油气资源评价中成因法分析与运聚系数取值模型研究
2021-06-18白琨琳赵迎冬
白琨琳,赵迎冬
(1.中国科学院南海海洋研究所边缘海与大洋地质重点实验室,广东广州 510301;2.中国科学院大学,北京 100049;3.南宁师范大学地理科学与规划学院,广西南宁 530001)
0 引言
油气资源评价是运用多学科、多手段、多方面资料成果和信息,在系统工程分析条件下,以石油地质基础研究为主线,对油气资源的过去、现在和将来状况进行综合分析(赵文智等,2005;吴晓智等,2016)。油气资源评价方法是进行油气资源评价的直接手段,包括成因法、类比法、统计法三大类(李建忠等,2016)。而成因法因其自身特点(Ungerer et al.,1984),已被广泛应用,但仍存在诸多问题,最典型的如运聚系数取值困难。虽然大量学者针对运聚系数进行了研究,并通过解剖刻度区初步建立了回归公式(宋国奇,2002;柳广弟等,2003;祝厚勤等,2007;周总瑛,2009;吕一兵等,2011;张蔚等,2019),但精度仍然很低,选取参数的相关性不高,与地质的关联性不强,容易产生误差,导致运聚系数取值变化幅度非常大,无法有效推广使用。本文以成因法与运聚系数的特点来阐述其计算方式,建立一套运聚系数计算过程模型,使运聚系数的取值更有依据,更能满足实际计算需要,同时也提高了成因法的可靠性。
1 成因法的特点与发展
1.1 特点
成因法遵守油气从生成到运移、到聚集成藏的原则,通过对烃源岩中烃类的生成量、排出量、吸附量、散失量、破坏量等计算,确定油气藏中油气最终的保留量(庞雄奇等,2000;赵迎冬和赵银军,2019),其计算过程展示了油气藏形成的完整成因过程,因此称“成因法”(图1)。其计算能够较好地体现盆地的生烃、排烃、运聚等过程,具有明确的地质意义。
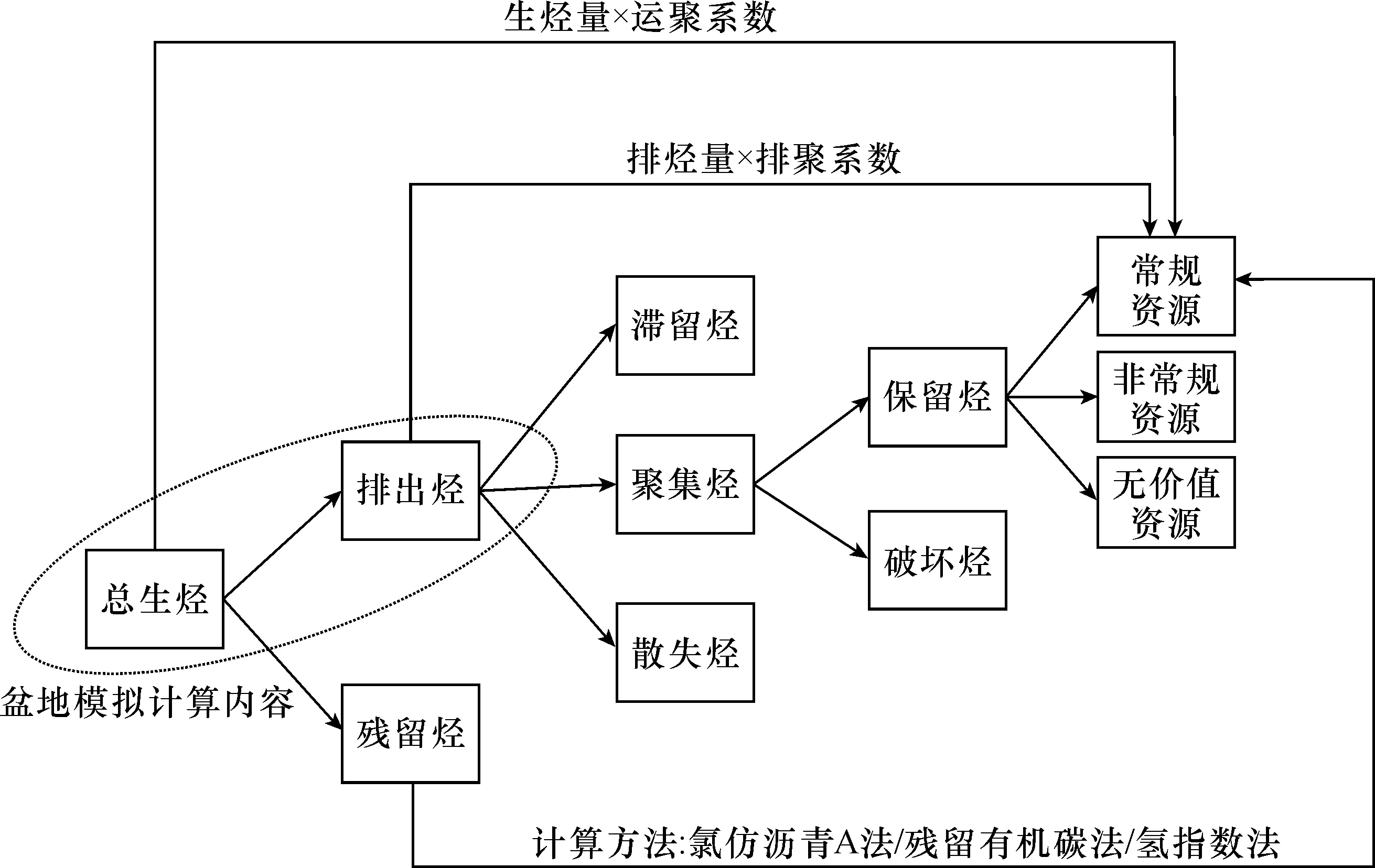
图1 成因法烃类转移过程
成因法通常用于盆地级、凹陷级油气资源的评价,而当研究区资料较丰富时,也可以用于计算区带级油气资源量。成因法在不同勘探程度地区都可以使用,通过不断丰度的地质数据来提高计算的准确度。如在低勘探程度地区,地质资料较少时,可以使用成因法中的氢指数法、残留有机碳法、氯仿沥青“A”等方法,这些方法所需参数较少,准确度较低;而在高勘探程度地区可使用盆地模拟法,全面计算出生烃、排烃、残留烃的含量,并推导出潜在资源量,准确度较高。
