结合随机森林与地理探测器的村域贫困分布格局及其分异机制分析
2021-06-17叶志超胡盈盈罗淑仪林锦耀冯艳芬
叶志超 胡盈盈 罗淑仪 林锦耀 冯艳芬

摘要 乡村贫困是我国经济发展过程中的重要问题,很多相关研究从定性或定量角度出发,分析地方或区域贫困问题,对扶贫脱贫的理论及实践产生了重要的意义。运用定量研究方法,结合机器学习与地理探测器分析村级贫困问题。以广东省重点扶贫地区连州市星子镇为例,选取12个对星子镇的贫困发生率产生影响的潜在因素,基于随机森林算法和地理探测器,对该镇21个行政村贫困分异的影响因素及其影响程度进行分析。结果表明:随机森林算法与地理探测器由于原理的差异,在分析各因子影响力这同一目的的前提下,得出数据结果存在差异;星子镇的贫困分异是多因子间的共同正向促进作用,具有复杂性,致贫需多模式综合并行;对于星子镇这个自然约束较大的地区,脱贫更需要着重降低社会阻隔,通过政策、资源的倾斜减缓社会阻隔,从而进一步促进自然约束力的降低,最终达到脱贫目的。
关键词 贫困分异;随机森林;地理探测器;连州市星子镇
中图分类号 K.902文献标识码 A文章编号 0517-6611(2021)02-0248-09
doi:10.3969/j.issn.0517-6611.2021.02.065
开放科学(资源服务)标识码(OSID):
Analysis on the Distribution Pattern and Differentiation Mechanism of Rural Poverty by Combining Random Forest and Geographical Detector
YE Zhichao, HU Yingying, LUO Shuyi et al
(School of Geographical Sciences,Guangzhou University, Guangzhou, Guangdong 510006)
Abstract Rural poverty is an important issue in the process of Chinas economic development. Many related studies analyze the local or regional poverty issues from a qualitative or quantitative perspective, which has important implications for the theory and practice of poverty alleviation.This article mainly used quantitative research methods, combined with machine learning and geographic detectors to analyze villagelevel poverty.Taking Xingzi Town, Lianzhou, a key poverty alleviation area in Guangdong Province as an example, and selecting 12 potential factors that affect the incidence of poverty in Xingzi Town,based on random forest algorithm and geographic detectors, the influencing factors and