视频内容特征与弹幕文本相结合的短视频推荐模型
2021-06-15邹宝旭徐红艳
冯 勇,邹宝旭,徐红艳
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引言
短视频成为日活跃用户规模增速最快的移动互联网细分领域之一,日活跃用户规模接近在线视频用户规模的2倍[1].用户上传的各类短视频数量增长势头持续上涨,例如国外的YouTube,国内的腾讯视频、爱奇艺以及抖音等各类在线视频平台通过积分、排名、推荐等服务激发用户贡献意愿和提升用户体验.
个性化推荐一直是处理海量信息的一种有效途径,在视频服务领域众多平台运用推荐系统向用户提供优质的视频以增加客户粘性和提升用户满足度[2-4].随着人工智能的不断发展,基于深度学习的推荐系统能够更好地分析用户的行为习惯和即时兴趣,进而为用户提供更具个性化的推荐列表.这方面具有代表性的研究成果有:文献[5]针对视频当中的物体检测问题,提出了一种基于深度学习的视频物体检测与内容推荐系统方案,通过视频中的物体检测和识别,将视频内容与相关的产品内容进行匹配.文献[6]对于视频在推荐过程当中多样性差的问题提出了一种所属性联合算法,该算法通过用户的历史记录以及系统内容的各项基本属性进行结合,以此来达到个性化推荐的目的.文献[7]提出了一种基于深度学习模型的内容推荐策略,引入深度神经网络词向量方法,根据视频自身的相关信息,以及用户的历史观看记录,以此作为基础对于用户进行相似用户的删选,进而产生推荐.文献[8]根据视频内容的隐含评论分析,提出了一种视频推荐算法,其目的主要是为了解决网络视频当中某些多媒体信息难以提取的问题.文献[9]提出了一种端到端的短视频处理框架,通过该框架能够将不同元素之间的内容进行特征提取,通过端与端之间的联系,以此来实现语义表征.
以上研究成果虽使视频推荐性能得到一定的提升,但由于没有考虑短视频中弹幕文本蕴含的丰富语义信息,导致推荐的准确度不高且效率低下.为此,本文引入弹幕文本分析,提出了一种视频内容特征与弹幕文本相结合的短视频推荐模型(A short video recommendation model combined video content characteristics with bullet screen text,CVBT).首先对弹幕文本进行分析,确定弹幕文本的主题;之后通过深度学习方法对短视频进行处理,利用视频的高光时刻,提取相应的视频内容特征;最后基于用户的最近兴趣,确定其所属主题,经相似度计算得到推荐列表.经对比实验验证,本文所提模型与LDA、RFM、VRFCL等短视频推荐模型相比,在准确率以及召回率上均有明显提升,并且具有良好的效率优势[2].
1 相关工作
1.1 短文本分析技术
随着社交网络的不断发展以及互联网技术的逐渐完善,传统的文本表述方式已经难以满足人们生产以及生活的需求,因此短文本应运而生.在最近几年的研究当中,国内外相关学者对于短文本的研究浪潮一直处于上升阶段.国外的一些研究人员很早就开始对于Twitter和Facebook进行了分析探讨.Song等[10]明确指出,进行Twitter内容分类的过程当中,是一件非常复杂且难度很高的工作.主要是因为用户在发送Twitter的时候,所使用的词语十分简单,同时在用词方面也十分随意.文献[11]提出了一种微博新词识别方法,微博中存在很多网络用语,这些网络用语并没有在词典当中进行体现,因此提出了一种关于微博中网络用语的识别方法.Wang等[12]根据图结构的特殊性,提出了一种基于标签的分类方法,根据用户发送Twitter时的文本内容主题不同,以此来进行标签划分,通过图结构对于各类标签构建联系,然后对Twitter文本的主题情感进行分类.文献[13]根据短文本的特点,利用深度学习技术理论,在短文本计算涉及的文本语义表示、中文分词以及文本相似度计算等环节进行了分析和研究,最终形成一个完整的短文本计算框架.
就其根本而言,所有的弹幕文本都是按照时间序列进行排序而得到的短文本,弹幕系统最近几年才开始被国内一些视频网站所采用.目前,随着我国直播行业以及短视频平台的流行,对于弹幕数据的研究也越来越多.詹雪美[14]深入分析弹幕视频的特点,讨论了弹幕视频网站的产生、发展与意义.文献[15]提出一种基于深度学习的弹幕视频片段情感分析模型,结合视频重要性评分与LSTM网络模型能够有效识别短视频当中的情感主题.
1.2 深度学习技术
深度学习是机器学习研究中的一个重要分支,随着深度学习技术的不断发展,其目的在于能够建立一个模仿大脑的神经网络系统,并且根据大脑的运行机制,对于输入其中的各项数据进行分析与解释,例如图像、声音以及文本等.
随着对深度学习方法研究的不断深入,越多越多的学者将其应用于视频以及图像的内容特征分析中.文献[16]提出了一种基于深度学习的视频关键帧提取与视频检索研究.文献[17]提出了一种基于深度学习的监控视频中的车辆实时检测,通过视频检测中的车辆特征检测,能够有效提高车辆的检测准确性.文献[18]提出的方法使用CNN提取图片特征,利用多尺度滑动窗口算法进行检测,取得了很好的效果.文献[19]提出了用深度卷积神经网络来学习人脸的识别性和压缩性二值表示,用于人脸视频检索.文献[20]提出了一种基于深度学习技术的视频表示方法,通过内容特征进行视频的分类与聚类.
2 视频内容特征与弹幕文本相结合的短视频推荐
针对目前的短视频推荐准确度不高,较少利用弹幕信息等问题,本文引入短视频中弹幕文本进行分析,提出了一种视频内容特征与弹幕文本相结合的短视频推荐模型.
对短视频进行分析,分析对象可以分为两个部分:一部分是短视频本身的内容,另一部分则是短视频中的弹幕文本.弹幕技术的出现使用户能够即时地针对观看的视频内容发表文本评论,与视频浏览后的评论相比,弹幕文本能够更为即时、准确地反映出用户在观看短视频时的体验与感受,用户通过发送弹幕以此来表达自身的情感以及对于视频内容的评价.本文以短视频推荐为研究背景,根据短视频中大量的弹幕文本,确定该短视频的弹幕文本主题;再通过深度学习方法分析短视频中的高光时刻,确定短视频的内容特征与主题间的关联;最后根据用户近期看过的视频,形成相应的推荐列表.下面给出视频内容特征与弹幕文本相结合的短视频推荐模型框架如图1所示,并对弹幕文本分析、短视频内容特征分析、生成推荐列表进行详细介绍.

