一种基于Wkmeans聚类的LTE外部干扰智能定位方法
2021-06-18中国联通浙江省分公司浙江杭州35800中国联合网络通信集团有限公司北京00033
赵 伟,王 勇,陈 乐(.中国联通浙江省分公司,浙江 杭州 35800;.中国联合网络通信集团有限公司,北京 00033)
1 LTE干扰排查现状及难点
在大流量背景下,移动用户不断增高的网络感知要求与网络覆盖不平衡的矛盾日益突出,进而因私装干扰器导致LTE 外部干扰现象明显增多。现有干扰器主要以直放站、信号放大器、部分不达标的民用设备等为主。干扰信号经由扩频后将引入上行干扰。目前,针对LTE 网络上行系统外部干扰定位的相关研究较少。现行排查方法以工程师现场扫频排查为主,存在以下4个难点。
a)人工成本高。每排查一个外部干扰源,至少需2 名经验丰富的一线工程师前往干扰现场,手持扫频仪器在受干扰基站覆盖范围内(大于500 m)进行地毯式排查。通常至少需要2次以上现场排查方能确定干扰源真实位置,且对扫频工程师的经验和专业水平要求高。
b)扫频仪器精度有限。当前常用的扫频仪器往往至多能对周围50 m 范围进行扫频,且随着使用年限的增长会存在一定程度的精度误差。
c)现场环境复杂。许多干扰器位于城区,障碍物多、建筑层数高、同网及异网基站密集,且往往发现同一片区域中存在多个干扰源,大大增加了定位的难度。
d)干扰器工作原理复杂且工作时间不定,部分干扰器仅在白天或特定时间段开启,若依照传统模式仅选取业务闲时(即02:00—04:00)的干扰电平数据来进行人工排查,容易忽略该类干扰器。
2 干扰定位建模基础理论
在通信系统中,发送端发出的无线信号经由信道传递至接收端。受发射器本身特性及传播环境的影响,接收端所收到的无线信号较原始发送信号均有一定程度的衰减。该衰减即为路径损耗,单位为dB。若在自由空间内对无线信号的传播进行建模,接收端与发送端传播距离为d,发送端天线发射频率为f,则传播损耗Lbs可表示为:
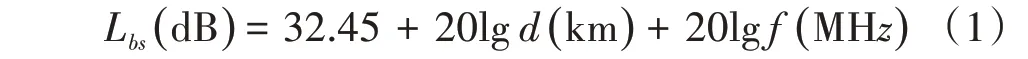
从式(1)可以看出,Lbs(dB)是与d、f正相关的函数L(d,f)。实际传播过程中,任一地形下的某发送端实际路径损耗是在Lbs(dB)的基础上,加上衍射损耗、地形损耗等损耗因子综合矫正后的结果,传播规律服从L(d,f)。因为干扰器和基站均为信号发送端的一种形式,其所受干扰强度和终端距离及发射器本身的天线增益呈正相关。