degree of poverty differentiation of 21 administrative villages in Xingzi Town, Lianzhou City were analyzed. The results indicated: due to the difference in principle between the random forest algorithm and the geographic detector, on the premise of analyzing the influence of various factors, the results are different; poverty differentiation in Xingzi Town is a common positive promoting effect among multiple factors, which means poverty differentiation is complex, and multimode integration is needed to get rid of poverty; for Xingzi Town, a region with greater natural constraints, poverty alleviation needs to focus on reducing social barriers. Through the tilting of policies and resources, social barriers are slowed down, which further promotes the reduction of natural constraints and ultimately achieves the goal of poverty reduction.
Key words Poverty differentiation;Random forest;Geographical detector;Xingzi Town in Lianzhou City
我國尚处于社会主义初级阶段,区域经济分化较为严重,贫富差距较大,且贫困人口多分布在偏远的山区和农村。改革开放以来,我国的减贫以消除绝对贫困为目标,经历了农村改革推动减贫,工业化、城镇化与开发式扶贫推动减贫,补齐全面建成小康社会短板推动减贫3个阶段[1],精准扶贫、乡村振兴战略正有条不紊地开展。国家提出“精准扶贫”战略,旨在运用科学方法对扶贫对象实施精确识别、精确帮扶与精确管理[2]。随后党的十九大报告进一步提出“乡村振兴”战略,集中力量坚决打赢脱贫攻坚战。扶贫工作要自上而下从“贫困区域—贫困村—贫困户”逐步细化扶贫对象,真正做到“精准化”。
为实现精准扶贫,国内外许多学者聚焦我国农村贫困识别及分异机制问题。研究方向主要集中在中国贫困化特征与贫困化主导因素识别上[3]。在数据处理与运用上,比较常见的处理方法是主成分分析法,该方法被运用在发展中国家公共卫生的相关研究上[4],而在地理信息方面,结合夜间灯光数据对区域贫困展开探讨也较为常见[5-6]。
