基于机器学习方法的母猪高低产分类模型研究
2021-06-08李喜阳李信颉赵志超李长春1刘向东1
李喜阳,李信颉,赵志超,李长春1,,刘向东1,
1.华中农业大学动物科学技术学院/农业动物遗传育种与繁殖教育部重点实验室,武汉 430070; 2.农业农村部生猪健康养殖重点实验室/广西扬翔股份有限公司,贵港 537100
母猪的产仔数性状是猪场生产成绩和母猪繁殖力的重要评定指标,据统计许多国家商业母猪群体的年淘汰率在20%~50%,其中产仔数性状差是母猪淘汰的主要原因之一[1]。母猪的高繁殖力直接决定了规模猪场的经济效益。因此,早在1980年,为选育出高繁殖力的母猪群体,欧洲畜产协会统一了母猪产仔数性状的记录方法并将其标准化,最早选育母猪的指标包括总产仔数(total number born,TNB)、产活仔数(number born alive,NBA)和健仔数(number healthy piglets,NHP)等[2]。此外,Nielsen等[3]和Su等[4]研究发现5日龄活仔数(number 5 day,N5D)与仔猪成活率之间存在中等遗传相关,对该指标的遗传改良将有利于提高仔猪成活率。因此,构建以上产仔数性状的分类模型,将有利于挖掘影响母猪生产水平的相关因素。
机器学习顾名思义就是让计算机学习,专门研究计算机怎样模拟或实现人类的学习行为,其不仅包含统计学知识,还是多学科知识交互应用的代表,例如其包含有大量的算法理论、概率论以及逼近理论等[5]。随着畜牧业的快速发展,所要处理和分析的数据量愈发庞大、数据结构愈发复杂,使得机器学习方法在畜牧领域得到了广泛应用。Bakoev等[6]以猪的生长和肉质特征为指标,利用9种不同的机器学习分类算法来评估猪的四肢状态。Messad等[7]利用梯度提升方法鉴定到的重要特征可作为猪饲料效率的可靠预测因子。Shahinfar等[8-9]利用绵羊的生产管理数据,通过不同机器学习方法构建了绵羊早期胴体性状和绵羊羊毛质量的预测模型,取得了不错的预测效果。Tusell等[10]基于猪的表型数据和基因组数据利用支持向量机预测猪的饲料效率和生长速度。李信颉等[11]使用几种不同的机器学习方法对母猪的产仔数性状进行预测。然而,之前的研究更多是对动物表型或经济性状的回归分析,涉及分类的研究较少。
