知识感知的多类型对话推荐
2021-06-10孙宇翔李程烽
张 骏,杨 燕,霍 沛,孙宇翔,李程烽,李 勇
(华东师范大学 计算机科学与技术学院,上海 200062)
0 引言
近年来,面向推荐的对话系统引起人们广泛的关注[1-4]。该系统是指集成对话和推荐的人机交互系统。过去的研究主要集中在单一类型的对话系统: 任务型或非任务型对话系统。任务型对话系统通过预先定义的槽匹配用户的偏好,而非任务型对话系统通过从数据集学习对话策略,然后在没有槽的情况下进行推荐。然而,在真实的应用场景下,对话往往同时涉及多种类型的对话,如闲聊、问答、推荐等[5-7]。如图1所示,面向推荐的多类型对话通过一条隐含的对话目标路径自然地获取用户偏好并向用户推荐合适的项目。上述示例中,系统先与用户进行寒暄,然后询问用户喜欢的电影与演员,并与用户围绕“林志颖”进行闲聊,最后向用户推荐其可能感兴趣的“林志颖”的电影。此外,在该过程中需要涉及很多外部知识,如“林志颖-简介-不老男神”、“林志颖-主演-《一屋哨牙鬼》”等。因此,多类型对话推荐比单一类型对话推荐具有更高的用户吸引力和用户满意度。如何构建面向推荐的多类型对话系统就显得尤为重要。
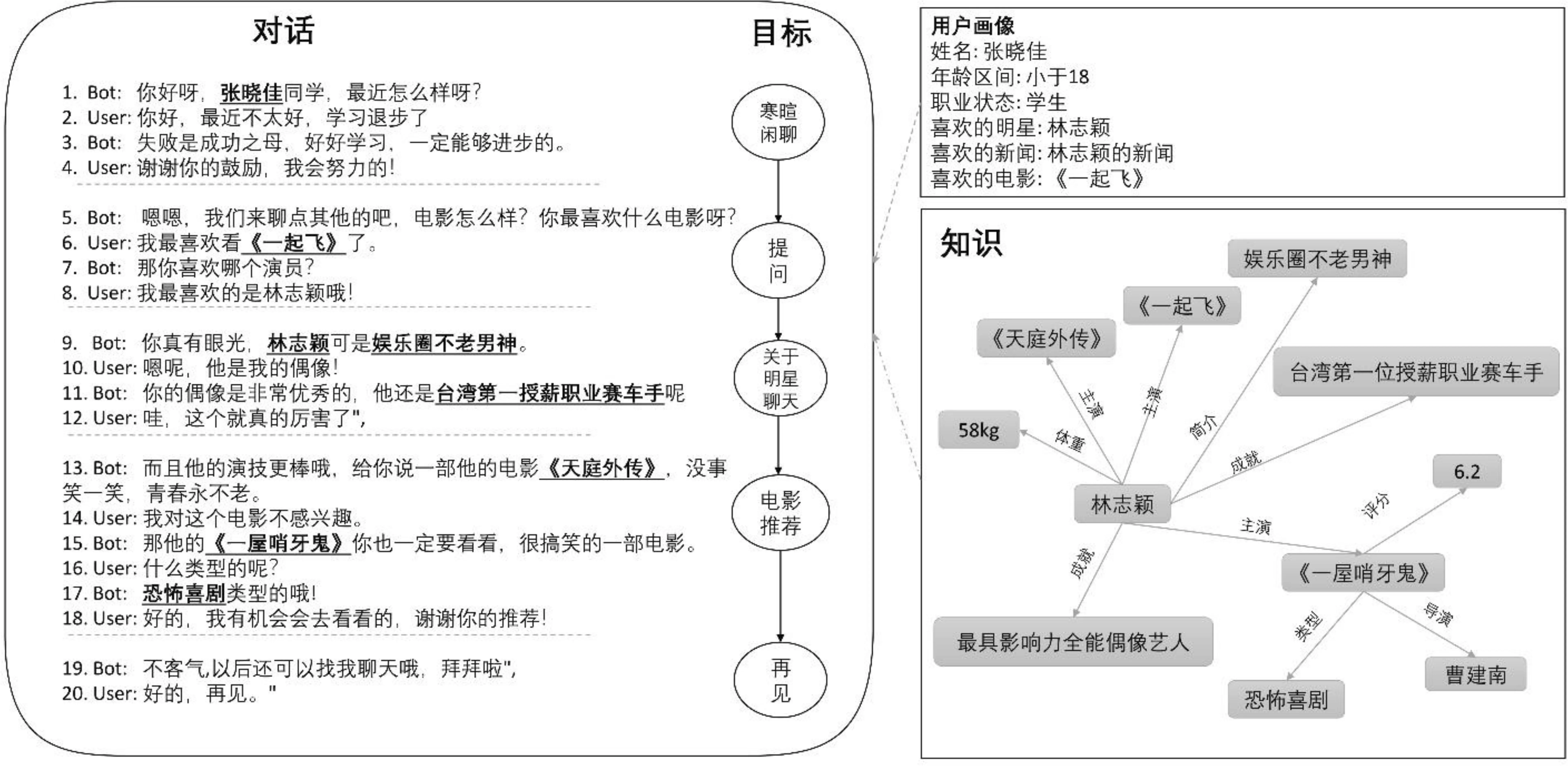
图1 面向推荐的多类型对话示例 注: 左边区域为对话过程,右边区域为提供的外部知识和用户画像。下划线标注的词是涉及外部知识的词。目标序列是根据真实对话进行标注的,每个目标对应一段多轮对话以及一个对话类型。
Liu等[8]首次提出了具有多目标驱动的对话策略机制的对话系统框架,并通过基于该框架的检索模型与生成模型实现面向推荐的多类型对话。该框架首先预测最可能的对话目标序列,然后将对话目标序列与对话历史、外部知识相结合,预测出最合适的回复。其中,基于检索的方法根据询问对预先准备的所有可能的回复进行排序,然后选择最佳的回复,即询问—应答匹配。该方法具有合理性、流畅性和可控性的优点,但存在长尾效应和难以定制的缺点。而基于生成的方法更加灵活,克服了基于检索方法的不足。它从数据集中学习回复的语言表达形式,可以生成从未在训练集中出现的回复。然而,在Liu等[8]提出的模型中,对话目标规划路径模块与对话输出模块是分离的,使得上述模型存在误差累积的问题。