地理探测器由王劲峰和徐成东等提出[7],目前学者对地理探测器的相关研究主要包括其原理以及应用,地理探测器的应用领域十分广泛并且较为成熟,如公共健康、自然灾害、旅游、生态环境等。在贫困研究上也得到较多应用,其内容主要涉及农村贫困化分异机制的地理探测与优化决策[8-9]、生态脆弱区贫困化的特征识别[10]、乡村反贫困绩效评估等[11]。在机器学习方面,相关学者大多使用神经网络模型研究贫困问题,常见的模型为BP神经网络,该模型可运用在研究集中连片特困区的区域贫困空间特征[12-13]。随机森林是近几年发展起来的一种新算法,在分类与回归方面比神经网络具有更优异的表现。尤其随机森林预测精度较高,不易过度拟合、具有较好的容噪声能力,能处理海量数据且对高维数据无需进行变量筛选[14]。但目前随机森林模型多用于生物信息、医学、遗传学以及经济领域,主要是进行预测、建模和算法的内部优化研究,在社会现象尤其贫困方面运用较少。
从现有研究成果来看,国内农村贫困化的相关研究仍以定性居多,主要包括农村贫困化机理、原因、政策等方面,而对农村贫困化地域分异机制的定量研究较少。原因主要是我国农村贫困统计数据缺乏,现有定量研究仍主要以较大尺度(如省级和县级)为研究单元,难以精准揭示乡村贫困的地理分布状况。而恰恰村镇是城乡地域系统的重要组成部分,村镇建设对于实现城乡统筹、促进城乡要素有序流动和乡村转型发展具有重要意义[15]。因此,笔者综合随机森林模型与地理探测器,拟诊断出镇域农村贫困化分异的主导因素,揭示农村贫困化分异特征及其动力机制,同时使两模型运行结果互相验证,分析两种算法的异同。
1 研究区概况与数据说明
1.1 研究区概况
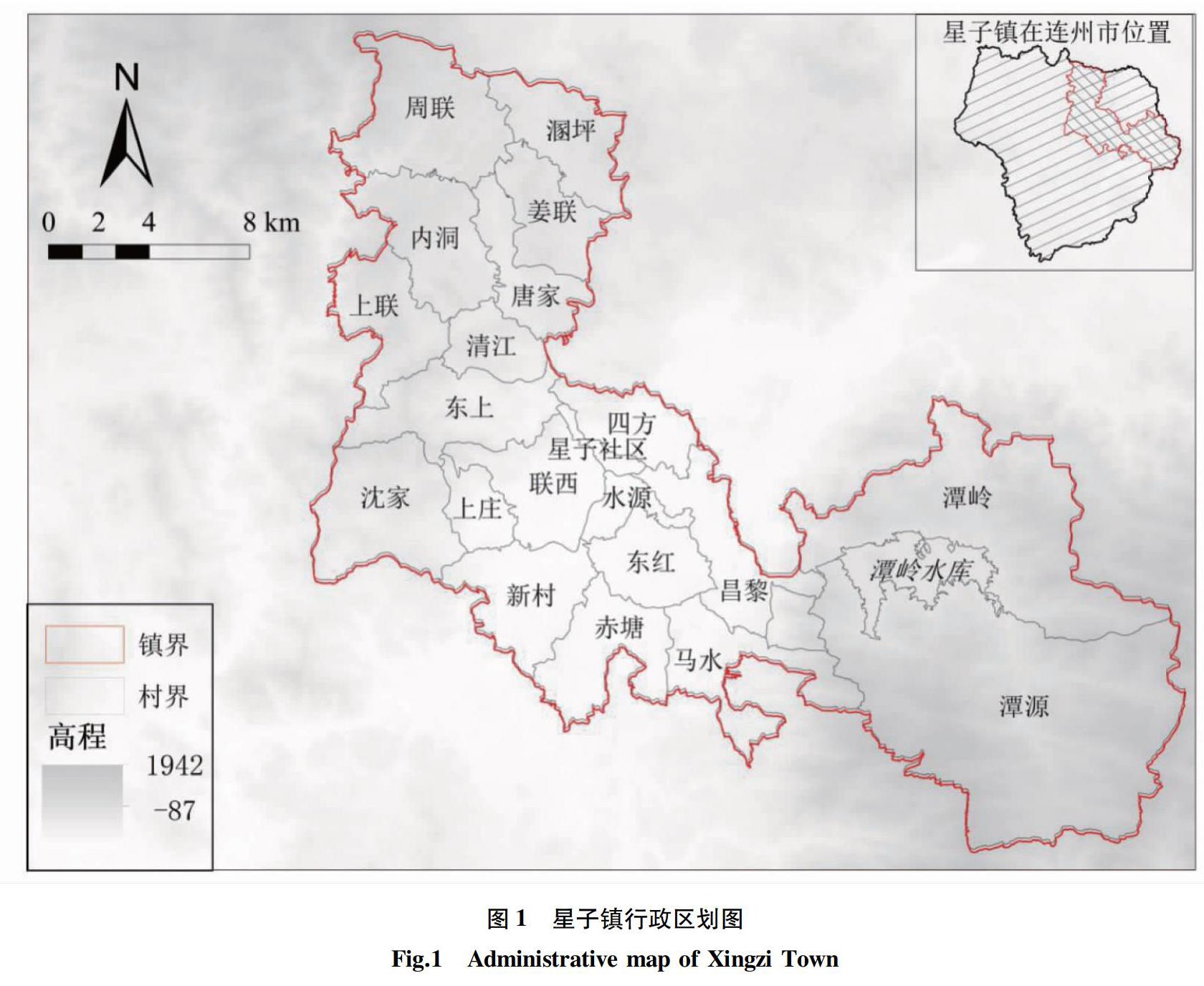
该研究区域为广东省连州市星子镇(图1),其位于连州市东北部,是广东的“北大门”,处于小北江的上游,地理坐标23°51′30″~25°08′00″N,112°25′00″~112°47′00″E。连州市地形以山地丘陵居多,由五大山脉连成一体且岩系构造复杂,土地肥瘠不匀。其中星子镇以农业生产为主,耕地资源东西分布不均,镇区地处小盆地,东北部为大东山脉。星子镇属亚热带季风气候,全年雨量充沛,平均年总雨量达1 612.2 mm。区域内矿藏分布广泛、电力资源丰富。全镇总面积462.5 km2,下辖1个社区居委会,20个村委会,总人口6.82万。但受自然与社会双重因素限制,星子镇新时期省定相对贫困人口村达11个,其中有贫困户1 443户,共3 478人,低保户593户,共1 352人,五保户279户,共295人。目前星子镇面临较为严峻的贫困问题,因此理清主要致贫因素,对区域开展精准扶贫具有重要意义。
1.2 指标选取与数据来源
贫困的影响因素具有复杂多变性,依据其属性分为自然环境和社会经济两大类。但其构成要素各异,没有统一的标准。围绕以农业发展为主的贫困地区应形成“公共政策-农业发展-减贫效应”复合减贫系统,协调系统发展态势,实现减贫[16];参考中国农村多维贫困相关研究[17];考虑数据的可获取性;遵循因素选择可空间量化原则、主导性原则、因地制宜原则[18],笔者选取12个指标作为模型的自变量因子,具体选取的影响因素及其数据来源见表1。表1简述的影响因素,在影响机制上部分表现为双向互为因果关系,部分表现为共线性特征[19],由于反映的侧重点不同,且地理探测器和随机森林模型均不受共线性影响,故允许其共存。此外,选取星子镇村级单位的贫困发生率作为衡量研究区域村镇尺度贫困程度的指标,即模型的因变量。该指标由2017年村内已知贫困人口数与村内总人口数比产生。
1.3 数据预处理
为了数据空间尺度的统一,首先应结合实际情况进行相关的数据预处理。其中属性数据需要通过公共字段关联到空间数据中,空间数据统一采用Xian_1980_3_Degree_GK_Zone_38投影坐标系,最终利用ArcGIS10.2软件处理得到12个尺度一致的栅格数据,每一数据栅格单元设定为10 m×10 m。各指标见图2。
