主成分分析结合支持向量机辅助激光诱导击穿光谱对塑料快速分类识别
2021-06-10刘俊安李嘉铭马琼雄张庆茂
刘俊安, 李嘉铭, 赵 楠, 马琼雄, 郭 亮, 张庆茂
华南师范大学信息光电子科技学院, 广东省微纳光子功能材料与器件重点实验室, 广东 广州 510006
引 言
世界上最早的合成塑料诞生于1907年, 标志着全球塑料工业的开端。 截至2015年, 全球大约产生了6 300吨塑料垃圾, 其中只有约9%被回收, 12%被焚烧, 剩余的大部分进入环境当中。 如果不能对塑料进行分类回收再利用, 到2050年, 大约有1.2万吨塑料废物将被扔到垃圾填埋场或自然环境中[1]。 在塑料回收中有一个关键环节是塑料的分类, 目前多采用传统的人力分类筛选或是经过复杂的化学工艺进行分选, 这些方法不但效率低下, 而且易对人体健康产生危害。 除此之外, 常见的分类方法还有红外识别光谱[2-4], 拉曼光谱[5], X射线荧光光谱[6]等。 虽然这些技术在塑料分类方面有较高的识别精度, 但易受环境条件和材料表面附着物的影响, 处理工序繁杂, 成本较高, 不能满足工业生产的需求。 激光诱导击穿光谱(laser-induced breakdown spectroscopy, LIBS)技术是一种原子发射光谱分析技术, 能够在不对样品做任何处理的情况下, 采集光谱信息用于大多数样品的分析, 灵活方便且具有快速检测能力。 目前LIBS技术被广泛应用于各个领域, 如生物医疗[7], 环境污水检测[8], 食物元素含量鉴定[9]以及冶金工业[10]等领域。
近年来, 国内外有许多学者已成功将LIBS技术应用于塑料分类领域, 并取得显著的效果, 主要包括: Myriam Boueri等[11]采用优化之后的人工神经网络(artificial neural networks, ANN)算法, 将LIBS光谱作为ANN的输入, 实现了对8种塑料制品的分类, 准确率在94%~100%之间; Banaee和Tavassoli等[12]利用CN, C2, N, Cl, O和H的谱线强度进行归一化后作为判别函数分析(discriminant function analysis, DFA)的输入。 