基于人工智能的三维多媒体视觉图像识别研究
2021-06-18唐晓
唐晓
(郑州工业应用技术学院信息工程学院,河南郑州,451150)
0 引言
人眼能够通过以往经验,对二维图像进行快速感应从而实现从二维图像到三维图像的转换。多媒体传播时代的到来,出现了一种结合上述人眼识别的方式,出现了一种人工智能图像识别技术,并在人们的日常生活当中得到了广泛的应用,例如在卫星定位、生物医学等领域当中,均应用了人工智能识别技术[1]。但当前,随着人们对图像识别要求的不断提高,在沿用传统的图像识别方法时,容易出现识别精度不符合要求、识别时间过长、识别结果与实际相差较大等问题[2]。因此,当前该领域研究人员逐渐将研究重点转向对有效识别方法的研究当中。对此,本文通过开展基于人工智能的三维多媒体视觉图像识别研究,为研究人员提供全新的识别方法设计思路。
1 基于人工智能的三维多媒体视觉图像识别方法设计
■1.1 三维多媒体视觉图像特征提取
在传统视觉图像识别方法的基础上,结合三维多媒体图像中各项规律,对图像特征进行提取。采用多尺度几何分析工具,实现对多媒体视觉图像的切波变换,对图像进行三维最优逼近,从而方便获取图像当中的各类型信息及特征。
首先利用层叠分类器对三维多媒体视觉图像进行分类,在保留图像窗口的条件下,过滤掉所有非识别图像窗口,在保证漏检率低的基础上将大部分非识别区域进行过滤。
其次,完成对原始三维多媒体视觉图像的剪切波变换后,对子图像获取,利用多方向局部二值模式,在已经获取到的剪切波变换图像上得出半径为a的圆形区域,并找出其中对应的n个特征采集点[3]。根据多方向局部二值模式给出其算子的表达式为:
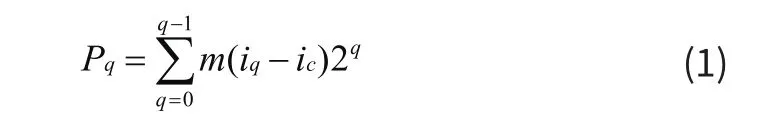
公式(1)中,Pq表示为多方向局部二值模式算子;iq表示为三维多媒体视觉图像中心点像素值;ic表示为三维多媒体视觉图像中相邻点的像素值大小;m表示为剪切参数,m值通常取[0,1]。根据公式(1)计算得出多方向局部二值模式算子后,按照图1所示流程对三维多媒体视觉图像特征进行提取和编码。
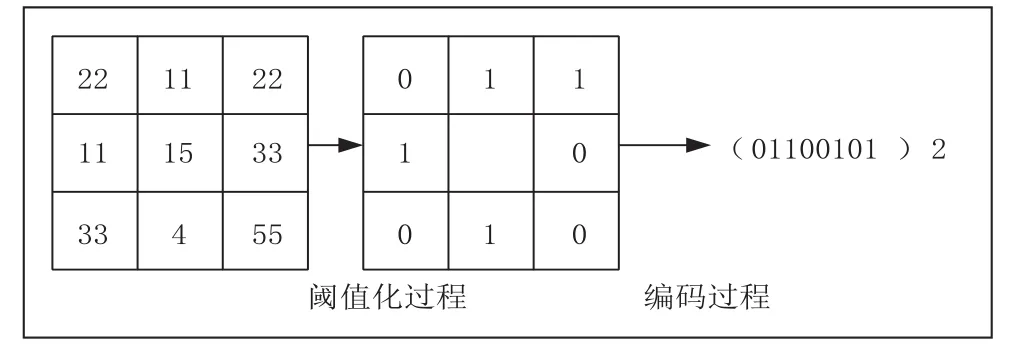
图1 三维多媒体视觉图像特征提取与编码流程
根据图1特征提取和编码流程得出,在特征提取过程中需要完成365维的编码,为了方便后续识别,对其阈值化结果采用均值处理的方式进行编码。设定一个二进制序列,并设定其从0到1和从1到0的过程不超过两次[4]。根据三维多媒体视觉图像在各个方向上的纹理图像,进一步将其划分为一个5×5的矩形区域。通过对各个方向上的联合直方图进行连接,得到一个完整的三维多媒体视觉图像特征量,再利用可编程计数器阵列,对三维多媒体视觉图像上的特征进行降维处理。最终得到需要进行识别的图像特征表示。表1为降维处理后,三维多媒体视觉图像维数及保留原始图像信息百分比对应关系。
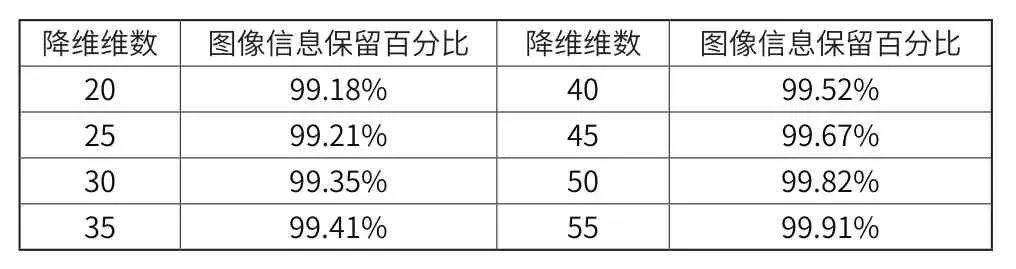
表1 降维后图像维数与原始图像信息百分比对应表
结合表1中的数据,在对三维多媒体视觉图像特征进行提取时,应当根据实际需要选择不同的降维维数,其中降维维数为20时,图像信息保留百分比最低,识别训练时间最长;降维维数为55时,图像信息保留百分比最高,识别训练时间最短。
■1.2 识别图像变化特征生成
在完成视觉图像特征提取的基础上,应根据识别图像的变化,进行识别特征的生成。在此过程中,假定获取的图像中存在动态的关键点,此时可利用动态点的变化,进行多媒体几何投影[5]。此过程可用如下计算公式表示。

