基于Flink的工业大数据实时分析平台
2021-06-16刘辉陈刚
刘辉 陈刚
(徐工集团工程机械股份有限公司科技分公司 江苏省徐州市 221000)
工业生产过程中会产生海量的数据,随着工业信息化的不断发展和应用,这些数据的格式、来源和内容逐渐多样化,数据决策的要求也日趋实时化、自动化,对数据存储、数据管理和实时计算等方面提出了新要求[1]。
传统的工业大数据分析系统一般采用基于Hadoop 技术体系的离线数据仓库架构[2],通过离线导入数据源,再根据具体的业务需求针对最近一段时间的历史数据进行统计分析。这种模式无法针对系统数据的实时性变化进行分析探查,为了实现对工业项目监控中实时指标的计算,可以在离线数据仓库架构的基础上增加实时计算,通过消息队列等形式进行数据流处理,即Lambda 架构[3]。Lambda架构满足了实时指标分析的需求,但需要同时开发离线计算、实时计算两套代码,不仅提高了开发难度,还带来了多套引擎的维护成本。
为解决这一问题,Kappa 架构[4]将离线批处理作为一种特殊的实时流处理,实现两套体系的融合。Flink[5]作为批流一体化计算引擎,能够很好地支撑Kappa 架构,目前已广泛应用于实时数据分析场景。为此,本文基于Flink 构建工业大数据实时分析平台,对工业生产过程中产生的海量数据进行实时采集、处理、分析与存储,面向不同格式的数据进行定制化存储,从而提供实时化、自动化的分析决策,支撑监测大屏、看板系统、报表系统、分析报警系统等多种场景的实时数据分析。
1 相关工作
1.1 Flink概述

图1:Flink 技术框架图
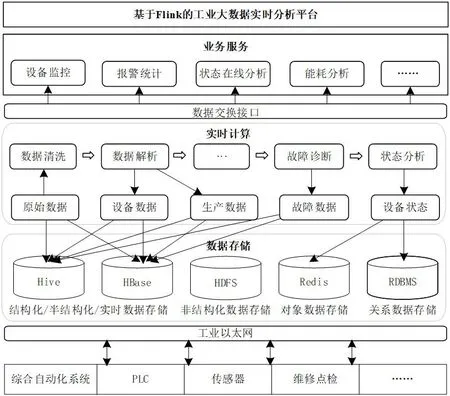
图2:系统总体架构图
Apache Flink[5]是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。如图1 所示为Flink 技术框架图,Flink 中有两个核心API:用于处理有界数据流的DataSet API(即批处理)和用于处理无界数据流的DataStream API(即实时流处理)。Flink 的核心是DistributedStreaming Dataflow 引擎,它用来执行Dataflow 程序,也是流式处理世界观的具体实现,DataSetAPI和DataStreamAPI 都可以通过该引擎创建运行时程序。在此基础上,Flink 还提供了用于机器学习的组件库FlinkML、用于图处理的组件Gelly 和用于结构化查询SQL (Structured Query Language, SQL)操作的Table API。Flink 会对Table API 逻辑在执行前进行优化,从而可以对SQL 或Table 查询进行效率上的优化。在运行部署方面,Flink不仅支持在本地的Java 虚拟机JVM (Java Virtual Machine, JVM)环境中直接运行,还可基于Cloud 端部署、以及基于Hadoop 的集群进行Standalone 模式或YARN (Yet Another Resource Negotiator, YARN)模式的部署。
1.2 实时数据仓库
数据仓库[6]是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。然而,随着数据时效性在企业运营中的重要性日益凸现,传统的离线数据仓库架构难以满足数据实时分析需求,同时Lambda 架构存在开发效率低、维护成本高等瓶颈,因此基于Flink 等引擎、Kappa 架构实现的实时数据仓库已成为数据仓库应用的新趋势[7-9]。

