而影响分类效果。针对此问题,改进了Relief算法以面向不平衡数据。首先使用K均值算法将多数类样本聚类为q类,然后分别在q个子类和少数类,总共q+1类样本中按比例釆样,形成两大类别大致平衡的训练集。同时引入样本权重到Relief算法中,判断随机选择的样本,若为少数类样本,更新特征权重时乘以大于1的因子,反之则乘以小于1的因子。
当随机选择的样本属于少数类样本时,特征的权重更新公式为:
(6)
属于多数类样本时:
(7)
其中,|S|、|L|分别表示少数类和多数类样本数。决定特征去留的阈值由下式计算:

(8)
式中,M是随机抽样次数:3678,α是第1类错误的概率,取0.05,得τ≈0.073。将经过以上样本平衡和特征筛选步骤后形成的样本作为最终训练集。
各个变量的平均权重如图3所示,平均权重大于阈值的变量在图中以黑色柱体显示,有风暴强度指数、对流有效位能、总指数、修正K指数、整层可降水量、抬升指数、500 hPa涡度平流和700 hPa涡度。采用这些入选变量建模。和Ibd值比较可见,部分高Ibd值的变量平均权重较低,少数高Ibd值变量仍具有较高权重,如总指数、修正K指数和抬升指数,因此Ibd不能完全代表变量的预测能力。

图3 各预报变量平均权重(黑色为大于阈值的变量)
1.3.3 评价指标
本文结合机器学习领域常用的AUC值以及气象预报领域的TS评分、空报率、漏报率作为评价指标。
ROC曲线(受试者工作特征曲线)是指在特定刺激条件下,以被试对象在不同判断标准下所得的空报概率为横坐标,以命中概率为纵坐标,连接各点而成的连线。AUC(Area Under Curve)是衡量二分类模型优劣的评价指标,为ROC曲线下方与坐标轴围成的面积,取值范围在[0.5,1],越接近1,分类器越完美,越接近0.5,分类器越接近随机猜测。AUC同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价,但AUC反应了太过笼统的信息,无法反应召回率、精确率等在实际业务中经常关心的指标。
有鉴于此,根据TS评分、命中率POD和空报率FAR的定义,结合机器学习领域常用评价指标,得到三者的计算公式为:
TS=NA/(NA+NB+NC)
(9)
POD=NA/(NA+NB)
(10)
FAR=NC/(NA+NC)
(11)
其中,NA,ND,NC,NB为模型对二分类问题正确和错误判断的样本数量,其意义见表3。

表3 机器学习性能指标的意义
值得注意的是,AUC表示模型总体上对所有类别的预测性能。当类别不均衡时,容易因为高的AUC而忽略实际上对少数类预报效果并不理想的情况,因此命中率和空报率对于类别不平衡问题是更清晰的衡量指标。
1.4 Xgboost建模方法
集成学习通过构建并结合多个学习器来完成学习任务,可获得比单一学习器更好的泛化性能。作为Boosting集成学习算法家族中的一员,Xgboost是一个树集成模型,将K个CART回归树的结果进行求和,作为最终的预测值:
(12)
式中,Xi为第i个样本,f(x)为单个树的结构和叶节点权重,Φ为所有k个树的集成。不同于传统集成决策树算法,Xgboost能够在节点内选择最佳分裂点,候选分裂点计算增益用多线程并行,训练速度快。其代价函数为:
(13)
(14)

Xgboost有包括正则化项、学习率和决策树数量和树结构属性等众多超参数。超参数定义了模型的复杂度或学习能力等特定基本属性,是在开始学习过程之前需要确定的参数,而不是在学习过程中由算法习得的参数,如权重和偏置。调节超参数的意义在于最小化期望风险,使模型优化度和模型复杂度达到平衡,尽可能同时避免欠拟合和过拟合。网格搜索是应用最广泛的建立在交叉验证基础上的超参数搜索算法,这种穷举式调参算法通过循环遍历尝试每种参数组合的可能性,找出表现最好的组合,能够找到全局最大或最小值。过程中采用了5折交叉验证,也即将训练集5等分,取其中一份为验证集,其余4份为新训练集,经过5次在不同验证集上的测试,取最优结果所对应的超参数组合。最佳关键超参数组合如表4所示:

表4 Xgboost最优超参数配置
2 试验结果
2.1 总体检验结果
将2015年独立样本经过以上阈值消空和变量选择步骤后投入模型预报。模型可以输出概率预报也可以输出确定性预报。经过聚类后的新训练集类别大致平衡,Xgboost的缺省样本不平衡度为1,也即类别平衡,而测试集中仍为类别不平衡,短时强降水出现概率小于0.5,如果采用模型在类别平衡时默认的0.5概率值,确定性预报会产生大量漏报,因此采用了不同的概率阈值生成相应的确定性预报以观察效果。
如图4所示,AUC由概率预报产生的概率值本身决定而不随概率阈值变化,因此保持0.92,表明模型的分类性能总体上较好。但对于类别不平衡的预测问题,还需要考察模型对各个类别的预测准确率。随着概率值从0.01开始增加,TS评分上升,POD和FAR下降,在阈值为0.1左右时三者达到稳定,分别为0.30、0.88和0.69。在阈值从0.1增至0.35的过程中,由于除个别样本的概率值接近0.35以外,其余均小于0.1,各项指标因此不随概率阈值的增加而变化。当阈值超过0.35后,由于模型未能识别出任何正例(NA、NC均为0)而导致TS和POD陡降至0,FAR为无意义的除零数(图中置为0),因此最佳的概率阈值为0.1,对应TS为0.3。实际应用中,可根据对空报和漏报率的敏感程度调节阈值得到用户自定义的确定性预报结果。在相同测试集上,EC未能体现出实况的任何短时强降水事件,且全部偏离实况,因此其TS和POD评分为0,空报、漏报率为1(图略)。模型相对EC对于2015年测试集上的短时强降水预报具有一定优势。

图4 各项检验指标在不同概率阈值上的分布
2.2 独立样本检验期间两次短时强降水预报分析
2.2.1 渝西南短时强降水过程分析
2015年6月28日夜间至30日,受高空波动槽、中低层低涡切变和低层暖平流影响,重庆长江沿线以北地区大雨到暴雨,西部区县的部分乡镇达大暴雨,并有短时强降水等强对流天气,24 h累积雨量如图5a所示。

图5 重庆市2015年6月28日20:00至29日20:00(a) 和7月21日08:00至22日08:00(b)实况雨量
如图6a、c所示,虽然EC再分析场在6月29日02:00—05:00的累积降水量主雨带形态与实况较吻合,重庆西北部预报的3~10 mm降水落区(红色实线圈所示)对实况的相应强降水区域有所反映,但预报较实况相比明显偏弱,主雨带中未预报10 mm以上落区,对于川北地区孤立的20 mm以上强降水中心(红色虚线圈所示)的预报位置也有明显偏西,预报效果不佳。Xgboost模型于29日02:00起报的短时强降水概率高值区(图6b)与实况的吻合度大大提升,除少数地区的空、漏报外,Xgboost预报不仅抓住了从重庆西北部到重庆东北部的西南—东北向主雨带形态特征,还对川北地区的短时强降水落区有所反应(如图中红色虚线圈所示),而全球模式往往很难预报出此类相对较弱的降雨中心或次雨带。02:00—03:00(图6d),遂宁、潼南已产生短时强降水,且中心强度在30 mm以上,从南充到城口为一条断裂为南北两段的强降水带,随后遂宁—潼南强降水中心向东、向南发展进入合川、铜梁,南充—城口强降水带在保持基本形态的前提下向东发展,有若干小中心生消演变(图6e)。川北地区在04:00—05:00新生强降水中心(图6f)。Xgboost预报的概率高值区基本包含了这些时段的强降水落区,且其西南-东北向的大值区中具有两条主线(如图中红色实曲线所示),分别与03:00—05:00强降水发展演变所形成的两条主雨带(如图中黑色实曲线所示)形成对应。到29日下午,如图7所示,Xgboost预报仍好于EC再分析场,对雨带强度和形态的刻画均更准确。Xgboost的高概率区不仅分布在重庆西部的重庆主城、铜梁、璧山等已经发生了短时强降水的地区,在广安和江津也有分布(分别为红色实线、虚线圈所示)。随着降水系统的移动和演变,到20:00(图7f),18:00初生于广安的降水增强到20 mm以上,而江津也产生短时强降水,与Xgboost在14:00预报的概率高值区吻合。此过程的两个时段中,如图10所示,Xgboost预报的TS、POD、FAR分别在0.2~0.4、0.6~0.9和0.6~0.8之间,EC的TS为0,未在图中显示。因此Xgboost对于此次过程两个时段的短时强降水预报好于EC。