结果表明, LIBS结合DFA对PET, HPDE等6种商用塑料可以实现99%以上的识别率; Yu等[13]提出了光谱权重调整结合激光诱导击穿光谱, 通过提高O Ⅰ 777.41 nm, C—N(0, 0)和C—C(0, 0)谱线的强度, 使得原本识别率较低的四种塑料(PE, PP, PU和PC)都能被100%识别; Rajendhar Junjuri等[14]用偏最小二乘判别分析法对10种常见塑料进行分类, 总体分类精度达到了93.30%, 另外还通过选取C, H, N等元素的谱线强度(谱线利用率占全谱的7.3%)重新建模后, 获得的分类准确度与全谱相当。 上述研究虽然都得到了很高的准确率, 但往往需要对原始数据做复杂的处理, 特别是分类准确度易受特征谱线选取的影响。 相较于其他算法, 支持向量机(support vector machines, SVM)是一种基于决策边界实现样本分类的机器学习算法, 特别适合用来解决复杂的中小型数据集的分类, 而且SVM算法能得到全局最优解, 训练和预测过程也比较稳定, 但是易受输入变量和噪声的影响, 面对高维数据的分类普遍存在耗费时间长, 无法有效地去除噪声带来的影响等问题。 主成分分析(principal component analysis, PCA)是一种常用的数据降维方法。 降维后的数据代表了原始数据的大部分特征, 而且去除了大部分噪声。 本文将PCA算法和SVM分类模型结合起来, 以实现又快又准地对塑料进行分类识别。
1 实验部分
1.1 LIBS装置