DEM 數据来源于地理空间数据云网站(http://www.gscloud.cn/)提供的SRTMDEM数据集,空间分辨率为90 m。NDVI数据来源于地理空间数据云网站的MODIS陆地产品数据集(MYD13Q1),空间分辨率为250 m,覆盖星子镇全境。获取上述数据后,利用ArcGIS 10.2软件进行拼接、重投影、裁剪等操作得出结果。土地利用矢量数据通过连州市土地利用数据库获得。采用欧氏距离算法求解村庄各像元点中心与水域、道路、采矿用地、乡镇中心的距离以获得像元点到目标像元的最短距离,运行后生成对应栅格数据。此外,在ArcGIS 10.2软件将人口统计、贫困人数、耕地面积、劳动力比重、医保覆盖比重、养老保险覆盖比重、美丽乡村建设数量等相关属性数据与对应村空间数据进行关联,并将所需空间数据转为栅格数据。其中政策量化数据是通过栅格计算器对3个指标(美丽乡村建设数量、医保覆盖比重、养老保险覆盖比重)各赋值1/3权重叠加得到。POI数据通过百度地图(http://lbsyun.baidu.com/)提供的Place API接口获取,利用欧氏距离计算工具,经裁剪处理获得。
2 研究方法
2.1 随机森林算法
随机森林(random forest)是一种基于分类树的算法,通过产生多个分类树来生成结果,即在特征的选取和数据的选取上进行随机化,生成分类树并汇总其结果[20]。该算法需要模拟和迭代,是目前最为先进的机器学习方法之一,例如有学者提出其用于遥感分类的精度较高[21]。随机森林是以K个决策树{h(X,k,k= 1,2,…,K}为基本分类单元,进行集成学习后得到的一个组合分类器。通过随机选择样本和随机选择特征子集来生成大量的树,最终的分类决策可用式(1)表示。
H(x)=argmaxYkiI(hi(x)=Y)(1)
式中,H(x)表示分类组合模型,hi是单个决策树分类模型,I(·)为示性函数(示性函数是指一个函数使得当集合内有此数时值为1,当集合内无此数时值为 0),Y表示目标变量(或称输出变量)。
笔者在Matlab平台上构建随机森林回归模型,设置树的数量(ntree),并根据袋外误差(out-of-bag error)衡量各因子的重要性。采用两项评价指标检验模型结果的精度:其一为平均绝对误差MAE,全称Mean absolute error,它表示预测值和观测值之间绝对误差的平均值。MAE的值越小,说明预测模型拥有更好的精确度;其二为误差平方和SSE,全称The sum of squares due to error,该统计参数计算的是拟合数据和原始数据对应点的误差的平方和,SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。综上MAE和SSE的值越小,模型的可用性越高,以此判断结果的可信程度。
SSE=Ni=1wi(yi-i)2(2)
MAE=Ni=1|(yi-i)|n(3)
式(2)和式(3)中,N为样本观察值的数量,yi表示实测数据即第i个村庄的实测贫困发生率,i表示拟合的数据即第i个村庄的拟合贫困发生率,其中wi>0。
2.2 地理探测器
地理探测器是王劲峰等提出的一种评价样本空间分异性和自变量分异对因变量分异影响力的统计学方法,其核心思想是基于以下假设:如果某个自变量对因变量有重要影响,那么该自变量和因变量的空间分布应该具有相似性[7]。地理探测器共分为4个部分,笔者所用的探测器主要为分异及因子探测器、交互作用探测器。
分异及因子探测器:探测变量Y的空间分异性,以及探测某变量X在多大程度上解释了变量Y的空间分异性。分异性强度用q值度量,表达式为:
q=1-Lh=1NhNσ2σ2h=1-SSWWWT(4)