分析成因法计算过程与原理,其计算是从生成、排出、运移、聚集、破坏、保留的多个角度来考虑,计算过程为一种递减模式,通常会使计算结果偏高,具有“高估”特点,可作分析资源“上限值”的方法(图2)。
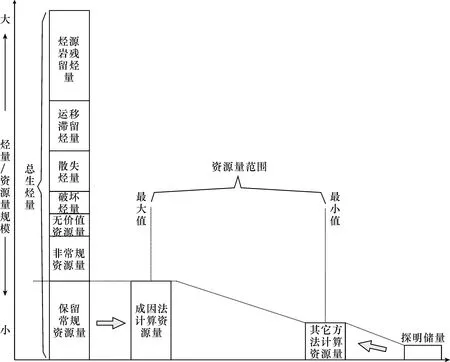
图2 成因法资源量特点
对勘探数据的要求少,可计算资源的“上限”是成因法的主要优点,如某些勘探早期地区,勘探资料匮乏,甚至缺少油藏发现,这种情况下,成因法所需数据少且计算方便的特点就能体现,并且成因法计算出的资源量较大,能给予该区勘探信心并指导勘探方向。如图3所示,当某盆地处于勘探早期,地质资料少,勘探只发现少数油藏,探明储量很低时,无法使用类比法,并且受有限的储量数据所限,统计法只能计算出较低的资源量。此时成因法可以快速算出盆地生烃量,并简单计算资源量。因成因法高估特点,该资源量会比统计法所得结果大,形成了该地区资源的“上限值”。同时该时期资料少,因此资源量范围幅度较大,符合当时实际的勘探情况。
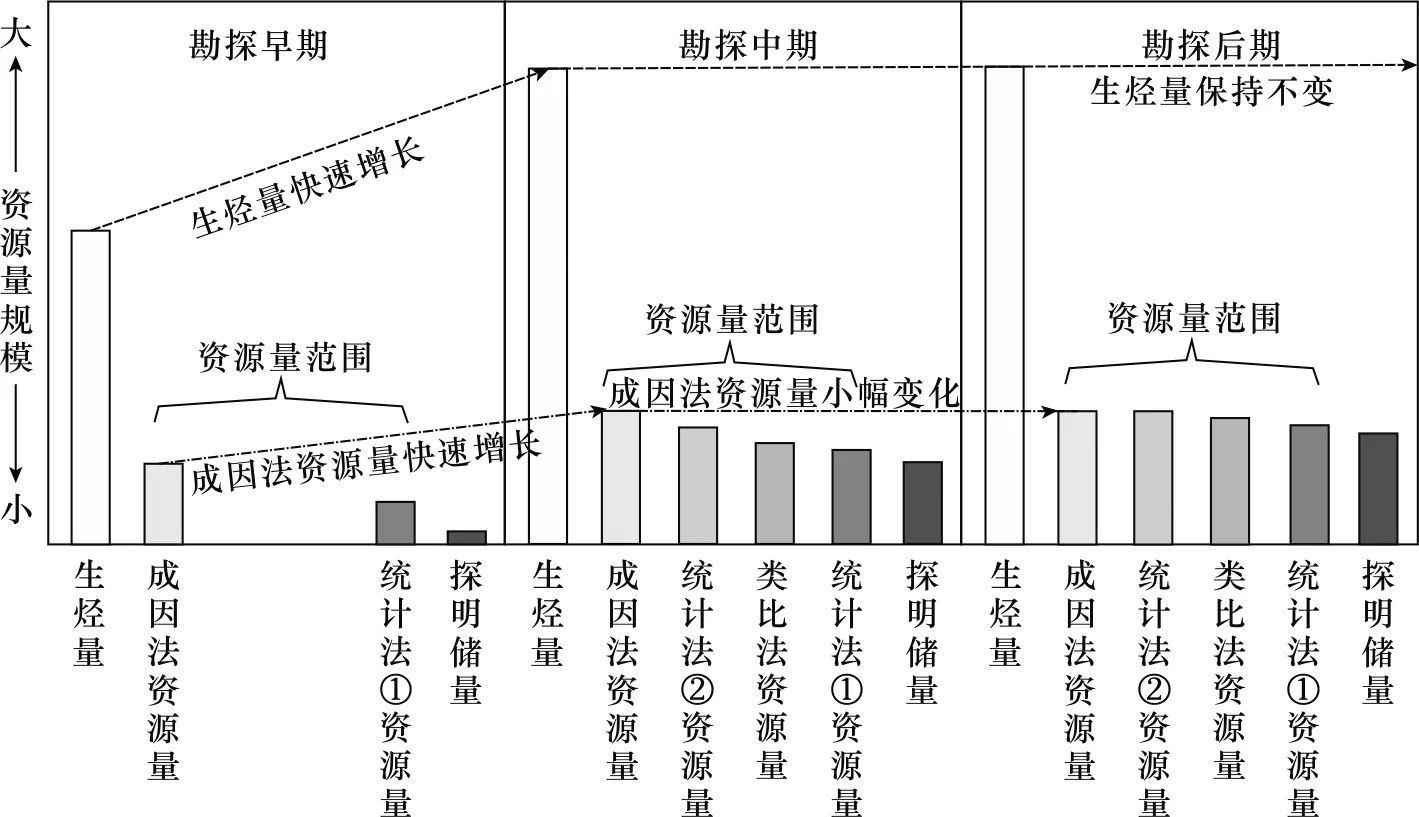
图3 勘探过程与资源量变化关系
而勘探中期,地质资料已经比较丰富,且有大量油藏被发展,探明储量也有了大幅度增长,此时就可以使用多种计算方法获取资源量,如可以通过类比法类比其它凹陷刻度区,也可以通过多种统计法分析统计规律计算资源量。此时地质数据较全,生烃量会有大幅度的增长,导致成因法计算的资源量大幅度增加(图3)。其它方法计算出资源量也因大量勘探发现而大幅度增加,导致最终资源量增加,此时成因法计算的资源量依然可作为“上限值”。
在勘探后期,油藏基本被勘探完全,探明储量达到顶峰。此时地质资料研究已经十分全面,生烃量与运聚系数变化都不大,导致成因法计算出的资源量变化很小(图3)。而油藏勘探完成与探明储量确定,会导致各种方法算得资源量都趋于统一,资源量范围幅度较小。综合以上,可将成因法看作勘探过程中一个计算油气资源量“上限值”的方法。
1.2 发展与瓶颈