激光诱导击穿光谱实验装置如图1所示。 该系统主要由激光器、 数字延时脉冲触发器(DG535)、 光谱仪和增强型电荷耦合器件(ICCD)探测器组成。 数字触发器DG535会发出两路脉冲信号用来触发激光器和控制ICCD电子开关。 激光脉冲经过反射镜后, 垂直穿过焦距为150 mm的聚焦透镜, 到达样品表面, 烧蚀样品并激发等离子体。 此时产生的光谱由采集头收集并通过光纤(长2 m, 芯径50 μm)传到光谱仪, 通过ICCD处理传到计算机进行数据处理。 本实验采用的是调Q开关的Nd∶YAG激光器, 输出波长为1 064 nm。 所使用的光谱仪为ME 5000中阶梯型光栅光谱仪, 其分辨率为λ/Δλ=5 000, 波长精度为0.05 nm, 光谱检测范围200~975 nm。 经过对部分样品进行采样分析后得到最佳的延迟时间为2.6 μs, 门宽对应于2 μs。 另外, 实验样品是放在一个可以进行三维移动的载物台上。 采集光谱过程中将样品的运动轨迹设置为“弓”形。 电脑的处理器为AMD Ryzen 5 2500U with Radeon Vega Mobile Gfx, 核心参数为14 nm工艺, 四核八线程, 基础频率为2.00 GHz, 加速频率为3.6 GHz, 一级、 二级和三级缓存分别为384 kB, 2 MB和4 MB。 电脑内存大小为8.00 GB, 频率为2 400 MHz。

图1 LIBS实验装置图
1.2 样品
实验样品均为常用工业塑料样品, 从塑料的分子式来划分总共有11种, 分别是工程塑料(ABS), 尼龙(PA), 有机玻璃(PMMA), 聚氯乙烯(PVC), 聚碳酸酯(PC), 聚乙烯(PE), 聚苯乙烯(PS), 聚甲醛(POM), 聚氨酯(PU), 聚四氟乙烯(PTFE)和聚丙烯(PP)。 这些塑料样品在加工的过程中, 往往添加某些化合物以改善塑料的外观和性能, 如增塑剂、 阻燃剂、 着色剂等。 本实验采取的样品中有一部分是同一类型但有不同颜色的工业塑料, 也将它们归为不同类型, 所以本实验总共有20种塑料样品, 见表1。

表1 实验样品信息
2 结果与讨论