SSW=Lh=1Nhσ2h(5)
SST=Nσ2(6)
式中,h=1,…,L为因素X的分层;Nh和N分别为层h和研究区的单元数;σh2和σ2分别为层h和研究区的贫困发生率水平(Y)的方差,SSW为层内方差之和,SST为研究区总方差。q的值域为[0,1],值越大说明Y的空间分异性越明显;如果分层是由自变量X生成的,则q值越大表示自变量X对变量Y的解释力越强,反之则越弱。极端情况下,q值为1表明变量 X完全控制了Y的空间分布,q值为0则表明变量X与Y没有任何关系,q值表示X对Y的解释率为 100×q%。
交互作用探测器:识别不同风险变量Xs之间的交互作用,即评估变量 X1和X2共同作用时是否会增加或减弱对因变量Y的解释力,或这些变量对Y的影响是否为相互独立的,变量的关系分为5类,见图3。
3 结果与分析
3.1 贫困现状
根据贫困发生率衡量连州市星子镇的贫困空间分布状况。贫困发生率,是指贫困人口数占总人口数的比率。由图4可观察,连州市星子镇的贫困发生率从空间格局上看,不具有明显分布特征。其中贫困高发区主要分布在3个区域,即以周联、姜联为主的西北部地区;清江、东上、沈家、上庄为主的西部地区和以星子社区、联西、新村为界的以北和以东部分地区。贫困发生率大于等于10%的有2个行政村,分别是贫困发生率最高的四方村,为13.03%,和贫困发生率为10%的清江村。贫困发生率最低的为1.61%的星子社区,也是星子镇镇政府的所在地。
3.2 随机森林回归分析
3.2.1 随机森林运行。
通过ArcGIS 10.2创建1 300个随机点,采样提取数值,将未提取出的边缘值进行删除后,最终得到1275个有效样本数据,作为选取测试样本和训练样本的初始数据。为避免偶然现象的发生,从初始数据中随机选取5组测试样本与训练样本。分别在Matlab进行随机森林模型的构建,得出相应因子的重要性以及模型精度(表2)。并采用MAE、SSE两个参数(式2和3)来衡量随机森林模型对于样本的拟合程度,来确定随机森林模型的可用性。MAE和SSE的值越小,模型的可用性越高,以此判断结果的可信程度。
在进行随机森林运行前,先采用初始数据调试决策树的数量,將树的数量分别设置为10、100、1 000,发现随机森林结果未见明显差别,最终将决策树数量设置为100。由表2可知,MAE和SSE的值均小于0.1,说明5组训练样本的拟合程度较好,预测精度较高,即随机森林模型的可用性高。图5展示了5组随机森林模型得出的因子重要性,结果表明该研究所选取的12个因子重要性均为正值,均对贫困发生率起正向作用。其中劳动力比、政策因素和人均耕地面积这3个因子对研究区域的贫困发生率影响较大,而距道路距离、距水域距离和距政府机构距离则对研究区域的贫困发生率具有较小的决定力。
3.2.2 随机森林结果分析。
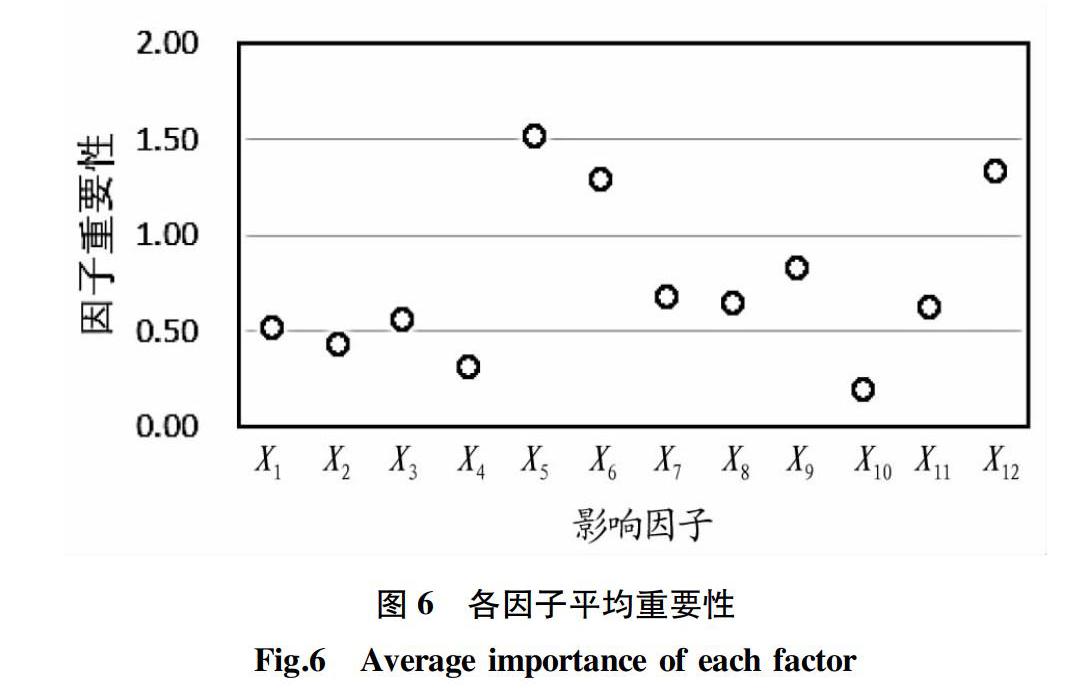
通过5组随机森林结果的平均值(图6)可知,笔者选取的12个因子均对贫困发生率有正向作用,决定力由大到小为人均耕地面积(X5)>政策因素(X12)>劳动力比(X6)>高程(X9)>距乡镇中心距离(X7)>距教育机构距离(X8)>距采矿用地距离(X11)>距医疗机构距离(X3)>NDVI(X1)>距政府机构距离(X2)>距水域距离(X4)>距道路距离(X10)。可见,人均耕地面积、政策因素、劳动力比和高程对星子镇的贫困发生率有较大的正向决定力,而距政府机构距离、距水域距离和距道路距离则对星子镇的贫困发生率有较小的正向影响。
3.3 地理探测器分析
3.3.1 地理探测器运行。