1978年,Tissot和Welte首次定义了定量计算烃源岩生烃量的数学模型(Tissot and Welte,1978),作为成因法计算油气资源量的理论基础。随后由于受制于运聚系数取值,成因法被认为误差大,准确率不高,真正使用得较少。此外,由于社会与经济体制的不同,国外追求经济效益,以远景可开采石油储量作为资源量(Meneley et al.,2003),而不重视地质成因与地质资源量,越来越少使用以地质资源为基础的成因法,多使用以经济效益为基础的统计法(Charles,1993;Charpentier and Klett,2005;Hackley and Ewing,2010)。
因此,近40年来国外在常规油气资源评价方法上主要注重改进统计模型与注重地质综合分析,而对成因法后续研究投入不多。国内则是重点发展成因法,在早期的油气资源评价中更是以成因法为主。随着90年代计算机技术的发展,将成因法研究的重点放在盆地模拟技术上(赵文智等,2005)。盆地模拟即通过计算机技术模拟整个盆地生烃与排烃的过程,计算出盆地生烃量与排烃量,并能够模拟出油气的运聚方向。可以说盆地模拟技术的诞生将油气的生成、运移、聚集合为一体,通过研究各种地质参数,建立了数字化的动态模型,方便了成因法的计算,大幅度提高了成因法计算的准确率。目前,盆地模拟技术技术已经发展到三维综合模拟阶段,并与含油气系统分析、成藏动力系统分析相结合,不断推进向更高的层次发展(张庆春等,2001),国内外发展出了多种盆地模拟软,如PetroMod、BasinMod等(Barker et al.,1984;Ulmishek,1986;Magoon,1987)。但目前盆地模拟计算资源量只是在生烃方面较为完善,还存在其它方面问题,如排烃过程较为复杂不易模拟,区带边界不易确定等。
目前运聚系数的取值依然是整个成因法使用中最主要的问题,盆地模拟技术无法解决,阻碍了成因法的进一步发展。
2 运聚系数分析与建模
2.1 存在问题
运聚系数是成因法中最重要的参数之一,它是生烃量与最终形成油藏的比率值,其中油的运聚系数取值范围从不足1%至15%(宋国奇,2002;柳广弟等,2003;祝厚勤等,2007;周总瑛,2009;吕一兵等,2011;张蔚等,2019)。有时也可以用排烃量与形成油藏做比值,称为排聚系数,这种排聚系数比运聚系数的准确度更高,但计算起来也更加复杂,还需要考虑排烃的复杂过程。但无论是哪种系数,都涉及到将生、排烃量转换为最终资源量,这是一个十分复杂的过程。
