基于行为日志的性格倾向预测
2021-06-16张晗陈平华秦勇
张晗 陈平华 秦勇
(1.广东工业大学 广东省广州市 510006 2.东莞理工学院 广东省东莞市 523830)
1 引言
基于日志的分析方法方法,是将从服务器客户端[1]收集的用户日志映射到终端操作行为中,通过研究用户与现有系统的交互关系,并进一步了解用户的性格。对网络用户行为日志的应用过程主要包括数据的预处理、网络用户行为模型的构建和网络用户行为的分析。过去的研究表明用户的性格特征的确通过网上的交互行为有所体现[2-3]。而目前用于分析用户网络行为研究性格分析通常有以下两种方法:
基于机器学习的方法,该方法使用词和词类的频率来量化文本,并结合支持向量机和朴素贝叶斯等传统的机器学习方法进行个性分析。例如Talasbek 等人使用k-means 聚类机器学习算法描述人格分类[4]。传统的方法其泛化能力较差,通常在某一特定领域表现优秀,例如机器学习方法多用于交通流量识别而在网络流量分析中表现不好[5]。
基于深度学习的方法,近年来该方法在自然语言处理的问题研究中受到了关注,较好地避免了机器学习方法的弱点。例如Araque等人提出了基于深度学习的集成技术,用于在社交应用中对情感进行分类[6]。现有的基于深度学习的方法有两个主要的局限性[7]:
(1)只提取用于人格检测的关键词;
(2)缺乏对情感信息和心理语言特征的分析。
传统的机器学习算法在小数据集的分类和回归任务中表现良好,该方法更适合处理大型社交媒体[8]。显然,以往的这些研究内容主要集中于社交网络上做分析[9],且数据单一。所以本研究在前人的方法基础上提出了一种基于用户日志数据预测性格的方法,由于日志数据具有动态性,所以本研究考虑使用长短时记忆(LSTM)神经网络结构,选用学生上网行信息构建用户性格模型,通过对用户信息与用户性格之间的关系进行分析。
2 预测模型方法
2.1 模型结构
该方法分为输入层、性格特征提取层和输出三个层,如图1 所示。第一层通过日志数据作为输入,通过主成分分析算法得到最优特征维度。第二层对第一层的输出作为LSTM 网络的输入,以捕获它们从顺序依赖关系。在网络的隐藏层进行加入Dropout 层。最终分析后得到该用户的性格倾向。
2.2 LSTM网络
典型的LSTM 单元由一个输入门(it)、一个输出门(Ot)、一个遗忘门(ft)、上一个神经单元的输出数据(ht)、一个单元状态(C't)组成。图2 给出了简化后的LSTM 单元。
W 是门的权重矩阵,b 是偏差向量,σ 是sigmoid 非线性激活函数;tanh 是正切函数。
3 模型建立
3.1 数据选取与处理
本实验用的数据来源于3 部分:
(1)学生辅导员处记录学生心里情况的名单。该名单是校内通过权威调查,并结合线上线下心理医生对学生访问分析后统计出来的名单。
(2)迈尔斯-布里格斯类型指标(MBTI)。来源于MBTI 问卷平台获取的心理状态数据,包含包括内倾(I)、外倾(E)、感觉(S)、直觉(N)、思维(T)、情感(F)、知觉(J)、判断(P),共计8 个指标。本实验选取其中内倾(I)、外倾(E)两个指标作为数据标签,实验中将该指标和辅导员处的学生名单进行融合。
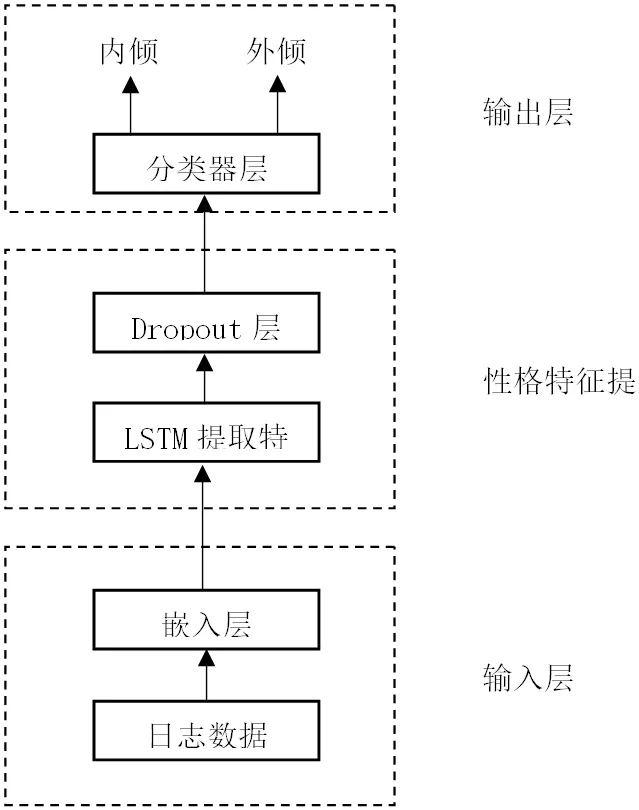
图1:模型结构图