地理探测器与随机森林运用同一份随机点数据,通过采样工提取数值。对于样本提取,两者在因子处理上略有不同,随机森林所使用的数据均为连续变量,地理探测器所使用的数据均为类型变量。将未提取出的边缘值删除后,得到1 275个有效样本数据。由于地理探测器结果稳定,只对这1 275个样本数据运行一次得出结果。
3.3.2 因子影响力分析。
通过因子探测器得出因子探测结果(表3)。从结果可知各因子对贫困分异的解释力各不相同,按其q值排序为人均耕地面积(X5)>政策因素(X12)>距教育机构距离(X8)>高程(X9)>距乡镇中心距离(X7)>NDVI(X1)>距医疗机构距离(X3)>距道路距离(X10)>
勞动力比(X6)>距政府机构距离(X2)>距水域距离(X4)>距采矿用地距离(X11)。其中人均耕地面积、政策因素、距教育机构距离、高程的q值相对较大,是对贫困分异影响最大的4个因子,距政府机构距离、距水域距离及距采矿用地距离的q值相对较小,对贫困分异的影响最不明显。
3.3.3 因子交互作用分析。
从交互探测的结果(表4)可以看出,两因子相交的作用力普遍大于单因子的作用力,在该研究中交互作用类型有非线性增强和双因子增强两种,这也体现出一个地区的贫困分异往往是多方面的因素共同造成,而非某个单因子起决定作用。如X2与除X5和X10外的所有因子呈非线性增强,X4与任意因子交互都呈非线性增强。且结合表3与表4,可知即使X4与X11因子的q值不高,单个因子解释力很小,但是与其他因子进行交互作用后呈现非线性增强效应,对贫困分异的解释力明显增强。此外,在68对交互因子中(除去因子与其自身交互的情况),X5∩X12的q值为0.78,是所有交互因子中q值最大的一对,说明X5与X12的共同作用会比其他两两因子组合对贫困分异的影响更大。X4∩X11 q值最小,仅为0.062,说明X4与X11的共同作用影响力较小。
3.4 随机森林结果与地理探测器结果对比
随机森林通过袋外误差来确定因子的重要性,地理探测器通过因子探测的q值来确定因子重要性。对两者因子结果进行对比,如表5所示,大多数因子排序较为一致,其中重要性完全一致的因子共有6个。无论随机森林还是地理探测器最为重要的因子均为X5(人均耕地面积)和X12(政策因素),说明这两个因子对星子镇的贫困分异影响较大,且较为稳定。在其他非一致因子中,部分因子排序较近,相差位数不大,仅X6(劳动力比)存在明显不一致现象。在随机森林结果中劳动力比排列在第3位,但在地理探测器中,劳动力比排列在第9位。
3.5 贫困分异机制分析
结合随机森林算法与地理探测器结果可知,星子镇贫困分异的主导因子主要有5个:人均耕地面积、政策因素、距教育机构距离、劳动力比以及高程。而距水域距离及距政府机构距离的重要性在2种结果中都较靠后,属于非重要因子。
3.5.1 自然约束。
地区的贫困很大程度上取决于其自身的先天条件,如资源的丰欠、地势的高低、水源的远近等都与贫困紧密相关。笔者通过随机森林算法与地理探测器的分析,发现对星子镇贫困分异影响较大的自然因子为高程。此外人均耕地虽不能严格当作自然因子,但在农村地区,耕地的水准与地区土壤肥沃度、地势起伏度等自然因子关联性更大,在一定程度上也可作为自然因子考虑。虽然贫困地区先天带有的自然约束在贫困分异上往往起着重大的作用,但却难以得到有效根除。
对于星子镇而言,东南部及西北部地势较高,中部最低。复杂的地理环境对贫困的空间分布一般具有相当强的正向驱动作用[22],但是由于其他因子的中和作用,使得高程因子的作用力得到一定减弱。此外,星子镇目前仍以发展第一产业为主,人均耕地对星子镇的贫困发生率有较大的影响,在数据处理过程中发现其全镇耕地面积占全镇土地总面积的13.81%,有效耕地面积却仅占总耕地面积的15.97%,能够得到有效利用的耕地资源并不多,这也使得星子镇的贫困进一步的加深。