公式(2)中:S(c)表示为在绘制图像过程中,多媒体环境下识别到的关键点。其中c的取值为c={c;z;v},将c中的二维图像与三维空间图像进行对比,并使用小孔成像设备,在现实环境中,对特征信息进行透视转换。假定在一个相同的二维图像环境中,存在图像坐标、点坐标、坐标轴、坐标系均在同一水平面上,此时可认为识别的特征数据存在统一性。为此,结合cs;co与c之间的三维目标关系,进行视觉目标共性的转换,转换过程如下计算公式所示。
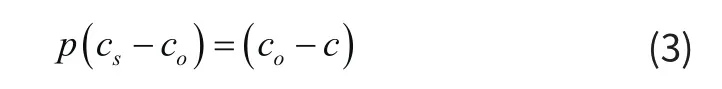
公式(3)中:cs表示为识别到的原始图像;co表示为三维坐标图像中,视觉目标的对应点。根据目前已知的图像变化特征,将其应用到实际中,进行多媒体设备对图像的平移、旋转等操作处理。假定Q;E;R分别表示为三维图像下的矩阵方向,则可认为生成特征生成的过程如下。

公式(4)中:U表示识别图像特征的旋转角度;Y表示为识别图像特征的平移角度。根据上述计算公式,输出具体数值,完成对图像变化特征的生成。
■1.3 基于人工智能的图像特征识别
在完成图像特征生成的基础上,引入人工智能技术,对图像特征进行最终识别,此过程中,使用智能化技术提供识别行为的稀疏表示法,构建一个智能化的识别模型,并采用梯度限制的方式,对图像目标函数的最小值进行投影,输出优化后的最小值,根据函数的梯度方向,进行特征识别。此时,假定存在一个三维图像样本数据集合,且集合内样本数据量充足,此时,可按照第j个训练矩阵中,J的数据样本字典进行三维视觉的训练。其中J的取值范围表示为Iα−β,用m表示为j类图像的字典矩阵,q表示为大于0的系数,则智能提取的过程可用如下计算公式表示。
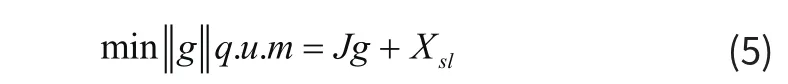
公式(5)中,g表示为样本训练集合。使用机器算法与智能化技术的结合,利用牛顿内点方法对目标函数进行约束,寻找约束范围中的(g,0)取值区域,根据g中的样本数量,得到g的最小值样本集合,以此为依据,定位函数的梯度方向,遵循此方向进行图像稀疏投影的分类,输出分类结构,并认为结构密集区域存在特征图像数据,反之不存在特征图像数据,综上所述,完成对图像特征的识别。
2 对比实验
本文选择三维多媒体视觉图像中的某一人体动作视觉图像作为实验对象,分别利用本文提出的基于人工智能的三维多媒体视觉图像识别方法,和传统图像识别方法对该实验对象进行识别,以此完成对两种识别方法的应用效果对比。为实现对实验结果的定量分析,本文按照人工智能识别率RR准则作为标准,对其正确识别率γ进行计算:

公式(6)中,K'表示为本文识别方法或传统识别方法准确识别视觉图像样本个数;K表示为实验过程中供进行识别的样本总数。本文实验当中选用的实验对象为ORL人体动作三维多媒体视觉图像库当中的500组视觉图像,其中共包含了50人,每个人在不同的环境下,完成了10张不同动作和形态的视觉图像展现。为确保实验的客观性,两种识别方法在应用过程中,均设置115×98的分辨率,灰度均在256级。根据上述实验准备,完成实验,并随机抽取100组识别结果,利用本文上述计算公式(6)对其正确识别率γ进行计算,并求解出每组平均γ值,将实验结果记录如表2所示。

表2 两种识别方法实验结果对比表
根据表2中的数据结果进一步得出,本文识别方法平均γ值明显高于传统识别方法平均γ值。因此,通过实验证明,本文提出的基于人工智能的三维多媒体视觉图像识别方法在实际应用中具有更高的识别准确性。同时,在实验过程中,通过对其识别时间进行比较得出,无论是在对三维多媒体视觉图像的特征提取,还是在识别过程中,本文识别方法耗时均明显小于传统识别方法耗时。因此,进一步证明本文识别方法具有更加重要的现实意义。
3 结束语
当前三维多媒体技术的快速发展,使得图像识别技术的出现为人们的日常生活带来了诸多便利,针对传统识别方法存在的精度不高、识别结果准确率低等问题,本文通过引入人工智能技术,对其进行了创新研究。将本文提出的识别方法应用到实际当中,能够有效增强识别性能,具有更高的实用价值。但由于研究能力的有限本文仅针对三维多媒体视觉图像中的灰度图像进行了研究,而对于彩色视觉图像的识别内容并未涉及,因此在后续的研究中还将针对彩色视觉图像进行更加深入的研究,从而提高识别方法的实用性范围。