因此,为探究影响母猪生产性能的相关因素(特征),筛选最佳的建模方法,本研究收集整理了包含以上产仔数性状的母猪群体数据集,针对不同产仔数指标制定母猪高低产的分类标准,利用4种不同的机器学习算法(逻辑回归、决策树、随机森林和支持向量机)构建母猪高低产的分类模型,并进行决策树视图分析,以期为实现高产母猪的早期选育提供参考。
1 材料与方法
1.1 数据的预处理
本研究收集整理了广西某猪场2016-2018年3个母猪群体的生产数据(以A、B、C数据集表示)。A数据集包含出生场地、分娩栏位、品种、第1胎初生窝重、第2胎初生窝重和第3胎的产仔数性状,B数据集包含出生场地、分娩栏位、品种、第1胎初生窝重、第2胎初生窝重、第3胎初生窝重和第4胎的产仔数性状,C数据集包含出生场地、分娩栏位、品种、第1胎初生窝重、第2胎初生窝重、第3胎初生窝重、第4胎初生窝重和第5胎的产仔数性状。正态性检验表明各胎次产仔数性状均近似符合正态分布。使用SPSS 19.0和Excel 2019对数据集进行预处理,剔除缺失值,并使用R软件对不同数据集的母猪产仔数性状进行描述性统计(表1)。
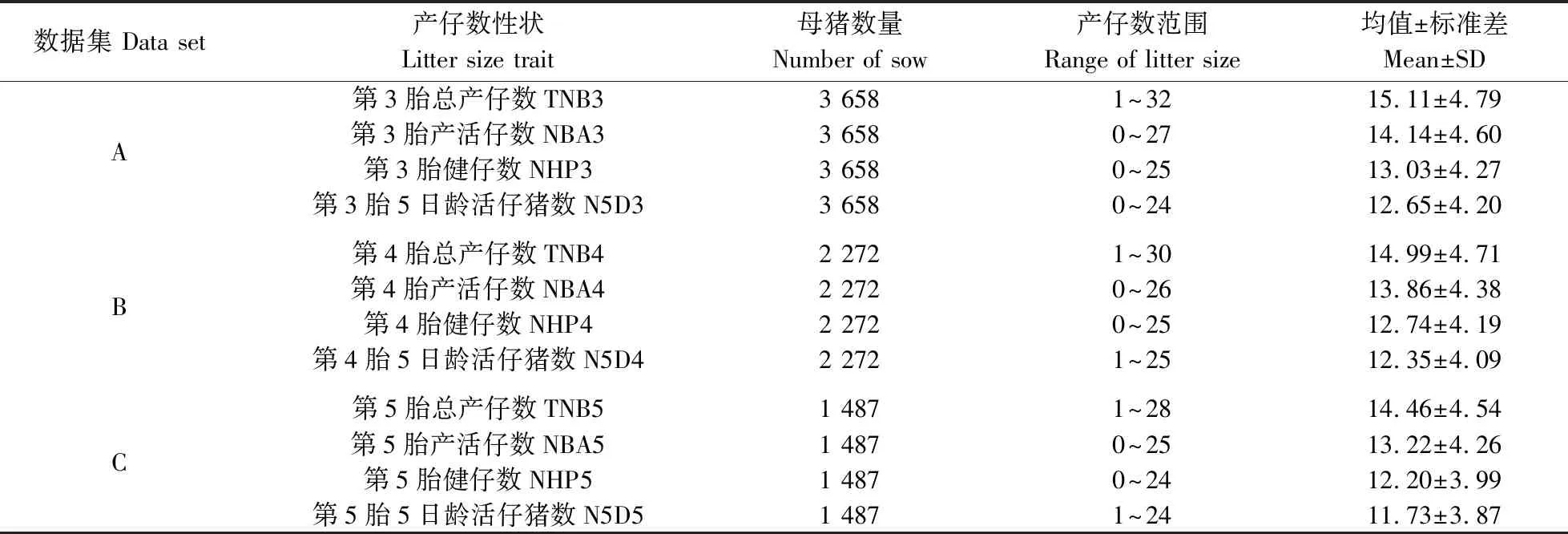
表1 不同数据集产仔数性状的描述性统计Table 1 Descriptive statistics of litter size traits in different data set
1.2 母猪高低产分类标准的制定
结合近年来我国核心母猪的生产水平[12]制定母猪高低产的分类标准。如表2所示,以A数据集为例,总产仔数大于等于18头、产活仔数大于等于17头、健仔数大于等于16头、5日龄产仔数大于等于15头的母猪为高产母猪,其余为低产母猪,以此类推,最后将产活仔数和5日龄仔猪数归纳为一个综合指标对所有数据集中的母猪进行再分类,形成最高产母猪。
