结合实体描述信息的跨句包关系抽取方法
2021-06-18申长虹姜景虎崔家铭
孙 新,申长虹,姜景虎,崔家铭
(1.北京理工大学 计算机学院,北京 100081;2.复旦大学 信息科学与工程学院,上海 200433)
0 概述
关系抽取是指从文本中发现与识别句子中已标记实体对之间的语义关系,这种语义关系常以三元组<头实体,关系,尾实体>的形式表达。关系抽取是信息抽取的关键技术,在知识图谱构建、智能问答和语义检索等方面被广泛应用。
在现有的实体关系抽取方法中,有监督方法的准确率较高,但缺点是费时费力,无法较好地完成大规模的关系抽取任务。为了能够自动获取高质量的标注数据,文献[1]提出了远程监督的方法,通过数据自动对齐远程知识库的方法解决开放域中大量无标签数据自动标注的问题。由于远程监督的关系抽取方法能够大幅减少标注成本,因此近年来受到研究者的广泛关注。
远程监督方法最大的问题在于通过知识库标注的句子往往存在噪声,如实体间存在多种关系,无法确定包含该实体对的句子具体表达哪种关系。此外,提取特征时引入的误差传播问题也会影响关系抽取的效果。针对这些问题,研究者提出多实例学习和多实例多标签学习的方法[2-3]来解决错误标注问题,并通过注意力机制对句子进行赋权。文献[4]将多实例学习与分段卷积神经网络模型(Piecewise Convolutional Neural Network,PCNN)相结合来进行远程监督的关系抽取,文献[5]在此基础上引入注意力机制,综合利用句包中所有语句的信息,为不同的句子赋予不同的权重,同时丢弃一些噪音数据,进一步提升了关系抽取模型的性能。
虽然很多关系抽取方法[6-8]都使用了注意力机制,但是这些工作所采用的注意力机制只是将每个关系当作独立的个体来看待,孤立地选取适用于每种关系的语句,没有充分利用关系之间存在的丰富关联信息。例如,在句子“我喜欢吃苹果”中,对于关系“喜欢”,此句就是高质量句子,那么相应地,可以认为对于关系“讨厌”,此句便为低质量句子。对于蕴含关联信息的关系,句子的表征也有一定的相关性。
此外,现有方法往往集中在探索句子的语义信息层面上,忽略了实体的描述信息对关系抽取效果的影响。在上述例句中,如果没有“苹果”是一种水果的信息,则很难判断该句表达的是哪种关系。在缺乏背景知识时,“苹果”可能是指电子设备,而句子并不表示关系“喜欢”。因此,实体本身的描述信息能够帮助改善关系抽取的效果。
本文提出一种结合实体描述信息的跨句包关系抽取模型(PC2SAD)。利用PCNN 进行句编码,获得更多与实体相关的上下文信息。同时为减弱错误标签带来的噪声,使用跨关系跨句包注意力机制获取关系特征,弥补传统注意力机制孤立分析单个关系的不足,更好地从远程监督的噪声数据中鉴别有效的实例,从而学习到更准确的关系表示。此外,为在跨关系跨句包注意力模块中提供更好的实体表征,使用卷积神经网络(Convolutional Neural Network,CNN)从Freebase 知识库与Wikipedia 文本中提取实体的描述信息,补充关系抽取任务所需的背景知识。
1 相关工作
实体关系抽取能够快速高效地从开放领域的文本中抽取出有效信息,是信息抽取的关键任务。现有的关系抽取方法主要分为有监督、半监督、弱监督、无监督和远程监督等方法[9-10],其中,有监督关系抽取方法和远程监督关系抽取方法是实体关系抽取的常用方法。
有监督的关系抽取旨在从大规模标注语料中获取表达实体间语义关系的有效特征,在已标注的数据基础上训练分类器,主要方法有基于规则、基于特征工程、基于核函数和基于深度模型的方法等。基于规则的方法[11-12]主要采用模板匹配的方式进行关系抽取,但是该方法依赖于专家经验,代价高且可移植性差,难以被推广使用。基于特征工程的方法[13-14]通过从句子中提取出相关词法、语法和句法信息获取有效特征。基于核函数的方法[15-16]通过构建结构树并计算关系距离以抽取关系实例,缓解了特性稀疏性问题。基于深度模型的方法能够自动学习句子特征,避免特征提取的错误传播问题,提升关系抽取的效果。虽然有监督的关系抽取方法准确率高,但是需要大量人工标注的语料,这限制了大规模的实体关系抽取。
为解决人工标注语料严重缺乏的问题,文献[1]提出一种不用人工标注的远程监督方法,其利用Freebase 知识库与Wikipedia 文本进行对齐,获取大量关系三元组。远程监督基于如下假设:如果已知两个实体间存在某种关系,那么所有包含这两个实体的句子都潜在地表达了该关系。因此,可以借助外部知识库将高质量的实体关系对应到大规模文本中,然后通过有监督的方法训练得到关系抽取模型。