图2:简化后LSTM 单元结构

表1:数据特征维度表

表2:不同特征维度保留信息占比

表3:模型评估结果
(3)日志服务器数据库里获取的网络访问日志数据,采集到学生ID 的性别、访问网站类型、网站名和时间数据,不涉及具体内容且所有数据都严格把控不被泄露。
对标签数据处理时,将有外倾向型得分数据归类为标签“1”,有内倾向型得分的数据归类为标签“0”。
在实际的数据中,访问网站类型有多种,每个类型又有多种对应的具体网站和访问次数,导致原始数据维度爆炸,有几百维之多。所以将同一种类型的网站归为一类。最终提取的特征维度示意如表1 所示。
在特征维度构造中,特征维度选取越多信息量占比越高,信息冗余和运算量也随之增加。为在减少运算时间的同时保留更多的信息,实验使用PCA 对数据的特征维度进行空间映射,该方法降低各维度之间的相关性并去除信息含量低的维度。提炼步骤为:
(1)样本中心化:

(2)计算样本协方差矩阵XXT,其数值大小代表特征之间的相关性,为了让特征维度之间相互无关,对各特征相互正交(协方差为0);
(3)对协方差矩阵XXT做特征值分解,将求得的特征值排序λ1≥λ2≥…≥λd;
(4)取前d'个特征值(d'≤d)所对应的特征向量构成投影矩阵W*= (w1,w2,……,wd)
(5)保留前d'维所包含的数据信息占比η 为:

根据公式(2),取前k 个特征维度时,每一次降维后所保留的信息比例如表2 中所示。由表中数据可知,降维后仅保留前7 个维度,信息保留率就达到了99%,这也证明了PCA 确实能有效地减少信息冗余。
(6)使用L2范数正则化缓解过拟合,计算公式为:

x、y 为训练样本和标签,ω 为权重系数向量,正则化参数λ>0。
3.2 算法过程
该分类预测模型过程可以由以下几个步骤进行描述:
3.2.1 构建特征向量
(1)对原始数据关键词提取得到分类列表,列表中每个元素是一种访问所对应的类型、时间、次数。
(2)将ID 转化成索引,对应其年龄和列表内的数据,得到一个V=M*N 的二维矩阵,其中M 表示有效索引的数量,N 表示每一组数据的维度。
(3)矩阵V 进行L2 正则化,正则化后的矩阵定义为V'。对V'内数据进行10 交叉验证划分,划分后的数据为PCA 模型的输入。
3.2.2 将V'输入PCA 进行降维
(1)根据表2 的结果,将PCA 中保留的特征数的参数n_components 设为7。
(2)参 数explained_variance_ratio_:array [n_components]返回所保留的7 个成分各自的方差百分比,即单个变量方差贡献率。总占比为0.9976。
3.2.3 在训练步骤中采用如下改进策略
降维后的数据作为LSTM 的输入。为防止过拟合,在训练阶段设置dropout 概率p,随机丢弃一些神经元。使用reshape 函数处理输入数据维度。LSTM 层是循环层,需要3 维输入(batch_size, timesteps, input_dim),即(训练数据量,时间步长,特征量)。将向量输入至Softmax 全连接层归一化,变换成条件概率分布,获取该信息的最终分类。
3.3 实验设计
本实验对比4 个神经网络网络模型,这四个模型分别是GRU模型(GRU),逻辑回归LR 模型(LR),卷积神经网络模型(CNN)和LSTM 模型。
实验中的所有神经网络模型代码是基于jupyter 的Tensor Flow实现的,实验所用机器CPU 为Intel(R)Core(TM)i5-6500,主频3.2GHz,操作系统为Windows 7。
四种模型训练出的最优参数模型所获得的数据如表3 所示。可以看出,本文提出的方法在总精度(Accuracy)、精确度(Precision)、召回率(recall)、f1-score 等方面都有较好的效果,且AUC 达到了0.83。
4 实验分析与结论
从网络日志内容中预测性格倾向是一个具有挑战性的问题。在本研究中,我们对LSTM 模型步骤进行改进,来进行内倾向和外倾向的预测。从实验中,我们发现所提出的方法相对于原始方法产生了更好的结果(AUC = 0.83)。该实验也存在一定的缺陷,包括数据集的大小有限,以及使用单一的神经网络模型。在未来的工作中,我们将进行不同的改进,比如通过加数据集的规模,以及融合多个深度神经网络的方法。
