深度学习在南川页岩气含气量预测中的应用
2021-06-08张勇马晓东李彦婧蔡景顺
张勇,马晓东,李彦婧,蔡景顺
(1.中国石化华东油气分公司 勘探开发研究院,江苏 南京 210005; 2.四川宝石花鑫盛油气运营服务有限公司,四川 成都 610000)
0 引言
近年国内页岩气勘探成果丰硕,先后发现了涪陵、威远等大型页岩气田。通过近几年的页岩气勘探开发实践,对页岩气富集主控因素也有了更深入的认识,其中含气量是评价页岩气富集高产的主控因素之一。目前含气量评价主要方法有测井解释、岩心实验测定以及地震预测。测井解释及岩心实验测定均只显示单点特征,要刻画研究区整体含气量平面特征,需通过地震预测来实现。地震预测方法中,由于含气性不是岩石物理弹性参数,难以通过地球物理反演技术直接预测,主要通过线性的单属性拟合或多属性融合、非线性的简单神经网络方法来预测[1-6],利用这几种方法对页岩气的含气量开展预测,发现精度较低。为了进一步提高页岩含气量预测精度,开展了非线性的深度学习预测含气量研究工作。近几年深度学习技术高速发展[7-8],在石油天然气勘探开发领域也有了广泛的应用。主流的深度学习神经网络包括深度神经网络(DNN)、递归神经网络(RNN)、卷积神经网络(CNN)。深度神经网络和传统意义上的神经网络结构并无太大区别,最大的不同是层数增多,训练方法更为优化,算法也更加先进;递归神经网络相比深度神经网络只能够接收到当前时刻上一层的输入,神经元的输出可以在下一时间段直接作用到本身,在自然语言处理方面多有使用;卷积神经网络[9]主要是模拟人的视觉神经系统,在人脸识别、图片识别领域应用广泛。本文利用深度神经网络的深度学习方法开展页岩含气量预测,结果表明,该方法能有效减小含气量预测误差。
1 深度神经网络原理
深度神经网络DNN(deep neural network)是基于神经网络的扩展,可以理解为很多隐藏层的神经网络[10],包括一个输入层,若干个隐藏层及一个输出层(图1)。深度神经网络相比传统的神经网络主要区别在于:加入了若干个隐藏层,整个模型的表达能力得到增强,但是随着隐藏层的增加模型的复杂度也随之增加;输出层的神经元也可以一个或者多个输出,模型可以灵活的应用于分类回归;对逻辑函数做扩展,简单神经网络的逻辑函数sign(z)处理能力有限,因此深度神经网络中使用Sigmoid函数。
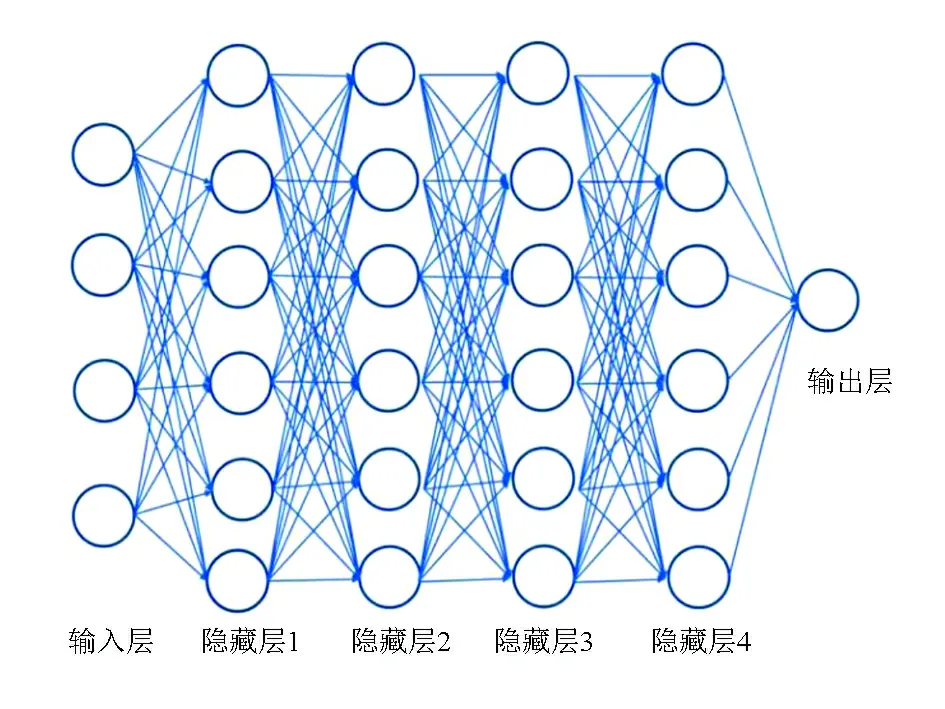
图1 深度神经网络结构Fig.1 Structure of deep neural network
在深度训练开始时,利用泽维尔初始化随机给出每一个地震属性对应的权重系数w以及偏置系数b,然后以加权平均的形式输入到第一个隐藏层中的神经元。神经元加权平均的和作为Sigmoid逻辑函数的输入,每一个神经元由一个非线性逻辑函数构成:
