新冠肺炎疫情信息累积更新采集系统的设计与实现
2021-06-18马乐荣
王 君,马乐荣
(延安大学 数学与计算机科学学院,陕西 延安 716000)
新型冠状病毒(2019-nCov)[1]是一类具有囊膜、基因组为线性单股正链的RNA病毒,是自然界广泛存在的一大类病毒[2]。该病毒在爆发前期,感染人数迅速上升,病毒在感染者身上会有一定时间的潜伏期,在此期间容易传染到接触者。由于新冠肺炎疫情在武汉的集中爆发,并迅速向全国各地蔓延,各省(自治区、直辖市)卫生健康委员会每天定时发布前一天的疫情相关数据,包括新增确诊病例、累计确诊病例、新增出院病例等,为人们的生活、出行、工作提供信息支持。
尽管也有一些平台收集资料并进行发布,但是想要第一时间获取数据最好的方式还需要在官网上进行查看。如果采用人工的方式收集数据,由于数据量庞大,这会花费大量时间,而且会存在手工整合数据错误的问题。因网络平台不同、数据格式不同,且数据每日都在更新,这样给及时获取数据带来了巨大的挑战。数据是分析、可视化、预测的基础,第一时间获取数据可以更方便的显示疫情数据的变化,了解国家对疫情把控的及时性。因此,本文使用Python语言、Scrapy库爬虫库和MongoDB[3]数据库,设计并实现了新冠肺炎疫情信息累积更新采集系统。该系统能对不同的网页结构采取不同的获取数据策略,并采用正则表达式对获取的文本进行数据清洗。实验结果表明,该系统具有良好的性能,并可推广使用。
1 实验设计
国家卫生健康委员会和31个省(自治区、直辖市)卫生健康委员会网站上设有疫情通报栏目,点击后会出现当日以前每一天的疫情情况。本文需要获取上述网页中新增确诊病例、新增疑似病例、新增出院病例、新增死亡病例和以上四项累计病例及累计报告病例、累计追踪密切接触者、尚在接受医学观察人数。
1.1 页面分析
在对网站页面进行爬取时,首先要对网页进行分析,各省(区、市)的网页结构不一样,内容上有的网站不仅包括了疫情情况而且还有当地的政策和通知。结构上有js动态加载内容,如吉林省卫生健康委员会疫情发布网页下一页按钮用js动态加载,福建省卫生健康委员会疫情发布网页统一在一个网址下,浙江省卫生健康委员疫情发布网页存在重定向问题。各网站发布的内容格式不同,如新增出院病人多少例和新增出院多少例,当出现境外输入病例时,累计确诊人数描述格式出现了变化。如陕西省卫生健康委员会网站对于新增病例出现过以下描述:新增**例新型冠状病毒感染的肺炎确诊病例,新增**例新冠肺炎确诊病例;对于累计确诊人数出现过以下描述:累计报告新冠肺炎确诊病例**例,累计报告本地确诊病例**例。
1.2 算法设计
图1是实验对应的程序流程图。
(1)首先访问start_urls中的地址。
(2)获取需要的每日疫情数据页面page_url,疫情通报栏目可能存在其他通知内容,在获取url时需要进行判别。
(3)如果未访问过,程序继续执行,如果访问过单条page_url,该地址不再访问,程序访问下一条page_url。
(4)访问数据详情页,获取疫情相关的数据。
(5)将数据存入到数据库。
(6)start_urls如果完成访问,则程序结束。否则继续(2)—(6)步骤。
1.3 数据筛选
每个网页爬虫爬取到的内容是包含所需数据的文本,不能直接使用,文本中含有特殊字符等使文本格式不整齐的内容,这就需要进行筛选和判别哪些是需要的数据。实验使用正则表达式匹配所需的内容,以键值对的形式对数据进行清洗,如键为new_care(新增出院),值为人数。
2 采用技术
本实验中使用Python3.6作为编程语言,使用Scrapy框架对网页数据进行爬取,并用Splash对页面中的JavaScript进行渲染,选择MongoDB数据库进行数据的存储。图2描述了系统组件图。
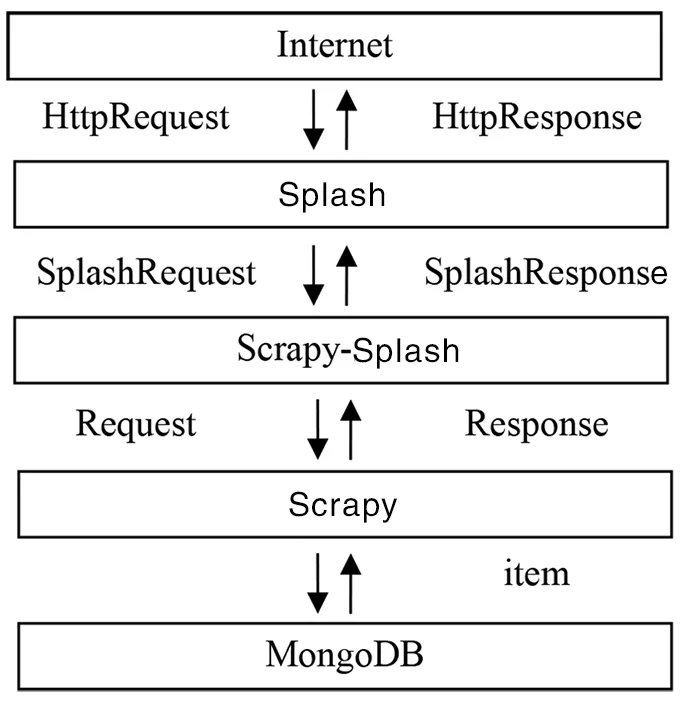
图2 系统组件图
2.1 组件介绍
Python是一门跨平台、开源、免费的解释性高级动态通用编程语言[4],支持面向对象程序设计,有大量在各领域可以调用的软件包。
Scrapy是一种用于抓取网站和提取结构化数据的应用程序框架[5],是基于Python实现的。Scrapy带有的选择器可以让用户通过xpah或者css选择器从网页中选择和提取数据[6]。提供了交互式的终端命令方式,可以用于提取数据的测试。它的middlewares.py可以按照实际需求定义自己的中间件,实用性强。
Splash可用于爬取动态网页,通过渲染JavaScript实现对网页的解析,Splash可以很好与Scrapy结合,经过渲染后可以直接用Scrapy分析网页。它需要在Docker中运行,使用时需要下载Scrapy-Splash库。
MongoDB数据库是介于关系数据库和非关系数据库之间的数据库,具备两者的某些有用的功能[3]。它由C++语言编写,是基于分布式文件存储的数据库。