本文提出端到端的基于Transformer的知识感知的生成模型(knowledge-aware generative model based on Transformer,KGMT)(1)https://github.com/562225807/recommandation-dialog-system,实现面向推荐的多类型对话系统。KGMT在Transformer解码器结构的基础上引入两个新颖的组件: 知识编码器和基于知识词表的Copy机制。知识编码器将每个知识表示为句子级别特征,并作为Transformer解码器的输入。Transformer解码器将类型向量与位置向量加入输入向量中隐式地建模对话目标序列,从而解决误差累积的问题。另一方面,该解码器使用多头注意力机制选取合适的外部知识进行解码,减少与用户询问无关的知识产生的噪声。Copy机制将生成的通用词汇替换为来自知识词表的词汇,以增加回复的知识信息量。本文将KGMT模型在DuRecDial数据集[8]上进行训练与评估,以此验证模型的有效性。实验表明,KGMT模型对比其他基线模型在各项指标上取得了很大的性能提升。在面向推荐的多类型对话任务中,KGMT模型能够选择合适的外部知识生成信息更丰富、语句更连贯、内容更适当的回复,从而完成每一个对话目标,并且主动引导用户进行下一个对话目标,最终完成对话推荐任务。
1 相关工作
1.1 面向推荐的对话系统
过去的面向推荐的对话系统主要可以分为两类: ①任务型对话建模方法。该方法中系统通过预先定义的槽匹配用户的偏好[2-3,9-10]; ②非任务型对话建模方法。在没有预定义槽的情况下,模型从数据集中学习对话策略[1,4,11-12]。目前的推荐型对话研究趋向于融合多种类型的对话来完成推荐任务。其中,Liu等[8]提出具有多目标驱动的对话策略机制的对话系统框架。该框架由目标规划模块和目标导向响应模块组成。目标规划模块控制对话流,根据用户的兴趣和在线反馈,为自然的话题转换制定合适的短期目标。目标导向响应模块选择合适的回复完成每一个对话目标。该框架在不同的模块间会产生误差累积的问题。而本文提出能够隐式地建模对话目标路径的端到端模型,可以从无标注的数据中自动地学习到合适的对话策略,并解决了上述问题。
1.2 生成式对话系统