式中,z代表神经元输入数据。经过逻辑函数非线性转换后,得到中间结果。
在得到中间结果后,将加权平均结果作为下一隐藏层神经元的输入,经过输出层后,再进行逻辑函数转换,得到最终结果。输出的最终结果是基于初始化的w和b所得到,最终目的是要对所有w和b进行优化,使输出结果与实测数据之间达到最小二乘误差,即构建一个以w和b为自变量的函数,使预测结果与实测数据之间误差的平方和最小。
2 深度学习预测含气量
2.1 研究区地质概况
南川地区构造上处于四川盆地川东高陡构造带万县复向斜南部,位于四川盆地与武陵褶皱带的过渡区,总体呈现“隆凹相间”的构造格局,是江南—雪峰陆内造山作用向NW方向递进扩展变形的结果[11-12],地表出露岩性多变,三叠系、二叠系、志留系、奥陶系、寒武系均有出露。地下构造特征复杂,断裂主要呈NE向展布(图2)。南川地区页岩地层五峰—龙马溪组为一套稳定发育的暗黑色页岩,含泥质粉砂,厚度为80~120 m,富含有机质和笔石化石。TOC大于2%的优质页岩厚度一般在30~38 m之间,热演化程度适中,Ro为2.3%~2.6%,孔隙度为3.2%~5%,含气量为3.5~7.3 m3/t,各项静态指标优越[13-15],测井响应特征表现为高伽马、低纵波速度、低横波速度、低密度。从A井五峰—龙马溪组综合柱状图(图3)看,五峰—龙马溪组一段可细分为9个小层,总含气量由下到上逐渐降低,下部①小层局部总含气量能达到7.2 m3/t。该区东北部A井所在背斜区域已完钻30口井,单井测试产量(15.4~89.5)×104m3/d,开发效果好。

图2 南川地区构造特征Fig.2 Structural characteristics map of Nanchuan area

图3 A井五峰组—龙马溪组一段综合柱状图Fig.3 Comprehensive histogram of the first section of Wufeng-Longmaxi Formation in Well A
2.2 含气量预测
深度学习需要有训练目标和训练数据,在训练目标和训练数据之间进行学习,得到训练模型,然后利用模型对训练目标进行预测[16-20]。在深度学习预测含气量过程中,需要对属性进行相关性排序,然后确定最优属性个数,再优选合适的最优化求解方法、隐藏层个数、神经元个数、迭代次数建立高精度的训练模型,以求获得高精度预测结果。
2.2.1 属性排序及优选