图1 视频内容特征与弹幕文本相结合的短视频推荐模型(CVBT)框架图
2.1 弹幕文本分析
2.1.1 弹幕处理
对于弹幕信息来说,人们通过发送弹幕能够有一种“实时互动”的感觉,弹幕信息是用户的切实体验或是情感表达.在同一时刻的短视频内容当中,发送的弹幕其主题具有一定的关联性,因此本文选择弹幕相对丰富的位置进行弹幕文本采集.
对于一个短视频来说,每一秒甚至是每一帧都有可能出现弹幕.在弹幕选取时,弹幕时刻的短视频内容与其是一一对应的,本文将短视频当中弹幕最为密集的时刻定义为该短视频的高光时刻.
2.1.2 文本分析
目前,在短视频推荐领域很少有人将弹幕文本作为推荐依据.而实际上,随着短视频的火爆以及弹幕系统的广泛应用,用户通过弹幕发表自己对短视频的评论与见解,弹幕文本越来越能够反映出用户的喜好.弹幕文本在用户进行视频选择的过程中,可以将其作为重要的参考内容,以此来满足不同用户对于各类视频以及视频内容的检索需求.
本文采用LDA[21]模型进行弹幕文本分析.如公式(1)所示,d为弹幕文本,z为弹幕文本中的某个主题,则条件概率P(zi|d)表示在弹幕文本当中某个主题的概率,w为文本主题中的某个单词,因此P(w|zi)表示在某个弹幕主题当中单词的分布概率.则对于一个单词w在整个弹幕文本d中的分布概率为:
(1)
其中,z表示隐含主题的个数,该数值大小需要提前进行确定,不同的z值将会对于文本建模结果产生影响.
本文通过Gibbs抽样进行LDA模型的构建,利用公式(2)计算每个单词在弹幕文本当中的概率大小,并且通过其概率来确定弹幕文本主题.对于弹幕文本di中的每个单词wi循环抽样,估算由wi生成一个新的主题zi=n的概率P(zi=n|wi,di,z-i)如公式(2)
(2)