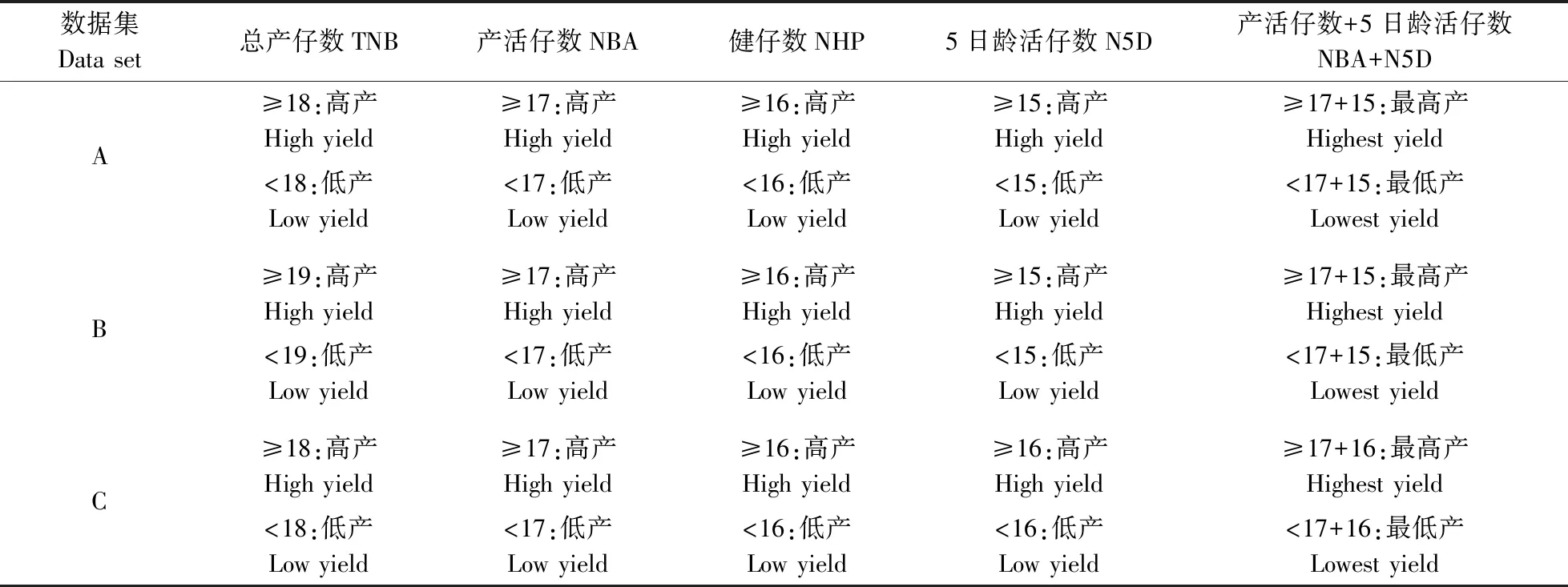
表2 高低产母猪的分类标准Table 2 Classification standard for high and low production sows
1.3 筛选构建分类模型的重要特征
使用R软件中的Boruta包对A、B、C 3个数据集中所包含的变量进行特征筛选[13],特征筛选结果如图1~3所示:除C数据集中的产活仔数模型中的第1胎初生窝重外(图3),3个数据集中所包含的其他变量对母猪产仔数性状分类模型的构建均重要,其中出生场地的重要程度均最高。
1.4 机器学习方法
1)逻辑回归(logistic regression,LOG)。逻辑回归是一种应用非常广泛的机器学习分类算法,它将数据拟合到一个logit函数中,从而完成对事件发生概率的预测。相比传统回归方法,逻辑回归弥补了线性回归无法处理分类问题的缺陷,其判别性能主要基于Sigmoid函数来实现,函数表达式如下:
通过Sigmoid函数计算特征得出相应的概率值,大于某一概率阈值的划分为一类,小于某一概率阈值的划分为另一类,以此来判断样本类别[5]。
2)决策树(decision tree,DT)。决策树作为最基础、最常见的有监督学习模型,常被用于分类问题和回归问题,它是一种以树结构形式表达的预测分析模型,其独特的树型分类图中从根节点到叶节点每一处都代表了一种特征。决策树算法的重要理论基础是“基尼指数”和“信息熵”,其为量化信息的分析工具。熵代表元素的随机性程度,在数学上,它可以借助于变量的概率来计算:H=-∑p(x)log(x),其中x表示离散随机变量,p(x)表示变量x发生的概率[14],概率越大,熵值越小,反之熵值越大。基尼系数和熵值的定义类似,基尼系数越大,熵值也越大,说明元素的随机化程度越高。
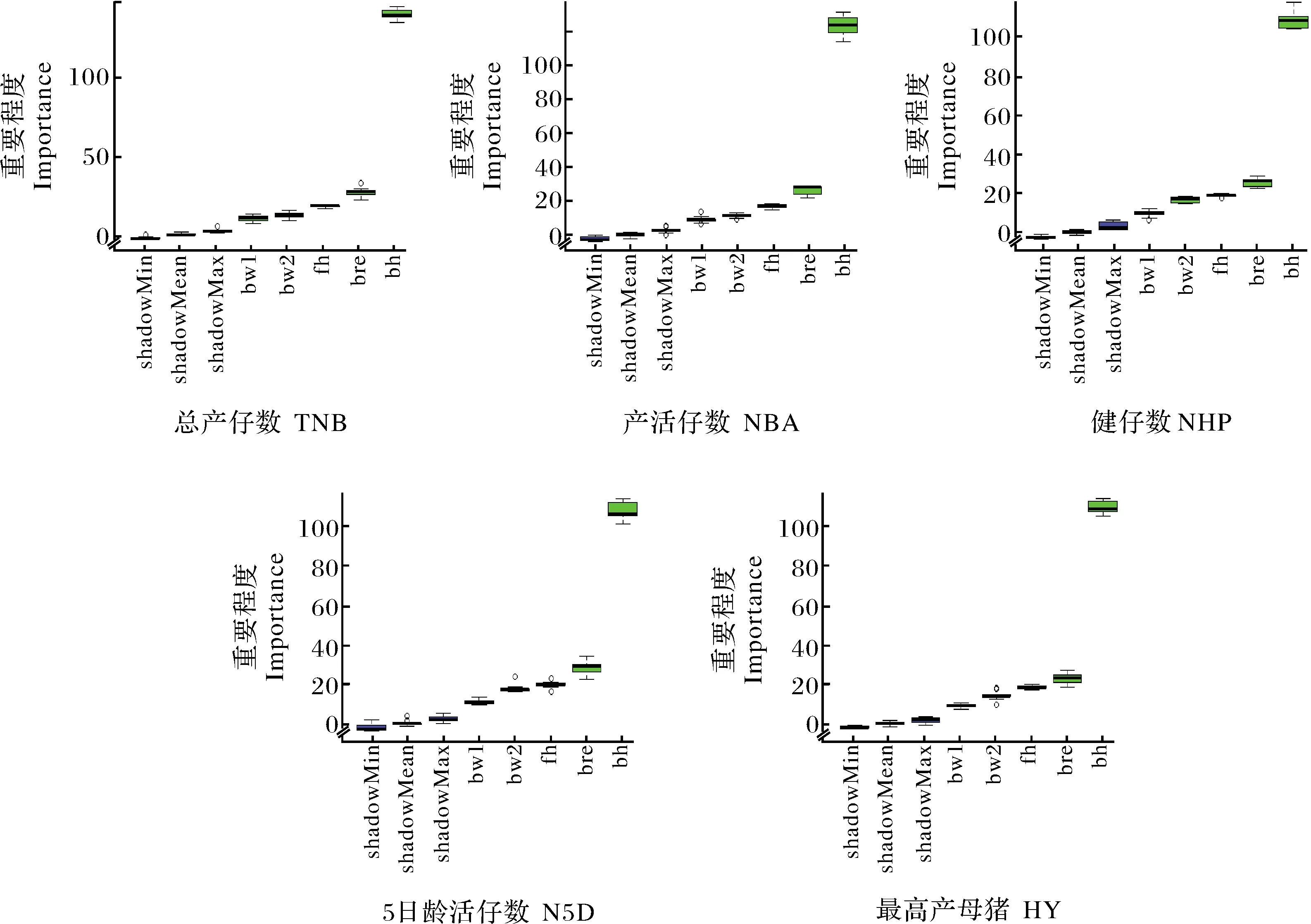
