分布式词向量研究和实现
2021-06-16唐国豪
唐国豪
(西北工业大学附属中学,陕西西安,710000)
1 研究背景
■1.1 研究意义
词是自然语言处理的最小单位,计算机中无法对词进行直接处理,因此需要采用数学的方式去表示词,通常采用的方式是词向量。常见的词向量有两种,分别是独热词向量和分布式词向量。分布式词向量表示相比于独热表示,具有向量维度小、具有语义相似性的特点。大规模数据训练得到的词向量,在各种下游任务如文本分类、文本聚类中表现超越传统方式,慢慢成为计算机处理自然语言的范式。
■1.2 国内外研究现状
Bengio在2003年提出了神经网络语言模型(Neural Network Language Model),该模型在学习语言模型的同时,得到了词向量。在对统计语言模型进行研究的背景下,Google公司在2013年开放了word2vec这一款用于训练词向量的软件工具。Word2vec可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式,为自然语言处理领域的应用研究提供了新的工具。Tomas Mikolov在2013年提出的两种训练词向量方式CBOW(Continues Bag-of-Words Model)模型和Skip-Gram(Continuous Skip-gram Model)模型,CBOW的主要思想是用词的上下文预测当前词,可看作语言模型的神经网络表示,而Skip-gram模型与CBOW模型训练方式刚好相反,是通过当前词预测其上下文。facebook人工智能研究院(AI Research)在2016年开源了fastText,它是一个词向量与文本分类工具,用简单而高效的文本分类和表征学习的方法,解决了带监督的文本分类问题,FastText结合了自然语言处理和机器学习中最成功的理念。
2 相关技术综述
■2.1 中文分词
在自然语言处理中,词是语义理解的最小语言成分。中文分词是指用技术手段,将汉语中句子拆分成一连串有意义的词。常见做中文分词的方式有基于语义的中文分词、基于匹配的中文分词和基于概率统计的中文分词。本文主要介绍基于概率统计的中文分词方式。
基于统计的分词方式的基本原理是计算不同切分下组成句子的概率,组成句子概率最大的切分方式即为句子的分词。这种分词方法基于一个非常简单的思想:越合理的句子在现时生活中出现概率越大。若S表示一个句子,其组成方式为S=w1,w2,…,wn,其中n是句子的长度,句子S出现的概率,可以表示成如下:
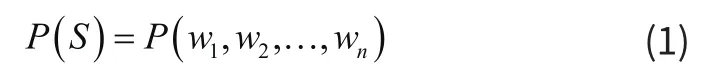
根据条件概率公式,可将式2-1展开如下:
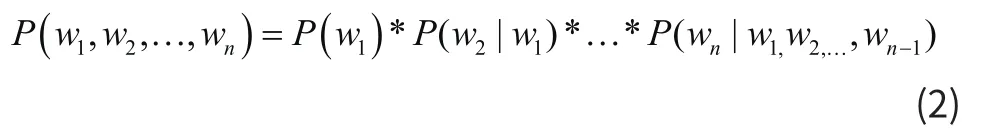
式(2)中, P (w1) 为词w1出现的概率, P (w2|w1) 为词w1出现的条件下词w2出现的概率,根据条件概率可知,第i(i= 2,3,4,…,n)个词是否出现与前面i-1个词均相关。式(2)我们称之为统计语言模型。
根据式(2),计算出右边每一项的值,相乘则得到句子出现的概率 P (S)。大树定理告诉我们:当统计量足够时,可以近似用频率近似代替概率。若用#w1表示w1在语料库中出现的频数, # (w1,w2,…,wi) 表示(w1,w2,…,wi)同时在语料库中出现的频数,#表示语料库中词语总数。根据大树定理,可以按照如下公式计算式(2)中右边的每一项:
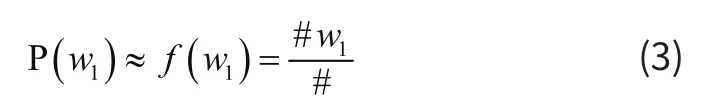