深度学习预测含气量,需要尽量多的含气量测井数据以及大量的地震属性,如叠后振幅、频率、相位属性,以及地震反演得到的纵波阻抗、横波阻抗、杨氏模量、泊松比等。有了属性数据后,要进行多属性排序:首先确定最优属性,即单属性中的与含气量曲线相关性最高的最优属性;然后将剩余所有属性依次和该属性配对,利用所有的配对属性进行预测,寻找预测误差最小的那个属性对,该属性对中的另外一个属性就为第二优属性;确定最优及第二优属性后,重复前面确定第二优属性过程,依次对所有属性的优劣进行排序,得到属性排序表。在经过排序以后需要确定最优属性的个数,由于地震叠后属性及叠前属性多种多样,并不一定选择属性越多,预测精度越高,过多的属性带入学习会导致学习过度,反而导致更大的误差。从分析图上看(图4),当5个属性时验证误差最低,所以优选5个属性,分别为密度、纵波阻抗、平均频率、极性、优势频率。
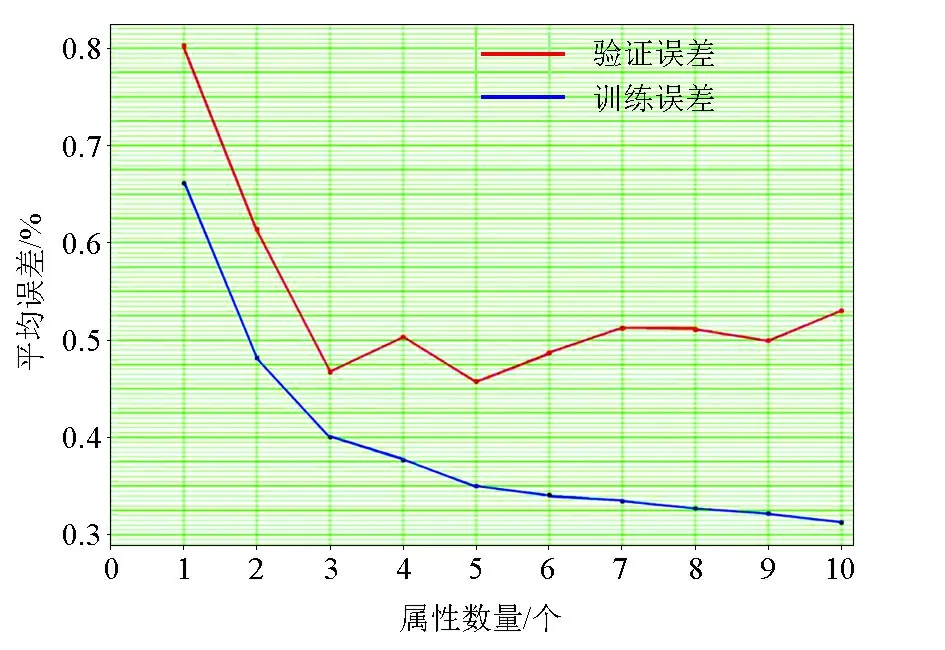
图4 属性个数优选Fig.4 Attribute number optimization diagram
2.2.2 最优化求解方法
在输出层输出结果过程中,由于求解方程包含很多非线性成分,直接求解不能得到期望的结果,需要确定优选最优化求解方法。最优化求解方法一般包括基于一阶泰勒级数展开的最速下降法、基于二阶泰勒函数展开的牛顿法,以及介于二者之间的共轭梯度法。最速下降法是最简单的优化方法,其利用的是一阶泰勒展开式,从初始点出发,采用一阶线性逼近,沿着负梯度方向移动一段距离,然后跳回到原函数,如此反复,直至收敛。牛顿法也是在每一步利用逼近来降低函数值,尽管也是利用泰勒级数展开,但牛顿法中用的是二次逼近,其从初始点出发,通过重复构造函数的二次逼近,移动到这个二次方程的驻点并跳回到原函数来进行优化。因为牛顿法的每一步都使用二次逼近,而二次方程可以更好地模拟相关函数,所以牛顿法比最速下降法收敛更快,但牛顿法每次迭代都需要计算和存储矩阵,计算量较大。共轭梯度法利用一阶导数信息,收敛速度较快,共轭梯度法的每一个搜索方向是互相共轭的。针对3种最优化求解方法进行测试,共轭梯度法训练模型相对另外2种方法精度更高,优选共轭梯度法来进行最优求解。
2.2.3 模型质量控制
在深度学习过程中,要得到高精度的训练模型还需要优选的参数,包括隐藏层个数、神经元个数以及迭代次数的选择。合适的隐藏层个数能提高学习效率,隐藏层个数太少,不能有效进行分类,过多的隐藏层个数会使参数呈爆炸式增长,为机器带来负担,并且分类效果增强得越不明显。通过测试,研究区隐藏层个数为3时较合适。选择一个合适的隐藏层神经元数量也是至关重要的,在隐藏层中使用太少的神经元将导致欠拟合,使用过多的神经元同样会导致过拟合。经过多轮测试,研究区每个隐藏层里20个神经元较为合适。在确定好隐藏层个数及神经元个数后,还需要选取合适的迭代次数,通过测试,当迭代次数为30次时,训练及验证误差最小。选取合适的质量控制参数以后,利用井参与训练相关系数达到了0.958,井不参与训练验证相关系数为0.942,相关系数高,且两个相关系数差距小,证明深度学习模型预测精度高。从4口井实测含气量曲线与预测含气量曲线叠合看(图5),预测曲线细节特征清晰,与实钻曲线吻合程度高。