shadowMin:阴影属性的最小值; shadowMean:阴影属性的均值; shadowMax:阴影属性的最大值; 阴影属性的最小、平均和最大值为数据集中的阈值,高于阈值水平的特征为重要特征,红色、黄色和绿色方框代表拒绝、暂定和确认的特征; bw1:第1胎初生窝重; bw2:第2胎初生窝重; fh:分娩栏位; bre:品种; bh:出生场地; TNB:总产仔数; NBA:产活仔数; NHP:健仔数; N5D:5日龄活仔数; HY:最高产母猪。下图同。shadowMin:Minimum value of the shadow attribute; shadowMean:Average value of the shadow attribute; shadowMax:Maximum value of the shadow attribute;the minimum,average and maximum Z values of the shadow attributes are thresholds in the data set. Features above the threshold level are important features. Red,yellow and green boxes represent rejected tentative and confirmed features; bw1:Birth weight of first litter; bw2:Birth weight of second litter; fh:Farrow herd;bre:Breed; bh:Birth herd;TNB:Total number born;NBA:Number born alive;NHP:Number healthy piglets;N5D:Number 5 day;HY:Highest yield.The same as below.
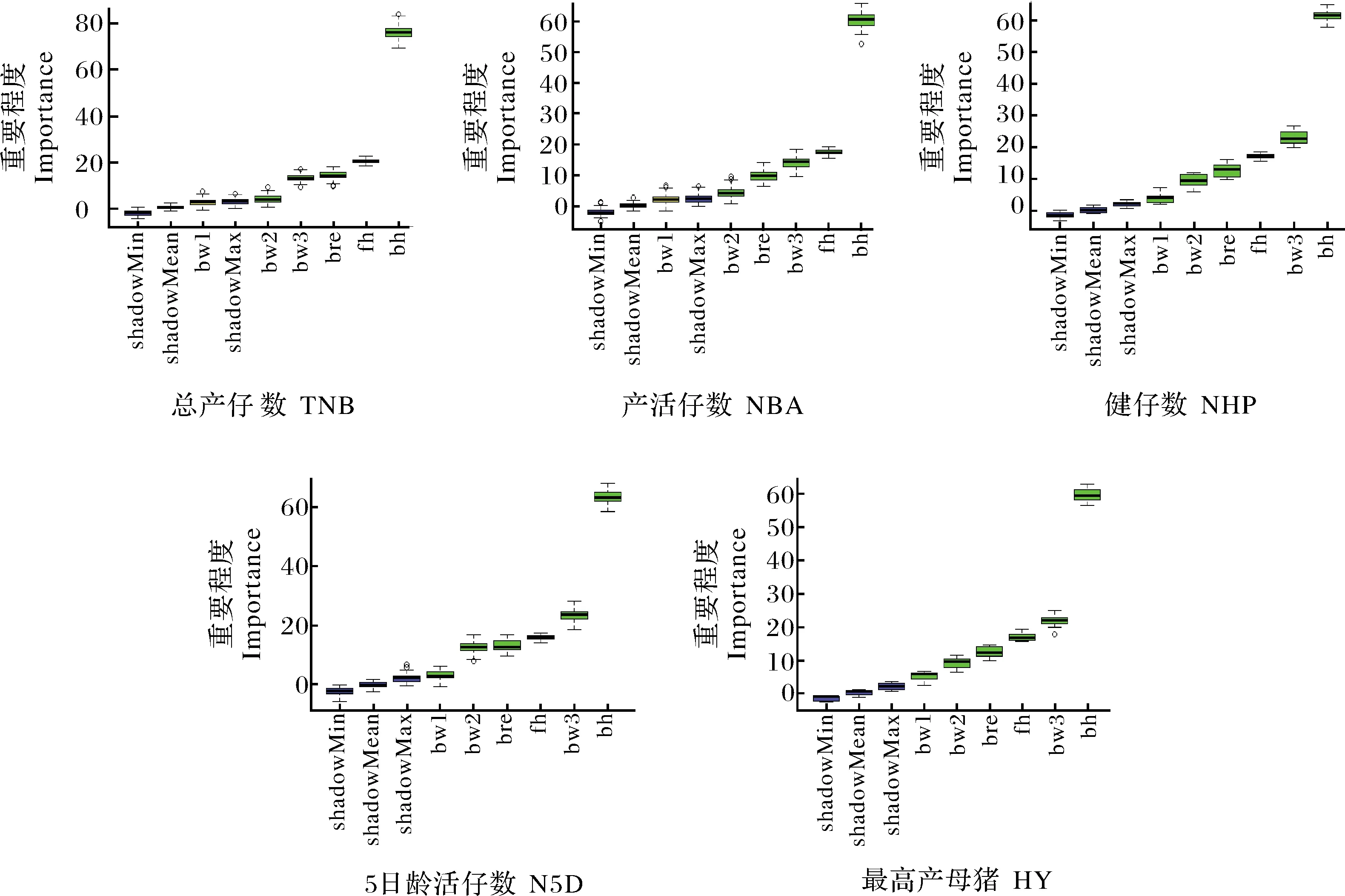