图1 给出了LTE 外部干扰传播模式及其定位原理示意图。在图1(a)中,基站C1、C2和C3所在区域受干扰器I影响,可知距离干扰源最近的基站C1受到强干扰,基站C2、基站C3则存在不同程度的弱干扰。相似地,干扰范围内的用户终端U1、U2和U3因所处位置不同,其干扰信号强度依次递减。目前常见的LTE 干扰定位模型采用计算用户上下行路损差值的方式来进行干扰源定位。假定正常LTE 小区在任意位置上下行路损的差值应小于阈值(如11 dB),已知干扰信号强度和终端所处距离呈正相关,因而上下行路损差值最大的位置即为干扰源所在位置。由于该方法涉及到上下行路损绝对值的计算,受环境的复杂性影响,难以对现网基站进行精准建模。此外,该方法需在基站侧开启额外的非标上行电平信息测量,受制于设备厂商系统的局限性及准确性,较难推广至实际生产中。

图1 LTE外部干扰传播模式及其定位原理示意图
因而,本文提出了一种通过计算上下行路损相似度的方法来进行干扰源定位,基于栅格化后的MDT 数据,通过寻找上下行路损变化最为相似处来识别干扰源的位置。如图1(b)所示,干扰源收到基站C1、C2、C3的信号强度(即DL1、DL2、DL3的路损大小)与其到基站C1、C2、C3的距离d1、d2、d3正相关。相似地,干扰器发送至基站C1、C2、C3的干扰信号强度(即UL1、UL2、UL3)与其传播距离亦和距离d1、d2、d3呈正相关。因此,下行路损向量(DL1、DL2、DL3)与上行路损向量(UL1、UL2、UL3)虽绝对值大小不同,但符合相同的波动规律,且距离干扰源越近的位置其相似性越高。通过计算上下行路损的相似度,本文采用了权重聚类算法对候选栅格进一步聚类,可以获取干扰源的预测位置。
3 干扰定位建模方法
根据小区上行PRB 时域特征来识别干扰小区,生成干扰字典,结合栅格化后的MDT 数据得到上下行路损向量的相似度,基于权重聚类算法定位可能的干扰源位置。模型整体流程如图2所示。
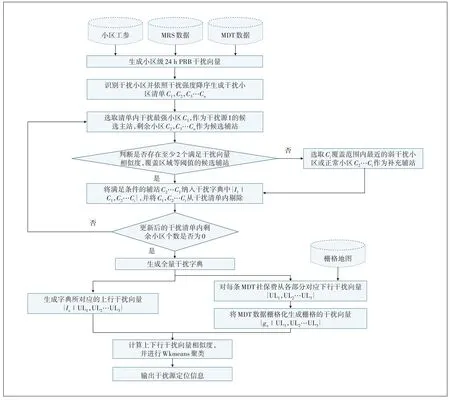
图2 LTE外部干扰定位流程图