图5 实测曲线与预测曲线叠合图Fig.5 Superimposed graph of actual measured curve and predicted curve
2.3 应用效果
将研究区分布不同构造部位4口导眼井A、B、C、D作为训练样本数据,E井作为验证井。利用多属性融合、概率神经网络、深度学习3种不同方法对含气量进行预测,首先从模型上看,多属性融合验证相关系数为0.728,概率神经网络验证相关系数为0.836,深度学习验证相关系数为0.942,深度学习预测模型精度最高。再从3种方法预测E—D井含气量连井剖面看(图6),3种方法都具有龙马溪组一段从下往上含气量逐渐降低,底部优质页岩段含气量明显高于上部页岩储层的特征。多属性融合方法预测含气量整体偏低,E井优质页岩段实测含气量为4.7 m3/t,预测为4.1 m3/t,误差达到12.7%,E井优质页岩段含气量明显低于D井不符合地质认识。概率神经网络方法预测含气量整体偏高,E井优质页岩段预测含气量达到5.1 m3/t,误差为8.5%,深度学习方法预测E井优质页岩段含气量为4.5 m3/t,误差为4.2%,是3种预测方法中预测精度最高的。从深度学习技术预测研究区优质页岩段平均含气量平面图看(图7),D井北部含气量相对较高,往南降低,D井与E井相差不大。基于深度神经网络的含气量预测方法,相对传统的线性属性融合技术以及神经网络技术,预测精度有了进一步的提高。

图6 不同类型预测方法含气量预测剖面Fig.6 The gas content prediction profile of different types of prediction methods

图7 优质页岩段平均含气量与构造叠合Fig.7 The average gas content and structure superposition map of high-quality shale section
3 结论
1)基于深度学习的页岩气含气量预测方法,相比多属性融合及概率神经网络,能有效提高页岩气含气量预测精度。
2)研究区预测页岩含气量最优属性为密度、纵波阻抗、平均频率及优势频率;最优化求解方法为共轭梯度法。当深度学习预测模型在3个隐藏层、20个神经元及30次迭代次数时,预测模型精度最高,验证相关系数达到0.942。
3)预测含气量与实测含气量误差较小,且平面特征符合地质认识,该技术在一定程度上能为研究区页岩气储层评价提供支撑,指导该区页岩气勘探。