3.5.2 社会阻隔。
除地区的先天性因素外,后天的社会经济因素对贫困分异同样有着较强的影响力,有时甚至能成为主导因素。如政府权力的最大有效影响半径,社会资源分配的均衡性等,都往往会产生一定的社会阻隔[23],难以顾及所有地区。该研究中影响最大的社会因子为政策因素,此外教育资源也是影响较大的社会因子。从图2政策因子中可看出,中部距离镇中心较近的村,受到的政策帮扶明显高于西北部地区,东部地区考虑到水库的存在,会有一定政策的偏重。同政策因子一样的原理,越接近镇中心,教育机构数量越多,对地区的脱贫也就更有帮助。该结果中不难得知,距地区经济中心越远,其经济约束越大。而距市中心较远的星子镇,由于在接受社会资源分配的时候,处于一个稍劣势的地位,所分配的资源有限,也就造成了整体的相对贫困。
综合来看,自然约束与社会阻隔往往是相互促进、相辅相成的,共同作用于贫困。对于此案例而言,高程越大的地区社会资源输入也较为不便,除去政策因子这个帮扶性主观性较强的因子来看,高程越大其教育资源与医疗资源等也相对欠缺;而教育资源与医疗资源的欠缺,也无形中使得人们改变自然约束的能力减弱,增强了自然约束的影响力。
4 结论与讨论
笔者通过随机森林算法与地理探测器,以广东省连州市星子镇21个村为例,探讨了村级贫困分异的主导因素及其机制,揭示了贫困分异的复杂性,在精准扶贫背景下具有一定的指导意义,主要结论与分析如下:
4.1 随机森林与地理探测器结果存在一定差异
这2种分析方法均可衡量12个因子对星子镇贫困发生率的影响程度,但从表5可知所得结果存在一定差异。这种差异存在很多原因,对于地理探测器而言,不同的离散化方法和分类数量都会影响到地理探测器的分析精度[24]。且地理探测器的分析基础是统计关系,而非因果关系,这就使得其结果存在一定局限性[25];对于随机森林而言,数据的不平衡会造成少数类样本识别率低的问题,不同的参数设置会影响模型的精度。两者各有优劣,但与地理探测器相比,随机森林不仅仅可以衡量因子的重要性,还可以基于所构建的数学模型,进一步实现贫困发生率的预测和贫困户的识别,在这一方面笔者未作深入研究。
4.2 地区的贫困分异具有复杂性
对于单一主导因子来说,贫困发生与治理都较为明确,易于分析处理。但多数情况下,地区的贫困是多种因素共同发生作用,情况复杂。根据地理探测器中交互探测结果可知,星子镇的致贫因子基本都为相互增强的关系,不存在单一因子发生作用的情况。因子的共同作用,使得星子镇贫困分异更加明显,也加大了扶贫的难度。在实际工作过程中,治贫也需要综合各个因子的重要程度及其相互作用,发展不同的治贫模式。
4.3 对于自然约束较大的地区,脱贫需要着重降低社会阻隔
在研究中,自然约束与社会阻隔相互作用,共同影响着星子镇的贫困分异。但自然约束往往很难进行改变,长期的存在不断加强着贫困地区的社会阻隔,使得贫困度越来越严重;而对于社会阻隔来说,只要有足够的人力物力财力的投入,可以在特定时间特定空间较大程度上改善贫困。如该研究结果中可以直观地发现政策因子的重要性,对于星子镇这
个距离连州市中心较远的乡镇来说,很多社会资源难以输
入。对于它的脱贫,若着重于解决自然约束,将会导致资金花费大而治理效果低的局面。相反,通过加大政策的倾斜与资源的输入,来降低社会阻隔,如教育扶持、基础设施建设等,对星子镇的脱贫会有很大帮助。
参考文献
[1] 叶兴庆,殷浩栋.从消除绝对贫困到缓解相对贫困:中国减贫历程与2020年后的减贫战略[J].改革,2019(12):5-15.
