城镇污水处理厂能耗信息系统研究与实现
2021-06-16张颖孔祥文苏杰张维
张颖 孔祥文 苏杰 张维
(中国市政工程华北设计研究总院有限公司 天津市 300074)
1 引言
20 世纪90年代以来,随着国家和地方政府对节能减排和人居环境质量改善目标的重视和落实,我国城镇污水处理事业得以快速发展,污水处理设施在地级以上城市已全面普及。近年来,随着对城镇污水处理厂出水水质要求的不断提高,污水处理的高能耗、高药耗已在行业内引起广泛关注。
目前,国内外很多科研机构、高校对不同城市的典型污水处理厂的电耗、药耗情况进行了分析评价[参考文献],以期为污水处理厂的节能降耗提供参考。但是,对于全国范围内城镇污水处理厂的能耗、物耗的总体水平鲜有深入研究和分析,与国外发达国家污水处理厂能源消耗情况的对比更是少之又少,因此,为了挖掘我国城镇污水处理厂节能降耗潜力,提高污水处理厂运行效能,为我国污水处理厂设计和运行优化提供参考,建立一个城镇污水处理厂能耗信息系统就变得尤为重要,用信息化手段将全国范围内污水处理厂的相关数据汇集起来并加以处理分析,使行业人员能快速准确的从多维度获取统计分析结果。
2 系统构建设计
2.1 系统整体架构
城镇污水处理厂能耗信息系统的总体架构如图1 所示,共分为数据采集、数据处理、数据分析及可视化展示四个模块,其中数据采集和数据处理关系着整个系统是否能提供可靠数据进行统计分析并对整个行业是否有参考价值,故本文重点介绍这部分内容。
2.2 数据库搭建
结合我国近4000 座运行的典型城镇污水处理厂近五年不同季节的电耗和各类化学药剂的投加情况,建立了“典型城镇污水处理厂能耗物耗数据库”。数据库包含所属流域、处理规模、排放标准、工艺类型等污水处理厂的基本信息、总能耗与处理单元能耗的能耗数据信息,以及涉及外加碳源、除磷药剂、脱水药剂等常用药剂的投加量数据信息,可对不同规模、不同排放标准、不同工艺类型的污水处理厂的能源消耗情况进行统计分析,并可对标一些发达国家的能耗水平。
2.3 粗大误差数据处理
粗大误差是指在测量过程中,偶尔产生的某些不应有的由异常因素造成的测量数值超出正常测量误差范围的小概率误差[1]。在实际污水处理厂能耗数据采集过程中,由于手机设备硬件条件及周边环境的影响,往往会产生部分具有粗大误差的数据,这种数据将导致后续数据统计分析结果产生偏差,大大降低数据的价值和有效性。因此,需要寻找一种有效的处理异常数据的方法来提升数据质量和价值。
目前在数据处理过程中,通常采用拉伊达准则、格拉布斯准则、肖维勒准则、狄克逊准则等进行异常数据的识别,本研究对以上几种方法进行了简单的对比分析。
2.3.1 拉伊达准则
拉伊达准则[2]是以三倍测量列的标准bai 偏差为极限取舍标准,其给定的置信概率为99.73%,该 准则适用于测量次数n>10 或预先经大量重复测量已统计出其标准误差σ 的情况。Xi 为服从正态分布的等精度测量值,可先求得它们的算术平均值 X、残差vi 和标准偏差σ。若|Xi- X|>3σ,则可疑值Xi 含有粗大误差,应舍弃;若|Xi- X|≤3σ,则可疑值Xi 为正常值,应保留。 把可疑值舍弃后再重新算出除去这个值的其他测量值的平均值和标准偏差,然后继续使用判别依据判断,依此类推。
2.3.2 格拉布斯准则

图1:系统架构图
图2:系统登录页