文献[17]根据上述假设,将基于远程监督的关系抽取问题形式化为多实例单标签问题,只关注于句包体现了实体对间的哪些关系,选择使关系概率最大的实例语句作为实体对的表示,从而更契合于实际应用场景。文献[2-3]考虑到在一个实体对中可能有不止一种关系成立,在多实例学习的基础上,更进一步地将该问题形式化为多实例多标签学习问题。
文献[18]使用卷积神经网络进行关系抽取,输入句子中所有单词的词向量和位置向量,通过卷积和池化操作提取句子特征,缓解了使用自然语言处理工具进行特征提取可能导致的误差传播问题。文献[4]在卷积神经网络的基础上进一步提出PCNN模型,根据实体在句中的位置将句子分段进行池化,得到更多与实体相关的上下文信息,也有效解决了特征提取误差传播问题。PCNN 虽然结合多实例学习方法提升了远程监督关系抽取的效果,但是多实例学习只给句包打标签,从包含实体对的句包的所有语句中只选择一个句子,这会导致丢失大量有用句子的信息。
文献[5]在文献[4]的基础上提出了基于注意力机制的多实例学习策略,使用关系向量作为注意力,对一个句包中的每个句子分配权重,以表示在该关系上不同句子的重要程度,并对句子向量进行加权求和得到句包嵌入向量,在此基础上直接对句包进行分类。
文献[19]提出双向长短时记忆网络来提取句子特征,同时应用注意力机制识别噪声句子。文献[20]指出句包中的假正例仍然是影响关系抽取效果的主要因素,并且识别错误标注的句子应该是决策问题而不是注意力的权重分配,在此基础上提出一种基于强化学习框架来训练关系抽取器。文献[21]提出的强化学习方法包含句子选择器和关系抽取器,句子选择器遍历句子并做出动作是否选择当前句子,关系抽取器用选择出来的句子做关系分类并给出奖励,该方法适用于句子级别的关系抽取而不是传统的包级别。
尽管远程监督关系抽取方法已经取得了显著的发展,但是仍然面临一些亟待解决的问题:首先,多数工作孤立地对每个关系建模,忽略了关系之间丰富的相关性;其次,现有的关系抽取方法只关注从文本中直接抽取实体之间的关系,忽略了实体描述所提供的有用的背景知识。为解决上述问题,本文利用关系之间丰富的相关信息减少噪音句子的影响,设计结合实体描述信息的跨关系、跨句包注意力机制,以期提高关系抽取性能。
2 跨句包关系抽取模型
本文在PCNN 模型基础上,提出一种结合实体描述信息的跨句包关系抽取模型PC2SAD,模型结构如图1 所示。首先利用PCNN 进行句编码,提取句子中的实体关系;然后利用跨关系跨句包注意力机制获取关系特征,从而既充分利用关系的相关性,又减少知识库中未出现或者过时事实的影响,尤其减少整包句子均为噪声情况的影响;最后使用卷积神经网络模型从Freebase 和Wikipedia 中提取实体描述信息的特征向量,并通过增加对关系抽取模块目标函数的约束,使其接近相应的实体向量。
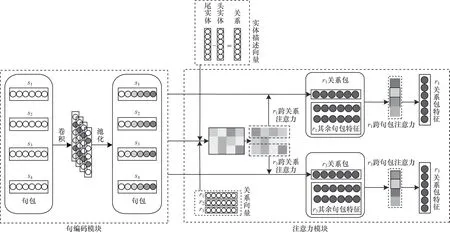
图1 PC2SAD 模型架构Fig.1 Architecture of PC2SAD model
2.1 句编码
传统的远程监督特征提取主要是利用自然语言处理工具进行数据集的特征提取,这会导致误差逐层传播,影响关系抽取的效果。本文选用PCNN 模型进行句编码,根据实体所在的位置将句子切分成3 段进行池化,从而得到更多与实体相关的上下文信息,以解决特征提取的误差传播问题。为方便表述模型内容,进行以下符号说明:
1)将含有相同实体对的若干句子组成的句子集合称为句包B。第i个句包记做其中,si,j是第i个句包Bi中包含相同实体对的第j个句子,j∊[1,nb],nb为句包Bi中句子的数目。
2)句包B中的每个句子用s表示,句子s的分布式表示记做句子s的特征向量s′。
3)对于句包B中第j个句子s={w1,w2,…,wm},每个单词wi经过向量化处理成词向量w′i,每个单词wi的实体相对位置特征经过向量化表示为位置向量pi。其中,m是句子s的单词个数,j∊[1,nb],nb是句包中句子的个数。
为充分获取句子的高维语义表示,解决句子特征提取的误差传播问题,PC2SAD 模型利用PCNN 模型将给定的句子转换成对应的特征向量,具体过程如下:
1)对于句子s,PC2SAD 模型拼接每个单词的词向量wi′与位置向量pi,作为模型的输入向量xi。此处,xi∊Rki,ki=kw+kp×2,其中,kw为单词wi的词向量维数,kp为位置向量维数。型定义qi∊Rl×d为第i个滑动窗口内的单词输入向量
2)对输入的xi使用PCNN 模型进行句编码。模xi的拼接:

W为其卷积核矩阵,其中,dc是句子特征向量的维度大小。
卷积层的第i个卷积输出为:

其中,b是一个偏置向量,f是激活函数。
经过卷积之后,传统的做法是直接进行池化操作,如最大池化,但是简单地进行最大池化并不能很好地捕捉实体词在句子中的结构信息,句法解析的准确性将会随着句长的增加而显著降低[17]。考虑到实体对在句子中存在一定的结构特征,即句包中的每个句子都被两个实体词分成三部分,利用这种内部结构信息将有助于捕捉实体间关系[4],因此,PCNN 模型使用分段最大池化操作以保留更细粒度的信息,获取准确的句编码表示。
句子s的特征向量s′∊的第j维通过分段池化操作得到:

此处,卷积层输出的结果被头实体和尾实体分成了三部分,i1和i2是句子s的头实体和尾实体在句中的位置。
句子s的特征向量s′∊为三部分池化结果的拼接:

通过分段池化操作将低层特征组合成高层特征,能够在保留句子细粒度信息的同时,避免利用自然语言处理工具进行特征提取所导致的错误传播问题。
2.2 跨关系跨句包注意力机制
在远程监督方法中,通过知识库标注的句子往往含有较多的噪声,包含实体对的许多句子可能并没有表达出该实体对的对应关系,这个问题会严重影响关系抽取的性能。本文在句编码的基础上,构建跨关系跨句包注意力机制,充分考虑和利用关系的相关性,以缓解错误标注句子对模型的影响。PC2SAD 模型先利用跨关系注意力为每种关系计算句包特征,减少噪音句子或者不匹配句子的影响,再利用跨包注意力为每种关系构造一个关系包,使其能够更多地关注高质量的训练实例。
2.2.1 跨关系注意力
在利用句编码将句包Bi中的每个句子si,j表示为s′i,j之后,依据句子和关系之间的相似度为每个句子计算其注意力得分:

其中,rk是第k个关系对应的注意力参数。
为捕捉关系间的相关性,利用贝叶斯规则计算预期的注意力权重βj,k,可以得到:

其中,αj,k为第k个关系在第j个句子上的条件概率计算值,βj,k为第j个句子在第k个关系下的条件概率计算值。
第k个关系下句包Bi的特征向量计算为:

依据句子与所有关系之间的相似度来计算跨关系注意力,最终得到每个关系对应的句包特征向量。
2.2.2 跨句包注意力
句子级别的注意力基于以下假定:如果两个实体间存在某种关系,那么在所有这两个实体共同出现的句子中,至少有一句表达了这种关系。然而,由于远程监督中大量数据被错误标记,句包中存在过时事实或者不存在事实等噪音数据,甚至整个句包都为噪音数据。因此,PC2SAD 利用关系包将注意力集中到更高质量的训练实例上。
相同关系的句包组成的集合称为关系包,其分布式表示向量称为关系包的特征向量。对于关系包B={B1,B2,…Bns},ns是关系包的大小,句包Bi被标记为表达第k个关系。
在跨关系注意力上,PC2SAD 模型捕捉句子之间的相关性,同时为每个句包构建其特征向量。PC2SAD 模型利用注意力机制将这些特征向量组合在一起。
关系包B的特征向量f计算方法如下:

其中,bi,k是句包Bi在第k个关系下的特征向量,rk是第k个关系对应的注意力参数,可以用余弦相似度计算得到。
多实例方法[4]只使用句包中一个句子的实例信息,未能充分利用包中的训练实例。本文提出的跨包注意力机制不仅能够解决这个问题,而且在综合利用包中所有训练实例信息的基础上,通过二次筛选和去除包中的无用信息,将关系相同的句子组合到一起,从而更好地改善远监督关系抽取的效果。
2.3 实体信息提取
实体描述信息可以为句子中的实体提供丰富的背景知识。PC2SAD 模型使用包含一个卷积层和一个池化层的CNN 模型,从实体的描述信息中提取特征。
在PC2SAD 模型中,为使实体的向量接近描述的向量,将它们之间的误差定义为:

基于TransE[22]思想,关系可以表示为尾实体减去头实体。例如,关系“/location/location/contains”可以表示为关系对应的实体对“Belle Harbor”与“Queens”之差:r≈wBelle_Harbor-wQueens,也可以表示为实体对“Celina”与“Ohio”之差:r≈wCelina-wOhio。
理论上,对于同一关系,不同实体对的计算结果是相似的,并使用平均值表示关系。
实体描述信息来源于Freebase 和Wikipedia,在Freebase 中提取25 271 个实体描述信息,在Wikipedia 中提取14 257 个实体描述信息。
在训练过程中,首先使用极大似然函数来训练跨关系跨句包注意力模块,然后再联合训练实体描述模块。
极大似然函数定义如下:

其中,nsb是训练过程中关系包的数目,li表示关系包的标签。
联合训练的损失函数为:

在训练过程中采用随机梯度下降来最小化目标函数,从训练集中随机选择数据进行训练,不断迭代,直到损失函数收敛。
3 实验与结果分析
为验证本文方法在缓解特征提取误差传播、减弱错误标签噪声数据影响以及补充实体背景信息方面的有效性,设计3 组实验,分别从语料库、句子和句子数量层面验证PC2SAD 模型的关系抽取效果。
3.1 数据集和参数设置
实验使用文献[2]所使用的数据集和NYT10 数据集[17]。文献[2]所使用的数据集(本文中用NYT11表示)共包含395 个人工标注的句子。NYT10 数据集[17]共包含53 种关系类型,其中,训练数据包含522 611 个句子、281 270 个实体对和18 252 个关系事实,测试数据包含172 448 个句子、96 678 个实体对和1 950 个关系事实。表1 列出了实验中使用的所有训练参数。