运聚系数目前没有准确的公式,也无法通过软件模拟出,常通过估值或回归公式的方式求取。但是目前的回归公式准确度仍然很低,选取的回归参数相关性也不高,并且这种回归公式的取值方式使成因法缺失了通过地质过程计算资源量的特点,同时缺失了成因法计算资源量“上限值”的特点。
近些年来,随着刻度区技术的发展,运聚系数又有了新的计算方式,即通过类比刻度区计算运聚系数。如将一个高勘探程度的刻度区解剖后获得运聚系数,通过对地质条件的比较,类比计算出预测区的运聚系数。然而该方法仍然存在问题,如用什么地质条件作为计算运聚系数的标准?类比刻度区求取运聚系数与直接使用刻度区类比法计算资源量有何区别?假如运用在勘探初期,无较多的地质资料,一些参数无法获取时,如何类比运聚系数?因此用刻度区类比计算运聚系数仍然不可行。
因此目前需要的是一个简单而有效的运聚系数计算模型,并拥有成因法具有体现油气成藏过程与计算“上限值”特点,应将运聚系数研究的重点放在模型的建立与改进上。
2.2 运聚系数分析与建模
运聚系数的分析不等同于地质条件分析,侧重点应有所不同。而油气的成藏过程是从烃类排出到聚集成藏,因此运聚系数分析也应参考成藏过程。
依据油气成藏过程,分析运聚系数计算的主要依据,建立了运聚系数取值模型,模型如图4所示。烃类成藏演化的过程可表示为:烃源岩生成烃一部分排出成为排出烃,一部分成为滞留烃;排出烃中的一部分运移聚集成为聚集烃;聚集烃中的一部分被破坏散失,一部分保留下来成为保留烃;保留烃中的一部分为非常规油气藏,只有一部分为常规油气藏。因此整个成藏过程可划分成6个过程,即排烃过程、运移过程、聚集过程、储存过程、破坏过程、资源比例过程(庞雄奇等,2000;张善文等,2003;周总瑛,2009),而此6个过程就需要通过6个参数来实现,参数一般为各时期影响资源丰度的主控因素(张蔚等,2019),如可以通过烃源岩埋深计算排烃率,用源储距离计算烃类滞留储层率,用储盖组合数计算烃类聚集率,用储层厚度计算聚集烃类储存率,用盖层保护计算烃类保存率,用储层埋深计算常规油气比例。
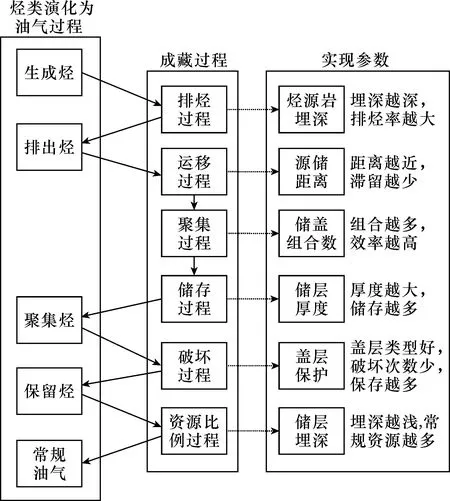
图4 运聚系数取值模型
然而,这些参数的取值依据还需通过大量数据构建,设立出参数取值标准。
2.3 模型参数设置
分别根据以上6个过程建立各项参数的取值依据,因较多使用以油藏为主的地区为数据来源,因此本文运聚系数模型主要适用于石油资源量计算。
(1)排烃过程