3.1 干扰小区特征提取
为了进行外部干扰定位,首先需提取小区的干扰特征,具体步骤如下。
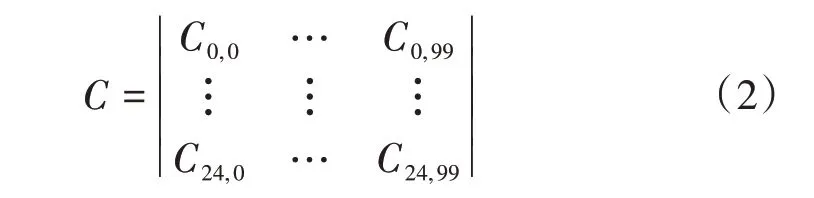
步骤1,通过LTE 的统计测量报告MRS 中MR.RIPPRB来获取各小区小时级0~99每个PRB的干扰噪声电平值,为每个小区构建如式(2)所示的24×100 维干扰特征矩阵C来保留完整的干扰时域特征。
步骤2,根据生成的特征矩阵针对任意小区Ci依照式(2)构建干扰强度评估函数IS(Ci):
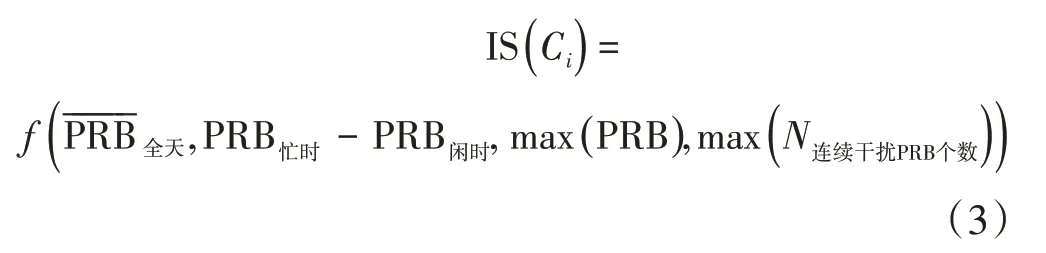
式中:
f——干扰强度评估函数
PRB忙时-PRB闲时——小区忙闲时干扰差值
max(PRB)——小区当日内的干扰最强小时的干扰PRB电平值
max(N连续干扰PRB个数)——当日小区小时级最大连续干扰个数的
通过IS(Ci)对小区的干扰强度进行综合评分,对选定小区按干扰强度进行降序排序,生成最终干扰小区清单C={Ci|i∈[1,n]}。
步骤3,利用皮尔逊相似系数两两评估干扰小区清单内小区间的干扰相似度。已知C的干扰特征矩阵为Ca,b,C′干扰特征矩阵为C′c,d,则0:00时2个小区的干扰特征向量可分别表示为任意2 个向量的皮尔逊相似度计算公式可表示为:
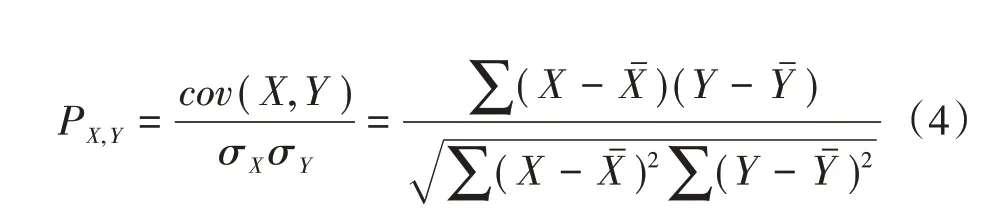
a)小区因临时断站或节电等原因导致缺失部分小时或个别PRB的数据。
b)现网不同小区的容量不同,主流20 MHz 带宽的小区可占用100 个PRB,但部分5~15 MHz 的小区仅分别占用25、50、75个PRB,进而导致剩余PRB 的干扰电平值为空。
考虑到此处的数据缺失具有实际意义,若统一填充异常值(如“-1”)进行维度占用将产生误差,因而需注意在两两向量相似度计算前将矩阵裁剪至维度一致,即令a=b=min(a,b),c=d=min(c,d)。
3.2 干扰字典生成
已知受相同干扰源影响的小区在时域PRB 特征上存在高度相关性,根据这一特性将干扰清单内的小区按照不同干扰源进行分组,进而生成干扰字典。具体步骤如下。
步骤1,选取清单C内干扰最强小区C1,作为干扰源I的候选干扰主站I1,令剩余小区为Ca1,Ca2,Ca3,…,Can,并作为候选辅站。
