云原生网络的宏观与微观技术分析
2021-06-16汤闻达
汤闻达
(中汇信息技术(上海)有限公司 上海市 201210)
1 背景
伴随着容器技术的成熟与微服务理念的普及,业务弹性和敏捷交付的诉求催生了一系列云原生技术。云原生计算基金会(Cloud Native Computing Foundation, CNCF)对云原生做出了如下的定义:云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。结合标准化自动化运维,云原生技术可帮助企业很方便地对容器化应用做出频繁且可预测的变更。
事实上,数据中心资源无外乎计算、存储和网络。云原生与传统架构在承载业务应用的区别主要是在计算、存储和网络资源管理和编排调度方式上的差异,而针对这些差异的理解与消化直接影响了企业上云业务应用的运行质量以及业务变更的灵活性。除此以外,对于那些采用本地部署(on-premises)云平台的用户,还涉及到数据中心基础设施的建设与维护成本。
1.1 数据中心传统网络架构与云原生的碰撞
宏观上看,网络资源作为数据传输的高速公路和纽带,可以数据中心网络的构建也无外乎由路由交换设备、服务器设备等实体硬件构成,各类资源的可达性和能力优势完全依赖于数据中心的网络拓扑结构。
传统数据中心主要承载的是南北向的网络流量(即数据中心外到数据中心内的流量,可以是外部流量到内部服务器,也可以是内部服务器到外部的流量)。相应的网络架构通常是三层结构。思科(Cisco)称之为:分级的互连网络模型(Hierarchical Internetworking Model)。这个模型主要包含了以下三层:接入层(Access Layer)、汇聚层(Aggregation Layer)和核心层(Core Layer)[1]。接入层交换机通常位于数据中心机房内的机架顶部,所以它们也被常常称为ToR(Top of Rack)交换机,由于它们直接连接着实际的物理服务器,可以提供网络接入的能力,所以叫做接入层交换机。汇聚交换机下连接入层交换机,用于提供防火墙策略执行等能力。核心交换机一方面为流入整个数据中心的数据包提供高速转发能力,另一方面下连多个汇聚层交换机并提供它们之间的连通性。
典型的数据中心三层网络架构如图1 所示。
按OSI(Open System Interconnection)七层参考模型,通常情况下的汇聚交换机是数据链路层和网络层的分界点,汇聚交换机以下的是数据链路层,以上是网络层。汇聚交换机和接入交换机之间通常为了防止数据链路层环路或广播风暴破坏网络等问题,运行着生成树协议(Spanning Tree Protocol,STP)。STP 使得对于一个VLAN 网络只有一个汇聚层交换机可用,其他的汇聚层交换机仅在出现故障时才被使用(上图中红色虚线表示备份线路),也就是说汇聚层是一个“主备”的高可用模式[2],其余网络设备的能力没有被充分利用。通过应用TRILL(Transparent Interconnection of Lots of Links,多链路透明互联)技术,在数据链路层引入IS-IS(Intermediate System-to-Intermediate System,中间系统到中间系统)这样的可运行于链路层的路由协议,可将数据链路层的简单灵活和网络层的稳定可靠相结合,实现针对已知单播数据包转发的等价多路径负载分担,从而规避应用STP 所产生的带宽利用率低等问题[3]。
目前已有大量数据中心中在使用这种三层网络架构,这样的架构可以很方便地支持数据中心南北向流量。但是近年来伴随着互联网业务的迅猛增长和日趋完善的应用微服务改造,数据中心虚拟化要求着更高的东西向流量(数据中心内的服务器之间的流量),甚至跨数据中心流量。据一份来自思科的网络分析报告描述,预计到2021年末,东西向流量将占数据中心总流量72%,远超南北向流量(15%),数据中心间流量(14%)[4]。
