一种基于Context Graph主题爬行算法的改进
2021-06-18高庆芳蒲宝卿
高庆芳,蒲宝卿,包 蕾
(陇南师范高等专科学校,甘肃陇南 742500)
0 引 言
随着互联网的快速发展和全面普及,通过不同网络搜索引擎,从海量网络信息中获取信息,是互联网应用在学习和生活中的重要表现形式和组成部分,搜索引擎的核心是网络搜索引擎爬行算法.
通过对主题爬行算法的研究[1],传统的算法思想可分为2类:一类是基于Context Graph的主题爬行算法以及基于网络的超链接结构的爬行算法;另一类是早期由学者Diligenti提出的基于Context Graph的主题爬行思想,即利用爬行算法爬取相近主题的页面时,路线都是相似的[2].要实现后者的爬行算法,就要构建Context Graph模型层次结构图,用链接指向表明页面之间的联系,爬行路径让主题爬虫自主爬取.
根据相关文献,机器学习是主题爬虫最突出的特点,即可在爬行时选择其一网页分析算法选择链接对象,对于无关的对象可进行剔除.在这种情况下,在保证爬取效率的同时,也必须确保得到的结果页面具有更好的相关性.在计算机系统中用中文分词系统对中文文本进行词语自动识别,这方面的研究目前已经比较成熟,很多学者都总结提出了相关的算法.根据其特点,可以对现有的中文分词算法分类,主要有基于字符串匹配的、基于统计的和基于语义的 3类[1].
传统的主题爬行算法存在不足之处是会降低网络的搜索速度.本文对传统的算法做了一个改进,主要修改了TF⁃IDF公式,目的是可以提高特征词权重计算的准确性,完成分类器的训练[3].主题爬虫是基于某个主题只爬取与主题属于同一类内容的页面,在建立的主题集上进行特征分类,在诸多量化方法中,下文提出的Context Graph层次模型具有较大优势.
1 Context Graph模型的构建
基于Context Graph的主题爬虫算法可以判断目标页面的路径与新访问的页面一致[3],计算当前页面及页面之间的位置.通过已知位置页面的样本训练,得到一定的链接路径,到达目标页面.
以一个 2层的 Context Graph模型为例[4],其结构如图1所示.为实现查询而收集的示例页面构成图的中心结点,作为第0层,指向第0层的页面(这些节点也称作父链接或者Backlink)被分到第1层,第1层和第0层的节点之间是直接链接关系,第1层的Backlink节点做为第2层,以此类推,直到构建出所需的模型为止.
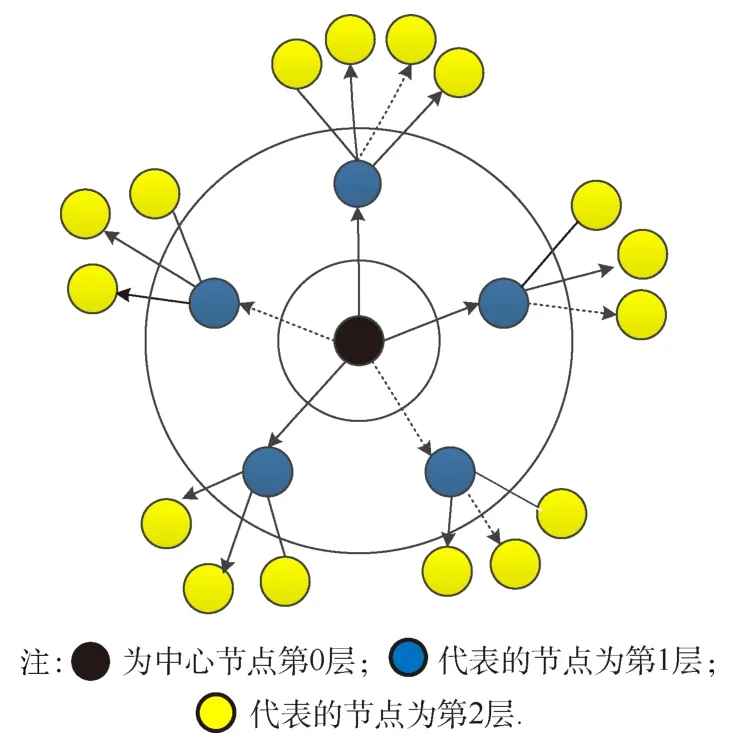
图1 2层的Context Graph模型
2 对特征权重算法的改进
传统的Context Graph主题爬行算法存在不足,如要基于爬虫爬行得到的已知页面集计算特征词的权值,而计算的值有时并不准确.在此,对原始算法TF⁃IDF公式做出改进.
2.1 文档特征权重的计算方法
TF⁃IDF函数用来表示一个特征项是否重要,即计算某个特定向量中一个词项的权重.特征项用词频(term frequency,TF)和逆文本频数(inverse docu⁃ment frequency,IDF)2个因素衡量其重要程度[5].
2.1.1 TF
TF表示某个文本中某个特征项出现的次数[6],值越大说明该特征项越重要.设特征词为ti,文档为dj,TF定义为