近年来,生成式对话系统由于其极大的灵活性而引起人们越来越多的关注。Sutskever等[13]首次采用生成式的序列到序列(sequence to sequence,Seq2Seq)模型进行对话建模。Seq2Seq模型首先采用编码器编码对话历史,然后通过解码器生成回复。Vaswani等[14]提出了基于Transformer的编码—解码器结构来解决循环神经网络不能并行计算的局限性。因此,基于Transformer的生成式模型引起了广泛的关注。Wolf等[15]采用了基于单个Transformer解码器生成个性化的回复。Budzianowski等[16]将预训练的GPT-2模型用于任务型对话任务。
尽管这些模型已经取得了较好的效果,但是仍然会生成类似“我不知道”这类通用的、无意义的回复。为了进一步提高生成的回复的质量,Marjan等[17]使用记忆网络获取外部知识库中的信息,将Seq2Seq方法推广到基于知识的神经对话模型中。Lian等[18]通过对话历史以及回复的后验分布,监督模型选取和询问相关的知识,从而增强回复的信息。上述模型通过知识的全局信息提升回复的质量,而本文提出的模型从词的角度出发,通过基于知识词表的Copy机制显著地提高生成的知识词汇的准确率,进而提高推荐质量。
2 知识感知的生成式对话系统
图2为本文提出的KGMT模型结构图,模型包含了三个组成部分: 知识编码器、Transformer解码器和基于词表的Copy机制。首先,知识编码器通过双向长短期记忆网络(Bi-LSTM)[19]将知识编码为句子级别的向量。然后,知识向量与词级别的对话历史向量拼接为Transformer解码器的输入,经过解码输出特征表示。最后,通过基于词表的Copy机制提高回复中的知识的准确性,使得模型在合适的位置选择准确的知识词汇,加入到生成的回复中。

图2 KGMT模型结构注: 左上角为输入示例,其中省略了外部知识、用户画像。
2.1 知识编码器
知识编码器用于向模型引入外部知识。数据集中的知识被表示为三元组(he,R,te),其中he表示头实体,r表示关系,te表示尾实体。本文将三元组拼接为新的知识项,第i条知识ki被表示为[he;R;te]。此外,本文将用户画像中的姓名和性别作为新的知识项,用于获取用户相关的信息。知识编码器使用Bi-LSTM将ki编码为隐藏表示,在t时刻的隐藏表示hi,t计算如式(1)~式(3)所示。
其中,Emb(xt)为知识ki中第t个词的词向量,[·;·]表示向量拼接操作。最后时刻的隐藏状态表示hi,t被表示为知识ki的句子级别向量hi。
2.2 Transformer解码器

