基于电网多源数据融合的深度学习算法研究与应用
2021-06-14李波李凯钟苏生黄恺彤杨朝谊吴丽琼
李波,李凯,钟苏生,黄恺彤,杨朝谊,吴丽琼
(广东电力信息科技有限公司,广东广州 510080)
电网运行过程中会产生调度、电量、检修等多种类型数据,这些数据蕴含丰富的电网运行状态信息。合理挖掘这些信息的价值,能够提高电网运行的智能化水平[1-6]。
多源数据融合旨在模拟人类从视觉、听觉、嗅觉等感知到认识的机制过程,在电力系统的状态监测、故障诊断、负荷预测与新能源预测等方面广泛应用[7-12]。与神经网络、深度学习等人工智能算法相结合[13-16],能够充分挖掘电网海量数据的应用价值,在保障电网安全、稳定运行的同时,提升电网公司信息服务能力。
1 多源数据融合模型
1.1 多源数据体系架构
由于电力系统中设备的状态不仅与电气参数相关,还与温湿度等环境参数有关。因此,基于多源数据融合驱动电力设备状态的监测与故障评估,结果的准确性与多源数据的选取紧密相关,多源数据的选取应该遵循科学性、可行性与全面性的原则。科学性原则是指选取应符合客观物理过程的发展规律;可行性原则是指数据的选取应在统计基础上,具有可操作性;全面性原则是指数据选取应全面反映电力设备状态的变化。
以油浸式变压器为例,其表征故障状态的特征参数众多,依据科学性、可行性与全面性的原则,构建油浸式变压器故障诊断的多源数据体系,如图1所示。正常状态下变压器绝缘油中气体含量与空气大致相同,但随着变压器使用时间的增长或出现过热与放电故障时,绝缘油会发生分解,产生一氧化碳、氢气等气体。通过油色谱试验分析变压器绝缘油中某些气体含量,可以对变压器状态进行评估及诊断故障情况。变压器绝缘油是变压器主要的绝缘介质,通过油化试验绝缘油状态间接评估变压器的健康状态。电气试验指标通过测量变压器的主要电气参数,直观、简明地反映变压器的状态。
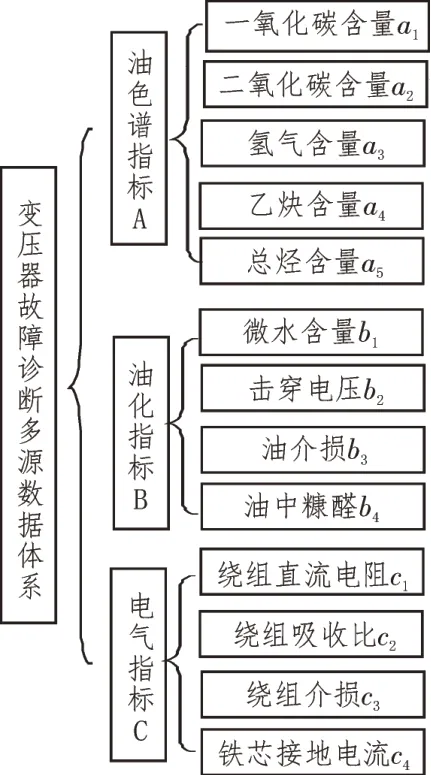
图1 油浸式变压器故障诊断多源数据体系
1.2 多源数据融合算法
多源数据融合(Multisource Data Fusion,MDA)是模拟人类从感知到认识的过程,结合不同学科的数据信息,通过对其进行优化分析、综合处理,完成所需任务的评估与决策。
DS 证据理论是多源数据融合领域常用的算法,属于决策级别的多源数据融合算法。其核心思想是将待分析的问题分解为多个子问题,通过DS 合成规则实现多源数据融合,最终依据所需任务的决策规则得到决策结果。基于DS 理论的多源数据融合决策算法如图2 所示。在数据层面,通过多个传感器进行多源数据采集,通过数据标准化、相关性分析等数据处理方法,实现多源数据整体识别与特征提取。在特征层识别所需任务决策证据,并通过DS 合成规则实现融合,在决策层依据融合形成的决策规则得到决策结果。

图2 基于DS理论的多源数据融合决策算法
DS 证据理论采用集合形式描述命题,假设N个互斥的独立事件构成一个集合,该集合称为识别框架,如式(1)所示。

式中,xn为识别框架θ的第n个元素。
识别框架θ的所有子集构成一个集合,称为幂集2θ,如式(2)所示。
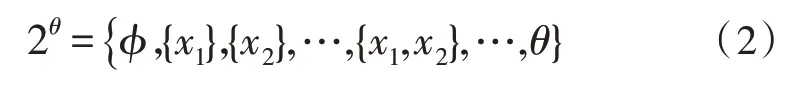
由此可见,幂集由2N个元素构成。假设A为幂集2θ的任意子集,即A⊂2θ,A与所需决策问题的一个命题相对应。进一步采用区间[0,1]的数值来描述对命题为真的信任程度,数值越大信任程度越高。命题A与该数值的对应关系采用基本概率分配函数进行描述。基本概率分配函数应满足以下关系,如式(3)所示。