[2] 王瑞芳.精准扶贫:中国扶贫脱贫的新模式、新战略与新举措[J].当代中国史研究,2016,23(1):82-85.
[3] LIU Y S,LIU J L,ZHOU Y.Spatiotemporal patterns of rural poverty in China and targeted poverty alleviation strategies[J].Journal of rural studies,2017,52:66-75.
[4] SU S L,GONG Y,TAN B Q,et al.Area social deprivation and public health:Analyzing the spatial nonstationary associations using geographically weighed regression[J].Social indicators research,2017,133(3):819-832.
[5] WANG W,CHENG H,ZHANG L.Poverty assessment using DMSP/OLS nighttime light satellite imagery at a provincial scale in China[J].Advances in space research,2012,49(8):1253-1264.
[6] YU B L,SHI K F,HU Y J,et al.Poverty evaluation using NPPVIIRS nighttime light composite data at the county level in China[J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2015,8(3):1217-1229.
[7] 王勁峰,徐成东.地理探测器:原理与展望[J].地理学报,2017,72(1):116-134.
[8] 刘彦随,李进涛.中国县域农村贫困化分异机制的地理探测与优化决策[J].地理学报,2017,72(1):161-173.
[9] 蒋潞遥,廖和平,曾于珈,等.山区农村贫困化分异机制探讨[J].湖北农业科学,2018,57(19):28-34.
[10] 夏四友,赵媛,文琦,等.喀斯特生态脆弱区贫困化时空动态特征与影响因素:以贵州省为例[J].生态学报,2019,39(18):6869-6879.
[11] 谭雪兰,蒋凌霄,米胜渊,等.湖南省县域乡村反贫困绩效评价与空间分异特征[J].地理科学,2019,39(6):938-946.
[12] 刘一明,胡卓玮,赵文吉,等.基于BP神经网络的区域贫困空间特征研究:以武陵山连片特困区为例[J].地球信息科学学报,2015,17(1):69-77.
[13] 曾永明,张果.基于GIS和BP神经网络的区域农村贫困空间模拟分析——一种区域贫困程度测度新方法[J].地理与地理信息科学,2011,27(2):70-75.
[14] 严梦佳,钟平安,闫海滨,等.基于随机森林的水电站发电调度规则研究[J].水力发电,2018,44(1):85-89.
[15] 屠爽爽,龙花楼,李婷婷,等.中国村镇建设和农村发展的机理与模式研究[J].经济地理,2015,35(12):141-147,160.
[16] 蒋辉,刘兆阳.贫困地区公共政策、农业发展与减贫的耦合协调分析:基于贵州、云南、安徽三省数据的实证分析[J].经济地理,2016,36(11):132-140.
[17] LI G E,CAI Z L,LIU J,et al.Multidimensional poverty in rural China:Indicators,spatiotemporal patterns and applications[J].Social indicators research,2019,144(3):1099-1134.
[18] 常敏.贫困村致贫因素探测及其土地资源利用[D].广州:广州大学,2018.
[19] 王超,阚瑷珂,曾业隆,等.基于随机森林模型的西藏人口分布格局及影响因素[J].地理学报,2019,74(4):664-680.
[20] BREIMAN L.Random forests[J].Machine learning,2001,45(1):5-32.
[21] PAL M.Random forest classifier for remote sensing classification[J].International journal of remote sensing,2005,26(1):217-222.
[22] 周蕾,熊礼阳,王一晴,等.中国贫困县空间格局与地形的空间耦合关系[J].经济地理,2017,37(10):157-166.
[23] 刘小鹏,李伟华,王鹏,等.发展地理学视角下欠发达地区贫困的地方分异与治理[J].地理学报,2019,74(10):2108-2122.
[24] CAO F,GE Y,WANG J F.Optimal discretization for geographical detectorsbased risk assessment[J].GIScience & Remote Sensing,2013,50(1):78-92.
[25] 通拉嘎,徐新良,付颖,等.地理环境因子对螺情影响的探测分析[J].地理科学进展,2014,33(5):625-635.
