一种基于CTPN网络的文档图像标题检测算法
2021-06-16郝聚涛段静文陈超陈鸿龙
郝聚涛 段静文 陈超 陈鸿龙
(1.上海电机学院电子信息学院 上海市 201306 2.上海思贤信息技术有限公司 上海市 200233)
随着互联网技术的发展创新,办公也逐渐进入了信息化时代,纸质文档数字化由于其便于存储和传输已被广泛应用。但是,大中型的企业由于文档数量庞大,陷于难以梳理的困境。对大量以图像或者pdf 格式存储的文档,进行管理需要能够智能化进行文档的组织和归流,方便用户按照类型进行查找,有效提高工作效率。
文档图像的版面分析是文档信息处理系统的重要组成部分,以及复杂文档OCR(Optical Character Recognition)必不可少的环节,它是实现纸质文档数字化的重要环节。文档版面分析是一个将文档图像分解成不同区域块并且进行文本、图像、表格和数学公式等分类的过程。版面分析在信息检索、机器翻译、光学字符识别以及从文档中提取结构化数据都有着广泛应用。
版面分析包含三个主要步骤:
(1)检测感兴趣的文档块;
(2)提取特征;
(3)对文档块进行分类。
传统的自顶向下、自底向上和混合的块检测方法被用于文档块的分割。然后,使用基于块、基于像素或基于连接组件的技术从块中提取特征。最后引入机器学习算法来分类文档块。
近年来,深度学习在文档布局分类中得到了广泛的研究。Kang将CNN 引入到使用自定义网络进行文档分类的任务中与传统的基于特征的方法相比,显著降低了错误率。
本文中的标题检测就是对文档进行逻辑版面分析的一种特定应用,首先将文档图像分割几何区域,进行文本行识别。然后对文本行进行语义类别划分,划分为标题和非标题。对标题文本区域进行OCR 识别,为后续进行文档自动分类和检索提供支持。
1 标题识别模型
1.1 模型整体结构
本文提出的文本图像标题检测模型主要由三个部分组成,第一部分为文本检测模块(Connectionist Text Proposal Network,CTPN),即对输入的文本图像(Text images)进行文本块的检测,获取图像中文本的位置信息;第二个部分是特征设计(Feature design),对得到的文本块位置信息进行特征设计,转化为分类器所需要的特征向量;第三个部分是分类器,对文本图像中的每个文本块进行分类,判断该本块是否属于标题,最后得到输入文本图像的标题概率分布。
1.2 文本行检测
CTPN(Connectionist Text Proposal Network)认为预测文本的纵向位置(边框的上下边界)比横向位置(边框的左右边界)更容易,因此CPTN 的基本想法就是去预测文本的纵向位置,水平方向的位置不做预测。由此提出了一个纵向锚点(vertical anchor)的方法,该方法与Faster RCNN 中的锚点类似,但不同的是,纵向锚点的宽度都是固定的16 个像素大小。而高度则从11 像素到273 像素变化,总共10个锚点。 同时,同一文本线上不同字符可以互相利用上下文,将长短期记忆网络(Long Short-Term Memory LSTM)引入到了网络里面,并且和卷积神经网络无缝对接,发挥LSTM 的记忆作用,根据前后的锚点序列来提取这种相互之间的关系特征,输出给全连接层,给每个锚点打分,最后用文本行构造法,将锚点连接起来,得到文本行。这两大亮点使得CTPN 在文本行检测的精确度方面有了很大的提升。
1.3 特征构建以及符号说明
标题与正文在排版以及字体大小等方面往往存在差别,可以利用这种差异性构建标题识别模型特征向量。只考虑图像的文本信息,任何一张文本图像都是由若干个文本块组成,假设该文本图像共有n 个文本块,以第i 个文本块text_block_i 为例阐述标题识别模型特征向量的构建。该文本块上边界离文本图像上边界的距离为vti,离文本图像下边界的距离为vbi;文本块左边界离文本图像左边界的距离为hli;文本块右边界离文本图像右边界的距离为hri;文本块的高度为fi;第i 文本块之上和之下分别存在的文本块数量为m 和k,且m+k+1=n;该文本块的特征向量为:
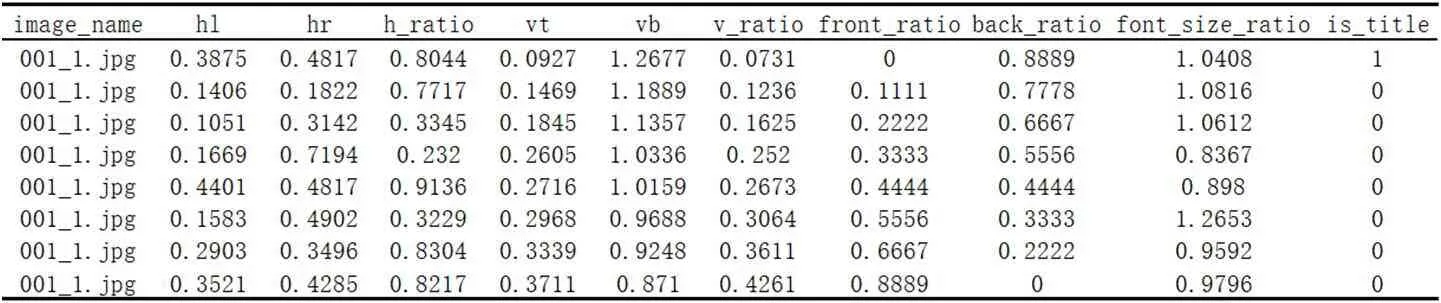
表1:文本图像001_1.jpg 生成的训练集

其中hl=hli,hr=hri,h_ratio=hli/hri,vt=vti,vb=vbi,v_ratio=vti/vbi,front_ratio=m/n,back_ratio=k/n,
2 实验评估
2.1 数据集描述
以文本图像001_1.jpg 为例(见表1),该图像存在8 个文本块,可以生成8 个训练样本,其中 用于说明该文本块是否属于标题,如果是标题则为1,反之为0,每张图片生成的训练样本数目取决于该图片文本块数量。这里选取了300 张文本图像,生成9647 个样本,其中正负样本比例为1:13。考虑到实际情况下,同样式下不同图像的文本块的相对位置会存在一定程度的左右偏移或者上下偏移;利用该特性,通过对每个特征变量引入偏移量 ,其中 ,生成伪样本,使得正负样本比例为1:1,得到最终样本数目为18617,训练集和测试集比例为7:3。
2.2 模型比较和实施
将样本数据输入给模型进行训练前,需要将其进行归一化或者标准化预处理,从而消除各特征量纲的影响。本文对训练数据特征预处理采用python 的sklearn 模块的StandardScaler 方法。选取sklearn 自带的7 种主流分类算法,即随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistics Regression,LR)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、轻量梯度提升机(Light Gradient Boosting Machine,LGBM)、自适应提升(Adaptive boosting,AdaBoost)、 极 端 梯 度 提 升(Extreme Gradient Boosting,XGBoost),分别作为本文的标题二分类分类模型,分类器参数均采用sklearn 默认值。
如表2 所示,各分类器均具有较优性能,其原因是本文涉及到的文本标题特征较为鲜明,即标题所处位置、大小和非标题文本存在交大差异,使得整个检测场景变的简单,而事实上这是一个在文档中普遍存在的合理的现象。本文最终选取RF 作为文本图像的标题检测分类器。

表2:分类器性能
2.3 特征重要性分析
对数据进行StandardScaler 预处理,采用RF 分类器进行训练,同时对样本的各个特征进行重要性排序,可知文本块所在的上下位置信息对该文本块为标题的贡献较大,特别的,该文本块上方存在的文本块数量与总文本块数量比率贡献最大,这个也是合理的,常见文档中,标题一般出现在第一行或者前几行。
2.4 效果展示与坏例分析
为了更好说明本文所提出的文本图像标题检测方法的有效性,从网络上随机下载了1000 份文本图像,标题检测准确率~96%,验证该算法具有强鲁棒性。同时,本方法也存在一定局限性,例如对竖直、干扰严重的标题检测失效。
3 总结
本文提出一种基于CTPN 的文本图像标题检算方法,首先检测文本图像中文本块,将每个文本块位置信息转化为标题检测模型所需的特征向量,并形成训练样本集,利用RF 分类器学习样本分布,再利用训练好的RF 分类器参数对未知文本图像的标题进行检测。传统基于规则的文本图像标题检测算法存在因为规则覆盖率有限导致算法泛化能 力差的问题。本文所提出的方法,结合了神经网络和随机森林分类器,算法泛化能力强,同时在给定样本分布下,训练得到分类器的精准率、召回率、F 值、准确率均接近于1,说明本文提出的标题检测算法具有较优的性能,可用于一般场景下文本图像标题检测。虽然该方法能较好的自动检测文本图像的标题,但是当文本标题周围存在较强或者手写字与打印字体识别置信度差异,构建新特征,进一步提高标题检测算法的鲁棒性和性能,这都是值得进一步开展研究的。干扰,例如手写字或者文本标题以垂直样式出现,该方法准确率下降,因此后续可以考虑引入字符串语义信息。