格拉布斯准则[3]适用于测量次数较少的情况(n<100),通常取置信概率为95%,对样本中仅混入一个异常值的情况判别效率最高。其判别方法如下:先将呈正态分布的等精度多次测量的样本按从小到大排列,统计临界系数G(a,n)的值为G0,然后分别计算出G1、Gn:G1=(X-X1)/σ,Gn=(Xn-X)/σ,(1) 若G1 ≥Gn 且G1>G0,则X1 应予以剔除;若Gn ≥G1 且Gn>G0,则Xn 应予以剔除;若G1<G0且Gn<G0,则不存在“坏值”。 然后用剩下的测量值重新计算平均值和标准偏差,还有G1、Gn 和G0,重复上述步骤继续进行判断,依此类推。
2.3.3 肖维勒准则
肖维勒准则[4]是建立在频率p=m/n 趋近于概率P{|Xi- X|>Zcσ}的前提下的(其中m 是绝对值大于Ecσ 的误差出现次数,P 是置信概率)。设等精度且呈正态分布的测量值为Xi,若其残差vi ≥Zcσ则Xi 可视为含有粗大误差,此时把读数Xi 应舍弃。把可疑值舍弃后再重新计算和继续使用判别依据判断,依此类推。
2.3.4 狄克逊准则
狄克逊准则[5]是一种用极差比双侧检验来判别粗大误差的准则。它从测量数据的最值入手,一般取显著性水平a 为0.01,此准则的特点是把测量数据划分为四个组,每个组都有相应的极端异常值统计量R1、R2 的计算方法,再根据测量次数n 和所对应的统计临界系数D(a,n)按照以下方法来判别:若R1>R2,R1>D(a,n),则判别X1 为异常值,应舍弃;若R2>R1,R2>D(a,n),则应舍弃Xn。
通过上述分析可知,以上准则在进行数据处理时效果均与样本容量有密切关联,当样本容量过大时,格拉布斯准则、肖维勒准则、狄克逊准则对异常数据检测的准确性将大为降低,而全国城镇污水厂的能耗数据是大样本数据,所以本研究采用拉伊达准则对采集的数据进行数据处理,剔除具有粗大误差的数据,保障后续统计分析的准确性。
3 系统开发实现
3.1 开发工具及环境
城镇污水处理厂能耗信息系统是基于B/S 架构的JAVA Web 应用程序,部署于tomcat 服务器,并集成于MyEclipse 进行程序创建和开发。
该系统前端采用了HTML、CSS、JavaScript、AJAX、Flash 等技术进行界面创建及美化,同时为了更加灵活生动的从多维度展示统计分析的成果,系统采用了百度开源的ECharts 工具制作了大量图表进行可视化展示。后端采用了J2EE 技术,它是为了克服传统Client/Server 模式的弊病,迎合Browser/Server 架构的潮流,为应用Java 技术开发服务器端应用提供一个平台独立的、可移植的、多用户的、安全的和基于标准的企业级平台,从而简化企业应用的开发、管理和部署。
此外,该系统在数据库端采用SQL Server 2008 来存储大量的城镇污水处理厂能耗数据,并广泛采用各种数据库技术进行数据处理和数据统计分析,为最终的数据可视化展示提供依据。
3.2 系统功能介绍
该系统如图2 所示,主要包含四个模块,信息录入、统计分析、条件查询和比较参考,其主要功能为:
(1)系统采用了SQL Server 数据库进行污水处理厂能耗信息数据的存取,数据可通过页面录入的方式进行单条存储,或通过Excel 导入的方式进行大批量数据的存储,如图3 所示。
(2)运用大数据技术对数据库中的海量数据进行计算与分析,将统计结果以图表的形式以不同角度和内容展现,如图4 所示。
(3)可自定义查询条件,如图5 所示,通过组合查询的方式筛选出所需的数据进行统计分析,并以图表形式展现。
3.3 系统特点
