基于图像的语义布局信息在服装展示上的研究
2021-06-22李健樊妍何斌
李健,樊妍,何斌
(1.陕西科技大学 电子信息与人工智能学院,陕西 西安 710021;2.同济大学 电子与信息工程学院,上海 201804)
0 引言
近年来,随着深度学习在服装时尚领域的深入,基于二维图像的服装展示技术的研究在纺织服装的设计、生产、商贸等领域都有着广泛的应用前景。尽管在线购物给人们提供了便利,但消费者仍担心在在线购买服装时,商品穿在他们身上看起来如何。因此对于基于姿势的服装展示工作来说,合理且准确的目标服装变形和服装合成是服装展示发挥其作用的必要前提。
1 相关工作
基于姿势的服装展示任务将目标服装转移到目标人物身上,引起了越来越多的研究关注。由此出现了基于二维的服装展示相关的研究与应用。现今主流工作之一主要集中在VITON[1],CP-VTON[2]等基于姿势的虚拟试衣方法使用粗略的人体形状和姿势图作为输入来生成穿着衣服的人。VITON是一种基于图像的虚拟试穿方法,仅使用2D信息。使用最新的人体姿势检测器[3]和人体分析器[4],此方法可以获得良好的人体质量分割和关键点。其中利用基于薄板样条(TPS)的变形方法,首先变形目标服装,然后使用合成蒙版将纹理映射到经过优化的服装展示结果中。形状上下文是通过手工进行提取特征,两个形状的匹配是耗时的,这不利于实现用户所需的实时性,并且生成的服装细节不够完善。CP-VTON采用了类似于VITON的结构,是在其工作上进行改进,使用空间变换网络中的卷积几何匹配器来学习目标人物服装的特征和合成目标服装特征之间的薄板样条(TPS)变换,服装细节相较于之前有所提升。因为它是对目标服装的特征信息进行二次提取﹐来合成更加真实的试衣图像,虽然相较于之前的算法服装细节更加逼真,但是依然会在姿势遮挡服装的情况下,丢失合成后目标服装细节和人物细节特征。VTNFP[5]通过简单地串联从身体部位和衣服中提取的高级特征来缓解此问题,从而产生比CP-VTON和VITON更好的结果。但是,模糊的身体部位和伪影仍然保留在结果中。之所以会出现这样的情况,是由于在整个服装合成过程中忽略了目标人物与目标服装的语义布局,缺少了其约束导致变形后的目标服装不足与更好的为服装渲染过程提供准确的对齐约束,尤其对于款式不同、纹理复杂的服装图像,以及姿态复杂的目标人物图像它并不总是能生成满意的试衣效果。
2 基于姿势的二维服装展示算法分析
2.1 算法总体框架
针对上述问题,本文主要包括语义预测模块和目标服装的变形以及融合语义布局信息的服装渲染模块三个部分,主要工作如下:
(1)通过条件生成对抗网络进行语义布局预测。首先利用条件生成对抗网络对经过处理的公开的数据集进行训练,仅通过目标人物图像和姿势图,以及将要试穿的目标服装得到能够预测穿衣后目标人物的语义解析图的模型。
(2)基于改进的空间变换网络实现目标服装的变形。根据得到语义解析图和目标服装,通过掩膜预测网络通过得到换装后目标服装的掩膜,再通过空间变换网络实现对目标服装的变形。
(3)融合语义布局信息实现服装渲染的构建。借助于换装后的语义解析图和变形后的目标服装,将其服装信息融入到局部渲染过程中,通过语义布局的约束,提高服装渲染的准确度和真实度,从而实现完整的融合语义布局信息的服装渲染方法。本文算法的总体框架如图1所示。