式中ni,j表示在特定文件dj中某个特征词的出现次数,dj包含的所有特征词出现的次数之和记做特征权重的计算会受到少数高频词的影响,所以要进行归一化处理[7],用lg(freqij)+1缩小TF范围,防止tf值偏向包含更多词项的长文件,则TF最终可表示为

2.1.2 IDF
IDF反映了特定特征项在不同文档中的区别.假设一个文档集中,某个特征词很少出现,会有这样的情况,即虽然该词频度很小,但实际上该词具有较高的重要性[8].因此,往往包含某个特征词的文档的总数与该特征词的权重成反比,或近似反比[2].IDF表示为

式中n为所有的训练样本数,则特征词ti出现的训练样本数为ni.
通过对TF⁃IDF公式的研究,则有,如果某些特征词在一类文档中出现频率足够高,而在整个文档集合的其他文档中出现频率足够小[5],该词能更好地区别不同文档,因此,用TF和IDF的乘积来标记特征空间坐标系的取值[10].TF⁃IDF 公式为
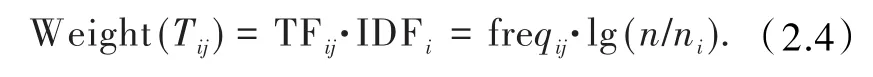
在文档dj中,特征词ti的频度为TFij,n为所有训练样本数,ti出现过的训练样本数为ni.
2.2 分类训练及主题分类
目前有较多的基于机器学习分类文本的算法,此处基于贝叶斯定理,用分类准确率较高的朴素贝叶斯(naive bayes classifier)算法[11].假设一个类变量y依赖于特征向量(x1,x2,…,xn),由贝叶斯定理有
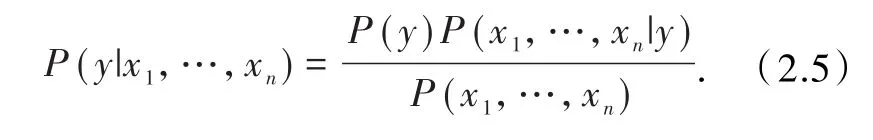
假设条件:
每个特征项都是独立的[12],则有
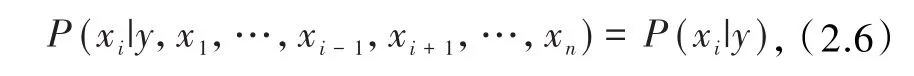
基于所有i的关系,可化简为
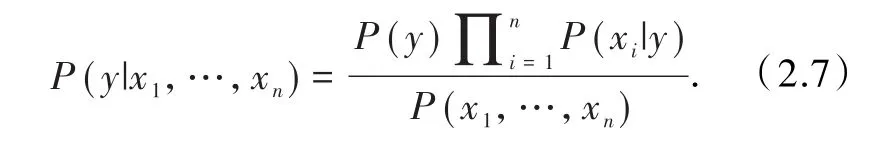
算法步骤:
(1)先验概率、条件概率的计算,
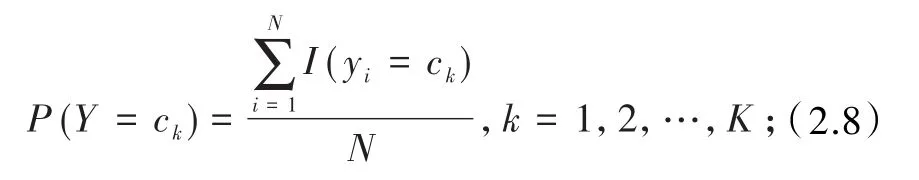
(2)其中I(·)是指数函数I(true)=1,i(false)=0,

