基于深度感知特征提取的室内场景理解
2021-06-18陈苏婷张良臣
陈苏婷,张良臣
(南京信息工程大学 江苏省气象探测与信息处理重点实验室,南京 210044)
0 概述
由于深度卷积神经网络(Deep Convolutional Neural Network,DCNN)[1-3]的快速发展,基于卷积神经网络(Convolutional Neural Network,CNN)的场景理解算法取得了巨大进步。室内场景理解视觉任务以室内场景语义分割为主,为图像中每个像素预测类别标签,是一个基本但具有挑战性的计算机视觉任务。取得准确的室内场景语义分割结果有利于机器人视觉、视觉即时定位与地图构建(Simultaneous Localization And Mapping,SLAM)及虚拟现实等应用的发展。与基于RGB 图像的室内场景语义分割方法相比,基于RGB-D 图像的室内场景语义分割方法可同时使用场景的2D RGB 信息与3D 几何信息,有效解决类别间由于相似特征而导致的分类错误问题,而场景语义分割方法[4-6]通过结合深度信息获得了模型的性能提升。这些方法主要分为两种特征表示形式,即利用人工设置的特征与使用基于CNN 学习的特征。早期的工作主要使用SIFT 与HOG 等人工设定的特征描述子表示RGB 图像特征,然后利用表面法线特征[7]或深度梯度特征[8]辅助场景语义分割。对于CNN 特征提取方法,全卷积网络[9]可通过学习具有高度表达力的特征大幅度地提高场景语义分割能力。一般而言,基于CNN 的RGB-D 场景语义分割方法使用两个全卷积网络分别从RGB 与深度通道提取特征,然后简单融合这两种特征作为最终输出特征,为每个像素预测语义标签。上述方法均要求关联深度标签与RGB 图像,然而相比RGB 图像,从场景中采集深度图更加困难,而且深度图与RGB 图像的对准本身就是一个极具挑战性的问题。
文献[10]提出利用多任务网络预测深度信息并通过简单的特征融合提高模型的场景理解能力,然而未进一步挖掘并利用预测的深度特征。本文通过联合网络模型学习深度特征表示,并提取深度特征中的几何信息以指导深度特征与语义特征的融合,再将融合后的特征与共享网络中的多尺度空间上下文信息与纹理细节信息相结合,产生更鲁棒的语义特征。
1 深度信息感知特征提取
本节详细描述了利用深度信息感知特征提高室内场景语义分割性能的CNN 框架,并且整个CNN模型由联合目标函数进行端到端训练。
1.1 深度信息感知特征学习
本文使用不带有显性深度图标签的深度信息感知特征辅助场景语义分割任务。直观的方法是首先从输入的RGB 图像中预测深度图,然后将深度信息整合到传统的RGB-D 分割网络中[5,11]。该方法将整个场景语义分割任务分为两个阶段,提高了模型的复杂度且不能实现端到端训练。因此,本文利用联合的网络框架,从RGB 图像中同时提取深度特征与语义特征,并通过结合这两类特征提高场景语义分割性能。在此将深度感知特征定义为在语义层上同时编码深度信息与语义信息的特征表示。
具体地,给定一张RGB 图像I,I中的像素表示为Ip∊R3,深度信息感知特征通过一个可学习的映射方程将RGB 像素编码为高维空间中的高语义特征。这些特征的学习过程可被建模为一个优化问题:
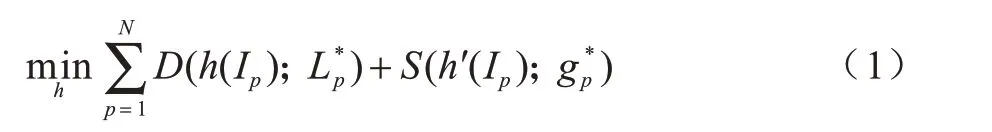
其中:N为I的像素总数;D(h(Ip);)为学习RGB 图像中的深度信息,h(Ip)为深度特征映射项,为编码RGB 图像深度特征的样本标签;S(h'(Ip);)为语义信息编码项,且h'(˙)与h(˙)共享部分参数。为了获得更具辨别力的映射特征h,使用深度卷积神经网络参数化式(1),并通过反向传播优化参数。因此,定义h为fθ,其中f表示由参数θ构成的DCNN。那么,深度感知特征学习的优化方程可重新表示为:

其中,fθ(˙)与(˙)使用相同的DCNN 模型进行参数化。
1.2 基于几何信息的深度特征传输
在学习到深度特征后,利用这些特征提高室内场景语义分割模型的性能。基于像素类同方法提取深度特征中的几何信息,并利用其指导深度特征传输到语义特征中。给定深度感知特征空间中特征点位置i与其邻近特征点位置j∊N(i),对于预测语义标签的得分图中对应位置j的特征点mj,在位置i上经过深度特征传输后的输出特征ni可表示为:
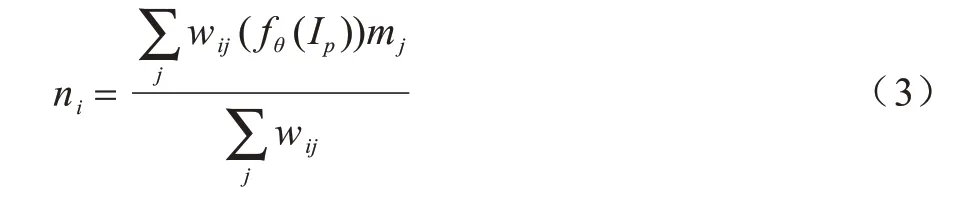
其中,fθ(Ip)为学习到的深度特征表示且wij来源于fθ(Ip)中的几何指导信息的传输权重。因为wij表示深度特征空间中的几何信息类同,所以wij由深度特征向量间的内积运算定义为:

其中,ϕ(˙)与ψ(˙)表示将原先学习到的深度特征通过两个不同的映射方程解耦到两个子特征空间中。为了解决深度信息传播过程中特征图维度的变化,通过另一个映射方程φ(˙)将语义特征mj映射到与ϕ((Ip))和ψ((Ip))相同维度的特征空间φ(mj)中。在具体的室内场景语义分割模型架构中,深度特征的映射由可通过反向传播自动学习的小卷积网络实现。特别地,原语义特征也被重新融合到传输后的特征图中以避免整个深度特征传输过程中语义特征信息的中断。综上所述,将最终的几何信息指导的深度特征传输模块定义为:

1.3 室内场景语义分割网络框架
1.3.1 总体网络模型
本节详细描述了用于室内场景语义分割的DCNN 框架。如图1 所示,DCNN 框架主要包含5 个部分:1)共享的DCNN 基本框架;2)深度特征提取网络分支;3)语义特征提取网络分支;4)几何信息指导的深度特征传输(GIGT)模块;5)金字塔特征融合(PFF)模块。整个室内场景语义分割网络框架为带有多任务预测端的编码网络-解码网络结构。编码网络部分的卷积层提取一般性的场景特征。对于解码网络部分,在图1 中上方解码网络分支提取RGB图像的语义特征,而下方解码网络分支提取RGB 图像对应的深度特征。深度图预测网络分支的特征信息以逐元素相加的形式,传输给对应的语义分割网络分支的特征,以提供多尺度深度信息。GIGT 模块被运用于语义特征提取网络分支的最终输出特征图上,利用学习到的深度特征中的几何信息作为指导提高语义特征表示能力。为了进一步精调语义特征,将结合几何信息指导的深度特征的特征图通过金字塔特征融合模块与共享的DCNN 网络的多尺度特征图相结合。PFF 模块最下方的得分图(在图1 中PFF4的输出)被用于最终的逐像素的语义类别预测。在语义特征提取网络分支的输出端与PFF 模块每层的输出端实施对语义特征学习的监督,同时使用深度图标签监督网络学习RGB 图像中的深度特征。整个场景理解网络由一个联合损失函数进行端到端训练。