依据二元模型和大树定理计算不同切分下句子的概率,如果有:
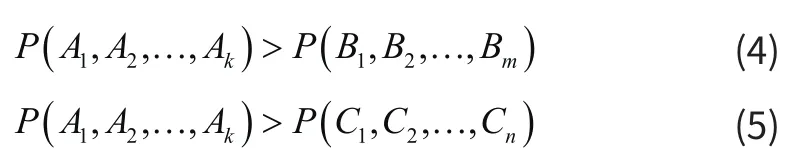
依照统计语言模型分词思想,A1,A2,…,Ak是最好分词方法。
句子S的切分方式随着句子S长度增加而呈指数型增长,采用穷举的方式计算每种切分方式下的句子的概率会导致计算复杂度过大,在实际应用中难以忍受,当前一般利用维特比算法解决这个问题。
■2.2 词向量训练
自然语言中词不能被深度学习算法直接处理,为了深度学习能够处理词,需要用数学方式表示词,词向量就是词的一种数学化表示方式。常见的词向量有两种,一种是独热表示(One-Hot Representation),另外一种是分布式表示(Distribute Representation)。
独热表示的词向量使用一个长度为词典大小的向量表示一个词,向量的分量只有该词在词库中索引位置处为1(词典索引从0开始)其他位置全为0。这种表示有两个巨大的缺陷:一个是维度灾难,表现为向量维度太大(量级大概在百万左右),占用的时间和空间巨大,特别是应用于深度学习中;另一个是词汇鸿沟,独热表示下任意两个向量内积为0,空间中表示为两个向量独立,语义上表示为两个词语义不相关,丢失了词语之间的相似性。
分布式表示最早由Hinton于1986年提出,是一种低维、稠密和包含语义相似性的词向量。分布式词向量语义相似性可由向量距离体现,计算词向量在语义空间距离可以得到词向量表示词之间的语义相似性,表示为空间距离越近则词语语义越相似。
word2vec中主要用到的是CBOW(Continues Bag-of-Words Model)模型和Skip-Gram(Continuous Skip-gram Model)模型,这两个模型是是Tomas Mikolov在2013年提出的两种训练词向量方式[3,4]。CBOW的主要思想是用词的上下文预测当前词,可看作语言模型的神经网络表示,而Skip-Gram模型与CBOW模型训练方式刚好相反,是通过当前词预测其上下文。 以CBOW模型为例,介绍word2vec训练的原理,CBOW模型结构如图1所示。
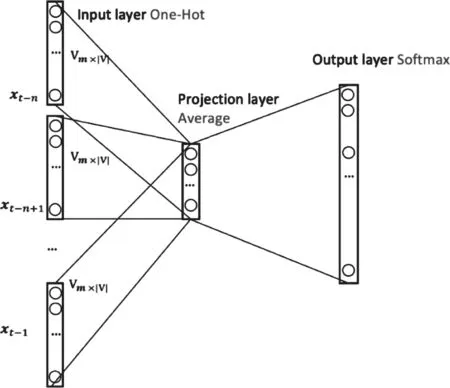
图1 CBOW模型结构
CBOW模型是一个三层的神经网络结构,模型中没有使用复杂的网络结构,每层之间均为全连接。输入层(Input Layer)是之前n-1个词的独热表示向量,每个向量通过矩阵乘法乘以一个维度为的权重矩阵后得到维度为m的向量;映射层(Projection Layer)直接把n个m维向量做平均,得到映射层的输出;输出层(Output Layer)包含个神经元,每个神经元对应词库中一个词,通过softmax函数将矩阵乘法结果映射到概率,这个概率表示预测结果为该神经元对应词的概率。在一个大型的语料库中,按照上述方式构建网络的输入和输出,通过反向传播算法,交叉熵损失作为损失函数,以梯度下降方式不断修正网络参数。当损失函数收敛时,网络训练完成,取出输入层和映射层之间的权重参数做为预训练好的词向量。
■2.3 FastText
fastText是facebook人工智能研究院(AIResearch)在2016年开源的文本表示和文本分类的工具。fastText的主要功能有文本表示、文本分类和模型压缩,分别在三篇论文中进行了详细的介绍。总结来说,fastText提供了一套完整的文本分类需要的工具,并且开源了其C++代码。C++工具包使用非常方便,文档也非常完善。本文主要使用到的fastText功能是文本表示,相对于Google在2013年提出的word2vec,fastText训练速度非常快,能够学习到词的形状特征,还能部分解决OOV(Out of Vocablary)问题。