需要指出的是,尽管上述传统三层网络架构也能够支持东西向流量,但是效率并不高(即便采用TRILL 技术),这主要体现在一旦发生网络层的东西向流量传输需求,都必须经过核心交换机完成转发,这不仅浪费了宝贵的核心交换机资源,多层转发也增加了传输延时。
1.2 云原生数据中心网络架构特征
云原生对于数据中心网络的需求,可以分别从基础设施平台以及业务需求两方面来进行分析。从基础设施平台方面来看,整个平台正在向分布式弹性化的方向发展,其在承载上层应用有关性能、可扩展性与可靠性方面都有对应的保障要求,并且各个微服务间的通信流量均衡与故障应对(如服务降级、熔断、限流)等均需交由平台进行处理。从业务需求方面来看,传统单体应用正在向微服务架构进行演进,以充分利用平台的弹性可扩展能力,这种将计算与存储分离的方式对网络资源的调配要求更高。

图1:典型数据中心三层网络架构

图2:Spine-Leaf 网络拓扑
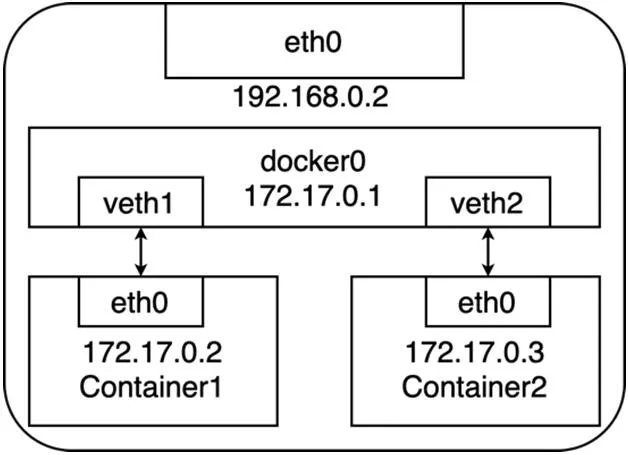
图3:宿主机docker0 网桥网络拓扑示意
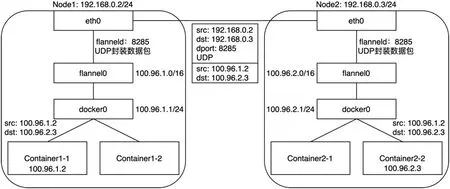
图4:两个宿主机上容器基于Flannel UDP 模式的通信过程
从业界实践上来看,一种基于Clos 网络模型的扁平化网络架构Spine-Leaf 可以为数据中心提供高带宽、低延迟、非阻塞的端到端连接。并且,它能够在性能、高可用等方面为上述需求的满足提供一定的支撑作用。图2 是一个典型的两级Spine-Leaf 网络拓扑。
在以上的两级Clos[5]拓扑中,每个低层级的交换机(Leaf)都会连接到每个高层级的交换机(Spine)。与三层网络架构类似,这里Leaf 层由接入交换机组成,用于连接服务器等设备。Spine 层负责将所有的Leaf 连接起来,这里每个Leaf 都会连接到每个Spine。任意一个Spine 发生故障,都不会影响到整个网络的正常运转,且吞吐性能只会有轻微的下降。与三层网络架构不同的是,Leaf 交换机与Spine 交换机间的网络流量都是网络层以上的流量,因此可充分利用到网络层等价多路径路由特性,实现网络链路的负载均衡。同时,在任意Leaf-Spine 链路发生故障时,实现快速切换。在上述基础上,网络扩容与接入资源的扩容只需对应增加一个Spine 交换机和Leaf 交换机即可,这样可很方便解决链路拥塞问题,且实现了无阻塞的网络架构。
在Spine-Leaf 架构中,任意一个服务器到另一个服务器的连接,都会经过相同数量的设备(除非这两个服务器在同一Leaf 下面)。因为一个数据包只需要经过一个Spine 和另一个Leaf 就可以到达目的地,这就使得整个网络中任意的端到端连接延迟是可预测的。因此,当数据中心的物理设备间通过Spine-Leaf 网络架构互联后,即可较为高效地处理数据中心的东西向网络流量,并同时保证低的、可预测的网络间延迟,从而为部署于物理机器上的各个应用容器提供灵活、高性能的通信。
2 云原生容器网络的需求与实现
云原生架构以容器和Kubernetes 为核心调度组件构建了一整套微服务生态系统。爱因斯坦曾经说过:“如果没有界定范畴和一般概念,思考就像在真空中呼吸,是不可能的。”容器技术的大规模灵活运用同样离不开底层宿主机间网络性能的支撑。云原生容器网络立足于前文描述的数据中心网络架构,聚焦于微观的技术实现,目的是为泛在的容器提供坚实的网络通信基础。
2.1 容器网络的需求
尽管运行于宿主机上的容器可以直接使用宿主机网络栈,从而为容器提供良好的网络性能,但这样做会不可避免地引入共享网络资源的问题,比如端口冲突等。和虚拟机的使用类似,大多数情况下都希望容器能拥有独占的网络资源。但在拥有独占网络资源后,依然面临两个问题:一是各个容器间如何进行有效通信?二是容器和其他非容器应用(宿主机、非宿主机等)如何通信?