bw3:第三胎初生窝重;bw3:Birth weight of third litter.图2 分类模型的特征筛选图(B数据集)Fig.2 Feature screening diagram of classification model(B data set)
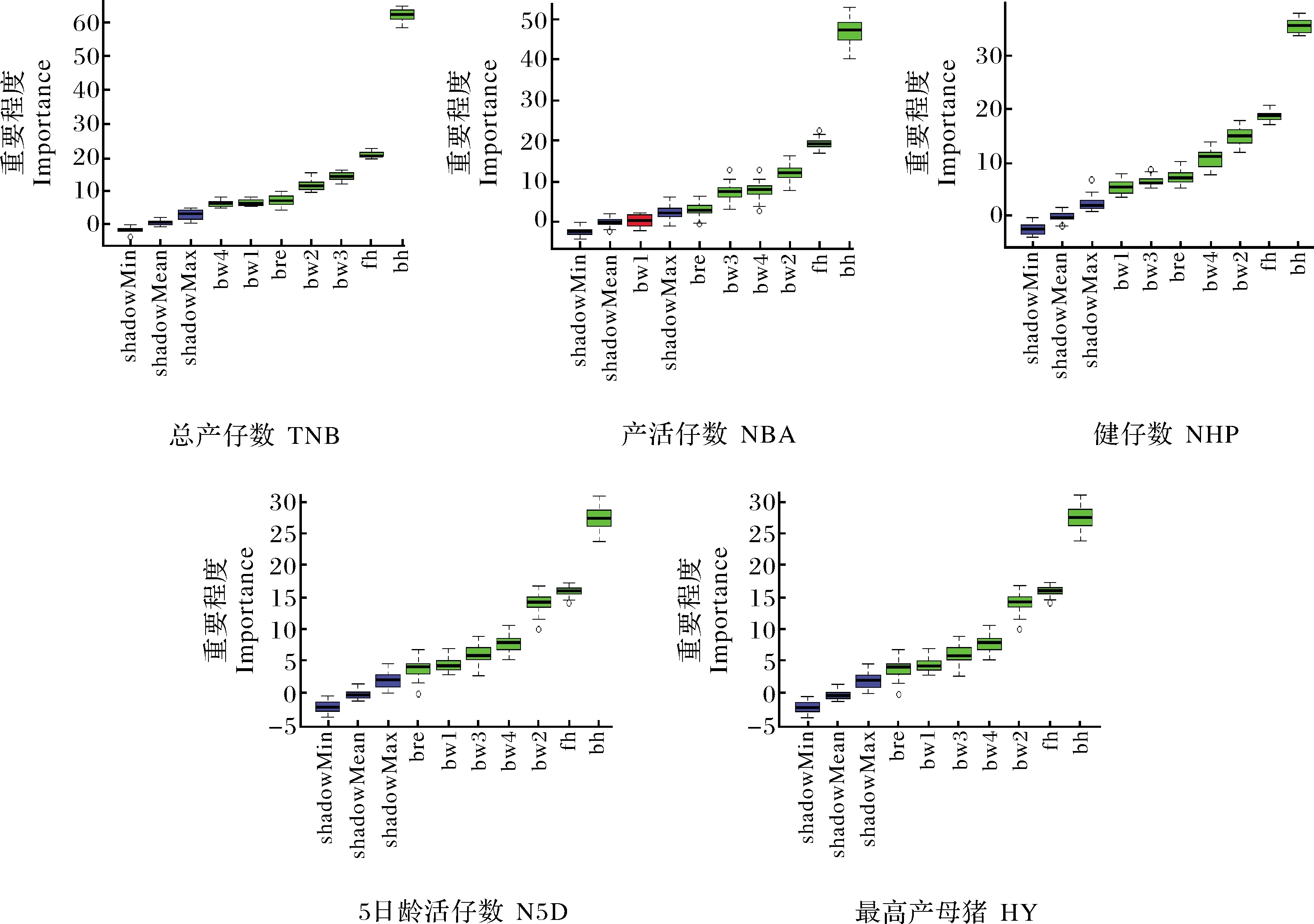
bw3:第三胎初生窝重 Birth weight of third litter; bw4:第四胎初生窝重 Birth weight of fourth litter.图3 分类模型的特征筛选图(C数据集)Fig.3 Feature screening diagram of classification model(C data set)
3)随机森林(random forest,RF)。随机森林是包含多棵决策树分类器的集合学习算法,在处理决策问题时,会根据集合思想构建多个分类决策树,同时进行决策,最后“遵循少数服从多数的原则”来确定最终结果,充分避免了单一决策树所产生的决策偶然性,提高了分类的可信度及准确率。
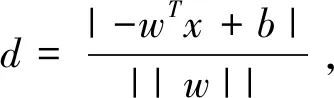
1.5 分类模型性能的评估
分类模型的评估是在已知特征和类别的训练集上构建,再利用从已知的原始数据集中拆分出一部分作为测试集对模型的分类性能进行评估,常使用混淆矩阵来计算其评估指标。本研究首先依据分类标准对A、B、C 3个数据集的产仔数性状进行二元处理,然后对数据集随机拆分,其中70% 的数据集作为训练集来训练模型,30%的数据集作为测试集来评估模型的性能。使用准确率指标对模型进行评价,准确率是指预测正确的结果占总样本的百分比,是分类问题中最简单最直观的评价指标。本研究对分类准确率最高的模型比较其ROC曲线的AUC值(ROC曲线下方的面积大小)来评估模型的性能,AUC值越高则其分类模型的性能越好。
1.6 决策树视图分析
决策树算法具有可视化的分析效果,使用R软件中的rpart包对经过二元处理后的A、B、C 3个数据集进行视图分析,找出重要的叶节点,从而分析影响母猪最高产的相关因素。