2.1 光谱数据的采集与处理
总共采集了20种塑料的光谱, 每种塑料取100幅光谱图像, 总共有2 000组数据。 样品光谱范围为200~980 nm, 共有25 745个输入变量。 为降低光谱强度的波动, 所有谱线均除以C Ⅰ 247.86 nm谱线强度进行归一化处理。 图2所示为样品PVC1的LIBS光谱强度经C线归一化后的全谱图。

图2 样品PVC1的LIBS光谱强度归一化全谱图
2.2 支持向量机结果分析
为了训练支持向量机, 提前将原始数据集随机分成训练集和测试集, 并为每种塑料设置相应的标签值。 我们将所有数据集打乱, 再从每种塑料光谱中随机取出50组数据作为训练集, 并将余下50组作为测试集用来评估分类器的效果。 将训练集的1 000组光谱数据及它们的标签值作为SVM的输入, 参与训练SVM模型, 另外的1 000组数据(不带标签值)输入到训练好的模型中去, 最后得到分类的平均准确度和每种塑料各自的识别准确率。
采用5折交叉验证, 寻得最佳的参数C=2,g=0.001 953 125, 分类结果如图3所示。 蓝色的圆点代表样品的实际标签, 红色的加号代表样品的预测标签, 当这两种标签相互重叠在一起时说明结果正确预测。 由图可知, 1 000个测试集的样品, 只有一个样品被预测错误, 识别准确率达到99.90%。 这说明LIBS结合SVM算法对塑料分类识别具有良好的应用前景。

图3 SVM算法对测试集样品分类结果(1 000个样品)
但是, 在进行参数优化过程中, 为了得到最佳参数, 训练时长总共耗费1小时58分41.13秒, 1 000个测试数据集预测结果的输出花了11.96 s。 虽然我们得到了很高的识别准确率, 但是为此付出了巨大的时间代价, 过长的训练时间显然不符合现实当中工业生产的要求。 为了能够在保证高识别精度的情况下, 缩短SVM训练的时间以及预测的时间, 我们提出了主成分分分析结合支持向量机模型对塑料进行分类识别。