Pod 是Kubernetes 的原子,是构建应用程序的最小可部署对象。单个Pod 代表集群中正在运行的工作负载,其一般封装一个或多个容器(比如基于Docker 运行时的容器)。
Kubernetes 使用了一种“IP-per-Pod”网络模型:它为每一个Pod 分配了一个IP 地址,Pod 内部的容器共享同一个网络空间(相同的网络设备和IP),且一个Pod 的IP 地址并不会随着Pod 中的一个容器的起停而改变。
Kubernetes 中的网络要解决的核心问题就是为每台容器宿主机的进行IP 地址网段的划分,以及容器IP 地址的分配。主要概括为:
(1)每个Pod 拥有集群内唯一的IP 地址
(2)不同宿主机节点的容器IP 地址划分不会重复
(3)宿主机节点的不同Pod 可以互相通信
(4)不同宿主机节点的Pod 可以与跨节点的主机互相通信
Kubernetes 提出了针对Pod 的网络模型,但是并没有提供具体实现细节。因此,任何满足Kubernetes 网络模型接口的都可视作一种有效的容器网络技术实现。容器网络插件则是针对Pod 的网络模型,通过不同的方法,实现不同宿主机上的容器通信目标。
2.2 主流网络插件解决方案
2.2.1 虚拟化协议栈
虚拟化协议栈主要目的在于从一台物理主机中分离出多个TCP/IP 协议栈进行资源隔离使用。Network Namespace 是实现网络虚拟化的重要功能,网络空间有独自的网络栈信息,路由表,防火墙策略等。采用Network Namespace 网络虚拟化技术后,容器进程就能使用自己 Network Namespace 里的协议栈,即:拥有属于自己的 IP 地址和端口。
2.2.2 虚拟化网桥
在采用NetworkNamespace+Veth 技术后,容器即拥有了自身独立的IP 地址和端口。但当宿主机启动多个容器时,一个显而易见的问题就是:各个被Network Namespace 隔离的容器进程如何进行端到端交互?如若让众多容器采用基于Veth 技术的“网线”的Container-to-Container Mesh 全互联实现,这显然是较为“臃肿”的。
可以把每一个容器看做一台主机,那么它们的联通需求即是实现多台主机之间的通信,通过网桥即可实现这样的虚拟交换功能。具体来说,通过将网桥的每个端口都用Veth 连接对应的容器NetworkNamespace,然后根据 MAC 地址学习来将数据包转发到网桥的不同端口上,从而可实现一个宿主机内部的不同容器通信需求。
以Docker 为例,它会在宿主机上创建一个名为 docker0 的网桥,然后所有的容器都借助于这个网桥进行通信[6]。图3 展示了在一台宿主机上基于docker0 网桥的容器网络拓扑。
2.2.3 虚拟化路由
事实上,Docker 通过Veth 虚拟网络设备以及Linux bridge 实现了同一台主机上的容器网络通信,在容器向外部网络通信的部分可通过宿主机的Netfilter/iptables 进行NAT 实现,但跨主机间的容器互访依然存在阻碍。跨主机容器通信所需要解决的问题即不同宿主机上网桥间的联通性问题,目前主要有如下两个方向对上述问题进行解决。
方向一:在底层网络设备中默认加入容器IP 地址的管理,需要感知容器实体的存在,一般依靠结合SDN 设备进行实现。
方向二:不修改底层网络设备配置,而是复用既有的Underlay平面网络,以Overlay 或通过自动化生成主机路由的方式解决容器跨主机通信,主要表现形式如下:
2.3 两组患者心理状态对比 干预前,两组患者SAS、SDS评分比较,差异无统计学意义(P>0.05)。干预后,观察组患者评分低于对照组,(P<0.05)。见表3。
(1)Overlay,通过隧道机制把容器发出的数据包封装在通过宿主机网络的数据包中,并复用既有的Underlay 网络传输到目标主机,目标主机再拆包转发给对应的容器中。Overlay 隧道如VXLAN、IPIP 等,目前使用Overlay 技术的主流容器网络有Flannel、Weave 等。