图1 算法总体框架
2.2 语义预测模块
2.2.1 网络架构
语义预测模块采用有条件的生成对抗网络,其中使用U-Net[6]结构作为生成器,同时使用pix2pix[7]中给出的鉴别器PatchGAN来区分生成的语义解析图和真实语义解析图。为了能够将目标服装的特征更好的与目标人物进行融合,本文使用OPENPOSE和SS-JPPNet[8]算法对目标人物进语义解析和姿势估计得到相对应的语义解析图Is和姿势图Ip,然后将提取的目标人物的语义解析图和姿势图高维特征,与目标服装c的新的特征相映射得以预测出穿衣后目标人物的语义解析图It。
2.2.2 损失函数
我们融合了特征匹配损失[68]激励生成器关注生成图像与目标图像之间的差异,来代替L1损失,避免图像模糊,来得到更完善的语义解析图。特征匹配损失可直接比较使用预先训练的感知网络(VGG-19)计算的生成图像和真实图像,激励生成器关注生成图像与目标图像之间的差异,这样对于处理目标衣服与原始衣服长短不一致时语义分割预测有着更好的效果。使用VGG19所提取出的图像特征与如下公式可以计算感知损失:
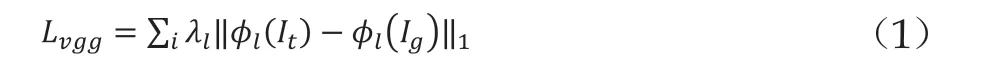

故对于此阶段采用的条件生成对抗损失可以表示为:
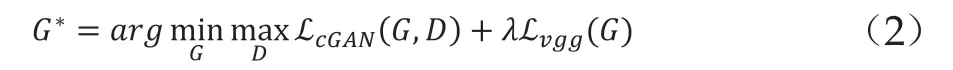
2.3 目标服装变形
2.3.1 掩膜预测
所以服装变形的目的是使服装适应目标人物服装区域的形状,并根据人体姿势在视觉上自然变形,并保留服装的特征。CP-VTON方法仅仅通过粗糙的身体形状来约束目标服装的变形,在出现姿势遮挡的情况下,目标服装不能适应姿势得到合理的变形。本文在其方法基础上首先根据生成的语义解析图和目标服装进行预测目标服装区域掩膜,在其约束下来改善目标服装的变形。
本文使用的网络结构以U-Net网络为基础,通过跳转连接直接在各层之间共享信息,我们使用了10层U-Net结构,包括5个步长为2的下采样卷积层,5个步长为2的上采样层。上采样使用双线性插值层和步长为1的卷积层的组合,最后一层添加Sigmoid激活函数。具体参数如表1所示:

表1 U-Net各层参数
对于损失函数设计部分,我们使用监督学习来训练掩膜预测,网络对于生成掩膜部分并不涉及细节特征部分,这里仅仅使用L1损失来优化整个过程即可。如公式(3),其中c记为预测的目标服装的掩模的真实数据,cM是掩膜预测网络的输出,我们采用了L1损失作为网络的损失函数,定义如下:

2.3.2 基于空间变换网络的服装变形
空间变换网络的几何匹配方法使用CP-VTON的方法,但通过改变其输入条件进行变形约束。如图2所示,通过输入目标服装的掩膜和目标服装,目标服装结合服装掩膜的几何约束,一同作为空间变换网络的输入,首先通过对其特征提取然后在将其合并成一个张量,输入到回归网络中。回归网络在进行仿射变换参数预测时,能够在轮廓约束下更稳定的进行形变,从而得到最终得到变形后的目标服装,其中代表真实目标人物的真实图像。

图2 空间变换网络算法框架
故不难得出服装变形的损失函数:

2.4 融合语义布局信息的服装渲染
本章节使用基于U-Net的编码器-解码器网络作为服装渲染的网络架构,如图3所示,算法的框图如下,为了防止产生棋盘格的伪影,进行卷积运算的使之用3×3的基础上填充1的卷积操作,在进行服装渲染过程之前,我们引入了与衣服无关的人表示,保留诸如脸部、肤色、发型、裤子等物理属性。在此使用SS-JPPNet算法对目标人物图像提取其人脸、头发区域和裤子的RGB通道,以便在生成图像时注入身份信息给新的穿衣后的合成图像。将其调整为256192分辨率的图像,进行卷积操作并对此关系进行建模。