2.3 主成分分析结合支持向量机算法结果分析
上述用SVM对塑料分类过程中, 是将全谱数据作为SVM的输入, 每种塑料的光谱数据有25 000多个特征, 共有20种塑料样品, 2 000组数据, 由此可知整个SVM训练和预测过程将需要处理庞大的数据, 这造成了运算的时间成本上升, 导致处理速度降低, 这一点在进行参数搜索过程中表现明显。 由于在进行全谱输入过程中引入了大量不相关的数据, 浪费了程序运行的存储空间, 同时也引入大量的背景噪声, 致使分类识别的准确度可能会降低。
基于以上问题, 引入主成分分析法。 在训练模型之前, 将2 000组数据进行降维处理, 得到前20个主成分的累计贡献率图4所示, 前两个主成分的累计贡献率已经达到97.13%, 能够代表大部分原始数据的特征。 当主成分个数为13或更多时, 贡献率的增加逐渐变得缓慢。
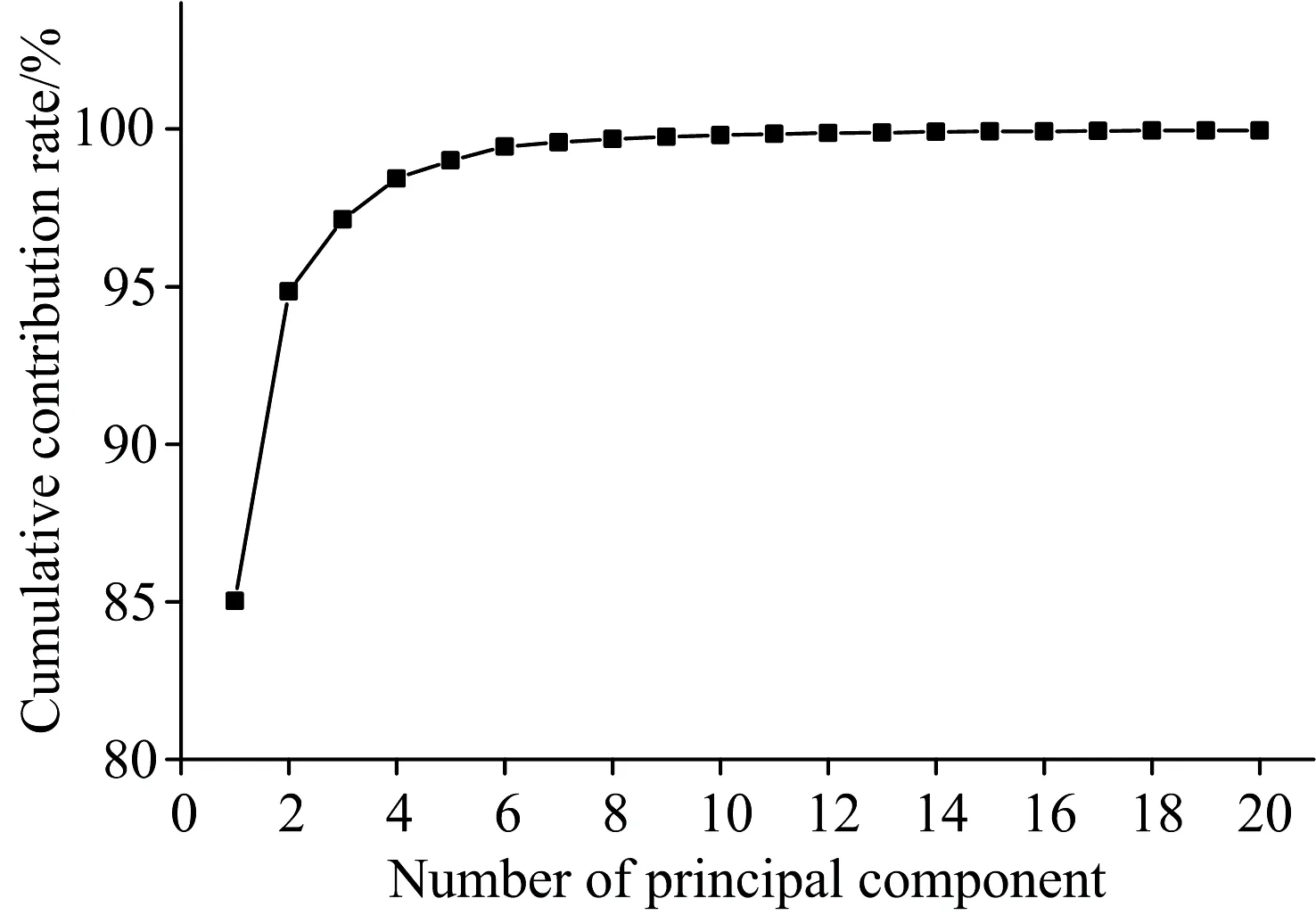
图4 前20个主成分的累计贡献率
为了能更直观地看到不同数据间的重叠程度, 把第一主成分, 第二主成分以及第三主成分各自的贡献率画在三维空间中。 它们的空间的分布如图5所示, 可以看到20种塑料间的区分度并不明显, 彼此交叠在一起难以区分, 这说明用三个主成分并不能很好地实现分类。 我们需要要做更进一步的分析。
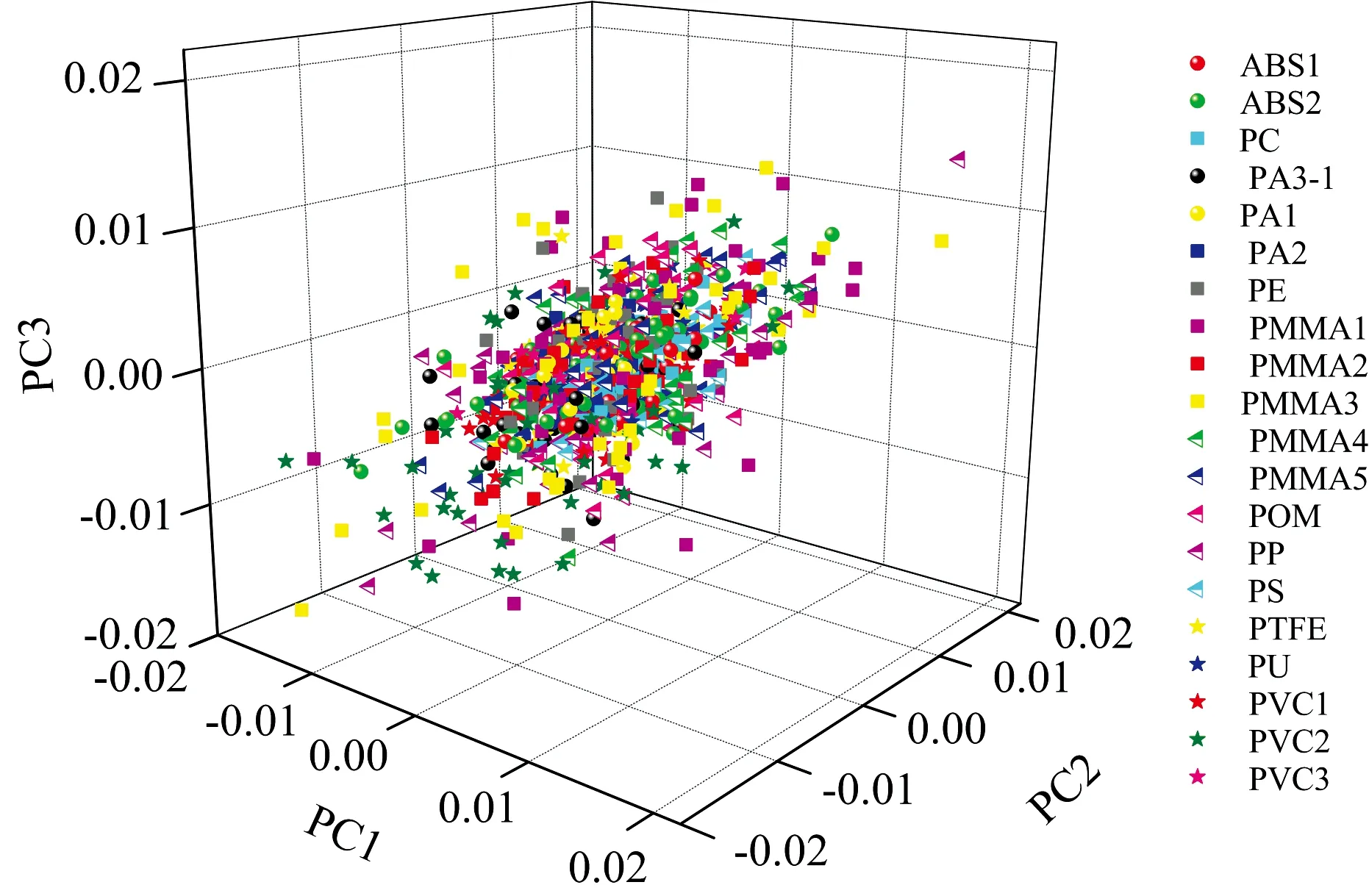
图5 20种塑料光谱数据在前3个主成分中的散点图
研究了在不同主成分下对应的分类识别准确率, 为尽可能减少样本分类过程中的偶然性, 降低实验误差, 每个主成分对应的准确率均进行了10次训练后再取平均的结果, 具体数值如图6所示, 从图中可以看到, 随着所取得主成分个数的增加, 识别的准确度也逐渐增加, 并最后到达一个平台期。 当主成分个数为13时, 采用10次训练求平均的方法, 得到的平均识别准确度是99.80%。 选取主成分个数为13, 训练得到时20种塑料的分类结果如图7所示。 