以往回归模型中常用烃源岩年龄来表示排烃量的多少,但如果烃源岩地层构造变化大,使用烃源岩年龄参数会与实际产生矛盾。如年龄较老的地层可能比年龄较新的地层抬升更高,但排烃率却更低,因此选用烃源岩年龄作为排烃率取值依据是不合适的。本文使用烃源岩埋深与排滞系数关系作为排烃率的取值依据(张延东等,2011),其中排滞系数即排烃抑滞率,即烃源岩中残留烃与生成烃的比值,计算式排滞系数f。
f=S1/(S0-S2)
其中S0为原始产烃率,mg/g TOC,mL/g TOC;S1为自由烃,mg/g岩石;S2为生油潜力,mg/g 岩石;S1与S2可以通过实验测试得出,S0需要经过公式换算得出。
排滞系数可以通过大量实验测试得出准确结果(徐春华等,2006;陈义才等,2009),排滞系数一般为0.4~0.9,整体上随深度增加而减少(周总瑛,2009)。排滞系数计算得到的排烃率相比传统残烃法或生烃潜力法计算出的准确率要高(张延东等,2011)。烃源岩埋深与排滞系数关系如图5a,可见同一埋深中较大排滞系数为排烃受到抑制时的排烃状态,代表烃源岩厚度巨大,烃类不易排出导致;而同一埋深中较小的排滞系数应表示处于砂泥交互带的烃源岩排烃状态。因此用较大排滞系数作为烃源岩的排烃效率,符合成因法计算“上限值”的特点,通过烃源岩埋深直接获取排滞系数与排烃率。
(2)运移过程
烃类从排出到目的储层需要经过一定距离的运移,途中烃类会散失一部分,因此需计算途中散失烃量,本文用源储距离作取值依据。根据砂岩储层氯仿沥青“A”的平均含量计算砂岩储层滞留烃量,即算出储层单位面积厚度的平均含烃量。通过分析几个刻度区的含烃量平均值,得到单位源储距离的烃类滞留量。如在排烃强度为2×106t/km2地区,依据刻度区氯仿沥青“A”平均值求得其单位储层滞留烃量为1×105t/km2,因此储层残烃率为5%。单位源储距离设为1 km,储层残烃率为5%,而源储距离设为2 km,储层残烃率为10%,这样随着源储距离的增加,储层残烃率程线性增长趋势(图5b)。因此可通过估计源储距离计算出储层滞留率。
(3)聚集过程