步骤2,按照以下规则构建干扰字典判决函数:
a)候选辅站与候选干扰主站之间干扰特征向量的相似度是否大于给定阈值(如0.8)。
b)候选辅站与候选干扰主站之间是否存在共覆盖区域。
步骤3,判断满足要求的候选辅站个数大于等于2个。若大于等于2 个,至多选取干扰强度最强的前5个站点作为干扰辅助站点;若小于2 个,选取I1覆盖范围内最近的弱干扰小区或正常小区Ca1,Ca2,Ca3,…,Cai,作为补充辅站。
步骤4,将满足条件的辅站Ca1,Ca2,Ca3,…,Cai依照干扰强度降序纳入干扰字典中{I1|Ca1,Ca2,…,Cai},并将I1,对应的站点从初始干扰清单C内剔除。
步骤5,判断更新后的干扰清单C 内的站点个数是否为0。若不为0,返回步骤1 继续运算,直到遍历完清单内所有站点。
步骤6,输出干扰字典{Ij|Ca1,Ca2,…,Cai}。其中,j代表区域内可预测干扰源。对于字典内任意干扰源Ij,有i个小区受其干扰影响,i的取值范围在[2,6]内。以图1(b)为例,干扰源I对应的干扰字典可表示{C1|C2,C3},其中干扰强度IS(C1)>IS(C2)>IS(C3)。
3.3 上行干扰向量生成
根据传播模型,任意干扰源的上行路损可表示为:

针对干扰字典中某特定干扰源,其周边受影响的干扰站点可表示为(Ci,Ca1,Ca2,Ca3,…,Cai),对应的上行路损向量可表示为:

对该向量按式(7)进行差值化处理,

其中ΔULai=ULai-ULi=PRBi-PRBai
3.4 下行干扰向量生成
根据传播模型,任意干扰源的下行路损可表示为:

从MDT 数据中可获取干扰主站每个采样点主服务器小区RSRP 电平值以及邻区RSRP 电平值,则每条MDT的下行路损向量可表示为:
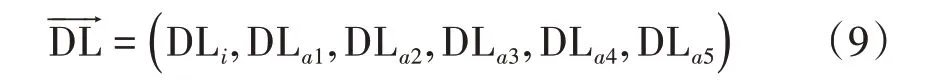
对该向量按式(10)进行差值化处理:
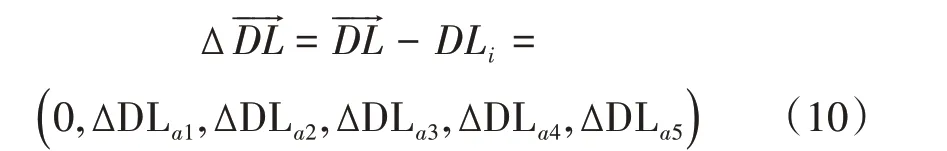
其 中 Δ DLai=DLai-DLi=(Pai基站发射功率-Gai天线增益-RSRPai)-(Pi基站发射功率-Gi天线增益-RSRPi)。将计算得到的向量落入50×50的栅格地图中,可获得每个栅格所对应的下行干扰路损向量。