当实际标签和预测标签相互重叠时, 即说明样品预测正确。 由图可见, 1 000个光谱数据中只有两个预测错误, 得到分类识别准确度为99.80%。 当主成分个数超过13后, 分类识别的准确度基本不再变化, 维持在99.90%以上。 由此可见, 经过PCA降维后, 去除了噪声和大量不相关数据带来的影响, 通过选取前几个特征值作为SVM的输入, 也能够实现很高的分类精确度。

图6 20种塑料光谱数据在不同维度下的平均识别准确率数

图7 PCA-SVM算法对测试集样品分类结果 (主成分个数为13)
为了分析实验过程所用时间, 本文先是研究将原始数据降成不同维度所需时间, 如图8所示。 PCA算法对数据的处理速度极快, 将原始数据降成13个维度也只需1.44 s。 虽然随着主成分个数的增加, PCA算法处理数据的时间也会增加, 但增加速度缓慢, 即使主成分个数达到20, 花费时间也不会超过2秒。 这体现了PCA算法在数据快速处理领域的优势。
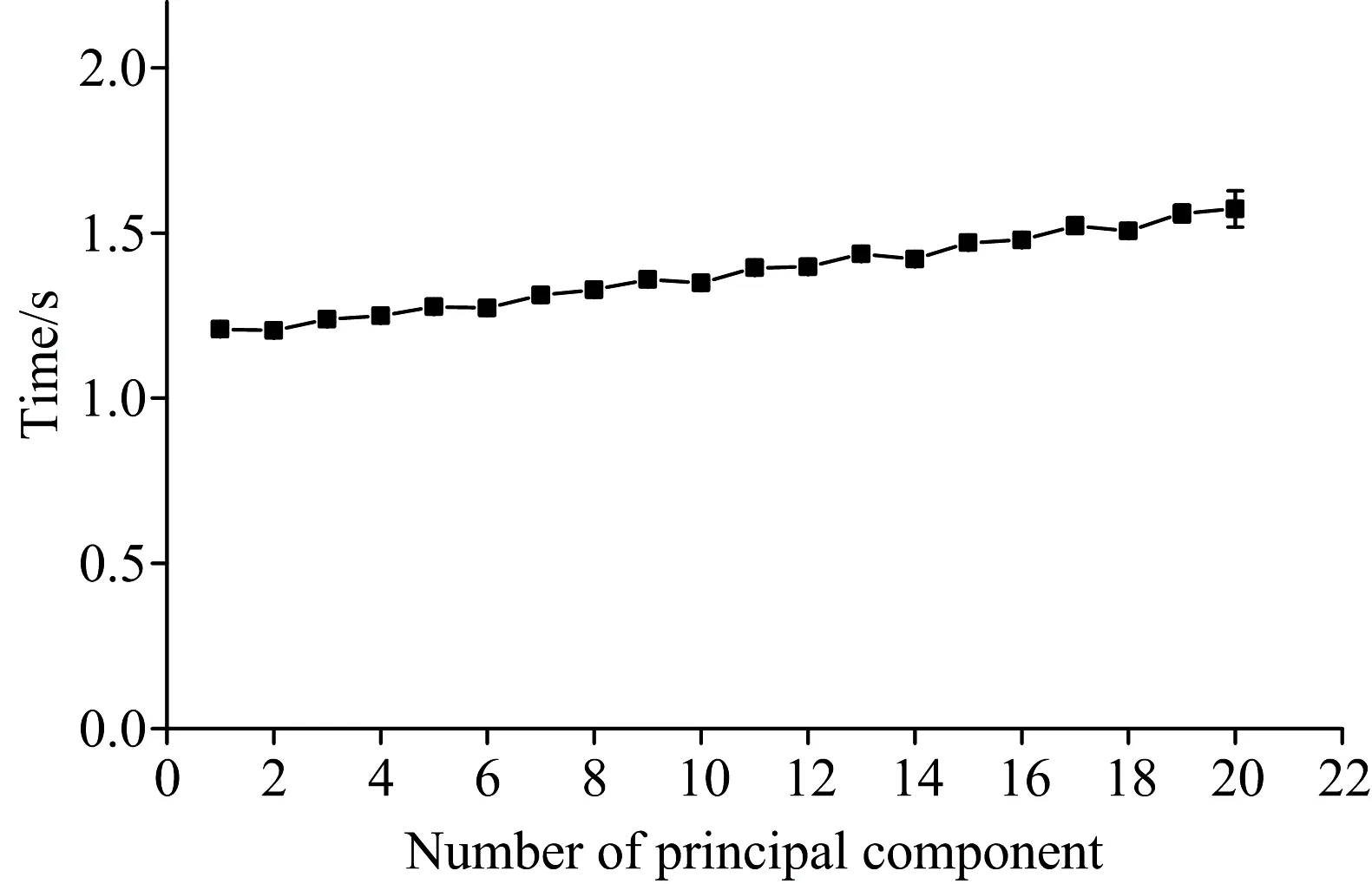
图8 PCA算法处理数据所需时间
接着进一步研究引入PCA算法后SVM分类器的效果。 将降维后的数据, 同样使用网格搜索和5折交叉验证的方法, 研究了在选取不同主成分个数的前提下, 相对应的模型训练所需时间, 如图9所示。 即使主成分个数已经取到20, 训练所耗费的平均时间仅为13.45 s, 这跟上述单纯用SVM训练时长(1小时58分41.13秒)相比, 速度提高了非常多。 除了第一主成分的训练时间波动较大外, 其他数量的主成分每次训练所需时间大致相同, 每次的训练过程均比较稳定。
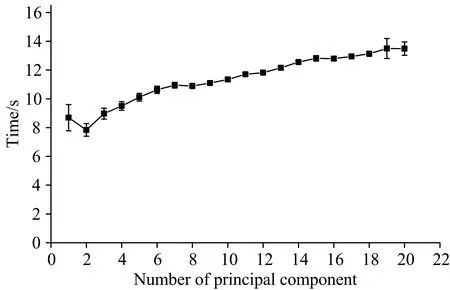
图9 20种塑料光谱数据在不同维度的平均建模时间