图3 融合语义布局信息的服装渲染算法框架
为了达到我们保持特性的目标,我们通过应用L1正则化使合成遮罩M偏向于尽可能选择变形的衣服。故服装变形的总体损耗函数为:

式中,Io表示生成的最终服装展示效果图,It代表真实图,M表示合成蒙版。
3 实验对比
3.1 数据准备
故本文对Han等人收集的现有的公开数据集[63]中目标人物进行语义解析和姿态估计,得到所需的新数据集进行实验。它包含大约19,000个前视图女性和顶级服装图像对,有16253个清洗对,分别分为训练集和验证集,分别具有14221和2032对。我们将验证集中的图像重新排列为未配对的对,作为测试集。
训练过程中使用的目标衣服与参考图像中的目标衣服相同,因为很难获得试穿结果的真实图像。在上述三个模块的训练过程中,通过设置损耗权重λ=λ=0.1,λ1=λ2=1和批处理大小8,将所提出方法中的每个模块训练20个单元。将学习率初始化为0.0002,并通过Adam优化器优化网络其中超参数β1=0.5,β2=0.999。所有代码均由深度学习工具包PyTorch实施。
3.2 实验对比
3.2.1 定性
我们使用VITON、CP-VTON和VTNFP对我们提出的方法进行主观分析评价。如图4所示,从上到下,手臂与服装的遮挡程度逐渐增加,VITON生成的图像都显示出许多视觉伪影,包括颜色混合,边界模糊,纹理混乱等。与VITON相比,CP-VITON在手臂与服装没有咬合的情况下可获得更好的视觉效果,但在有肢体遮挡的情况下,仍会导致不必要目标服装和身体部位模糊。当手臂和躯干之间有交叉点时,也可以观察到较差的情况,例如在生成的图像中手臂细节消失乃至断裂现象。综上所述,VITON和CP-VTON将目标服装扭曲到衣服区域并映射纹理和绣花,缺少相对应的语义布局的约束,从而可能导致对身体部位和下装的编辑不正确。

图4 各种算法对不同姿势下实现的服装展示效果图
3.2.2 定量
上述定性比较是基于视觉层面上的结果对比。该部分为了更好地比较两种方法的效果采取定量比较的方式,选取了3个评价指标对生成结果进行评测,其中PSNR 、SSIM、MSE分别表示两幅图像间的峰值信噪比、结构相似性以及均方误差,评测结果如表2和表3所示。

表2 随机选取100组实验结果
表2是随机选取100组实验结果的数据,表3是全部测试结果(共14221组)的数据。从表中可以看出,本文方法的PSNR值略高于CP-VTON方法,表明了本文方法试衣后的图像质量更好。SSIM值基本一致,表明两种方法在图像结构性保留方面都有着较好的效果。此外,本文方法的MSE值小于CP-VTON方法,说明了本文方法的图像失真较小,更好地保留了原始图像的结构特征,试衣后图像更加保真。

表3 全部实验结果
4 结语
本文在目前已有的成果基础上,通过融合目标服装和目标人物的语义解析图预测出换装后的人的语义解析图,语义布局不仅能够约束目标服装的变形,而且在指导完整的局部渲染的过程中占据了重要的因素,从而构建融合服装信息的局部渲染构建方法,但是收到各方面资源的限制,本文目前只针对上衣服装的常见姿势的服装展示效果的应用与研究。取得了一定的进展,但以下几个方面还需作深入的研究:(1)融合深度学习的方法的局限性。目前的配准效果较为依赖训练出的模型精度,对于不同的测试对象,学习训练的数据集选择应更具有普适性。(2)在服装款式方面,本文只是针对上衣和目标人物之间语义解析和掩膜预测,从而实现较为完善的服装展示效果,在以后的研究中,可以通过构建更多样式的数据集,设计针对图像中规则体的深度学习目标检测与边缘提取网络,来提高检测精度。未来的研究可以考虑将目标人物分位各个服装区域的语义解析图,实现更多的服装搭配。