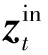
其中,WQ,WK,WV均为可训练参数,hn为注意力头的个数。
2.3 基于知识词表的Copy机制
对于知识驱动的对话聊天机器人,一个重要的能力是根据给定的知识来生成回复。为了增强生成的知识词汇的准确性与信息性,基于知识词表的Copy机制[20]被用于实现从知识词表中复制与对话相关的知识词汇。它使用门控单元pgen,t控制选择普通词表词汇或者是知识相关的词表词汇。pgen,t计算过程如式(7)所示。
pgen,t=sigmoid(Wsst+b)
(7)
其中,Ws与b为可训练参数,st为经过Transformer解码器获得的隐藏状态表示。因此,t时刻输出词表的概率pt计算过程如式(8)~式(10)所示。
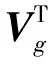
为了构建与当前对话相关的知识词表,本文把外部知识中所有的词组成一个新的词表。其中的标点符号、停用词被删除,留下的词汇组成当前对话的知识词表。
2.4 损失函数
每个样本的损失函数定义为最小化目标分布pt与真实分布ot交叉熵误差。其中真实分布ot为one-hot向量。损失函数计算如式(11)所示。
(11)
3 实验
3.1 数据集
本文使用DuRecDial数据集进行模型效果的评估。数据集包含10 190组多轮对话,共计155 477个句子,涵盖多类型的对话目标,包括寒暄、推荐、问答等。本文将数据集分为50 398组数据的训练集,7 272组数据的验证集和4 645组数据的测试集。每组数据由以下五个部分组成:
(1) 对话目标: 描述真实对话目标路径。
(2) 用户画像: 描述用户身份和喜好。
(3) 对话场景: 描述对话发生的场景,包括时间、情景状态。
(4) 外部知识库: 由多条与当前对话相关的知识三元组组成。
(5) 对话历史: 由符合对话目标序列和对话场景的一对一多轮对话组成。
3.2 训练设置
本文使用Pytorch实现模型,词向量维度为768,词表大小为29 920。Bi-LSTM中的单向隐藏层大小为384。Transformer中多头注意力头个数为12,Transformer解码器堆叠层数为12,mini-batch大小设置为4,学习率为1e-5。模型在整个训练集上训练10轮,在GPU-P100上训练了8个小时。