1.7 数据处理
本研究使用Microsoft Excel 2019和R 3.5.3软件进行数据处理,其中用到的R包有Boruta(特征选择)、rpart(决策树)、randomForest(随机森林)、e1071(支持向量机)及glm( )函数。
2 结果与分析
2.1 基于重要特征构建母猪高低产的最佳分类模型
按照不同的分类标准将母猪产仔数性状进行二元处理,基于筛选出的重要特征,利用4种不同的机器学习方法构建母猪高低产分类模型,比较最佳的分类模型。如表3所示,在A数据集中所有分类标准下,机器学习方法构建分类模型的分类准确率均在71%~74%;在B数据集中所有分类标准下,机器学习方法构建分类模型的分类准确率均在73%~77%;在C数据集的所有分类标准下,机器学习方法分类模型的分类准确率均在76%~84%。
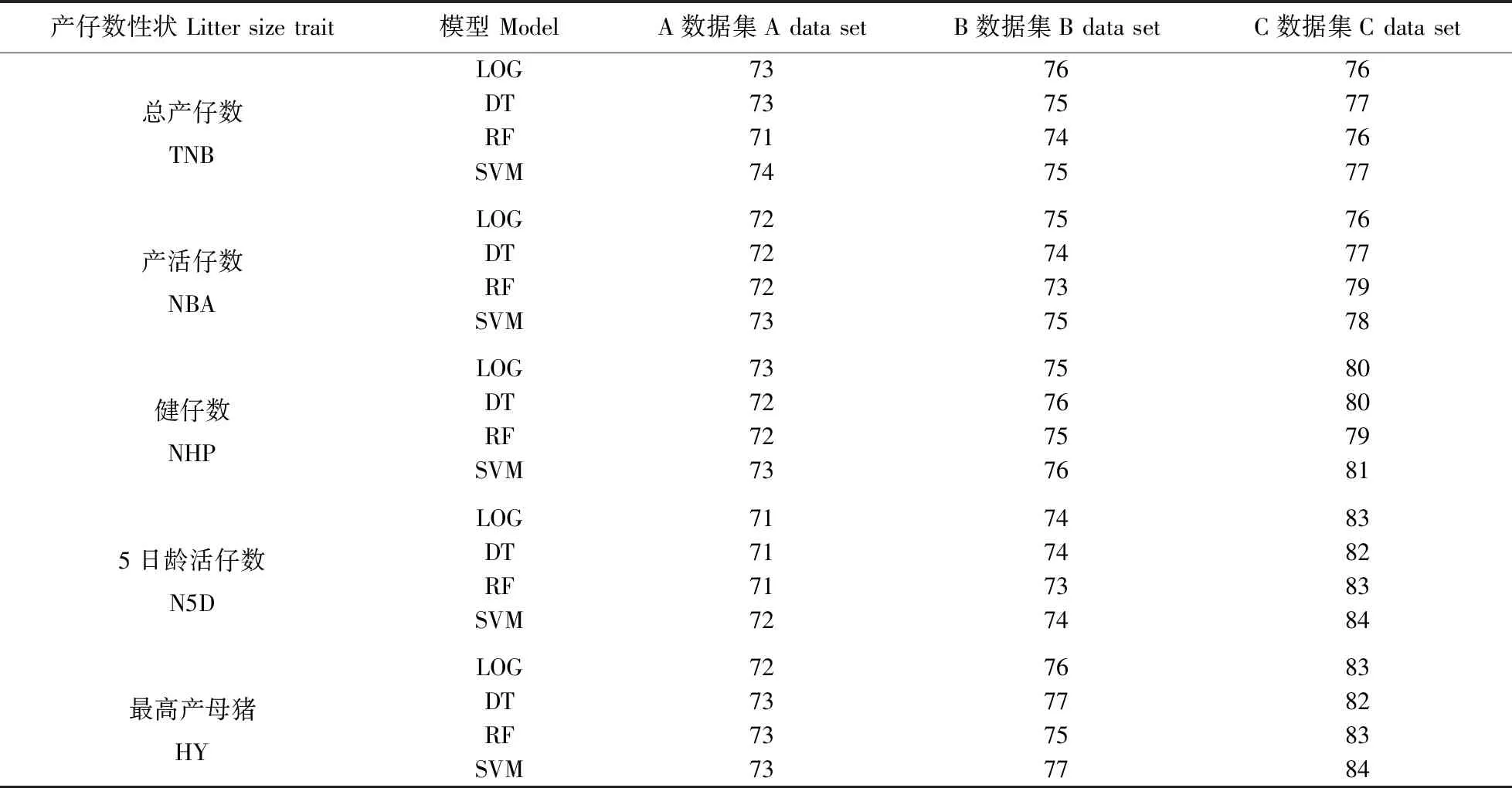
表3 不同分类模型的准确率比较Table 3 Comparison of accuracy of different classification models %
以分类准确率为评价指标,筛选出分类准确率最高的模型,对于最高分类准确率相同的模型,通过比较其ROC曲线的AUC值来确定最佳的分类模型(表4)。在不同数据集和不同分类标准下,最佳的分类模型也不同。结果如表5所示,在不同数据集的不同产仔数性状的最佳模型中,SVM(出现6次)、DT(出现4次)、LOG(出现4次)出现的次数较多,而RF只出现1次。
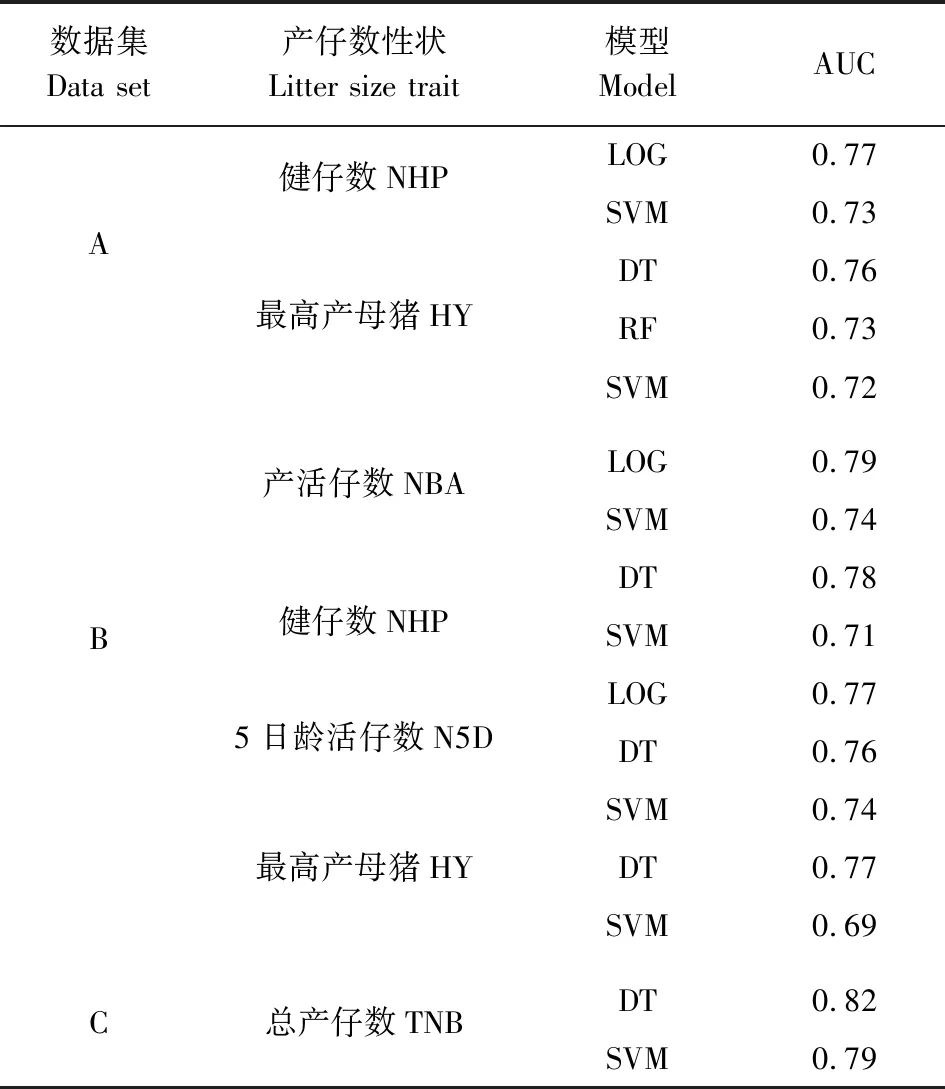
表4 不同数据集中最高准确性模型的AUC值比较Table 4 Comparison of AUC values of the highest accuracy models in different data sets