3 实验结果和分析
■3.1 实验环境
本文实验使用的操作系统是Ubuntu16.04,中文分词工具使用的是jieba,词向量训练工具是fastText v0.9.1,实验环境硬件配置如表1所示。

表1 实验环境配置
■3.2 数据集介绍
本文使用的语料来源于清华大学新闻分类语料库THUNews,THUNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含83万篇新闻文档(3.9 GB),均为UTF-8纯文本格式。在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
■3.3 评价指标介绍
词向量表示好坏往往非常难以直接横向,本文拟采用文本表示下的文本分类效果来衡量系向量好坏。在分类任务中,我们通常用准确率,召回率和F度量值表示文本分类效果。在二分类任务中,准确率(Precision,P)表示在分类器判断为正样本的样本中真实为正样本的比例,召回率(Recall,R)表示被分类器判断为正样本且真实为正样本的样本占样本中所有真实为正样本的比例。为了更好的描述准确率和召回率,引入混淆矩阵(Confusion Matrix),混淆矩阵定义如表2所示。

表2 混淆矩阵
其中,TP表示将正样本预测为正样本的数目,TN表示将负样本预测为负样本的数目,FP将负样本预测成正样本的数目,FN将正样本预测为负样本的数目。根据以上描述,准确率和召回率可以表示为:
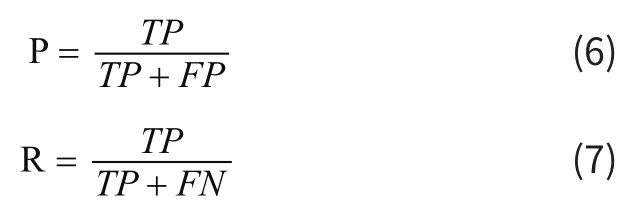
■3.4 实验结果分析
词向量训练采用的是网上提供的开源工具fastText,fastText是Facebook提供的一个词向量训练工具,速度很快,能够在普通CPU上在几十分钟内快速训练得到词向量。在(3)中得到的训练集合中用fastText,采用CBOW模型,训练词向量。训练用时14分钟,得到一个词库大小为277959,向量维度为100维的词向量,人工检查发现向量相似性效果较好,如与妈妈最相似的两个词分别是“爸爸”和“女儿”;与高兴最相似的两个词是“更高兴”和“开心”。
将数据按照9:1划分训练集和测试集,在训练集合上用构造分类器,用时2分14秒,在测试集合上验证分类器正确率为94.1%,高于清华大学公开分类器的87%。
4 总结和展望
本文主要介绍了分布式词向量。我们首先对基于概率统计的中文分词进行研究,建立了统计语言模型。然后使用FastText分类工具CBOW模型进行分布式词向量训练。确定了实验环境,使用了清华大学新闻分类语料库THUNews,明确了评价指标。通过实验,采用文本表示下的文本分类效果来衡量词向量表示好坏,实现分布式词向量的指标评价,并对实验结果进行分析,人工检查发现向量相似性效果较好。实验结果表明,分布式词向量是一种维度小、含有语义相似性的词向量。
研究分布式词向量过程中,我对分布式词向量的原理和含义有了深入的了解,并且在完成论文中实验过程中,我掌握了训练分布式词向量流程,对其中使用到的数据集和开源工具有了简单的了解;在科学研究过程方面:我学习到科学研究的一般过程,了解了许多查询资料的手段。最终,在同学和老师的帮助下,利用开源工具fastText实现了一个版本的词向量,并且在文本分类任务中检验训练好的词向量效果,在THUNews数据集上达到94.1%的正确率。