3.3 基线模型
本文使用了如下模型与KGMT模型进行对比: ①2020语言与智能技术竞赛自动评估前十团队模型; ②MGCG_R: 为Liu等[8]提出的检索式模型; ③MGCG_G: 为Liu等[8]提出的生成式模型。
为了展现Copy模块的有效性和预训练词向量对KGMT模型的影响,本文采用如下消融实验: (1)KGMT-CP: 不包含Copy机制的KGMT模型; (2)KGMT+Emb: 使用了BERT预训练词向量的KGMT模型。
3.4 自动评估
评估指标: 本文使用了如下几个常用的自动评估标准,包括BLEU[21]、F1[8]和Distinct[22]。BLEU用于计算预测的回复与真实回复的词重叠程度,本文的BLEU是指BLEU-2。F1用于评估预测的回复与真实回复在字级别上的精准度。BLEU与F1均用于评估生成的回复与真实回复的相似性。Distinct评估生成的回复在词级别的多样性,本文的Distinct指Distinct-2。
评估结果: 表1展示的是自动评估的结果,第2行至第11行是最终前十团队模型的评估结果,KGMT模型在2020语言与智能技术竞赛的自动评估中获得第三名。第12行至第13行是MGCG框架模型MGCG_R与MGCG_G的评估结果,KGMT模型相比于MGCG框架模型在各个指标上均呈现很大的性能提升。其中F1指标上,KGMT较MGCG_G提高59.08%。在BLEU和Distinct指标上KGMT较MGCG_R分别提高了110.00%和66.14%。这表明KGMT模型能够生成更流畅、更具有信息性和更多样性的回复。MGCG_G与MGCG_R模型缺少对外部知识精确生成的控制,因此在F1与BLEU指标上有所不足,而KGMT在Transformer结构的基础上采用基于词表的Copy机制,很大地提高了外部知识生成的精准性。第14行至第15行是消融实验结果,从消融实验可以看出,去除基于词表的Copy机制使得KGMT模型的F1、BLEU和Distinct急剧下降,说明模型在不用对话目标下有效地利用了外部知识。此外,去除Copy机制使得模型生成结果多样性变低,也证明了特定的知识词汇的生成比例减少。使用BERT预训练词向量之后,各项指标降低,这是因为对话中包含与领域知识相关的词汇较多。BERT预训练模型不能很好地初始化这些词汇,从而增加了模型训练的噪声。
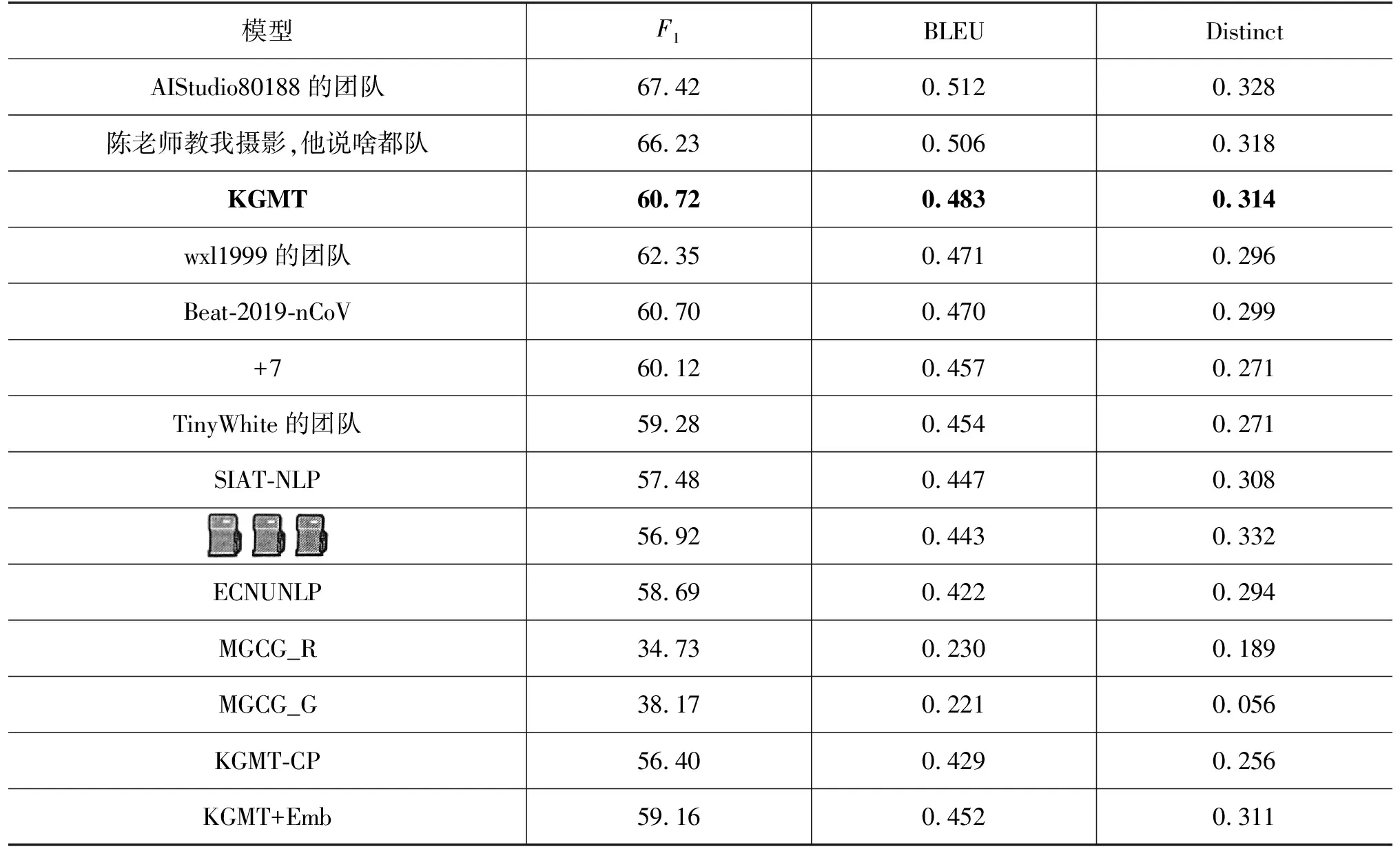