最后, 还研究了20种塑料光谱数据在不同维度下1 000个样本的预测时间, 如图10所示, 由于预测时间太短, 以至于预测时间在不同测试集间波动较大, 但是总体上1 000个样本预测所需时间也不超过0.04 s。 与上一节提到的11.96 s相比, 优化后SVM的预测速度得到很大提高。
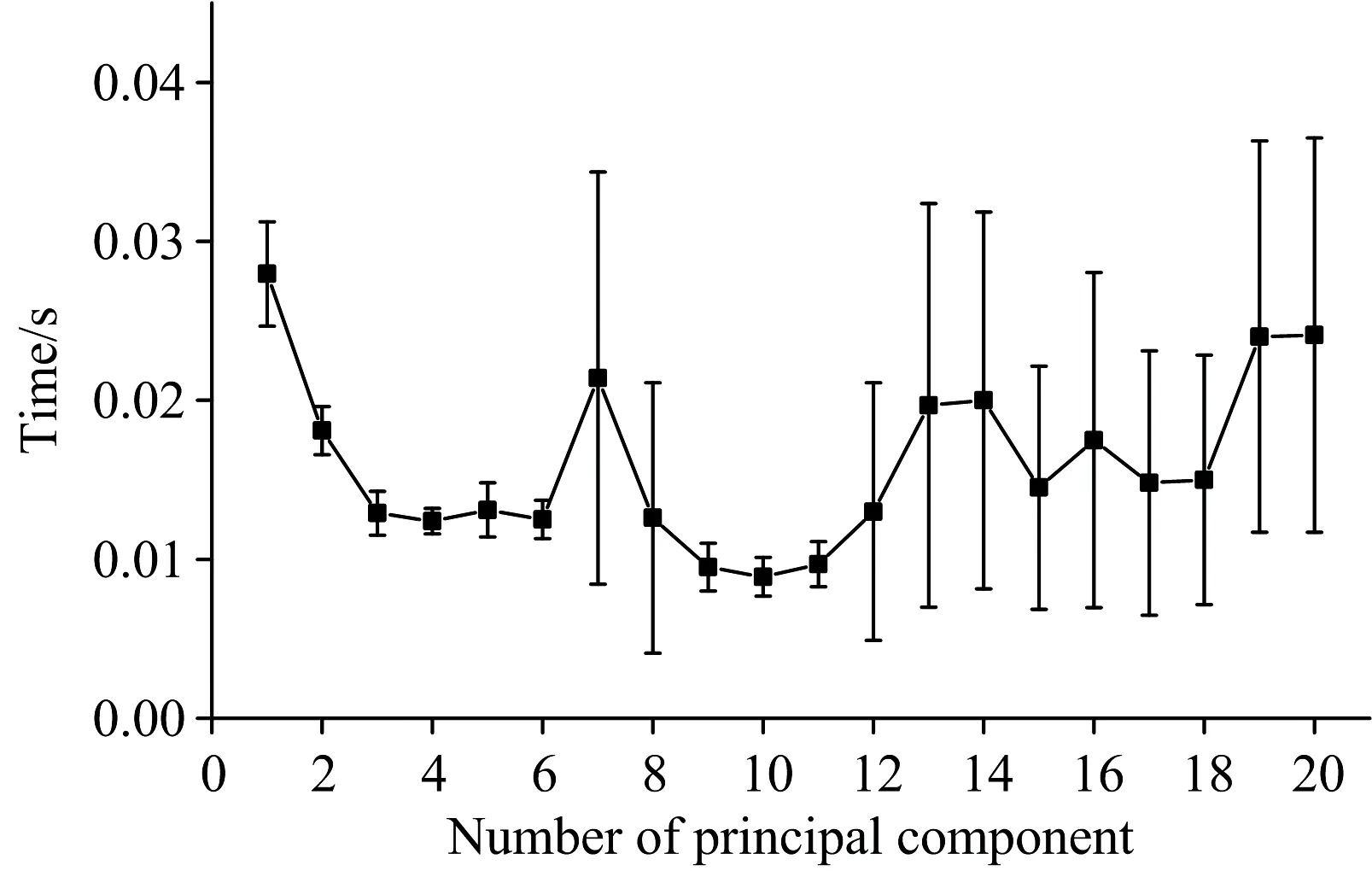
图10 20种塑料光谱数据在不同维度下的平均预测时间
为了直观比较两种实验方法在识别效率和识别精度上的区别, 选取主成分个数为13, 比较它们各自的识别时间和准确率, 如表2所示。 由表可知, 无论是实验过程的总体时间, 还是训练时间和预测时间, PCA算法结合SVM分类器的实验方法在分类识别速度上优势明显, 即使其准确率有些许的降低, 但两种方法的识别准确率仍处于同一水平上, 综合来看, 结合PCA算法利用SVM分类更加符合工业生产的要求。

表2 当主成分个数为13时SVM和PCA+SVM 实验结果比较
3 结 论
主成分分析结合支持向量机辅助激光诱导击穿光谱对20种塑料进行快速识别, 取得了预期成果。 在用支持向量机算法对塑料进行建模分析中, 得到99.90%的识别准确度, 训练时间长达1小时58分41.13秒, 预测时间为11.96 s, 整个实验过程总共花费1小时58分53.09秒。 这说明SVM算法分类准确度很高, 但是需耗费大量时间。 为了优化SVM的训练时间, 引入PCA算法对数据进行降维处理, 实现了分类识别准确率达到99.90%以上, 所需时间也在十几秒内, 特别是当主成分个数为13时, 降维时间为1.44 s, 训练时间也只需12.16 s, 相对应的预测时间为0.02 s左右, 从建立模型到输出预测标签所花时间也不超过12.18 s, 整个实验过程总共花费13.62 s, 而识别精度达到了99.80%。
兼顾塑料分类识别的准确率和分类识别速度, 将PCA算法和SVM算法相结合, 为实现塑料高效率、 高准确度自动分类提供了一种有效的方法, 有望运用在工业生产中。