聚集过程主要关注储盖组合情况,因为单纯的储层厚度并不能决定烃类的富集程度,只有形成有效的储盖组合后才能大规模富集烃类。储盖组合数与聚集率的关系也可通过刻度区来分析,如通过层区带刻度区来分析单个储盖组合的聚集效率,再通过运聚单元刻度区来分析多个储盖组合下的聚集效率。以中国东部大量断陷盆地为数据基础,根据其多个运聚单元刻度区及其内部层区带刻度区解剖结果,单个储盖组合运聚系数在4%~5%,而2个储盖组合运聚系数为7%~8%,3个储层组合运聚系数为10%左右,4个储层组合运聚系数为13%左右。通过回归分析,认为聚集效率与运聚系数正相关线性相关。因此对比储盖组合数,就可得出聚集效率结果,结果如图5c所示。
(4)储存过程
储存过程指储层能存下的烃量,储层越厚储存率越高,因此本文将储层厚度作为储存率的计算依据。一般一些岩性油气藏中储层厚度是油气富集率的关键。储存率与储层厚度的关系可通过油层有效厚度来统计分析,经过统计大多数油藏油层有效厚度主要集中在10~50 m,而油层有效厚度100 m以上的概率不到1%(据多家油田探明储量报告统计)。那么大概率100 m左右厚的储层就能基本储存下全部烃量,而累计砂岩厚度不足100 m时,储存率会受影响。按照油层有效厚度分布概率,可计算油层有效厚度的累计概率曲线,将此概率曲线作为储存率随储层厚度变化标准,最终关系如图5d所示。
(5)破坏过程
有学者使用不整合数来表示破坏过程,但实际并不合适,同样不整合数地区关联的油气运聚系数变化幅度却很大,比如受1次构造破坏的地区,运聚系数可以从6%~20%,变化大,无法准确取值。因此可以加入盖层性质来综合取值,如将盖层分为厚层泥岩(火山岩)、中层泥岩、薄层泥岩、砂泥互层4种盖层类型,分别分析不同盖层类型下不整合次数对运聚系数的影响。最后通过保存率与运聚系数相关性分析出保存率得取值,结果如图5e所示。
(6)资源比例过程
很多地区成藏条件好,但因储层物性不好,形成常规油藏少、致密油藏多的情况,因此资源类型与储层物性有关。可以用储层埋深代替储层物性,并推算常规油藏的比例,以孔隙度8%作为常规油藏与致密油藏的分界线(贾承造等,2012)。综合大量储存孔隙度随深度变化数据,当埋深3200 m以浅时,平均孔隙度8%~18%,普遍大于8%,因此常规油藏比例100%;而储层4200 m以深时,孔隙度基本都小于8%,因此常规油藏比例为0,具体如图5f所示。
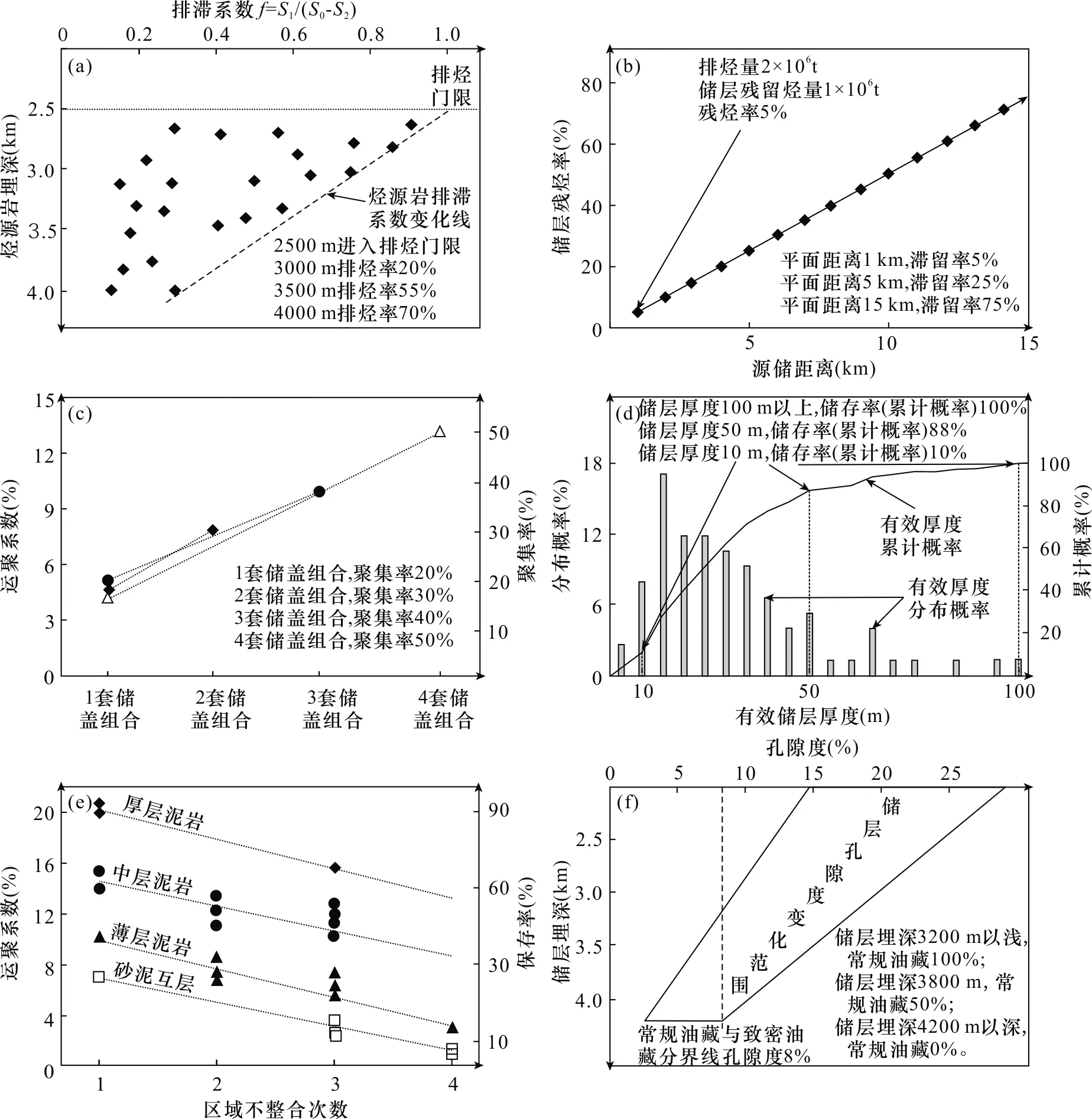
图5 运聚系数模型内各参数取值依据
模型参数的取值普遍对应较大运聚结果,因此计算出的运聚系数普遍较大,可使最终成因法的计算结果偏大,达到计算资源“上限值”的目的。