通过Gibbs重复抽样,当抽样次数足够多且满足要求的时候,弹幕文本中隐含的主题概率将会趋于稳定,并且服从狄利克雷分布函数,而此时对于公式当中的平滑参数α、β,其达到其收敛值.对于其中的先验概率可以通过式(3)和式(4)得到.
(3)
(4)
通过LDA模型,得到弹幕文本中的主题分布,进而确定该短视频的主题,将短视频按主题进行划分,同一个主题下有若干短视频.
2.2 短视频内容特征分析
2.2.1 视频片段处理
与传统的视频相比,短视频不仅具有轻量化的特点,同时其包括的内容量大,信息全面,表达方式跟为直观、具体.用户能够在短时间内找到自己感兴趣的视频内容.用户在观看短视频的同时,可以发送弹幕,弹幕最为密集的时刻,本文将其定义为高光时刻,同时将高光时刻作为生成网络的输入,高光时刻是整个短视频内容中的核心部分,也是用户更为感兴趣的环节.
高光时刻为短视频当中弹幕最为密集的时刻,高光时刻的选取跟弹幕的数量密切相关.与此同时,本文通过对大量短视频研究发现,短视频中弹幕的生存时间为t0=5 s,即一条弹幕出现到消失持续时间为5 s,因此本文根据短视频弹幕的生存时间t0=5 s,按照5 s时间间隔进行弹幕收集,将其中弹幕数量最多的部分,作为该短视频的高光时刻.
2.2.2 内容特征提取
经2.1节对所选弹幕文本进行LDA主题模型分类之后,各短视频能够根据其弹幕文本的主题进行划分.与此同时,根据弹幕文本的选择,能够确定各短视频中的高光时刻.在同一主题下,将所属短视频中的高光时刻作为生成网络的输入,提取短视频内容特征.
深度学习模型能够准确识别视频、图像以及文字等内容,本文采用深度学习方法中的卷积神经网络对短视频中的“高光时刻”进行处理,如图2所示,本文采用两次卷积+池化的方式,以此来保证提取特征的稳定性.

图2 主题模型生成网络
本文将短视频中的高光时刻作为生成网络的输入,在卷积层当中设置其卷积核大小为5×5的,输入的通道数是1,输出的通道数是32,经过卷积层之后得到6个C1特征图,并且将其作为第一次池化的输入,设置池化的步长为2,经过池化之后,S2中每个特征图的大小是C1中特征图大小的1/4,通过sigmoid激活函数,得到短视频高光时刻中的内容特征.
在第二次卷积+池化的过程当中,其卷积核大小与第一次相同,但是其输入的通道数增加为32,输出的通道数64,S4中每个特征图的大小是C3中特征图大小的1/4,在全连接层当中,加上一个偏置,结果通过sigmoid函数输出.生成网络根据短视频中视频内容特征进行模型训练,最终实现短视频的主题分类.
2.3 生成推荐列表
根据用户的历史观看记录,能够得到用户最近所观看过的短视频,通过短视频中高光时刻的内容特征,确定该短视频的主题.这里借助one-hot[22]编码的思想,使用N位状态寄存器表示N位信息,每一位信息表示一种主题类别.在同一主题下,通过公式(5)进行相似度计算,最终按照相似度大小排序,选择排序靠前的短视频形成推荐列表.
(5)
D1表示用户近期观看短视频中的高光时刻,D2表示同一主题下其他视频的高光时刻,通过one-hot编码对短视频的高光时刻进行向量计算,即lk表示短视频中的向量.分子表示两个视频向量的点乘积,分母表示两个视频向量的模的乘积,进行其相似度计算.
3 实验分析
3.1 实验环境与数据
本文构建的推荐模型开发工具为pycharm,运行环境为Windows10-64位系统,计算机采用2.30 GHz,Intel(R)Core(TM)i5-4200U和8 GB内存.
本文中所用数据来源于哔哩哔哩网站、腾讯视频以及优酷新媒体短视频,样本数据的统计信息包括:视频总量为8 000个,视频类别包含10个大类,34个小类,所有的数据处理都是通过Python进行实现的.
3.2 评价指标
本文设置了三组对比试验以此来验证模型的准确性和效率.本文还设置了通过用户的行为分析进行视频推荐RFM[23]、融合评论分析的视频推荐模型VRFCL[24]以及基于内容的协同过滤模型MTER[25]作为本实验的对比实验.本实验采用准确率、召回率和F值三个指标来衡量各模型的有效性,评价指标的计算公式如式(6)-(8)表示.其中TP表示的是方法推荐的并且用户真实喜欢的视频数,FP表示方法推荐的但不是用户喜欢的视频数,FN表示方法没有推荐但是用户实际喜欢的视频数,而TN则是方法既没有推荐而且用户也不喜欢的视频数.
(6)