图6 EC细网格再分析场的6月29日02:00—05:00降水量(a)、Xgboost模型29日02:00起报的短时强降水客观概率预报(b)和29日02:00—05:00实况降水量(c)以及02:00—03:00(d)、03:00—04:00(e)、04:00—05:00(f)小时降水量

图7 EC细网格再分析场的6月29日17:00—20:00降水量(a)、Xgboost模型29日14:00起报的短时强降水客观概率预报(b)和29日17:00—20:00实况降水量(c)以及17:00—18:00(d)、18:00—19:00(e)、19:00—20:00(f)小时降水量
2.2.2 渝西短时强降水过程分析
2015年7月21日至22日,受高空槽冷平流和中低层低涡切变影响,中西部和东南部地区及东北部偏南地区普降大雨到暴雨,局部大暴雨,并伴有短时强降水等强对流天气。24 h累积雨量如图5b所示。
如图8a、c所示,EC预报较上一次过程更好,虽然总体上仍然偏弱,但在重庆西部与四川交界地区预报了20 mm以上强降水,降水落区的形态与实况在一定程度上吻合。14:00起报的Xgboost则不仅预报了重庆偏西地区的概率高值区,对应着实况3 h累积雨量在50 mm以上的强降水中心,在合川和永川分别也有概率高值区(分别为红色实线、虚线圈所示),从图8d~f的逐时降水量演变可见,雨团东移发展并逐渐体现较清晰的人字形切变形态,19:00—20:00在合川和永川也产生了短时强降水。到21日夜间,如图9所示,EC在重庆西南部预报的强降水落区明显落后于实况,重庆中部地区(红色实线圈所示)的落区预报较准确。Xgboost仍然抓住了主雨带动态,较好预报了黔江、彭水地区的强降水(如图中曲线所示)。对于切变线上的雨带东移和湖南西北部新生的强降水区(红色虚线圈),Xgboost都有所体现,即彭水—黔江和务川—酉阳—咸丰(红色曲线所示)分别有概率高值区与未来3 h内相应地区的实况短时强降水(黑色曲线所示)相对应。

图8 EC细网格再分析场在7月21日17:00—20:00降水量(a)、Xgboost模型21日14:00起报的短时强降水客观概率预报(b)和21日17:00—20:00实况降水量(c)以及17:00—18:00(d)、18:00—19:00(e)、19:00—20:00(f)小时降水量
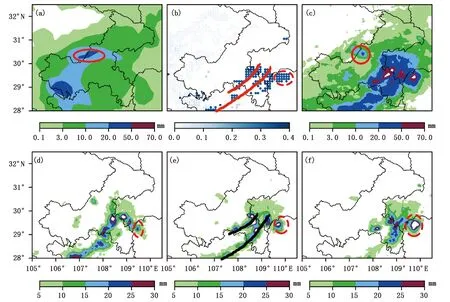
图9 EC细网格再分析场在7月22日02:00—05:00降水量(a)、Xgboost模型22日02:00起报的短时强降水客观概率预报(b)和22日02:00—05:00实况降水量(c)以及02:00—03:00(d)、03:00—04:00(e)、04:00—05:00(f)小时降水量
如图10所示,在此次过程的两个时段中,Xgboost预报的TS、POD、FAR分别在0.2~0.4、0.6~1和0.6~0.8之间。TS和FAR评分与前一过程总体持平,POD略高于前一过程,但两次过程的Xgboost预报无论从定量还是定性结果来看都优于EC。从以上个例分析可见,该方法可以较好预报短时强降水发生的概率及落区,对短临预报预警具有一定参考价值。

图10 两次短时强降水个例的Xgboost预报的各项评分随时次变化(起报时刻分别为6月29日02:00、14:00以及7月21日14:00和22日02:00)
2.3 近年短时强降水过程回报检验
收集了2016、2017和2019年的主要短时强降水过程,并使用本文创建的预报模型进行回报检验。同时,检验了EC再分析场在相应时次的预报效果,结果见表5。