对于同一决策目标,由于决策过程的数据来源不同,所以对应着不同的基本概率分配函数。假设两个来源不同的数据样本X与Y,其对应的基本概率分配函数分别为m1与m2,合成后的基本概率分配函数,如式(4)所示。
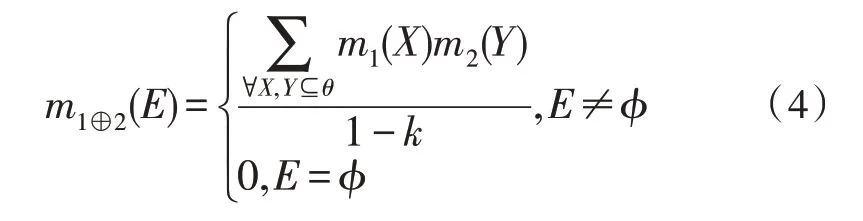
式中,E为合成后的数据样本,k为X与Y之间的冲突系数,k值越大说明X与Y之间的冲突越大。当k=1 时,说明X与Y完全矛盾,合成不成立,k的计算方法如下:

2 多源数据融合的深度学习算法
2.1 深度学习网络模型
机器学习算法是模拟人类大脑神经元处理信息机制的算法,传统神经网络模型包含2~3 层神经单元,如图3 所示。传统神经网络处理大规模数据的能力有限,通常要经过人工的数据特征提取,将提取后的特征数据作为输入。
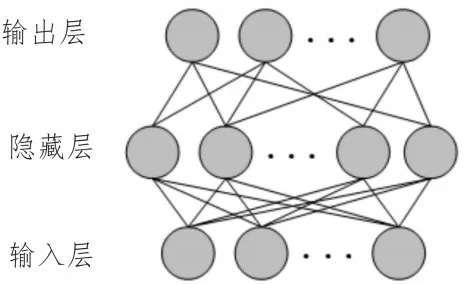
图3 神经网络模型
深度学习网络(Deep Learning Network,DLN)由神经网络发展而来,其可由5~10 层神经单元构成。因此可以处理更大规模的数据,实现特征的自动提取,具有较高的学习效率。其典型结构,如图4 所示,由多层受限玻尔兹曼机(RBM)堆叠而成。DLN的训练方法包含正向传播与反向传播两个过程,正向传播过程以原始数据作为输入数据,采用对比散度法进行无监督的预训练;反向传播过程根据输出结果的预测值与实际值的误差,采用梯度下降法对预训练得到的参数进行微调。
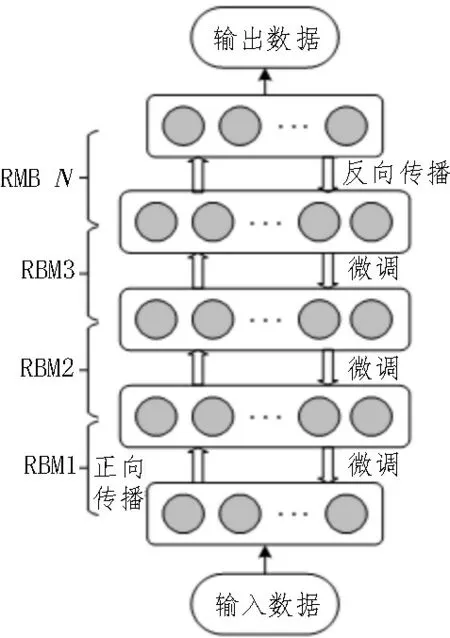
图4 深度学习网络模型
2.2 基于DLN-DS的变压器故障诊断算法
文中将DLN 与DS 理论结合,并将该算法应用于电力变压器的故障诊断。基于DLN-DS 的电力变压器多源数据融合模型如图5 所示。