2.2 技术实现要点
做实验之前首先要搭建好环境并进行测试。实验中创建新Python环境存放需要的第三方Python库。安装Python库若出现异常无法成功下载,可以考虑选择国内镜像进行下载,文献[7]中列有常见的Python镜像站。关于Scrapy-Splash库安装时需要首先安装Docker容器,对于Windows系统,Windows7和Windows8采用Docker Toolbox来安装,Windows10采用Docker Hub方式安装。
对于网络结构的不同,数据获取方式主要分为两大类:一类是不需要使用Scrapy-Splash进行渲染,可以直接进行获取;另一类是需要Scrapy-Splash预渲染。由于浏览器中的部分数据是通过js动态加载出来的,如果直接使用Scrapy的Response获取数据,会得到一个空的列表。经过Scrapy-Splash的SplashRequest对象,由Splash访问对象的页面后返回渲染之后的页面,在这一类问题中存在需要用Scrapy-Splash进行分页。部分网页存在重定向到第一页的问题,可以用js方式模拟鼠标点击解决。
3 关键问题及解决方案
本部分列举实验中遇到的问题及解决方案,总结如下:
问题1:代码没有编辑错误和运行错误,无法获取数据
这类问题的原因是网页是由js动态加载的,虽然在网页中可以查看到数据,但当查看源文件时搜索不到数据。解决办法是使用Scrapy-Splash对网页进行渲染。如果在Windows10系统上使用Docker toolbox方式安装,打开Docker Quickstart启动Docker Toolbox会出错;如果Windows10系统安装方式Docker不带有专门的命令终端,直接使用Windows系统的命令提示符运行命令docker pull scrapinghub/splash,下载镜像完成后使用命令docker run-it-p8050:8050--rm scrapinghub/splash,启动Splash服务。
问题2:网页中点击下一页,浏览器url地址不变
这类问题是由于实验中只有第一页的url地址,所以无法获取后面页面的信息。解决办法是在Splash的参数lua_source中模拟手动点击操作,第一页的后面页面都以第一页为基础,比如第二页在第一页的基础上模拟点击第一页一次,第三页在第一页的基础上模拟点击第一页两次,依次类推。由于Splash使用的是LUA语言,开启Splash服务后可以在本地浏览器上先进行测试。
问题3:如何判定某条页面数据是否抓取过
如果存在有重复数据,一是会增加数据库存储量,二是爬取效率不高。本实验尝试过三种方式。第一种是实验开始时首先查询数据库,以json格式保存爬取过所有的url,json的名称是城市的拼音,值是城市对应爬过的url,其次每获取到一个url与json文件的url进行比对,如果存在则不继续获取数据,反之程序继续运行,这种方式的好处是每次程序开始只需要访问一次数据库;第二种是每次获取到一个url都与数据库进行比对;第三种方式是采取多布隆过滤器进行url去重。多布隆过滤器的基本思想是:有一个固定长度的列表,初始时每个位置都为0,有多个哈希函数,每个哈希函数将一个元素映射到列表中的一个位置,并将该位置置为1,如果某个位置为1,我们就可以知道集合中有该元素。文献[7]中使用到了多布隆过滤器进行url去重。
4 实验结果
本次实验以国家卫生健康委员会和31个省(自治区、直辖市)卫生健康委员会官网发布的疫情通告栏目为数据采集对象。针对不同网页的结构采取不同的策略,不同的网络结构有JavaScript动态渲染,包括福建、贵州、江苏等省(区、市);浙江省疫情网页下一页会重定向到首页;福建省疫情网页点击下一页后,浏览器url地址不变。采集每天数据并存入数据库中,另外每条数据多加了当天的日期、网页地址和信息来源,增加信息来源的目的是方便后续核对。实验从2020年2月初开始,系统第一次从31个省(自治区、直辖市)卫生健康委员会官网累计获取总共约460条数据,之后实验每天访问官网疫情页面,程序自动判断哪些是新发布的数据,哪些是已经访问并存入数据库中的数据,实验只获取当天网上发布的数据,累计更新存入数据库中。对每个省(区、市)各自爬取约90条数据,总计爬虫2936条数据。最终访问数据库将各省(区、市)每天的数据保存为csv文件格式,以便后续的查阅和数据处理。
5 结论
本文以国家卫生健康委员会和31个省(自治区、直辖市)卫生健康委员会官网上发布的疫情通告为采集对象,给出了一种获取数据的有效方式,将采集的数据存入到数据库中,并且以csv文件方式单独存放每个省(区、市)的数据到本地文件中。实验证明该系统可以有效的针对不同网页结构采集到数据,清洗后的数据可以直接应用到后续工作,包括数据可视化、趋势预测等。