图1 室内场景语义分割网络框架Fig.1 Network framework of indoor scene semantic segmentation
1.3.2 GIGT 模块
在本文提出的室内场景语义分割网络框架中,图像深度特征的传输均由带有批量归一化操作的逐元素相乘的卷积层实现。图2 给出了几何信息指导的深度特征传输模块的结构。首先,将深度特征输入到两个特征映射卷积单元精调特征;接着,计算深度特征向量间的类同以获得几何信息;然后,将计算得到的深度特征类同结果作为指导以融合深度特征与语义特征;最后,结合原语义特征与融合后的特征作为语义特征提取网络分支的最终输出特征。整个深度特征传输过程中生成的特征图维持与输入的语义特征图相同的维度。
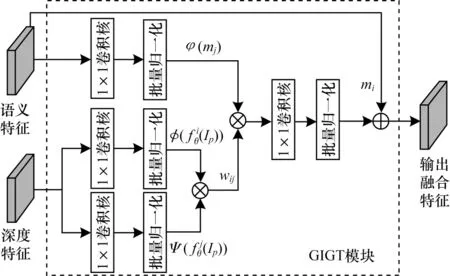
图2 GIGT 模块结构Fig.2 Structure of GIGT module
1.3.3 PFF 模块
由于DCNN 在提取特征时会丢失图像中的细节信息,导致特征的表达能力降低,因此本文提出金字塔特征融合模块修复并丰富语义特征图中的细节信息。因为编码网络最终输出高语义但其中只含有极少细节信息的低分辨率特征图,所以基于高语义特征图的解码模块生成的特征图中仍然极少地包含有效的细节信息。受到目标检测任务中特征金字塔网络[12]的启发,本文将编码网络输出的多级特征图与GIGT 模块输出的特征图相融合提高语义特征的表达能力。PFF 模块的结构如图3 所示。第一个PFF 模块(PFF1)以融合深度信息的语义特征图作为输入,该特征图经过一个1×1 卷积核修正和尺度调整后与编码网络的特征图并置,再通过一个3×3卷积核调整后将特征图传输给下一个PFF模块,同时在每个PFF 模块的输出端逐像素地预测语义类别标签并利用侧边监督调整网络权重。

图3 PFF 模块结构Fig.3 Structure of PFF module
1.4 损失函数
多数室内场景语义分割方法使用交叉熵度量样本预测值与样本标签间的距离。然而,对于NYU-Dv2[7]与SUN RGBD[13]等场景理解数据集,语义类别标签的分布极端不平衡,即少数语义类别标签主导整个数据集,例如,wall、floor 和chair 等类别拥有比tv、toilet 和bag 等类别更多的样本。这将使场景语义分割网络模型偏向于学习这些主导的语义类别,导致模型在具有少数样本的语义类别上产生过拟合现象。为了缓解训练样本数据不平衡的问题,基于Focal Loss[14]提出如下的语义分割损失函数:

其中,p为训练图像中的像素索引,c为训练集图像场景中的物体类别,sp,c为像素p预测为类别c的概率且为其样本标签。通过该损失函数可提高难训练样本的损失贡献度而压制易训练样本的损失贡献度,例如:如果一个像素被预测正确且置信度为0.9,那么该像素损失值的权重为(1-sp,c)2=0.01;如果一个像素被预测错误且置信度为0.1,那么该像素损失值的权重为0.81。此时,式(1)中语义特征优化数据项可表示为Lseg。
除了语义特征学习的监督项外,学习深度感知特征需要受到深度领域的监督。本文借鉴深度估计算法[15]的思想,使用berHu 损失函数作为深度监督项,定义为:
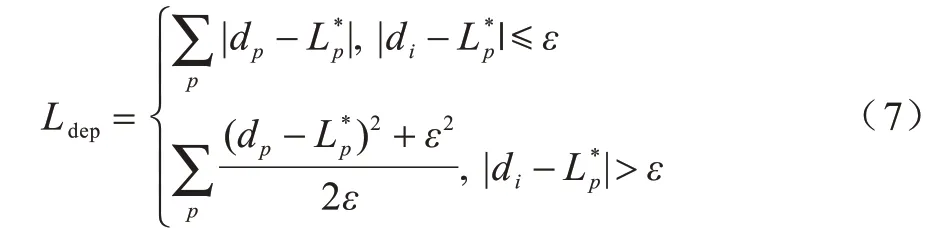
其 中,dp为由深度特征fθ(Ip)预测的深度图,ε=为深度图样本标签。此时,式(1)中的S(h′(Ip);)深度特征优化数据项可表示为Ldep。
本文结合金字塔特征融合模块与多个特征层上输出的语义类别标签预测的损失函数(称为侧边监督),提出的室内场景语义分割网络框架的最终联合损失函数表示为:

2 实验与结果分析
2.1 实验数据集与评价标准
实验使用NYU-Dv2 数据集[7]与大规模的SUN RGBD 数据集[13]评估本文方法。NYU-Dv2 数据集样本是由Microsoft Kinect 从464 个不同场景捕获而来,共包括1 449 张同时含有语义标签与深度信息的训练图像样本,其中,来自249 个不同场景的795 张图像用于训练,来自215 个不同场景的654 张图像用于测试。NYU-Dv2 数据集涵盖近900 个不同的语义类别,实验选用40 个类别标签[16]。SUN RGBD 数据集包含10 335 张RGB-D 图像,其中每张图像同样具有逐像素的语义标签,在实验中利用含有5 285 张训练图像的训练集训练模型以及含有5 050 张测试图像的测试集评估模型。基于SUN RGBD 数据集的实验共涵盖37 个语义类别标签。为了全面地评价本文方法,使用像素准确度(Pixel Accuracy,PixAcc)、平均准确度(mean Accuracy,mAcc)与平均交并比(mean IoU,mIoU)作为评价指标。
2.2 实验过程与参数设置
基于深度感知特征提取的室内场景语义分割网络模型以预训练的ResNet-50[3]作为参数共享的编码网络,并由4 个反卷积层构成解码网络分支。设置解码网络部分所有特征图的卷积通道数为256。整个分割模型的参数量为1.43×106,计算能力为5.3×109FLOPS。除了预训练的ResNet-50 外,所有卷积核参数使用文献[17]方法进行初始化。整个网络模型由β1为0.9、β2为0.999 的Adam 优化算法[18]进行优化。对于NYU-Dv2 训练集,设置总迭代次数为6×104,初始学习率为10-2,30 次迭代后学习率降至10-3,4.5×104次迭代后降至10-4。对于SUN RGBD 训练集,设置总迭代次数为1.2×105,初始学习率为10-2,60 次迭代后降至10-3,1.0×105次迭代后降至10-4。本文提出的场景理解方法使用PyTorch v1.4 搭建模型框架,并在配置有4 块12 GB 存储容量的NVIDIA Titan X GPU 的工作站上训练,且设置输入的训练图像的batch size 为4,整个训练过程持续22 h。此外,图像色彩增强与随机水平翻转的特征增强方法被用于丰富训练图像的特征。
2.3 与传统方法的性能比较
2.3.1 在NYU-Dv2 数据集上的性能比较
表1 给出了本文方法与文献[4-5,10-11,15]方法、FCN[9]、RefineNet[19]、3DGNN[20]、D-CNN[21]、RDFNet[22]和ZZNet[23]在NYU-Dv2 数据集上的性能比较结果,其中,“—”表示对应方法无此评价指标值。可以看出,本文算法获得85.2%的PixAcc、69.5%的mAcc与60.7%的mIoU,相比其他方法取得了显著的性能提升。值得注意的是,在NYU-Dv2 数据集上训练的大部分方法都是基于RGB-D 的方法,意味着这些方法在测试时也将深度图标签作为输入辅助模型预测。尽管本文方法仅输入RGB 图像评估算法,但相比基于RGB-D 的方法仍表现更好。与本文方法类似,RefineNet[19]与RDFNet[22]也利用了多尺度的特征图信息,但仅结合了编码网络部分的特征并且不带有侧边监督。由表1 结果可知,利用GIGT 模块与带有侧边监督的PFF 模块可显著提升模型性能。