图5 DLN-DS多源数据融合模型
以图1 的油浸式变压器多源数据作为输入数据,采用DLN-DS 算法进行故障诊断的步骤流程,如图6 所示。其包含以下3 个步骤:
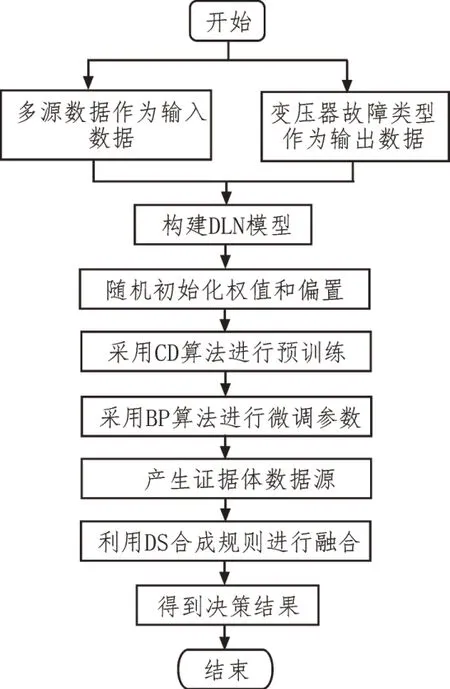
图6 基于DLN-DS的变压器故障诊断算法步骤
1)采集原始数据,其样本包含多源特征数据与变压器故障类型标签,多源特征数据作为DLN 模型的输入数据;
2)采用对比散度算法与梯度下降法对DLN 模型进行迭代训练,直至得到满足精度要求的DLN 模型;
3)采用DS 证据理论对DLN 模型输出结果进行数据融合,根据融合结果得到变压器故障诊断结果。
3 算例分析
文中算例采用某省电网2019 年变压器检修报告的故障数据,数据样本总数为1 400 个,每个数据样本包括油色谱指标L1、油气试验指标L2与电气试验指标L3共13 组数据。将变压器故障类型作为数据标签,常见变压器故障类型包括局部放电、过温过热、中低温过热、高能放电和低能放电。
3.1 多源数据融合对诊断结果的影响
以某次局部放电故障为例,分析采用DS 证据理论进行多元数据融合对变压器诊断结果的影响。图7 为各证据体关于局部放电故障的信任度。可以看出,只选取单种数据时信任度在0.2~0.4 范围内;选取两种数据时信任度在0.5~0.7 范围内;同时选取3 种数据时信任度为0.784。虽然不同数据方案下均能判断故障类型为局部放电,但采用3 种数据进行融合决策,结果更直观、明显,可以提高故障诊断的准确率。
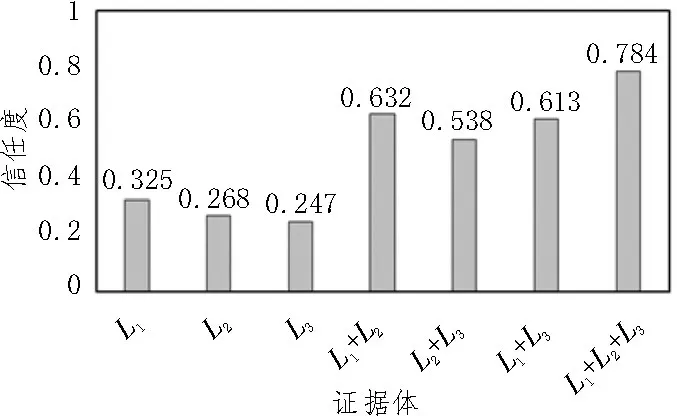
图7 局部放电故障各证据体的信任度
选取不同数据方案的变压器故障诊断准确率,如表1 所示。只选取单种数据时平均准确率低于85%;选取两种数据时平均准确率低于95%;同时选取3种数据信任度时,平均准确率高达98.1%。由此可见,采用多种数据融合方案具有更高的诊断准确率。

表1 不同变压器故障类型诊断准确率(%)
3.2 不同机器学习算法对诊断结果的影响
为对比深度学习算法与其他机器学习算法在变压器故障诊断应用上的差异,将上述变压器故障多源数据样本作为输入数据。机器学习模型构建方面分别选用BP 神经网络(BPNN)与支持向量机(SVM),均将其与DS 证据理论相结合,形成BPNN-DS 和SVM-DS 算法。各类机器学习算法故障诊断结果如表2 所示。

表2 各类机器学习算法故障诊断结果
由表2 可知,故障诊断平均准确率DLN-DS>SVM-DS>BPNN-DS,因为DLN 算法相比于BPNN与SVM 算法更适应大量数据的应用场景,具有较高的故障诊断准确率。
4 结束语
文中以油浸式变压器为例说明多源数据选取原则,构建电网多源数据体系,分析基于DS 证据理论的多源数据融合决策算法,进一步提出基于DLNDS 算法的电力变压器故障诊断算法。由算例仿真分析可知,通过DS 证据理论进行多源数据融合,能够更加明显、直观地得到故障诊断结果。多源数据融合决策相比于单源数据单独决策或双源数据融合决策,具有更高的故障诊断准确率。DLN 算法比BPNN 或SVM,具有更理想的故障诊断准确率。