3.5 权重聚类定位干扰源
已知下行路损与上行路损向量波动规律越相似的栅格即为干扰源所在的栅格。因而依照式(11),将上下行路损向量代入余弦相似度计算公式进行相似度Wi的计算。
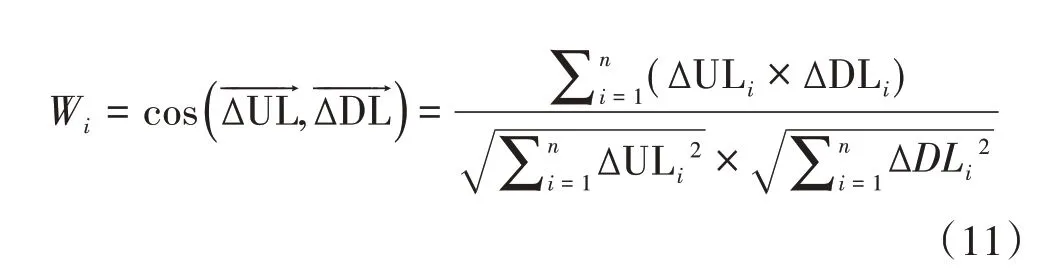
其中,Wi∈[-1,1]。Wi越大,向量间相似度越高,反之则相似度越低,可认为min(Wi)所在的栅格为本文前述方法所认定的干扰源位置。
但是,同一小区往往会受到多个干扰源的共同影响,处于覆盖边缘或阻挡位置的栅格有可能因为弱覆盖等原因反而与上行干扰向量存在高度相关性。最终筛选得到的高相似性栅格集合可能在空间上呈现离散的点状分布态势。图3(a)即为一典型场景。相似度最高的栅格(相似度0.99)与真实干扰源存在一个栅格距离的偏差,而覆盖范围内右下角(图3(b))存在大量高相似度的栅格。

图3 权重聚类算法应用示意图
如图3(b)中所示,常规Kmeans 聚类算法以数据点到初始聚类中心的欧式距离作为优化的目标函数,聚类结果会因部分密集低权重的栅格产生偏差。而本文算法将上下行路损相似度作为栅格的权重参数Wi纳入目标函数中,将迭代目标更改为计算每个栅格到质心的加权距离和。该方法强化了高相似性栅格在聚类时的重要性。相较于直接选取相似度最高的栅格,最终预测位置和真实干扰源位置的误差进一步缩小,有效提升了定位精度。具体实现步骤如下:
步骤1,初始化聚类个数k=1。
步骤2,假设mc代表质心,gi代表候选栅格样本,πc代表生成的聚类簇,依照公式(12)迭代计算每个栅格到质心的加权距离和D,生成初始聚类结果如下:
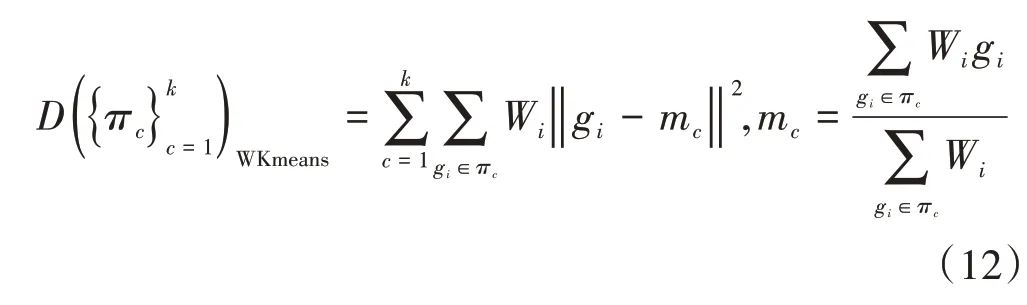
步骤3,按式(13)计算当前轮廓系数,其中a表示某个样本与其所在簇内其他样本的平均距离,b表示某个样本与其他簇样本的平均距离。Sk越接近1 则代表聚类性能越好。

步骤4,令聚类个数k=k+1,重复步骤2和步骤3。步骤5,比较Sk和Sk+1。若1>Sk+1>Sk,重复步骤2~步骤5;否则循环结束,输出聚类结果。
3.6 指标评价
为评估本文算法在实际生产环境的预测能力,通过人工现场实地排查,假设预测位置和其真实干扰源i的距离误差为di,共计有n个样本,则平均误差为