(2)Routing,通过动态修改宿主机的路由表信息,把宿主机当作容器的网关,调整路由规则转发到指定的主机,达到容器间的网络层互通。目前通过路由技术实现容器跨主机通信的网络有Flannel host-gw、Calico BGP 等。
本文接下来以同时兼顾Overlay 与Routing 的Flannel 解决方案描述容器的跨主机通信机制。
Flannel 的设计分为两个方面,一个是容器IP 的分配机制,另一个是容器间的通讯机制。Flannel 提供了一种全局的网络地址分配机制,并使用外置的etcd 数据库来存储网段和节点之间的映射关系,Flannel 通过配置各个节点上的容器只能在分配到当前节点的网段里选择IP 地址,从而实现IP 地址分配的全局唯一性。
在容器间通讯的具体实现上,Flannel 利用各种backend 例如UDP,VXLAN,host-gw 等等,通过不同手段实现跨主机转发容器间的网络流量,完成容器间的跨主机路由通信。
Flannel 的UDP backend 方案里会在每台宿主机上生成flannel0设备,它是一个TUN 设备。TUN 设备可以在操作系统内核态和用户态应用程序之间数据。当内核将一个数据包发送给flannel0 设备之后,flannel0 就会把这个数据包交给创建这个设备的应用程序进行处理,这里就是flannel 的守护进程——flanneld。而如果 flanneld 进程向 flannel0 设备发送了一个数据包,那么这个数据包就会根据宿主机的路由表进行处理。
图4 展示了两个宿主机上容器的通信过程。
所以,事实上Flannel UDP 模式即是在不同宿主机上的两个容器之间打通了一条Overlay“隧道”,它使得任意两个容器可直接透明地进行IP 通信,且无需考虑容器和宿主机在网络中的位置。考虑到该模式采用了flannel0 这个TUN 设备,它在数据包传输过程中频繁存在用户态与内核态的数据拷贝,性能较差,因此基于VXLAN(Virtual Extensible LAN)的模式应运而生,它可以完全在内核态实现上述封装和解封装的工作。
Routing 的形式主要体现在flannel 的host-gw 模式。在实际运作中,host-gw 工作模式就是将每个宿主机承载的flannel 子网的“下一跳”设置成了该子网对应的宿主机的 IP 地址。具体来说,hostgw 模式通过在宿主机上添加一个路由规则:<目的容器IP 地址段> via <网关的IP 地址> dev eth0。而这个路由规则的更新则是通过在各个宿主机上部署代理进程动态地将容器网络的变化信息“翻译”为到主机的路由表信息,从而实现在所有的宿主机上都拥有整个容器网络的路由信息。
由于host-gw 模式完全是依靠宿主机的路由机制,因此它的效率与虚拟机直接的通信相差无几。但这种网络方案得以正常工作的核心,是为每个容器的IP 地址,找到它所对应的,“下一跳”的网关。所以说,Flannel host-gw 模式必须要求集群宿主机之间在数据链路层之间是连通的,这也限制了集群的规模。不仅如此,大规模的路由表查询也会进一步影响容器网络的性能。因此,host-gw 模式在宿主机本身存在跨网段情况下的实现有一定的局限性。
为了同时兼顾性能和支持宿主机跨网段,可为flannel 的VXLAN 指定DirectRouting 参数,当两个容器所在宿主机节点在同一个网段中时,可直接通过物理网卡的网关路由转发,而不用额外对数据包进行隧道封装。当且仅当所在宿主机跨网段时,才使用VXLAN 模式。
3 总结与展望
数据中心网络在云计算基础设施中具有关键地位,其性能的高低一定程度上影响着企业云计算的服务质量。以容器、微服务、Kubernetes为主要核心的云原生架构,是当下设计具有弹性、可扩展、高可用业务系统架构的主要聚焦点。由于该架构中的实施往往伴随着数据中心东西向网络带宽的高要求,因此,其涉及的有关网络拓扑、资源规划和分配方式等需要配合以云原生的方式演进与适应,从而为“应用系统上云”的工作打下坚实基础。