(3)j=1,2,…,n,l=1,2,…,Sj,k=1,2,…,K,表示第i个样本的第j个特征,ajl是第j个特征可能取值的第l个特征;


分类器的构建通过分类训练实现,过程如下:
(1)将待分类项设为x={a1,a2,…,am},a为特征属性;
(2)存在类别集合C={y1,y2,…,yn};
(3)计算条件概率P(y1|x),P(y2|x),…,P(yn|x);
(4)如果P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)},则x∈yk;
(5)计算(3)步骤中的每个条件概率是关键.算法思想是先定好训练样本集,然后对每个类别中的各个特征词的条件概率估值进行统计[13].

若设定条件独立的各特征属性,按贝叶斯定理有
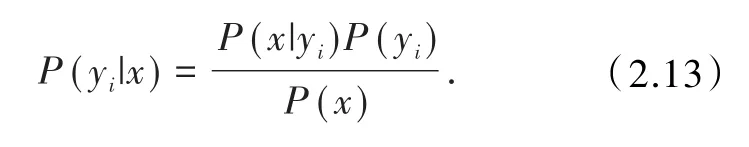
分母是常值,在此只需最大化分子.基于各条件独立的特征属性得到

相关的研究显示[14],构建N层的上下图文集模型,则参与训练的先验概率就要为N+2个类别:P(ci)(i=0,1,2,…,N)、P(cother()若某页面不在N层中,则将被归至cother类),可估计其先验概率,包含较多文档的层具有较大的先验概率.因此,重要步骤是估算各个特征词在每个层次(类)的先验概率P(mt|cj)(t=1,2,3,…,|kj|),可用公式为
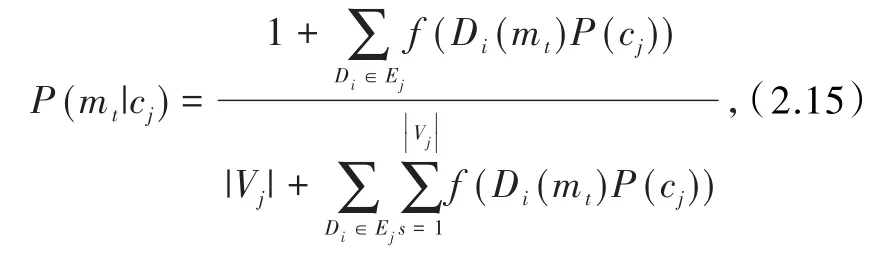
式中f(Di(mt)P(cj))为词mt在文档Di中出现的次数,|Vj|为词集中词的总数.
N层Context Graph需N+2个先验概率类别,则文本分类器要有N+1个类别[15].每次爬取新的页面Di时,先对类别Di进行判断,确定是否会被划归至P(cj|Di),根据事先设定的阀值计算最大的类别Cj,再与阀值比较,若小于阀值,则Cj会被归于P(cj|Di)类.
因此,在一个N层上下图文模型中,爬虫得到的页面链接存放需要N+2个队列.初始状态下,0~N队列为空,少量特定的页面会存放在第N+1队列中.经判断,对应层次Ci的页面会存放在0~N队列中,经计算,某个页面分类值小于预定阈值,其将被划归到cother类别,就存储在第N+1队列中.这个过程是循环的,每一个新的网页被爬取时,会将其从距离模型中心最近的非空队列中取出,经过文本训练后,确定归属的类别,得到概率值,默认需求最近的前驱页面会优先处理.队列内部会根据概率值的大小进行排序存储,确保优先处理的特点[16],这也是主题爬虫算法的重要特征.
若事件w发生的概率记做p(w),则可定义信息论中的信息量公式为