4 干扰定位模型效果验证
本文使用的数据集为某省所有在网小区某天小时级每PRB 的干扰噪声电平值来进行分析处理。结合人工扫频现场排查,使用本文所提出的算法,在某省试点某频段小区,共排查出172个干扰小区,干扰小区识别准确率为97.18%,输出63 个干扰源可能位置。对63个干扰源定位误差分析如表1所示。

表1 各场景下算法评估对比表
对比发现,本模型在无线环境相对简单的场景误差精度可达46 m,而随着环境复杂度的提升,预测误差也随之增大,平均误差最高不超过115 m,误差范围控制在204 m之内,显著提升干扰排查效率。
图4 为模型验证的3 种典型案例,分别为厂区、办公楼宇、居民区3 类场景。其中黑色方块代表模型预测位置,橙色三角形则代表真实干扰源所在位置。
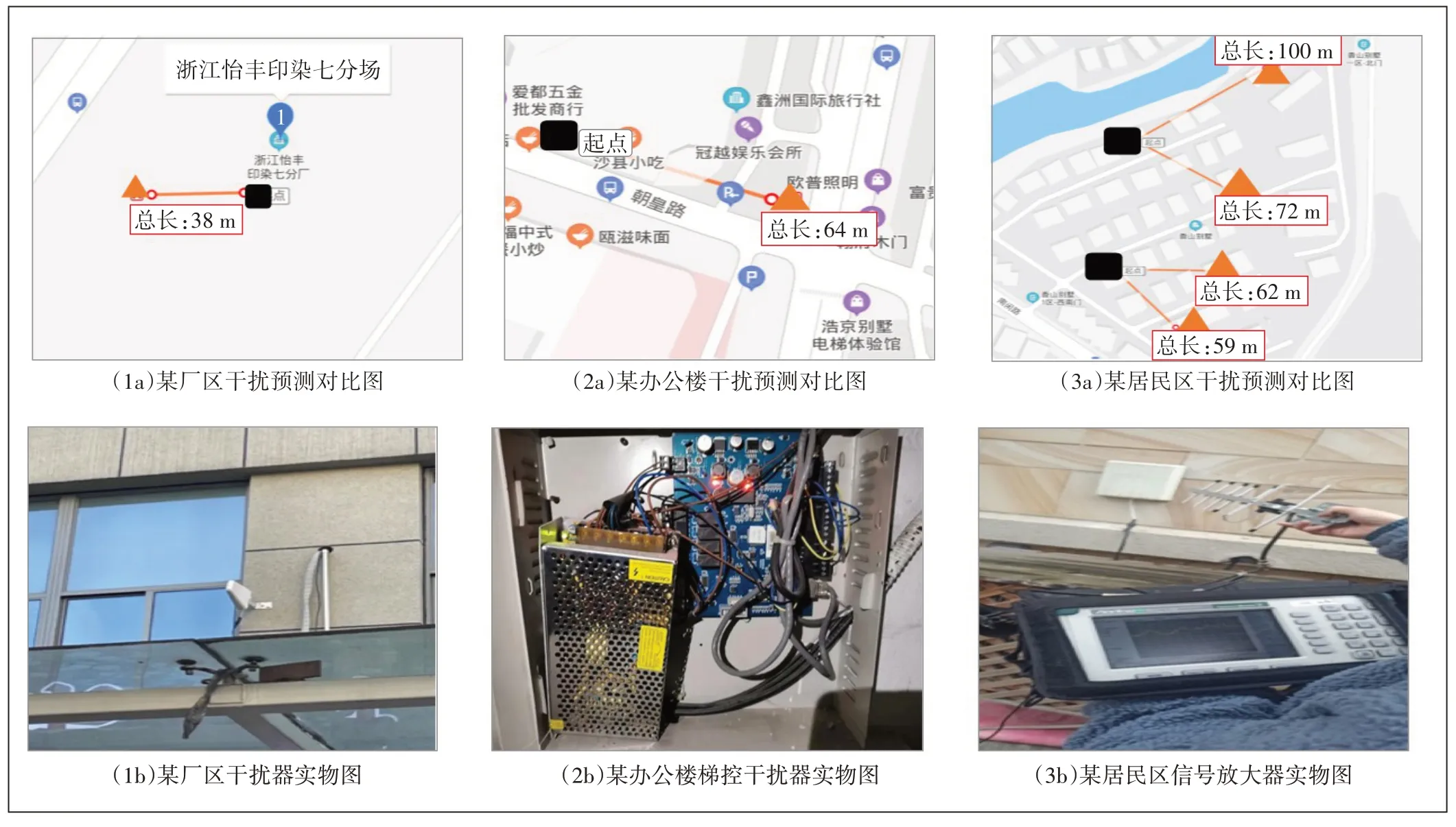
图4 3类典型场景干扰预测对比及现场实物图
a)某厂区位于远郊,处于空旷开阔地,周围无线环境相对简单。该厂区附近基站24 h 内均出现不同程度的全频段干扰。经现场排查后发现干扰器实际为厂区内私装的信号放大器。对比预测结果,可以看到模型对该类场景适应性较好,预测误差不超过50 m。
b)某办公楼宇处于中等密集城区,周边楼宇相对较多,且周边存在多个不同频段的基站。该楼宇附近基站在凌晨呈现弱干扰,而在白天工作时间08:00—20:00 存在强干扰。人工排查后发现为楼宇梯控系统所致,对比预测结果,可以看到模型对该类场景适应性较好,预测误差不超过50 m。
c)某居民区为别墅区,其地下室信号覆盖不佳。多幢住户私装放大器,片区内干扰器密集,影响周边多个基站。模型迭代预测出2 个可能的干扰源位置。预测误差较前面2类场景稍高,但未超过150 m。
5 结束语
本文描述了一种基于权重聚类的LTE 外部干扰定位和识别的方法。相较于传统通过计算上下行链路不平衡预测的方式,本文所提出的算法一方面引入相似度概念,减少对传播空间建模的误差;另一方面通过引入多个站点进行辅助定位,结合人工智能中的权重聚类算法,进一步提高了定位的精准度。本文所述方法已在东南某沿海X省成功试点,实时性高、误差精度小,可有效估计干扰源的位置,降低人工成本,具备实际生产指导意义,具有良好地推广性与复制性。