(7)

(8)
与此同时,为了保证弹幕文本能够突出其主题,根据弹幕文本当中的主题数量Z进行实验,由于片段当中的弹幕数目有成百上千条,其主题数也有几十种,为了保证主题简短而有效,设置Z的数值为1~10,图3为弹幕主题个数对准确性的影响情况.由图3可知,在主题个数Z的选取中,当主题数为3时达到最优,超过5个后,对准确率的影响不大.

图3 弹幕文本主题Z个数对准确性的影响

图4 各模型指标的比较
通过图4的比较可知,模型的召回率更高,其模型的推荐性更高,并且其F值也明显也高于另外三种模型.图4中对于4种模型的准确率、召回率以及F值进行了汇总,通过观察可知,本文通过引入弹幕文本,极大的提高了个性化服务水平,在模型的准确性、召回率以及F值等方面都有了一定程度的提升.
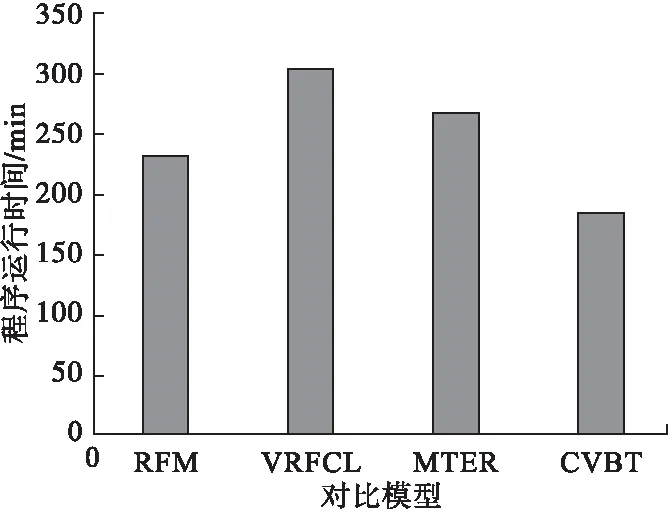
图5 各模型效率对比图
在方法四当中,本文提出的CVBT模型充分结合了视频当中的弹幕信息,弹幕文本能够在一定程度上反映出用户的真实情感,用户在观看视频的时候,可以通过弹幕的方式将自己的情感或者是对于内容的评论进行发送,这样新型的弹幕文化对于短视频推荐当中起到的作用是毋庸置疑的,因此推荐的准确率更高一些.同时方法四的召回率更好一些,说明其稳定性更好一些.
本文根据高光时刻进行视频内容特征的分析,其效率要比对短视频作整体内容分析要高,图5所示为模型效率对比,如图所示,本文提出的CVBT在效率上要比其他模型高很多.
4 结论
基于目前短视频在推荐过程中的准确性与效率不高,本文提出了一种视频内容特征与弹幕文本相结合的短视频推荐模型,融合深度学习方法与弹幕技术的优势,提高短视频推荐的个性化水平.首先对于弹幕进行文本分析,确定弹幕文本的主题;然后通过深度学习分析短视频内容的特征,得到相应的主题模型;最后根据用户的近期兴趣,确定其主题,形成相应的推荐列表通过对比实验验证,本文所提模型在准确率、召回率上比RFM以及VRFCL等模型有较显著的提升,并且效率也有所提高.