(1)与行业技术紧密结合,污水处理厂能耗信息系统是部门自主研发,系统中的数据来源于全国各地上千个污水处理厂的实际数据,通过研究行业主管部门的监管需要以及调研各项业务指标的相互关系,筛选出满足城镇污水处理有研究价值的主要指标,运用信息技术构建了系统中的几个重要模型,如污水厂基本信息、月水质水量泥量、月药耗量、月物耗量等,从而架起了行业信息与互联网系统之间的桥梁,为系统的建立奠定了基础。
(2)在数据录入方面,大部分系统都会采用页面录入的方式,页面录入的方式简单直观,但适用于数据量不大的情况,该系统保留了单条数据页面录入的方法,同时也提供了批量数据后台导入的方法以满足数据量庞大时录入系统的情况,为了避免异构数据导入失败,系统为用户提供了Excel 模板,利用模板可以在数秒内导入大批量数据,增加了系统的实用性,为用户提供了便利。为了避免导入系统的数据中含有干扰数据从而影响计算结果的准确性,结合该系统模型的实际情况自主设计了一种排除干扰数据的过滤算法,使得在系统导入数据后自动对数据进行检测且不对前端运行产生影响,方便准确。

图3:信息录入模块
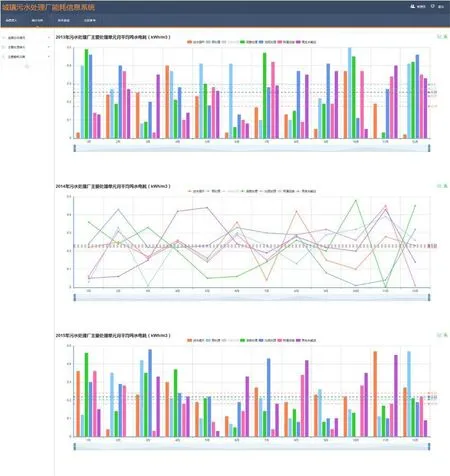
图4:图表展示样例
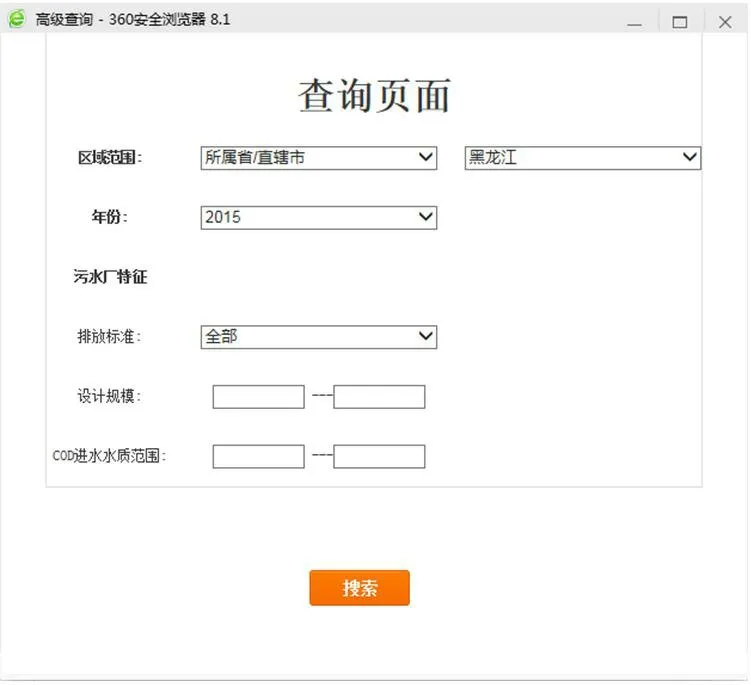
图5:多条件查询界面
(3)不同于冗长的报表式数据展示,系统中对各指标的计算结果全部采用图表这种可视化数据形式展现,但不同于一般系统中的静态图表,该系统采用支持动画的动态图表,图表生成后可进行柱状图、曲线图的切换,可变换需要显示的属性,也可调整横坐标的显示区间等。对于复杂的污水厂能耗数据,这种展示方式能让数据更生动、图表更闪耀、交互更友好、使用更便捷。
(4)为了避免系统因过快上涨的数据量而导致运行效率降低甚至崩溃的情况,以城镇污水处理厂能耗信息特点为基础,以互联网时代下大数据技术为背景,以数据库优化技术为手段,结合该系统特点构建了一套系统优化方案,从最大限度上减少因数据量增加以及算法计算的复杂性而影响系统运行速度,从而提高系统的可用性。
(5)由于污水处理厂能耗数据的基本信息指标较多,为了使用户能个性化定制查询条件从而较准确的定位自己所需的数据,系统采用了购物网站类似的多条件组合查询功能,从而避免了单一查询每次只能选择一个查询条件的情况,使系统可操作性更强,用户使用更加方便。
4 结束语
城镇污水处理厂能耗信息系统的项目建设是坚持信息技术与管理制度相结合、坚持信息技术与行业技术进步相结合、坚持信息技术与国家重大决策相结合的一项重要成果。城镇污水处理厂能耗信息系统将污水厂真实的能耗数据以信息化的表达方式构建模型,使数据从传统管理方式向信息化管理方式转变;利用计算机程序从庞大的数据中以算法为依据计算出所需的结果,并以图表方式直观展
现给用户,避免人为计算产生的差错以及降低数据的时效性;大数据、数据库优化等信息化技术的应用优化了数据库系统结构,避免了干扰数据对计算结果准确性产生影响,同时也加快了系统的运行速度,提高了系统的可用性。城镇污水处理厂能耗信息系统在我院运行良好,同时也需要不断的完善,随着城镇污水问题层出不穷,系统也应与时俱进,模型架构需不断充实、系统功能需不断扩展、运行速度也有待提高,尤其是如何与数据挖掘技术相结合提取出更多对节能减排有价值的信息是以后工作中应更加努力的方向。相信随着系统功能不断完善,数据及时性、准确性、全面性不断提高,该系统会成为城镇污水处理管理工作强有力的技术支撑。
