基于AI算法的无线网络邻区关系优化研究与实践
2021-06-18李张铮董帝烺中国联通福建省分公司福建福州350000
李张铮,陈 锋,董帝烺(中国联通福建省分公司,福建福州 350000)
0 引言
在无线网络优化工作中,邻区优化是降低掉话率、提升移动网络质量、改善用户感知的最基本且最有效的手段。目前基站邻区优化有2 种方式:自动邻区关系(ANR)和非自动邻区关系(下文简称非自动邻区关系网络为传统网络)。具备自动邻区关系的网络可自动优化邻区关系,不需人工干预;传统网络邻区关系需优化人员手工优化。这些网络邻区的数目众多,优化工作量非常大;需要优化邻区的确定与个人优化经验有很大的关系,稍有不慎就可能造成邻区漏配或冗余邻区,存在较大的优化风险。规避上述问题,提高邻区优化的效率和精度已成为网络优化的关键。考虑到在ANR 网络中,自动邻区关系已成为小区SON 功能的标配,无需人员操作网络便可自动识别和添加邻区,如何利用ANR 邻区关系来优化传统网络邻区已成为网络运营智能化的重要课题。
机器学习技术作为人工智能的重要组成部分,是国家发展战略重点扶持的目标和当下各行业关注应用的焦点。为了推动传统网络邻区优化的智能化,提升网络运营智能化水平,特开展基于机器学习算法的邻区关系优化的研究。
1 传统无线网络邻区关系优化难点
在传统网络优化中,邻区关系优化一直以来是一个难点。由于邻区关系数量多、影响大、技术要求高、优化手段匮乏等等方面的因素,使得邻区关系优化在传统网络中存在一些挑战。
1.1 邻区关系数量多,导致优化耗时耗力
以福州联通为例,W 现网有小区25 000 个,用每个小区有20~25 条邻区来计算,所配置的邻区个数至少50万条以上,网优人员每周提取MR数据,使用厂家工具进行同频、异频邻区核查,根据核查结果,确定需要优化的邻区,并进行相应操作,邻区优化的工作量非常大。
1.2 邻区关系影响面大,直接关系网络口碑
邻区设置不当,会导致干扰增大、容量下降和性能恶化,严重影响用户感知,引发的掉话等问题会导致用户投诉,给运营商网络口碑带来负面影响,影响NPS 得分。邻区设置不当主要有2 种表现方式:邻区漏配和冗余邻区。邻区漏配会引起干扰增大,降低用户的通话质量甚至掉话,从而引起容量及覆盖能力下降;冗余邻区一方面将会由于切换的过多会导致信令负荷加重;另一方面由于终端测量能力的限制,会降低测量的精度、增加测量时延。同时信号较多会造成干扰,容易出现掉话,影响速率的提升,从而影响用户感知。
1.3 邻区关系优化手段缺乏,对技术要求高
传统的邻区关系优化手段有2 种:基于路测软件分析和基于厂家的邻区核查工具平台。
a)路测软件分析。基于导频的小区切换关系来定位邻区关系合理性,该方法的局限性是路测范围有限,覆盖面不足,无法开展全网的精细邻区优化,且路测方法耗时耗力。
b)基于厂家的邻区核查平台。通过采集UE 上报的测量报告、话统呼叫记录、事件进行汇总分析,判断邻区漏配和冗余。该方法有较高的精确性,但受限于厂家License配额和优化人员的技术水平。
2 基于XGBoost算法的小区切换占比预测
随着运营商移动用户数的不断增加,良好的用户网络体验保障对无线网络运营提出了更高的要求。影响无线网络质量的因素很多,其中邻区关系是一个关键因素,它是小区移动性管理的直接承载者。做好邻区关系优化,始终是网优工作的重点。
本文通过利用XGBoost 机器学习算法学习ANR现网邻区关系数据,建立小区间切换次数占比模型预测出传统网络小区的邻区关系。该模型可在开站邻区配置、邻区核查、用户投诉分析等网优日常工作中起到积极作用。
2.1 训练集和测试集样本生成
2.1.1 样本的采集
提取某省联通2 个行政区LTE 网络3 天的两两小区切换次数报表,汇总每个小区邻区的切换次数占比降序排列,取每个小区占比前50 名的邻区作为样本,切换占比为样本标签,同时关联网络工参相关字段(见表1),形成最终样本。
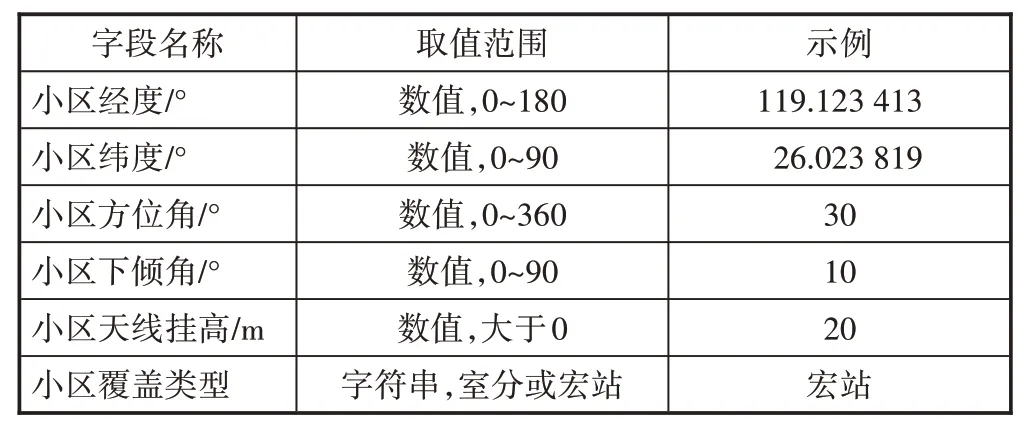
表1 网络工参字段
2.1.2 样本划分为训练集和测试集
机器学习一般将样本划分为训练集和测试集,训练集用于模型训练,测试集用于测试模型性能。本文利用sciki-learn 的train_test_split()函数将样本划分为训练集和测试集,其中参数测试集比例test_size 取0.2,即训练集和测试集比例为8∶2。
2.2 数据预处理
数据预处理主要是检查每个特征是否有缺失值或非法字符,对不合理的值进行校正替换。检查样本数据发现,覆盖类型为室分的小区方位角都是0值,这与实际室分小区为全向覆盖不符,故室分小区的方位角需修正。修正方法如下:若室分小区与宏站邻小区同经纬度,则室分小区取宏站邻小区的方位角;若室分小区与室分邻小区同经纬度,则室分小区方位角取值368°;若室分小区与邻小区不同经纬度,则室分小区方位角取室分小区与邻小区连线与正北方向的顺时针夹角r(见图1)。
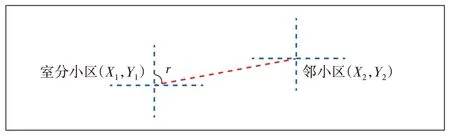
图1 室分小区方位角定义
设室分小区经纬度(X1,Y1),邻小区经纬度(X2,Y2),具体小区连线夹角r计算公式如下:

为了便于书写,令

图2给出了室分小区方位角特征预处理过程。

图2 室分小区方位角特征预处理
2.3 特征工程
特征工程是机器学习过程的重要环节,样本特征的好坏决定了机器学习性能的上限,而模型只是逼近这个上限而已。特征工程的主要内容包括特征构造、特征抽取和特征选择。本文的原始特征包括本地/目标小区经纬度、本地/目标小区方位角度、本地/目标小区合计下倾角度及本地/目标小区天线挂高10 个维度。为了满足特征选择的需要,在此基于本地/目标小区的经纬度构造额外的特征,主要包括haversine距离、两经纬度的方位角、经纬度PCA 分量,最后进行特征选择。
2.3.1 haversine距离
haversine 公式是计算球面两点间距离的一种方法,该方法采用了正弦函数,即使距离很小,也能保持足够的有效数字。haversine距离计算公式如下:


图3 本地/目标小区haversine距离计算
2.3.2 两经纬度的方位角
设本地小区经纬度为(lat1,lng1),目标小区经纬度为(lat2,lng2),两经纬度间的方位角公式计算如下,代码实现如图4所示。

图4 2个经纬度间的方位角计算
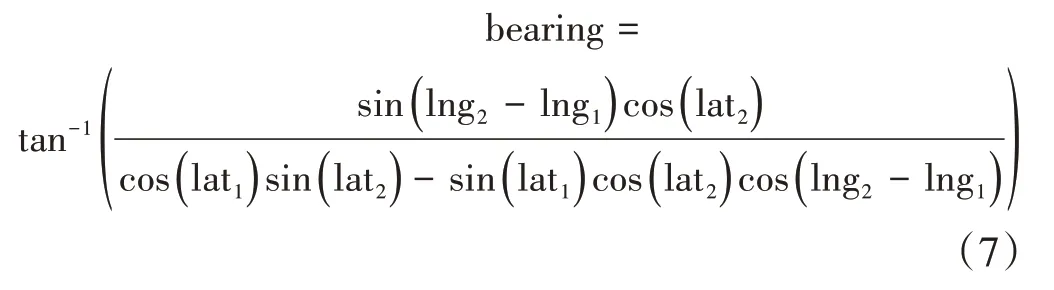
2.3.3 经纬度的PCA分量
主成分分析(PCA——Principal Component Analysis)是最广泛的数据压缩算法,主要通过降维可以生成更便于人理解的新特征,加快对样本有价值信息的处理速度。此处对本地/目标小区经纬度4 个特征采用PCA 进行变换,默认降维后的特征数仍为4(见图5)。