表1 训练参数设置Table 1 Setting of training parameters
3.2 结果分析与比较
3.2.1 语料库层面关系抽取方法比较
为证明PC2SAD 模型的有效性,本文以PCNN 模型作为句子编码器,在NYT10 数据集上与以下模型进行比较:
1)PCNN:将PCNN 作为远监督关系抽取的基线模型。
2)PCNN+ATT:以PCNN 为句编码模块,结合普通注意力机制ATT,验证远监督关系抽取中注意力模块的有效性。
3)PCNN+C2SA:以PCNN 为句编码模块,验证C2SA 在关系抽取中的有效性。
实验采用准确率-召回率曲线对不同方法性能进行衡量,即通过对比测试集上每个句子在每个关系上概率的高低,逐一判断每个句子在该关系上的正确性,计算得到准确率-召回率曲线,如图2 所示。可以看出,PC2SAD 在整个召回率范围内显著优于基于人工特征的方法,这表明人工特征无法简洁地表达句子的语义含义,同时,借助自然语言处理工具所带来的错误同样也会影响关系抽取的性能。相比之下,PC2SAD 可以很好地表达关系抽取所需的句子语义信息。
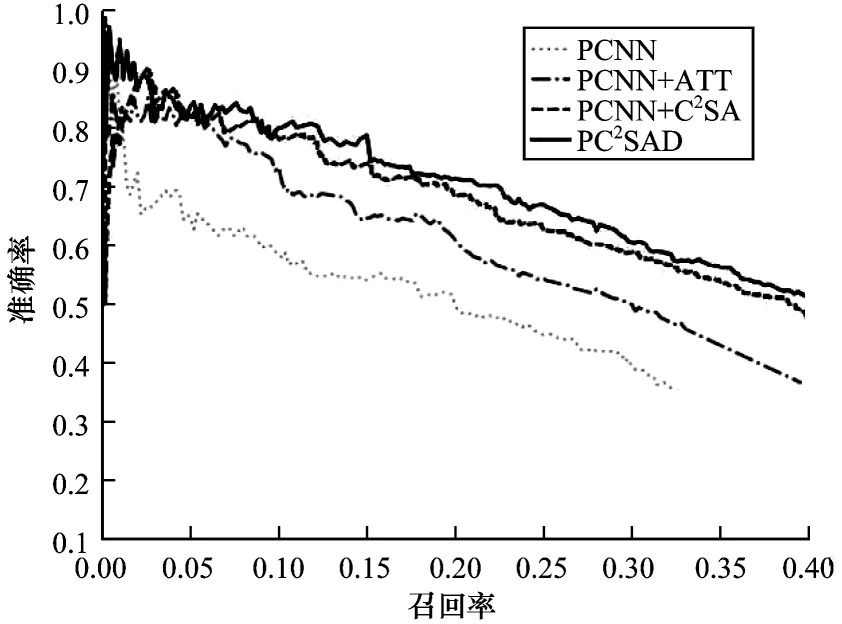
图2 不同关系抽取方法的准确率-召回率曲线Fig.2 Precision-recall curves of different relation extraction methods
对于PCNN+ATT 模型,加入ATT 方法可以使模型相比于原始的PCNN 有更好的关系抽取效果,这表明加入ATT 可以有效过滤对关系没有意义的句子,缓解远监督关系抽取中存在的错误标注问题。
对于PCNN+C2SA 模型,图2 的准确率-召回率曲线验证了C2SA 方法的有效性,这表明跨关系跨句包注意力模块对关系抽取的性能要优于普通注意力方法ATT,跨关系注意力确实能够提高实例选择的质量,而跨句包注意力对过滤知识库事实不匹配或者不存在的噪音数据也有一定的缓解效果。
对于PC2SAD 模型,从图2 中可以看出,该模型的效果优于上述所有模型,这表明在PCNN 作为句编码、C2SA 进行实例权重选择基础上,加入实体描述信息,不仅为预测关系提供了更多的信息,同时也为注意力模块带来了更好的实体表征。
3.2.2 句子层面关系抽取方法比较
为进一步验证PC2SAD 中加入跨关系跨句包注意力机制和实体描述信息后整个模型在句子级关系抽取方面的性能优势,比较不同方法针对特定句子识别实体对的关系类型的性能。在文献[2]所使用的数据集上,分别以PCNN、循环神经网络(Recurrent Neural Network,RNN)为编码模块,替换普通注意力网络ATT、跨关系注意力CRSA、跨关系跨包注意力C2SA 以及加入实体描述信息后的模型,以此进行实验对比,实验结果如表2 所示。
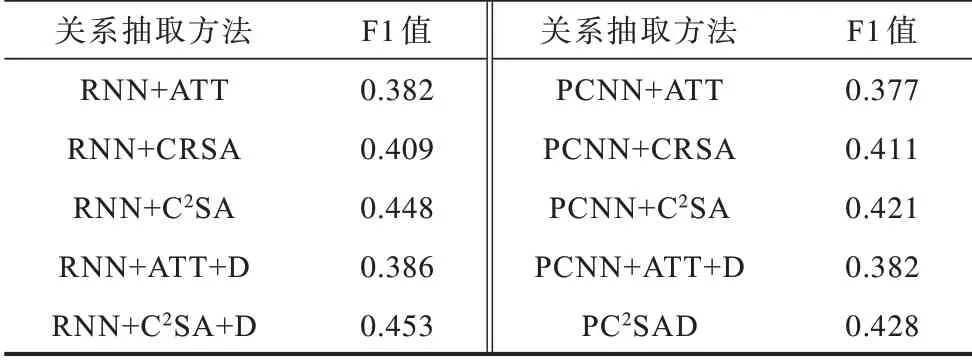
表2 句子层面不同关系抽取算法的F1 值比较Table 2 F1 value comparison on the sentence-level relation extraction
从表2 可以看出:
1)以PCNN 和RNN 为句编码模块的关系抽取效果相当,而PC2SAD 整体上优于其他模型。这一实验结果验证了实体描述信息在关系抽取任务中的有效性,其与ATT、C2SA、PCNN 模型相结合后,关系抽取的效果得到了更好的提升。
2)PCNN+C2SA 模型效果优于PCNN+ATT,这表明相比于ATT,C2SA 不仅具备ATT 已有的噪声数据权重更低的优势,更能充分利用关系的相关性,尤其是减少句包中所有句子均为噪声数据时对模型性能的影响。
3)RNN/PCNN+CRSA 模型比PCNN+ATT 效果要好,这表明跨关系注意力机制通过计算句子与所有关系之间的相似度,对于噪声数据或者错误标注的数据计算得到的权重会比较低,因此,可以降低错误标注的影响。而PCNN+C2SA 模型的效果要更好,这表明句包中的句子有些是过时的或者是不存在的事实,跨包注意力将关系相同的句向量组合到一起,可以丢弃没有价值的信息,从而关注更高质量的训练实例。
3.2.3 句子数量对关系抽取性能的影响
在NYT10 原始测试数据集中,有74 857 个实体对仅对应于一个句子,在所有实体对上占比接近3/4。由于PC2SAD 模型的优势在于能够处理包含多个句子实体对的情况,因此本文比较CNN/PCNN+MIL、采用注意力机制的CNN/PCNN+ATT 和结合实体描述信息的PC2SAD 在具有多个句子的实体对集合上的表现。此处,MIL 是文献[4,18]提出的多实例学习方法。
实验内容如下:
1)One:对于每个测试实体对,随机选择其对应的句子集合中的1 个句子作为训练实例进行关系预测。
2)Two:对于每个测试实体对,随机选择其对应的句子集合中的2 个句子作为训练实例进行关系预测。
3)All:对于每个测试实体对,选择其对应的句子集合中的所有句子作为训练实例进行关系预测。
实验结果如表3 所示,可以看出:

表3 不同关系抽取方法的P@N 值比较Table 3 P@N value comparison for different relation extraction methods
1)随着实例数量的增加,所有方法的性能都会有所提高。这进一步表明,跨关系、跨句包注意力可以通过选择高质量的实例、丢弃无用实例来更好地利用句包信息。
2)以PCNN 为句编码模型要优于以CNN 为句编码模型,这表明利用实体对将句子分成三部分进行分段最大池化操作是有益的。相比于CNN 模型仅用单个最大池化操作,分段最大池化可以有效捕捉句子结构信息。同时加入MIL 方法可以有更好的性能,这表明以PCNN 为句编码模型可以一定程度缓解远监督中存在的噪音问题。加入ATT 方法表明对每个句子赋予同等权重,同时也会从错误标注的数据中得到负面信息,进而损害关系抽取的性能。
3)由于Freebase 知识库不完整,导致NYT10 数据集[17]中许多句子被错误标注。soft-label 方法[6]是通过使用后验概率约束来校正可能不正确的句包关系类型,该方法可以从正确标注的实体对中挖掘语义信息,从而在训练过程中动态地纠正错误的标记。以PCNN 为句编码模块加入MIL 方法或ATT 方法,再结合soft-label 方法,比PCNN 加入MIL 方法或ATT 方法效果要好,校正了错误标注后的关系抽取效果优于本就存在错误标注的NYT 数据集,这表明错误标注确实影响了远监督关系抽取的效果。
4)以PCNN 为句编码模型的抽取效果优于以CNN 为句编码模型的效果,这表明分段池化操作将低层特征组合成高层特征,既保留了句子中细粒度的信息,又避免了利用自然语言处理工具进行特征提取可能会导致的错误传播问题。PC2SAD 模型的性能优于CNN+C2SA+D,则从整体上验证了分段池化操作在关系抽取时,考虑到句子的内部结构信息,能捕捉到更多与实体有关的上下文信息,缓解特征提取的误差传播问题。
5)PC2SAD 模型的性能优势,进一步说明本文提出的模型可以充分利用实体描述所提供的有用的背景知识,有效过滤对关系抽取没有意义的句子,缓解错误标注带来的负面影响,改善关系抽取效果。
4 结束语
本文研究远程监督的实体关系抽取方法,针对现有模型学习中只关注实例本身,没有关注到各个关系之间的关联信息,以及忽视实体描述信息的问题,构建结合实体描述信息的跨句包关系抽取模型PC2SAD。该模型引入跨关系跨句包注意力机制用于远程监督关系抽取,充分应用关系层次中所蕴含的相关性选择有效的实例,并进一步从Freebase 与Wikipedia 中提取实体的描述信息,补充关系抽取任务所需的背景知识,利用该实体描述信息支撑关系预测任务,同时为跨关系跨句包注意力模块提供更好的实体表示。在大规模基准数据集上的实验结果表明,本文模型能够充分利用实体描述所提供的背景知识过滤对关系抽取没有意义的句子,减小错误标注带来的负面影响,改善关系抽取效果。下一步将研究现有多种注意力机制的变种形式,在此基础上改进注意力模块,尝试利用强化学习进行模型训练。