表5 不同分类标准的最佳建模方法Table 5 The best modeling method of differentclassification standards
2.2 决策树视图分析
对A、B、C 3个数据集中的最高产母猪进行决策树视图分析,结果如图4所示。对于A数据集,核心母猪的品种为大白,在1号场生产,第1胎初生窝重大于等于17 kg时其第3胎的产仔数性状较好,结合表3可知,利用决策树模型可推测母猪第3胎有73%的概率产活仔数在17头以上,5日龄产仔数在15头以上(图4A);对于B数据集,核心母猪在1号场生产,品种为大白,第1胎初生窝重小于23 kg,第3胎初生窝重大于等于22 kg时其第4胎产仔数性状较好,结合表3可知,利用决策树模型可推测母猪第4胎有77%的概率产活仔数在17头及以上,5日龄产仔数在15头以上(图4B);对于C数据集,核心母猪在1号场生产,第1胎初生窝重大于等于21 kg或第2胎初生窝重大于等于23 kg、第3胎初生窝重大于等于23 kg、第4胎初生窝重大于等于20 kg时其第5胎的产仔数性状较好,结合表3可知,利用决策树模型可推测母猪第5胎有82%的概率产活仔数在17头以上,5日龄产仔数在16头以上(图4C)。

A:A数据集; B:B数据集; C:C数据集; bre:品种(L:长白猪,Y:大白猪); bh:出生场地; bw1:第1胎初生窝重; bw2:第2胎初生窝重; bw3:第3胎初生窝重; bw4:第4胎初生窝重; H:最高产母猪; L:低产母猪。A:A data set; B:B data set; C:C data set; bre:Breed (L:Landrace,Y:Yorkshire); bh:Born herd; bw1:Birth weight of first litter; bw2:Birth weight of second litter; bw3:Birth weight of third litter; bw4:Birth weight of fourth litter; H:Highest yield;L:Lowest yield.