表1 12种分割方法在NYU-Dv2数据集上的性能比较结果Table 1 Performance comparison results of twelve segmentation methods on the NYU-Dv2 dataset %
为了评估类别样本数据分布不均衡情况下的模型表现,表2 针对不同语义类别给出了IoU 比较结果。可以看出,相比文献[4-5]方法、FCN[9]、RefineNe[t19]和RDFNet[22],本文方法在大部分语义类别上表现出更好的预测结果,尤其对于clothes、books、box 与bag等一些难以预测准确的类别,仍可取得更高的IoU值。本文设计的GIGT 模块、与其紧密连接的PFF模块和新引入的损失函数使得模型几乎在所有类别上均表现出较强的鲁棒性。然而,本文方法对person、wall 与floor 等类别的预测性能不佳,这是因为不同场景的深度图可能与其对应的2D 外观存在较大差异。

表2 6 种分割方法在各语义类别上的IoU 比较结果Table 2 IoU comparison results of six segmentation methods in each semantic category %
2.3.2 在SUN RGBD 数据集上的性能比较
表3 给出了在大规模的SUN RGBD 数据集上本文方法与文献[4,23]方法、FCN[9]、RefineNe[t19]、3DGNN[20]、D-CNN[21]、RDFNet[22]和Bayesian-SegNet[24]的性能比较结果。可以看出,本文方法取得86.3%的PixAcc、68.4%的mAcc 与52.7%的mIoU,在所有评价指标上均优于传统方法,验证了基于深度感知特征提取的室内场景理解方法的有效性。值得注意的是,SUN RGBD数据集内包含许多由场景捕获设备得到的低质量深度图,可能会影响GIGT 模块的有效性。然而,从实验结果可看出,即使在未去除这些含有较多噪声样本的情况下,本文方法仍然可获得最佳的预测效果,这表明深度特征提取网络学习到的深度感知特征可有效地表达3D 几何信息。

表3 9 种方法在SUN RGBD 数据集上的性能比较结果Table 3 Performance comparison results of nine methods on the SUN RGBD dataset %
2.4 各模块的有效性验证
本节在NYU-Dv2 数据集上研究本文模型中的各模块对模型性能的影响。实验使用单独的语义特征提取网络作为基本框架(由seg 表示),seg+GIGT表示在单独的语义特征提取网络基础上加入GIGT模块进行实验,seg+Lseg+HHA 表示在单独的语义特征提取网络基础上加入Lseg损失和HHA 模块,seg+Lseg+多尺度深度特征表示结合语义特征提取网络、Lseg损失和多尺度深度特征表示,seg+Lseg+多尺度深度特征+GIGT+PFF 表示结合语义特征提取网络、Lseg损失、GIGT 模块和PFF 模块,实验结果如表4 所示。将损失函数Lseg用于训练网络模型可增加4.2 个百分点的mIoU,这主要是因为损失函数使网络偏向于学习仅含有少量样本且难训练的语义类别。尽管使用深度图标签作为输入的模型测试方法(由HHA[16]编码)验证了利用深度信息的有效性,但本文通过简单结合多尺度深度特征的方法得到高于其2.3 个百分点的mIoU。在结合多尺度深度特征方法的基础上引入GIGT 模块可使模型提升10.3 个百分点的mIoU。最终通过增加PFF 模块以整合GIGT 模块的输出信息与编码网络的多尺度空间上下文信息及纹理细节信息能使模型再次获得明显的性能提升。