表1 自动评估结果
3.5 人工评估
评估指标: 本文采用单轮评估和多轮评估。单轮评估中,对话系统根据对话历史与外部知识生成下一句回复,评估人员对回复在流利度、适当度、信息量和主动性上进行评估。多轮评估中,评估人员与对话系统进行一对一多轮推荐对话,并对系统在语言连贯性和任务成功率方面进行评估。
评估结果: 表2展示的是前五获奖队伍的人工评估结果。模型在单轮评估中流利度、适当度、信息量和主动性分别为0.961、0.843、0.453、0.693,在多轮评估中成功率和连贯性指标为0.745和0.91。此评估结果在2020语言与智能技术竞赛: 面向推荐的对话任务中获得第三名。
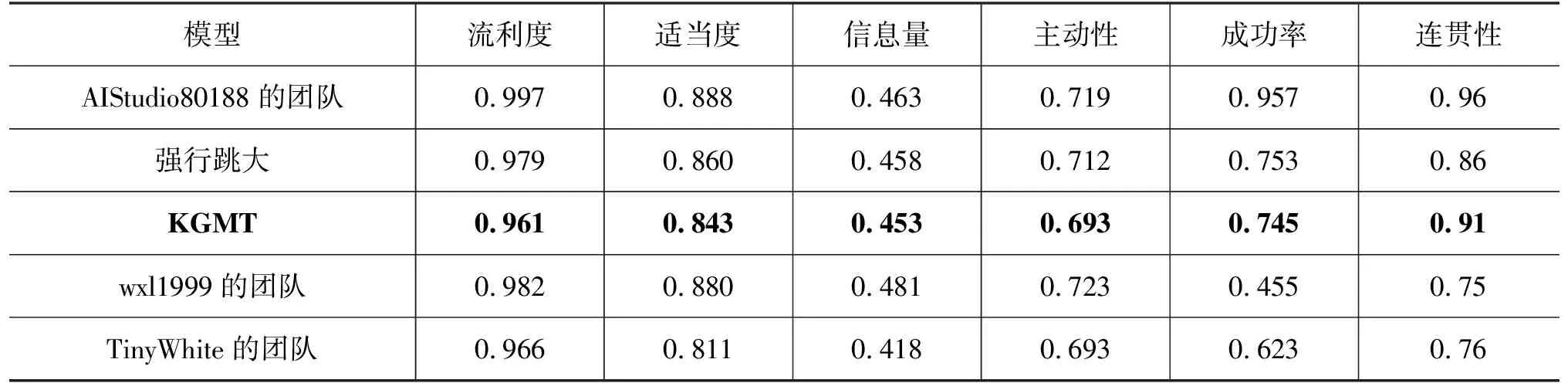
表2 人工评估结果
4 示例分析
图3展示的是本文提出的KGMT模型的对话生成样例。示例展现了KGMT模型能够通过多种对话类型主动地获取用户的喜好,并自然地向用户推荐合适的电影。从问答和推荐的精确度来看,KGMT能够将与对话目标相关的外部知识精准融入到生成的回复中。例如,当需要为用户推荐“张柏芝”的电影时,模型能够准确地从外部知识中获取该明星主演的电影以及电影类型,并反馈给用户。但当我们将知识感知模块从模型中删除时,即KGMT-CP模型,该模型生成的回复中出现的电影以及电影类型均是有误的,其获取的知识准确性就明显下降,这是由于模型倾向于生成训练集中出现频率高的词汇。从回复的流畅性角度来看,KGMT模型生成的回复在语法和语义表达方面都非常准确。此外,模型能够根据用户的喜好,主动与用户交流其感兴趣的话题,比如示例中,主动生成用户喜欢的明星的相关回复。

图3 不同模型生成的对话样例注: 下划线标注的词是涉及外部知识的词,具有灰色背景的词是与外部知识不符合的词。
5 结论
本文针对面向推荐的多类型对话任务,提出了基于Transformer的具备知识感知能力的生成模型(knowledge-aware generative model based on transformer,KGMT)。该模型在Transformer解码器的基础上引入知识编码器和基于知识词表的Copy机制。实验证明,模型能够生成信息更丰富、语句更连贯的回复,并且能够主动引导对话最终完成推荐任务,为构建具有知识感知能力的面向推荐的人机对话系统提供了有价值的参考。