图5 本地/目标小区经纬度的PCA变换
2.3.4 特征/目标相关性分析
特征选择不仅具有减少特征数量(降维)、减少过拟合、提高模型泛化能力等优点,而且还可以使模型获得更好的解释性,增强对特征和特征值、特征和目标之间关系的理解,加快模型的训练速度获得更好的预测性能。此处采用pandas 的相关系数计算函数corr()来分析特征和目标间的相关性(见图6和表2)。
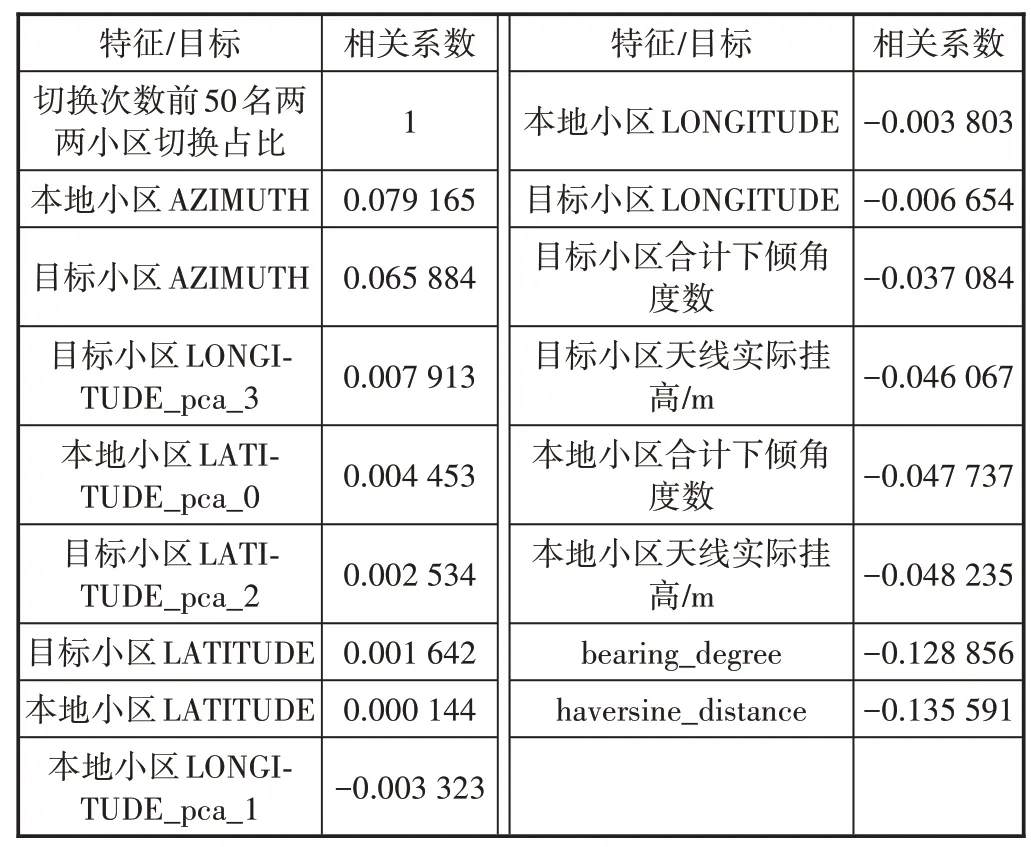
表2 特征和目标间的相关系数值
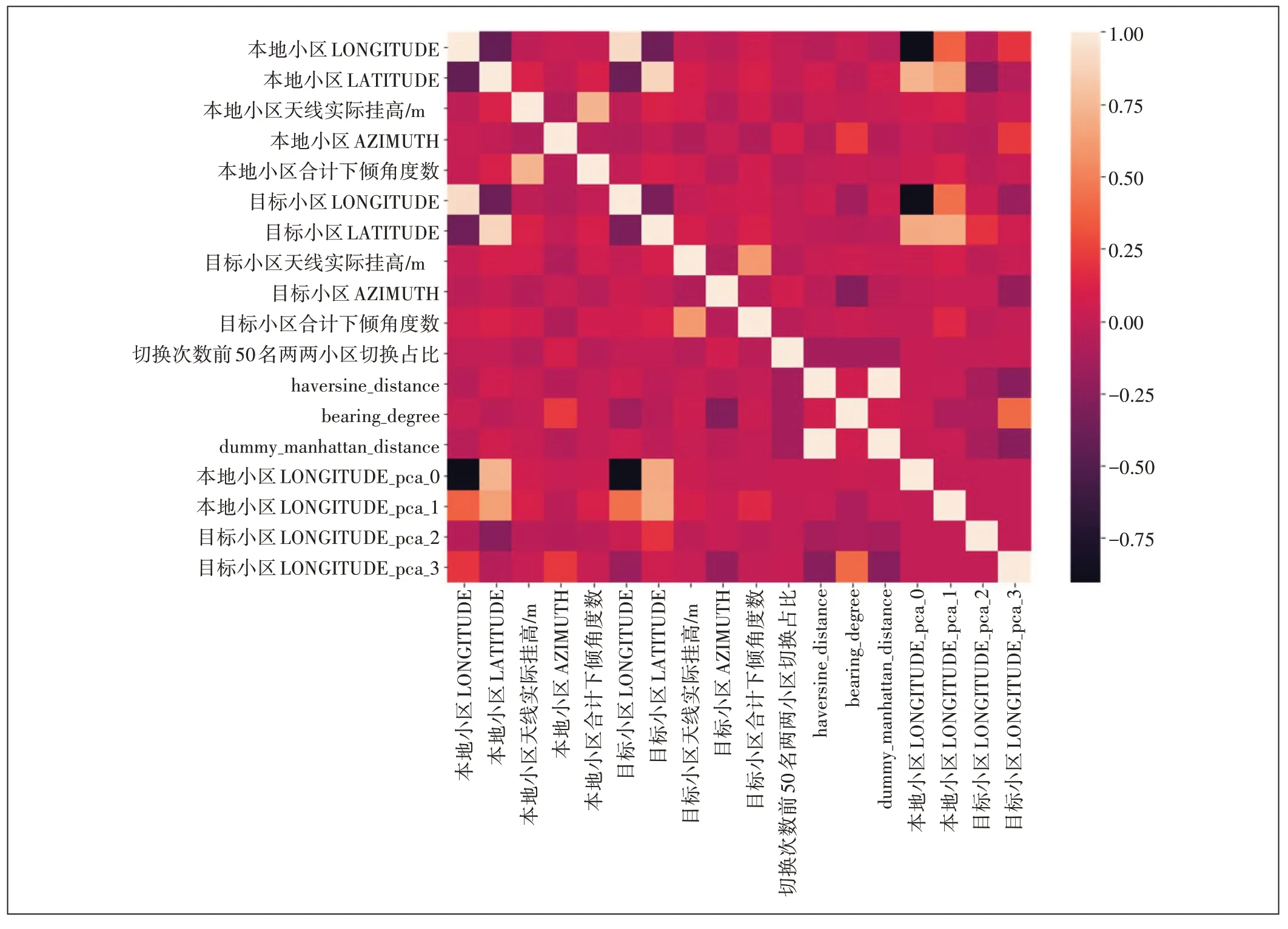
图6 特征和目标间的相关性热力图
从热力图上可以发现,部分特征间的相关性过高,这将造成特征间的多重共线性,影响模型效果,这里剔除相关系数大于0.8 的特征(包括本地小区LATITUDE,本地小区LATITUDE_pca_0,本地小区LONGITUDE),保留与目标相关性最大的特征。
2.3.5 特征标准化
特征标准化就是将某列特征的值缩放到均值为0,方差为1 的状态,计算公式为标准化的好处是提升模型精度和加快收敛速度。此处使用scikit-learn自带的StandardScaler()类进行转换。
2.4 模型训练
2.4.1 基于交叉验证的回归预测模型选择
机器学习中常用的回归预测模型有线性回归、KNN、随机森林、GBDT 和XGBoost 等。这里分别使用这几个模型进行交叉验证打分,选出最好的模型。这些模型的参数都取默认值,交叉验证参数取5,评估标准为平均绝对误差MAE。实验结果表明,最好的模型为XGBoost,平均cross_val_score 得分最高为-0.03(见图7)。下面就使用XGBoost模型进行建模训练。