3 运聚系数模型实例检验
刻度区是一种高勘探程度区,地质资料、成藏过程、储量勘探等方面分析十分全面,可以起到标准区的作用,因此可以通过刻度区检验本文的运聚系数取值模型是否准确。刻度区的高勘探程度可以直接获取运聚系数,其运聚系数可以直接用刻度区的资源量与生烃量比值获得,取值十分准确。本文将以勘探程度较高的南堡凹陷为例,以南堡凹陷内的两个刻度区检验本文运聚系数取值模型,两个刻度区都是以油藏为主。
3.1 南堡凹陷刻度区解剖
用来检验模型的刻度区通常是凹陷级或运聚单元级,但层区带级刻度区研究更精细(张雪峰等,2016),也可以用于检验,因此本文将南堡凹陷两个刻度区作用检验对象,分别是运聚单元级刻度区——高柳刻度区,层区带级刻度区——南堡1号构造东营组一段(Ed1)刻度区。刻度区基本成藏特征如图6所示。其中运聚单元级刻度区是为了准确验证运聚系数取值模型,而层区带级刻度区是为了验证模型在小尺度精细评价时的准确度。
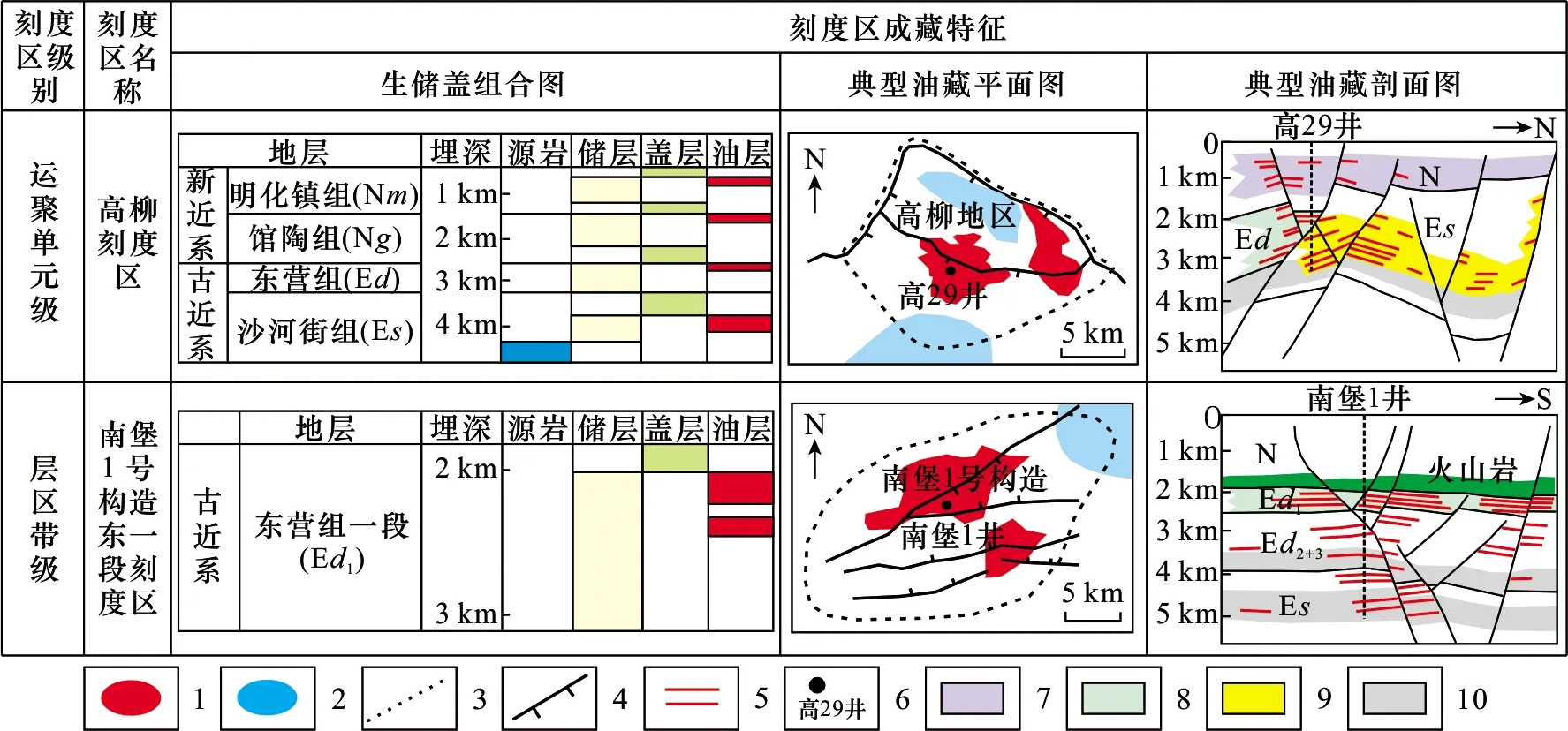
图6 南堡凹陷刻度区成藏特征
刻度区解剖的主要内容又可分为两个方面,一是刻度区油气成藏条件的详细解剖,分析刻度区油气成藏关键地质因素,如生、储、盖等条件;二是运用合理的计算方法确定刻度区资源量,进而分析出刻度区的资源参数,如运聚系数、资源丰度等(胡素云等,2005)。
刻度区之所以称为“刻度”是因为其通过解剖能做为“标尺”进行量化分析,因此其成藏条件必须能以参数形式展现,如烃源岩条件需从烃源岩厚度、有机碳含量、有机质类型等方面进行量化。分别对2个刻度区的成藏条件进行量化分析,结果如表1所示。
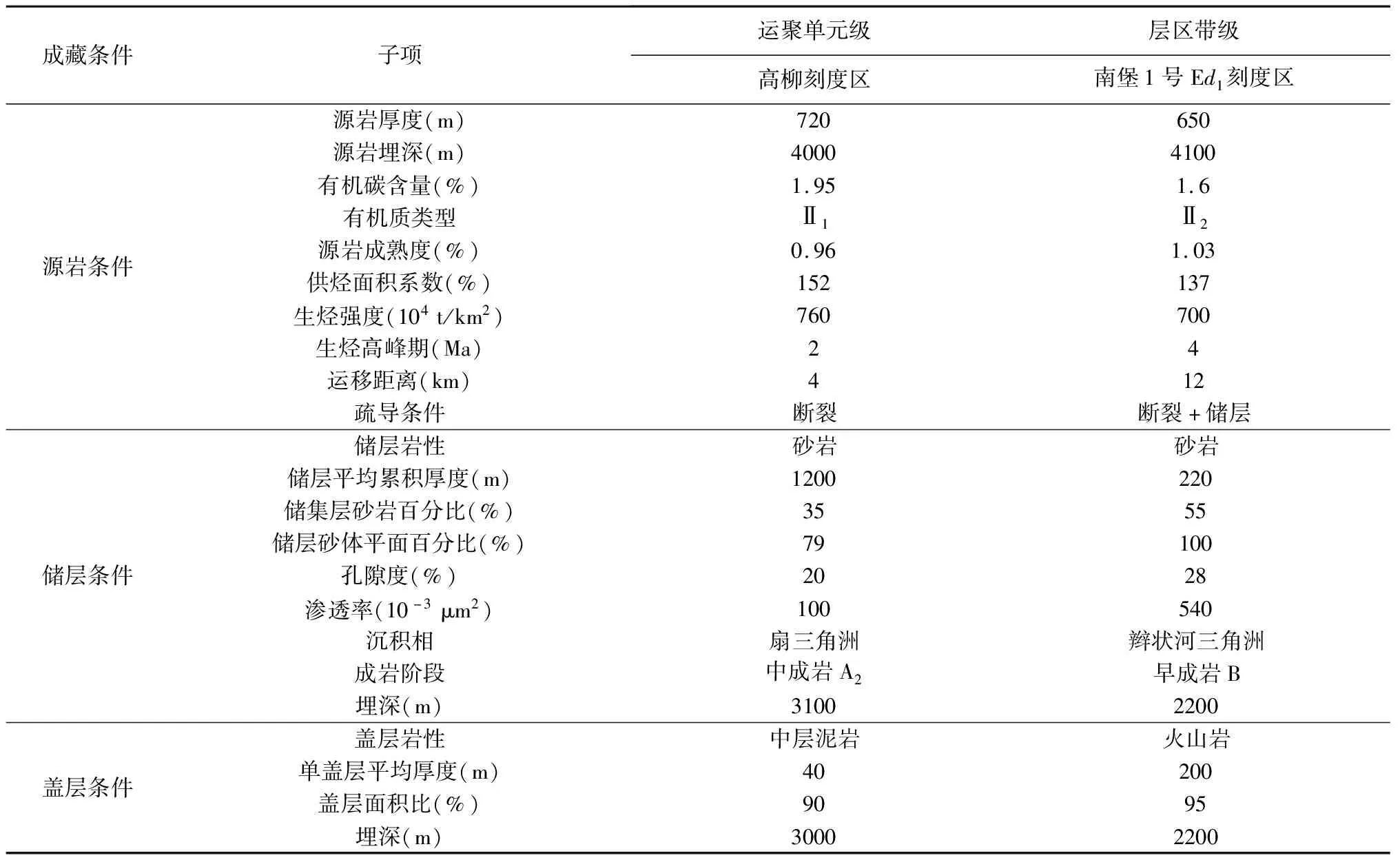
表1 南堡凹陷刻度区成藏条件解剖参数表
资源参数是刻度区类比其它地区时使用的重要参数,通过计算刻度区资源量可以得到所需的资源参数,其中就包括运聚系数。由于刻度区是高勘探程度地区,在资源量计算方法上通常以统计法为主(庞雄奇等,2000;吕一兵等,2011),参考本次刻度区级别,选取适合的计算方法,油藏规模序列法与圈闭加合法。生烃量通过盆地模拟软件求得。计算结果如表2所示,高柳刻度区烃源岩生烃量为24.6×108t,资源量30908×104t,计算得运聚系数为12.6%;南堡1号Ed1刻度区烃源岩生烃量为25.3×108t,资源量12689×104t,计算得运聚系数为5.0%。