表4 本文分割模型中各模块的有效性分析结果Table 4 The effectiveness analysis results of each module in the proposed segmentation model %
2.5 深度信息监督方法分析
尽管本文模型在测试时无需输入任何深度信息,但深度信息监督对于网络训练而言仍然是十分必要的。本节分析模型基于部分深度信息实施半监督训练的结果,实验基于NYU-Dv2 数据集,构建4 个训练样本集,分别包含训练数据中20%、40%、60%与80%的深度图样本。所有深度图子集中的元素都是通过随机采样原数据集中的样本得到。对于使用不同深度图子集的训练样本中可能不存在深度信息标签的情况[25],在此固定深度特征提取网络的参数且模型的其他部分仍然使用与上述实验相同的训练策略。实验结果如表5 所示,在不使用深度信息训练模型的情况下,本文方法仅取得41.5% 的mIoU,相比使用全部深度图样本训练的模型降低了19.2 个百分点。值得注意的是,即使仅利用20%的深度信息作为监督,本文模型也可获得比未使用深度信息作为监督的情况下更好的模型性能,该结果表明深度信息对提高室内场景语义分割模型性能具有重要意义。

表5 深度信息监督方法的分析结果Table 5 The analysis results of supervision method with depth information %
2.6 可视化结果分析
图4 在NYU-Dv2 验证集上给出了本文方法的可视化输出结果,为进行详细对比,也给出了联合学习网络模型在移除GIGT 模块或PFF 模块后的室内场景语义分割可视图,如图4(c)和图4(d)所示。可以看出,通过学习深度感知特征可成功地提取RGB 图像中的3D几何信息。例如,图4(a)的第4 行对应的RGB 图像中的pillow 类别与bed 类别非常相似,很难直接通过2D外观区别这两类物体(图4(c)的第4 行对应的分割图存在该问题),然而将语义特征与深度特征融合后,可以很好地区分这两个类别(图4(d)与图4(e)的第4 行分割图验证了该方法的有效性),并且图4(a)的第3 行对应的RGB 图像中的desk 类别和cabinet 类别也为类似的情形。此外,PFF 模块融合了编码网络框架中不同深度的RGB 图像特征,有利于挖掘多尺度空间上下文信息和物体细节信息用于辅助模型学习。例如,图4(a)的第4 行对应的RGB 图像中的picture 类别与wall类别在空间和语义上通常是强相关的,并且图4(a)的第5行对应的RGB 图像中的desk 类别与books 类别也是强相关的。

图4 室内场景语义分割可视化结果Fig.4 The visualization results of indoor scene semantic segmentation
3 结束语
本文提出一种新的室内场景理解网络框架,建立结合语义特征提取网络与深度特征提取网络的联合学习网络模型,通过RGB 图像学习更具表达力的深度信息感知特征,使其能够有效地指导与辅助场景语义分割任务的实施。联合学习网络模型主要包括几何信息指导的深度特征传输模块、金字塔特征融合模块与针对训练样本数据不平衡问题的损失函数。深度特征传输模块应用学习到的深度特征中的几何信息指导深度特征与语义特征的融合,金字塔特征融合模块充分挖掘编码网络中的多尺度空间上下文信息与纹理细节信息,并将这些信息与深度特征传输模块的输出特征相结合生成更鲁棒的语义特征。实验结果表明,该模型在输入单张RGB 图像的情况下可同时捕获图像的2D外观与3D 几何信息,并且在NYU-Dv2 与SUN RGBD数据集上相比传统分割方法具有更好的室内场景语义分割性能。下一步尝试将注意力机制引入室内理解网络框架中提高联合学习网络模型的学习效率,同时通过网络轻量化设计加快模型运行速度。