若属于类别d的文档的出现概率为p(d),在可确定的情况下,p(dmk)的值差别不大.针对该现象做出一个改进,对应公式为

可知,若计算得到的MI(d,mk)值越大,则lgp(mk)的值就应足够小.
特征选择算法的特点是基于TF差异[17].在改进的算法中,将实现对现有的TF⁃IDF公式的改善.
如果用M(mk,di)来表示词mk关于类别di的权重[18],则计算类别权重的公式为

式中mk为某一文档集中第k个特征词,di为类别中的第i类,N为数据集总类别数为mk在di中出现频率,λ为调整系数在d中的方差,i在d中的均值.i
基于以上理论提出改善后的TF⁃IDF公式为

与原计算公式的差别是,原公式与特征词的类别权重进行乘运算.因为不同类别的文档,每一个特征词的重要性都应该被区分,也就是存在某个特征词在某个特定类别的文档中更为重要,而该词必然不会在其他类别中表现得更为重要.
一般使用比较成熟的语料库,优点是样本可直接使用.首先,对样本集所包含的各个分词在每个类别的权值M(mk,di)进行计算;其次,计算平均值(mk,di);最后,按照语料库中某个主题对应的类别,用已计算出的类别权值以及改进的TF⁃IDF公式来进行运算.如果遇到的分词还没计算出类别权值,可以取该词对应类别中所有分词权值的平均值,而后整个集合的特征词集就由计算结果最大的分词构成.
3 结 果
使用搜狗语料库作为数据源来提取文档和特征词,其资源内容主要采用手工整理与分类,目前是很多实验中都在采用的样本.该语料库中有财经类,本文选取“20.txt”这一文档,通过对各类别特征词的权值的计算,再通过后续处理.搜索主题为房地产时,其文档总数为720次,得到的部分结果如表1所示.可知,利息出现过的文档在整个文档集中的比例也不高(24%),如果按照改进前的TF⁃IDF公式,类似的这些分词不会被重视,对原有思想及公式改进后,其权重值增大,说明在此提出的改进算法是有效的.
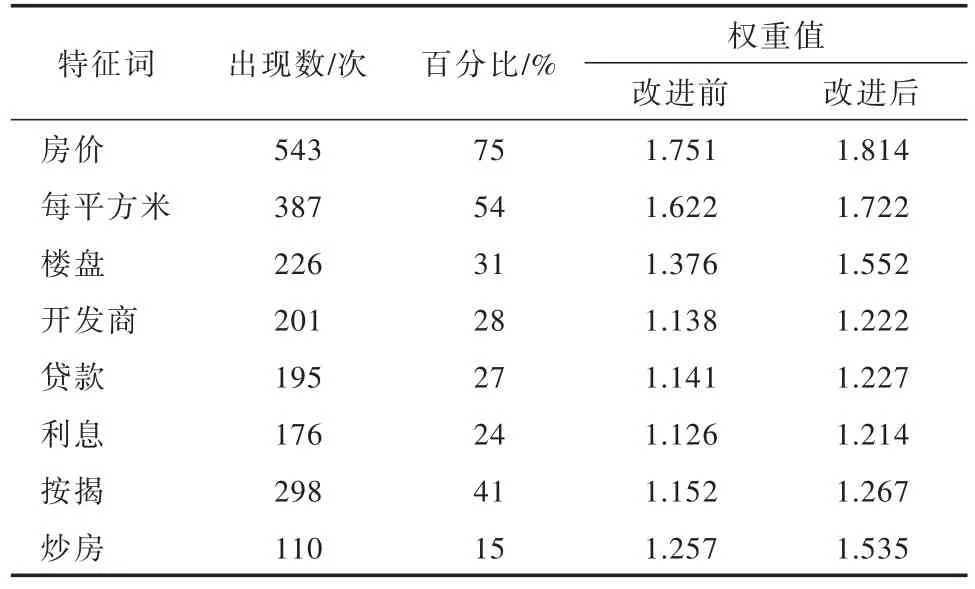
表1 提取房地产的部分特征词结果
4 结束语
本文提出的改进算法是成功而有效的,可以提高提取特征词的准确性.算法不足之处是特征词相关度的确定还需再提高.由于汉语的结构复杂、语义丰富,怎样理解用户的真正意图并准确定位用户的搜索目标,能否给出其想要的信息,是目前搜索引擎技术亟待进一步解决的问题之一.