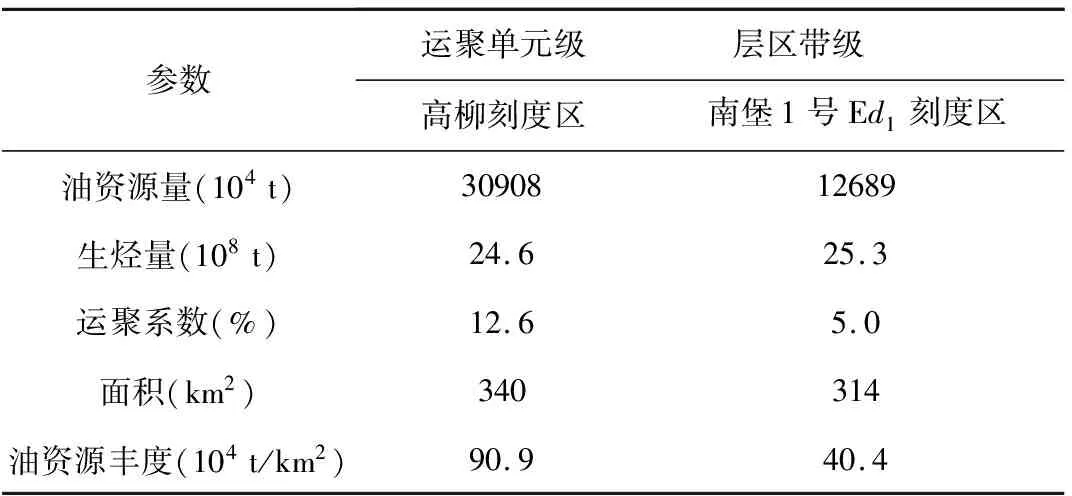
表2 南堡凹陷刻度区资源参数表
3.2 模型检验
将2个刻度区结果代入到运聚系数模型中,其中参数取值分别为:高柳刻度区烃源岩埋深为4000 m,源储距离4 km,储盖组合数4个,储层厚度1200 m,盖层保护为中层泥岩,不整合次数2,储层埋深3100 m;南堡1号构造Ed1段刻度区烃源岩埋深为4100 m,源储距离12 km,储盖组合数1个,储层厚度220 m,盖层保护为火山岩,不整合次数1,储层埋深2200 m。根据模型(图5)可将以上结果转化为排烃率、滞留率、聚集率、储存率、保存率、常规油藏率,结果如表3所示。依据运聚系数模型最终计算出高柳刻度区运聚系数12.6%,南堡1号构造Ed1段刻度区运聚系数5%。对比模型计算结果,与实际运聚系数结果相差小,说明模型准确度高,且在不同级别的预测区均能使用。

表3 刻度区解剖结果检验运聚系数取值模型
3.3 模型的适用性分析
即使运聚系数精确度提高,其始终是成因法计算资源量的一部分,因此运聚系数取值模型也应遵循成因法的特点,即计算资源量的“上限值”。其适用性也应与成因法一致,即适用范围广,使用频率高,准确度较低。因此,本文建立的运聚系数取值模型其目的主要是为了使成因法更加便捷,计算更加简单,在数据不多的情况下也可使用。
不同勘探程度地区对资源量计算准确度的需求不一样,在成因法的使用上会产生不同“需求”。因此可以通过分析不同勘探地区对计算资源量的“需求”来指导成因法的“需求”,再判断运聚系数取值模型是否满足“需求”,得出模型的适用性。结果如表4所示,可以看出模型在中-低勘探程度地区可满足计算“需求”,在计算过程中起到了关键的作用,因此适用性高;而高勘探程度地区,取值模型只是众多计算方法之一,重要程度较低,因此适用性中等。

表4 运聚系数取值模型的适用性分析
4 结论
(1)成因法计算资源量具有明确地质意义,因其高估的特点,可以用于计算油气资源量“上限值”。
(2)油气成藏可划分成6个过程,即排烃过程、运移过程、聚集过程、储存过程、破坏过程、资源比例过程,对这6个过程分别设立参数取值依据可得运聚系数的取值模型。
(3)该运聚系数取值模型在中-低勘探程度地区适用性高,而在高勘探程度地区适用性中等。