3 讨 论
本研究使用R软件中的Boruta包筛选的重要特征包括出生场地、分娩栏位、品种和不同胎次的初生窝重,如表3所示,基于这些特征构建的母猪总产仔数、产活仔数、健仔数和5日龄仔猪数的分类模型的准确率均在71%以上,最高可达到84%,表明利用机器学习方法构建的母猪高低产分类预测模型具有一定的可靠性。李信颉等[11]比较了3种不同的机器学习方法预测生产母猪产仔数性状的性能,发现SVM的预测性能要显著优于KNN和DT,这与本研究结果类似。Kirchner等[16]以母猪总产仔数、产活仔数、健仔数等为预测变量,利用决策树(DT)算法对母猪繁殖力的高低进行预测,其分类准确率在85%以上,其预测准确性与本研究较为接近。Bakoev等[6]基于猪生长和肉质特征使用多种不同的机器学习方法对猪的四肢状态进行分类预测,发现随机森林和K近邻拥有更好的预测性能,这与本研究的结果有出入,可能是本研究所用到的数据结构和特征不同所致。
决策树是近年来被广泛应用的一种数据挖掘方法,最早被用来挖掘人类社会经济数据中具有价值的数理模型[17]。决策树视图分析方法在畜牧业中的应用研究也较多,如Monteils等[18]利用决策树视图分析出了小母牛在生长期间有利于胴体品质的最佳饲养途径,从而更好地指导生产,提高母牛的饲养效率。本研究首次尝试使用决策树视图来分析影响母猪最高产的相关因素,结果发现在A、B数据集的最高产母猪的决策树视图中均显示品种是母猪高低产划分的重要叶节点,其中最高产母猪多为大白母猪。这与刘庆伟等[19]研究发现大白猪的产仔数性状要显著高于长白和杜洛克(P<0.05)、郭建凤等[20]研究表明大约克猪和长白猪的繁殖性能要显著高于皮特兰和杜洛克(P<0.05)的分析结果相吻合。
此外,在不同分类标准下的最优分类模型中,SVM出现的频次最高且均表现出较高的预测准确性,DT和LOG次之,RF出现的频次最低(只有1次)。Fernandez-delgado等[21]通过在121个UCI数据集上进行179种分类算法的分类性能比较,发现RF的预测性能更好,这与本研究结果有出入。有研究表明随机森林自身不能很好地处理非平衡数据且对于连续性变量处理还需要进行离散化[22-23],而本研究的A、B、C数据集中存在的不同胎次的初生窝重特征恰为连续性变量,这可能是造成此差异的原因。虽然SVM模型在不同分类标准及特征下均有较高的分类准确率,但部分SVM分类模型的AUC值要低于其他的分类模型,且对不同的产仔数性状其最优的机器学习算法也不尽相同。事实上没有哪种单一的分类方法是“最优的”,每种分类算法都有其特定的应用环境,要根据数据结构特点来选择合适的模型[24]。
本研究对已有的生产母猪数据集进行特征筛选,尝试运用4种不同的机器学习方法构建母猪高低产分类模型来对下一胎次的高低产进行预测,其预测准确率在71%以上,最高可达84%,并利用决策树视图探究了影响母猪高产的相关因素。然而,本研究也存在一定的局限性,如样本量较小、分类模型的预测准确性不高、模型的泛化能力还有待验证、所收集数据包含的变量较少等。在后续的研究中我们将进一步扩充用于构建模型的数据样本量,收集整理更多的变量,例如母猪的发情间隔、公猪的精液品质、母猪的体况和环境数据等,尝试用更科学的算法来构建模型以提高模型分类准确率,使得机器学习方法能够更好地应用于养猪生产,实现高繁殖力母猪的早期选育。