表5 Xgboost模型预报和EC预报在2016—2019年几次短时强降水过程中的检验
由表5检验结果可见,Xgboost预报的TS评分在0.1以上,POD在0.2左右,相对2015年独立样本测试的结果较低,但在各个样本集和指标上均优于EC细网格。已有研究表明[28],常规业务中,短时强降水预报在第1小时的TS在0.1以下,并随时效递减,就此次回报检验而言,其TS评分略高于文献指出的常规业务水平。FAR总体较高,达到0.7左右,模型的空报较多。值得说明的是,本文采用了严格的时空点对点二分类检验,即预报了短时强降水的小时时段以及格点与实况完全一致时才判断为命中,且EC细网格再分析场具有全球模式对中小尺度对流性强降水预报偏弱的固有局限性,另外在插值模式降水统一分辨率的过程中也会削弱、平滑强降水,以上因素可能导致了检验结果中EC表现差。综上,Xgboost模型相对EC细网格在短时强降水预报上具有明显优势,业务应用中也具有一定参考意义。
3 结论和讨论
尽管高分辨率数值模式不断发展,但其对短时强降水等强对流天气的预报能力仍然严重不足。随着大数据挖掘和机器学习在各个领域的大放异彩,基于高时空分辨率模式、结合了机器学习算法的短时强降水客观预报技术成为一种非常值得尝试的思路。本文选取了重庆地区2011—2015年 5—9月间逐小时实况格点降水场,在利用EC细网格模式的再分析资料计算预报变量的基础上,通过观察变量的箱线图差异指数确定了阈值进行消空,初步剔除了噪音样本并建立训练集,然后结合K均值聚类和改进的Relief算法,构造了类别平衡的训练集并挑选出预测能力较强的预报变量最终进入模型,最后依托Xgboost算法建立起短时强降水预报模型,可以输出概率预报或用户自定义概率阈值生成的确定性预报,可对目前业务中的雷达降水估测和模式预报形成补充。2015年独立样本测试和近年来短时强降水过程的回报检验表明,该方法对重庆地区的短时强降水预报较EC细网格更好,其产品在实际业务中也具有一定参考意义。本文主要结论归纳如下:
(1)基于EC细网格再分析资料计算了短时强降水预报变量,并根据各预报变量的箱线图差异指数IBD制定了阈值法消空规则,通过剔除短时强降水潜势过低的时次来提高短时强降水样本在总体样本中的占比,达到消空目的并做出初步预报。其中850 hPa涡度、K指数、修正K指数、700 hPa散度、700 hPa水汽通量散度以及地形高度的IBD绝对值大于0.2,相对其他变量较高。
(2)结合K均值聚类算法和改进的Relief算法,建立了类别平衡的新训练集,并考察了变量对短时强降水的预测能力。变量平均权重表明,抬升指数、整层总降水量、修正K指数、总指数、对流有效位能和风暴强度指数等变量预测能力较突出,因此将其纳入建模过程。
(3)在样本初步消空、预报因子筛选和重建类别平衡训练集的基础上,初始化了Xgboost算法,并通过网格搜索调参确立了最佳超参数,建立起Xgboost短时强降水客观概率预报模型。
(4)2015年独立样本测试表明,当概率阈值取0.1时,模型的AUC为0.92,总体分类效果较好,全体样本的短时强降水TS评分可达0.3,好于EC再分析场。对其中两次个例分析表明,Xgboost短时强降水客观概率预报能更好刻画强降水发生的概率和落区,逐时次的预报效果仍优于EC,TS评分在0.2~0.4之间。近年来短时强降水过程的回报检验中模型预报的TS虽有降低,但仍高于EC再分析场,与业务水平持平,具有一定参考意义。
同时,本研究也存在以下几点不足需要注意:受资料所限,本文采用6h间隔的再分析资料作为起报场计算预报变量,起报后的2~6 h内预报效果会逐渐变差,但随着该模型与业务EC细网格模式的对接,上述问题有望得到缓解;其次,气候背景异常,如厄尔尼诺年的异常降水,以及模式在分辨率、参数化方案和同化方案等方面的变换更新都可能对模型稳定性和预报结果产生不利影响,因此预报概率阈值需要根据气候背景和模式升级重新确定;最后,本方法只能对短时强降水有无做出预报,无法指示其具体量级或强度。这些都是下一步工作中需要改进和注意的。