图3:实时数据仓库模型结构图

图4:实时分析平台看板系统
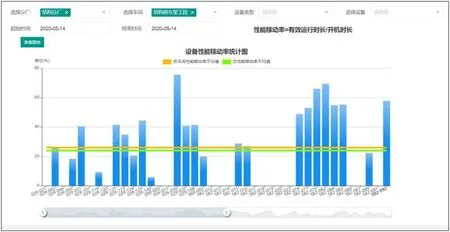
图5:实时分析平台报表系统
2 系统总体设计
基于分布式实时计算架构的生产设备数据分析平台总体架构共包括:数据采集层、数据存储层、资源管理层、数据计算层和应用层。
如图2 所示为平台系统架构图。
2.1 数据采集层
平台数据主要源于工业制造场景中应用的综合自动化系统、PLC、传感器、维修点检数据等。数据通过采集系统基于工业以太网进行传输。
2.2 数据存储层
平台利用分布式存储架构根据数据场景及应用需求进行个性化存储,通过Hive、HBase、HDFS、Redis、RDBMS 等存储模型,为结构化数据、半结构化数据、实时数据等不同类型的数据提供存储支持。
2.3 实时计算层
基于Kafka 消息队列及Flink 实时计算引擎,针对所采集的数据进行数据清洗、数据解析、分析计算,并将计算结果如设备数据、生产数据、故障数据、设备状态等信息写入相应的存储结构中。
2.4 业务服务层
操作人员可通过Web 界面进行交互,实现对设备实时监控、观察报警统计数据,同时支持状态在线分析、设备能耗分析等功能。
3 工业大数据实时分析系统
3.1 实时数据仓库模型设计
实时数据仓库采用批流一体的Flink 引擎作为实时计算框架,通过分层的方式建立数据模型,包括:贴源数据层(ODS, Operation Data Store)、明细数据层(DWD, Data Warehouse Details)及数据服务层(DWS, Data Warehouse Service),具体如图3 所示。
3.1.1 贴源数据层
利用Kafka 可以实现对实时数据的传输,达到高并发、低延迟和消峰的效果。因此,基于Kafka 构建分布式消息队列,对如:设备状态、操作日志等需要实时处理的原始数据进行采集,实现贴源数据层。
3.1.2 明细数据层
针对所采集的原始数据进行数据清洗、多表联接、维度信息关联等操作,将数据处理为实时明细数据。对于这部分数据,根据需求一部分将其写入到HBase 中便于实时查询,另一部分仍通过Kafka 消息队列传输到数据服务层进行后续处理。
3.1.3 数据服务层
根据数据分析场景将Kafka 消息队列接收到的数据进行轻度汇总和高度汇总两条分支处理,轻度汇总层面向OLAP 查询,便于进行指标聚合和报表分析;高度汇总层将数据写入HBase,能够向实时监测大屏等提供快速查询。
3.2 设备监测指标实时计算
以性能稼动率这一实时指标为例介绍实现过程:首先,原始数据通过采集设备、工业以太网传输到平台Kafka 消息队列;进而进入明细数据层,基于FlinkSQL 进行数据的解析、清洗、关联维表等操作;然后,分别计算该设备在一定时间内的有效运行时长和开机时长,相除得到性能稼动率并导入HBase,实时监测大屏系统及报表查询系统可以进行指标的查询并展示。
4 系统实现
4.1 环境搭建
平台首先基于Hadoop 体系、2 个主节点和4 个计算节点构建大数据集群,包括:HDFS、Yarn、HBase、Hive 等平台组件,此外还部署Zookeeper、Kafka、Flink 等计算组件。
分布式节点硬件配置选用4 核2.7GHzCPU、24GB 内存、1TB硬盘,选用CentOS764 位系统,同时部署组件版本为JDK1.8、Hadoop2.6.0 及Flink1.9.0。
4.2 功能演示
基于Flink 的工业大数据实时分析平台能够支撑看板系统、报表系统、分析报警系统等多种场景的实时数据分析需求,如图4 所示为系统看板中心。
如图5 所示为系统性能稼动率报表,可根据筛选条件进行快速查询并生成图表展示。
5 结论
本文针对工业大数据实时分析的需求,基于批流一体计算引擎Flink 设计工业大数据实时分析平台,对工业生产过程中产生的海量数据进行实时采集、处理、分析与存储,面向不同格式的数据进行定制化存储,从而提供实时化、自动化的分析决策,支撑监测大屏、看板系统、报表系统、分析报警系统等多种场景的实时数据分析。