图7 基于交叉验证的回归模型选择
2.4.2 XGBoost算法原理概述
XGBoost 算法近年来在工业界和各类数据挖掘竞赛中大放异彩,取得良好的预测效果。与传统的Boosting 算法如GBDT 比较,XGBoost 算法优点在于:GBDT只利用了一阶导数的信息,而XGBoost对损失函数做了二阶泰勒展开,并且在目标函数中加入了正则项,用来权衡目标函数和模型的复杂程度,防止过拟合;Boosting 是串行过程,不能并行化且计算复杂度较高,也不适合高维稀疏特征,而XGBoost 在特征粒度上可进行并行化计算且考虑了训练数据为稀疏值的情况。该算法原理如下:
XGBoost 算法的目标函数包含损失函数L和正则化项Ω:

根据第t步的新模型的预测值ft(xi),此时的目标函数可写成:

利用泰勒公式将目标函数进行泰勒二阶展开,得

其中gi为损失函数一阶导数,hi为损失函数的二阶导数。当损失函数取平方损失时,目标函数近似为:
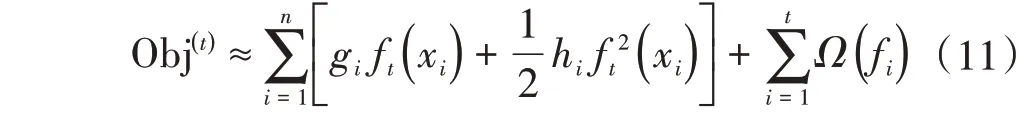
进一步地,基函数取为决策树模型ft(x)=ωq(x),q(x)表示样本x所在的叶子节点,同时设决策树叶子节点数为T,该值决定了决策树的复杂度,值越大模型越复杂,此时目标函数的正则项表示为:
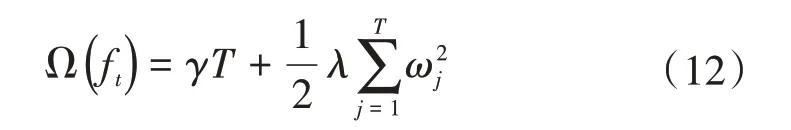
由于每个样本xi最终都是落在叶子节点上,且每个叶子节点都会包含多个样本,因此遍历所有样本xi求损失函数等价于遍历所有叶子节点求损失函数,设第j个叶子节点包含的样本集合为Ij={i},则损失函数为:
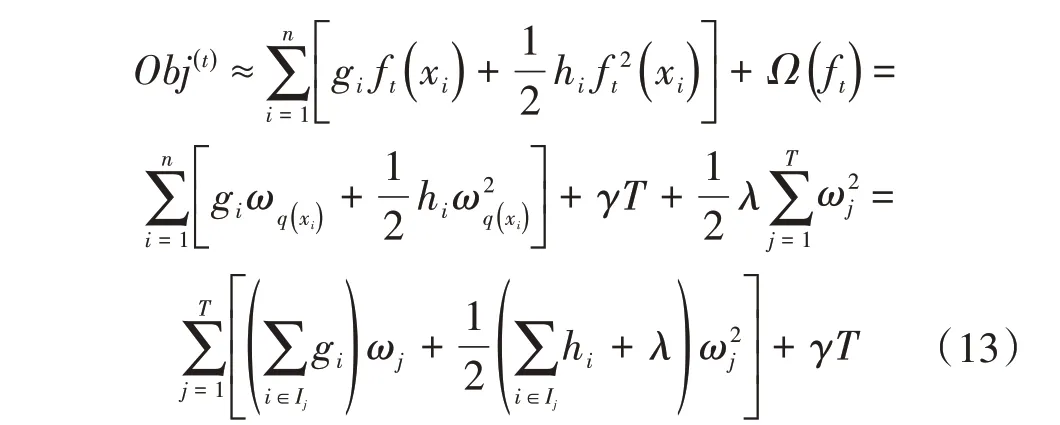
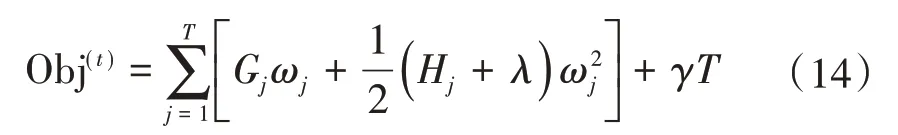
接着对ωj求一阶导数,并使之为0,得叶子节点j对应的权值和最优目标函数为:
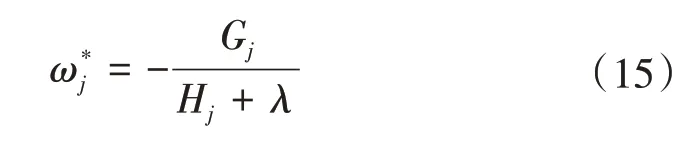
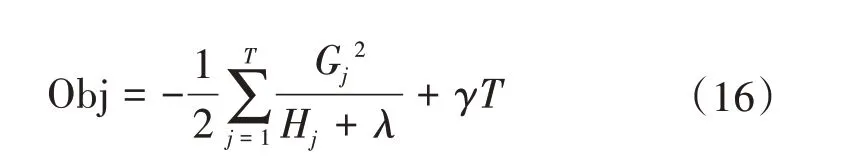
2.4.3 基于网格搜索的XGBoost模型超参数调整
XGBoost 模型的超参数分2 类:第1 类负责控制模型的复杂度,第2类用于增加随机性,从而使得模型在训练时对噪声不敏感。下面介绍调参重点关注的超参数:
a)eta,学习率,默认为0.3,范围为[0,1]。
b)gamma,最小划分损失,它是对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值,默认为0。
c)max_depth,每棵子树的最大深度。其取值范围为[0,∞],0 表示没有限制,默认值为6。该值越大,则子树越复杂;值越小,则子树越简单。
d)min_child_weight,子节点的权重阈值。表示对于一个叶子节点,当对它进行划分之后,它的所有子节点的权重之和的阈值。该值越大,则算法越保守。默认值为1。
e)subsample,对训练样本的采样比例。取值范围为(0,1],默认值为1。
f)colsample_bytree,构建子树时,对特征的采样比例。取值范围为(0,1],默认值为1。
g)lambda,正则化系数(基于weights 的正则化),默认为1。该值越大则模型越简单。
h)alpha,正则化系数(基于weights 的正则化),默认为0。该值越大则模型越简单。
本文利用scikit-learn库自带的GridSearchCV 网格搜索算法来调整XGBoost算法超参数(见图8),候选超参数值集合如下:

图8 基于GridSearchCV的XGBoost模型超参数调整

最终得到的最佳超参数组合是:{′alpha′:0.85,′colsample_bytree′:0.7,′eta′:0.05,′gamma′:0,′lambda′:5,′max_depth′:18,′min_child_weight′:1,′n_estimators′:200,′subsample′:1}。在测试集上进行评估,平均绝对误差MAE为0.005 10。
2.4.4 基于ANR 网络切换占比模型的传统网络小区邻区关系预测
对需优化邻区关系的传统网络小区选取5 km 范围内的周边小区,根据切换占比模型特征采集数据,构成样本输入模型进行预测。实验结果表明,对现网真实邻区关系的命中率为60%,即60%的现网邻区出现在预测出的占比前50名小区中。
3 总结
传统网络小区邻区优化是网优工作的重点和难点,人工优化方法费时费力。通过引入机器学习算法学习ANR 网络的邻区关系建立切换次数占比模型可模拟真实的传统现网邻区关系情况,极大程度地提高了邻区优化效率和用户网络口碑。
